해당 글은 제로베이스데이터스쿨 학습자료를 참고하여 작성되었습니다
Transformer
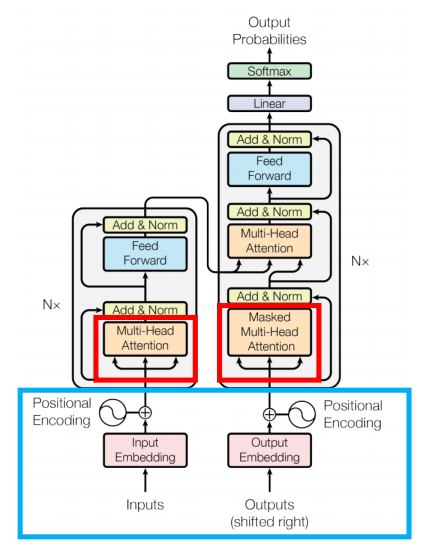
Transformer Architecture
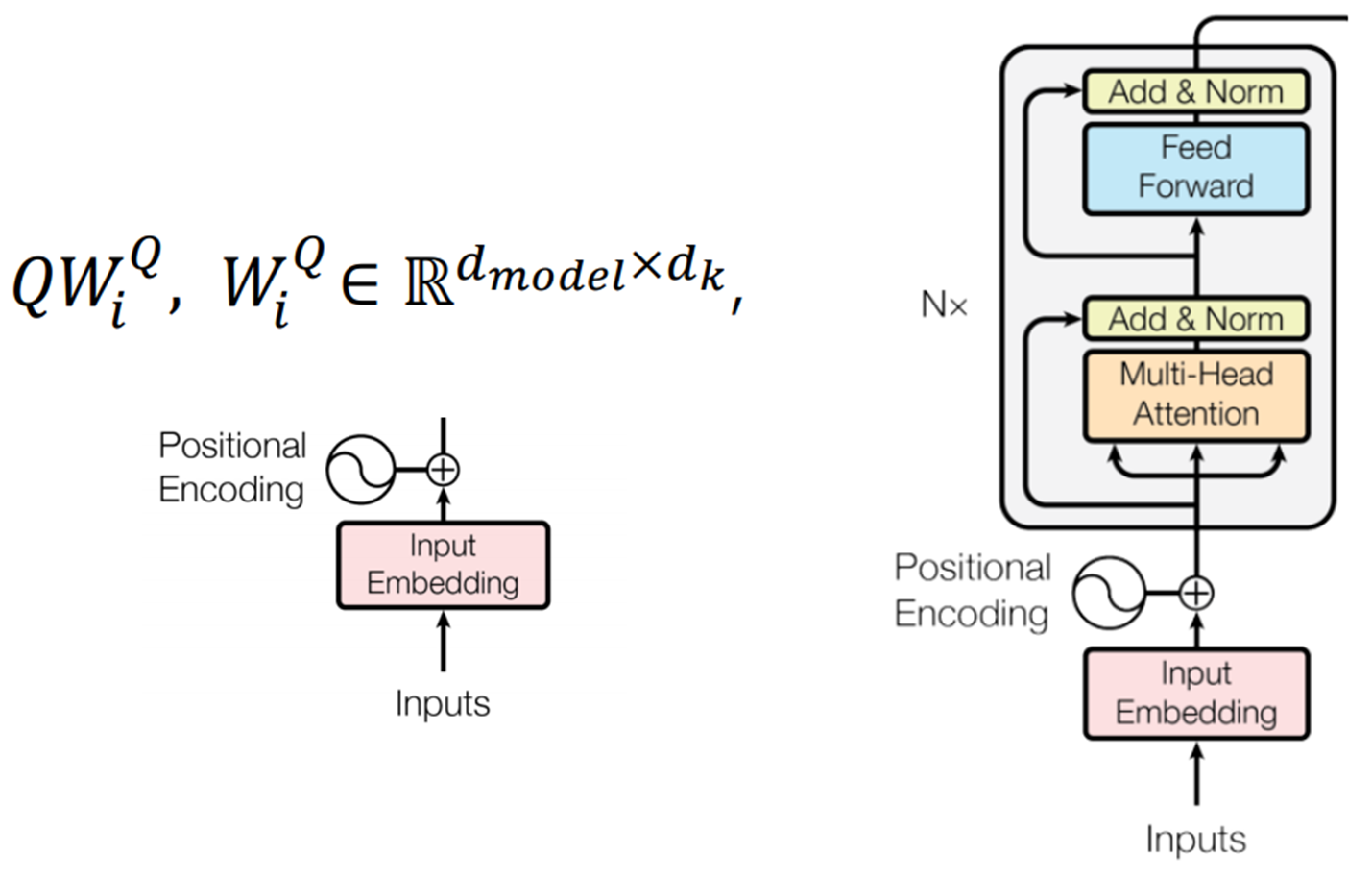
Positional Encoding
- transformer는 병렬 처리이므로 성능이 향상되었으나 RNN에서 가능했던 순서처리가 불가능해짐
- 이를 해결하기 위해 positional encoding 사용
- 각 토큰의 입력 임베딩에 위치 인코딩을 추가함으로써 Transformer 모델은 병렬 처리 구조에도 불구하고 토큰의 순차적 순서를 유지할 수 있게 됨
Multi head attention
- Self-Attention 메커니즘을 이용한 자연어 처리 향상 모듈
- 입력벡터로 query, key, value 벡터를 받음
- 이를 활용하여 attention score를 계산하고 단어별 중요도를 결정할 수 있음
성능향상을 위한 기술
- Skip Connection
- 한 계층의 출력을 다른 계층의 출력에 직접 추가하는 연결
- Vanishing Gradient를 완화하기 위해 사용한 방법
- Layer Normalization
- 각 계층의 출력 정규화
- 입력 변동의 영향을 줄이고 네트워크의 전반적인 안정성과 성능 향상
기존 모델과 성능비교
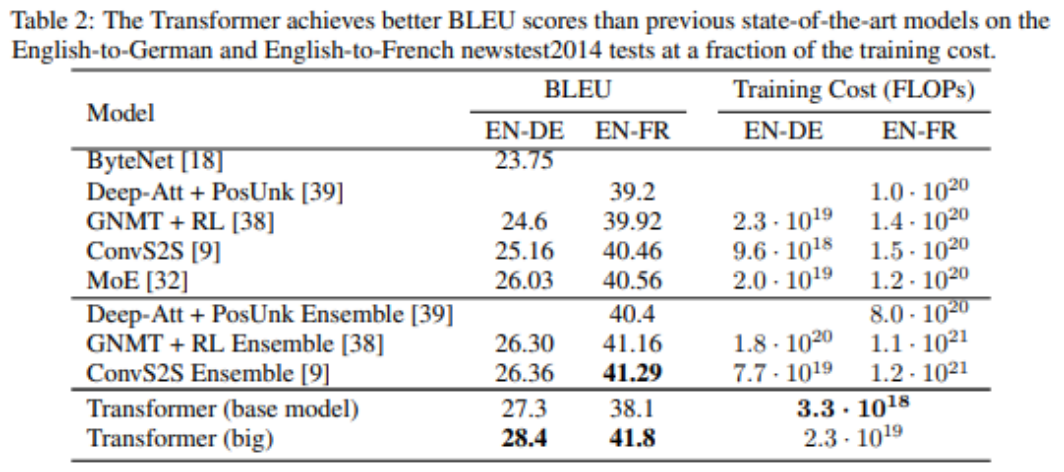
요약
- 기계번역 task에서 기존의 연구들 보다 성능적으로 우수
- 병렬적으로 처리가 가능한 모델 -> time complexity 감소
- 이후에 사용되는 Bert, GPT 모델에서 일반화에 강점이 있다는 것이 확인
Positional Encoding
필요한 이유
- 기존의 RNN 기반의 방법 경우, context 벡터를 추출해서 사용함
- 이러한 추출을 하기 위해서는 문장의 단어들을 순차적으로 처리해야 했음
- 디코더도 마찬가지로 순차적으로 처리되었고 문장의 순서를 고려하게 됨
- 반면 Transformer 의 입력 Q 의 경우 행렬 연산을 통해 입력 벡터로 변환되어 Multi-head attention 모듈에 들어감
- 문장의 순서에 대한 정보를 넣어줄 필요성이 생김
어떻게 부여해야 하는가
- 단어 순서대로 숫자 카운팅 -> 숫자가 너무 빨리 커져서 weight 학습이 어려우므로 X
- 카운팅 후 정규화 -> weight 학습은 안정적이지만, 단어가 추가되면 같은 값 할당 불가능하므로 X
- 단어 순서대로 벡터표현 -> 단어 순서끼리의 거리가 달라지므로 X
- Sinusodial Encoding 사용
- i=depth, p=position
- 삼각함수 sin, cos 사용
- rotaion matrix로 인해 적절한 상대거리를 얻게 됨

 Reference : skyjwoo의 position_encoding 포스팅
Reference : skyjwoo의 position_encoding 포스팅
Python Code
def positional_encoding(max_position, d_model, min_freq=1e-4):
position = np.arange(max_position)
freqs = min_freq**(2*(np.arange(d_model)//2)/d_model)
pos_enc = position.reshape(-1,1)*freqs.reshape(1,-1)
pos_enc[:,::2] = np.cos(pos_enc[:, ::2]) # 짝수만 cos
pos_enc[:, 1::2] = np.sin(pos_enc[:, 1::2]) # 홀수만 sin
return pos_encMulti-head Self-attention
설명
-
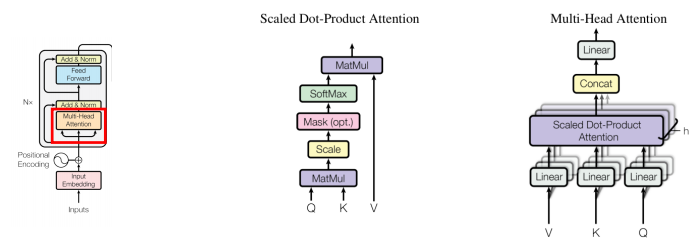
Query, Key, Value attention을 기반으로 Scaled Dot-pordict attention을 사용함
-
기존의 attention 기법의 경우 Key와 Query만 존재
-
그러나 Transformer의 attention의 경우 Value까지 존재
-
문장을 이해할 때 단어들은 서로 영향을 끼치며 그 강도는 다르다
-
단어에 대한 벡터(Q)는 주어진 단어들에 대해서 유사한 정도(K)만큼 고려하고 각 주어진 단어들은 V만큼의 중요도를 갖는다
Attention
k번째 단어만 고려하여 Q, V, K 계산

"I love you"라는 문장으로 예시를 들면 input linear embedding을 통해 각 단어에 대한 Q,K,V 행렬로 변환한다
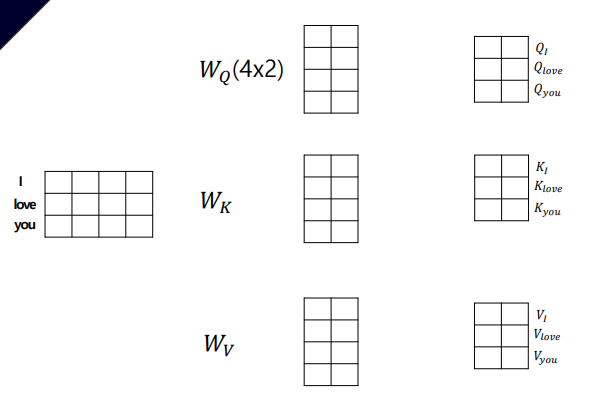
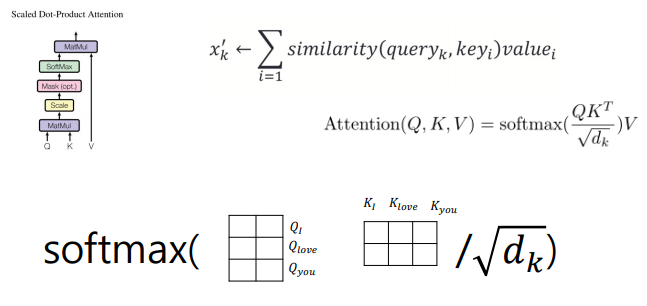
softmax을 Q, K에 대해 적용한다
- Query 로 단어를 주었을 때
- 이 단어와 유사한 Key 값을 더욱더 attention 을 주고
- 이 key 값의 중요도에 따라서 Value 값을 준다.
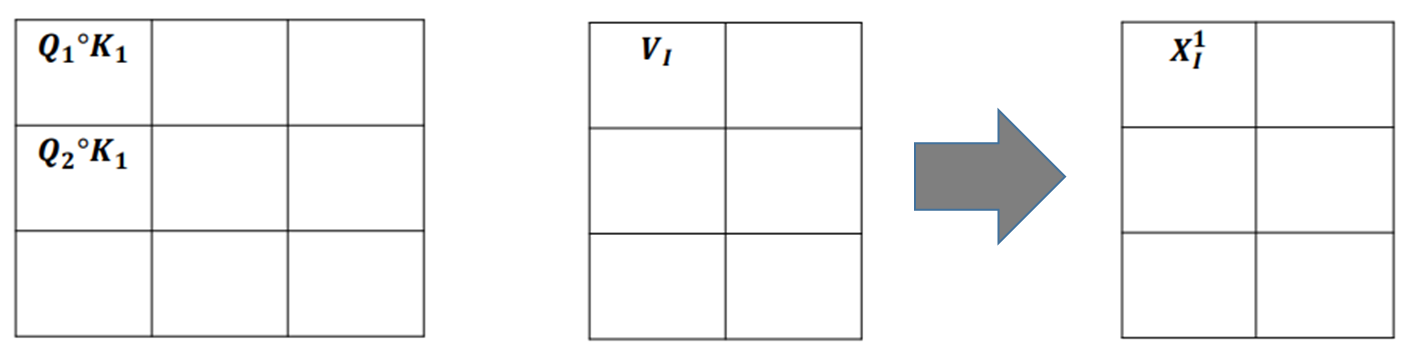
softmax(Q,K)결과에 V를 곱해서 Attention 획득
- Attention 매트릭스가 Query의 차원수와 동일해짐
- 계속해서 같은 차원으로 Self-attention 수행이 가능하게 된다
Mask Matrix
-
에 mask값으로 0에 가까운 값을 주어서 특정 단어는 무시할 수 있도록 함
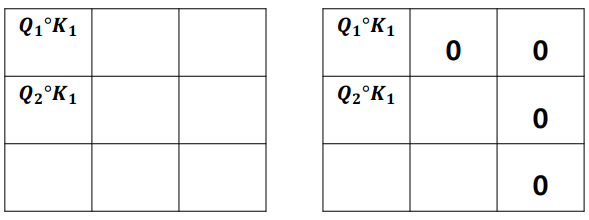
-
처음 쿼리의 차원수 head의 개수만큼 나눠주기 때문에 최종적으로 입력의 차원수와 같게 된다

Python Code
- reference : 참조한 깃허브
import torch
import torch.nn as nn
class MultiHeadAttentionLayer(nn.Module):
def __init__(self, hidden_dim, n_heads, dropout_ratio, device):
super().__init__()
assert hidden_dim % n_heads == 0
self.hidden_dim = hidden_dim # 임베딩 차원
self.n_heads = n_heads # 헤드(head)의 개수: 서로 다른 어텐션(attention) 컨셉의 수
self.head_dim = hidden_dim // n_heads # 각 헤드(head)에서의 임베딩 차원
self.fc_q = nn.Linear(hidden_dim, hidden_dim) # Query 값에 적용될 FC 레이어
self.fc_k = nn.Linear(hidden_dim, hidden_dim) # Key 값에 적용될 FC 레이어
self.fc_v = nn.Linear(hidden_dim, hidden_dim) # Value 값에 적용될 FC 레이어
self.fc_o = nn.Linear(hidden_dim, hidden_dim)
self.dropout = nn.Dropout(dropout_ratio)
self.scale = torch.sqrt(torch.FloatTensor([self.head_dim])).to(device)
def forward(self, query, key, value, mask = None):
batch_size = query.shape[0]
# query: [batch_size, query_len, hidden_dim]
# key: [batch_size, key_len, hidden_dim]
# value: [batch_size, value_len, hidden_dim]
Q = self.fc_q(query)
K = self.fc_k(key)
V = self.fc_v(value)
# Q: [batch_size, query_len, hidden_dim]
# K: [batch_size, key_len, hidden_dim]
# V: [batch_size, value_len, hidden_dim]
# hidden_dim → n_heads X head_dim 형태로 변형
# n_heads(h)개의 서로 다른 어텐션(attention) 컨셉을 학습하도록 유도
Q = Q.view(batch_size, -1, self.n_heads, self.head_dim).permute(0, 2, 1, 3)
K = K.view(batch_size, -1, self.n_heads, self.head_dim).permute(0, 2, 1, 3)
V = V.view(batch_size, -1, self.n_heads, self.head_dim).permute(0, 2, 1, 3)
# Q: [batch_size, n_heads, query_len, head_dim]
# K: [batch_size, n_heads, key_len, head_dim]
# V: [batch_size, n_heads, value_len, head_dim]
# Attention Energy 계산
energy = torch.matmul(Q, K.permute(0, 1, 3, 2)) / self.scale
# energy: [batch_size, n_heads, query_len, key_len]
# 마스크(mask)를 사용하는 경우
if mask is not None:
# 마스크(mask) 값이 0인 부분을 -1e10으로 채우기
energy = energy.masked_fill(mask==0, -1e10)
# 어텐션(attention) 스코어 계산: 각 단어에 대한 확률 값
attention = torch.softmax(energy, dim=-1)
# attention: [batch_size, n_heads, query_len, key_len]
# 여기에서 Scaled Dot-Product Attention을 계산
x = torch.matmul(self.dropout(attention), V)
# x: [batch_size, n_heads, query_len, head_dim]
x = x.permute(0, 2, 1, 3).contiguous()
# x: [batch_size, query_len, n_heads, head_dim]
x = x.view(batch_size, -1, self.hidden_dim)
# x: [batch_size, query_len, hidden_dim]
x = self.fc_o(x)
# x: [batch_size, query_len, hidden_dim]
return x, attentionLayer Normalization
Batch norm vs Layer norm
- Batch nrom : sample들의 feature별 평균과 분산 -> batch size에 따라서 성능변화가 심함
Layer nrom : 각 batch에 대해서 feature들의 평균과 분산
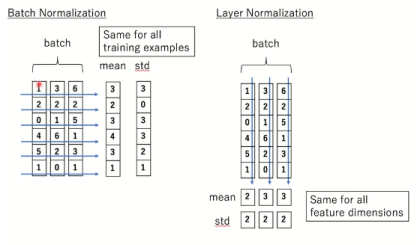
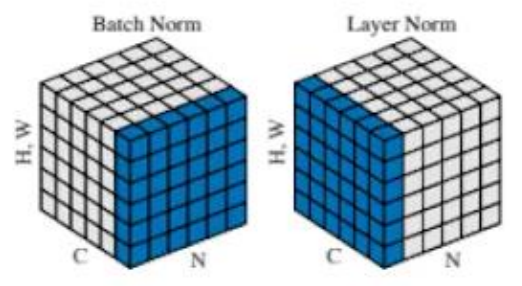
Python Code
class LayerNorm(nn.Module):
def __init__(self, d_model, eps=1e-8):
super(LayerNorm, self).__init__()
self.gamma = nn.Parameter(torch.ones(d_model))
self.beta = nn.Parameter(torch.zeros(d_model))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.gamma * (x - mean) / (std + self.eps) + self.betaFinal Summary
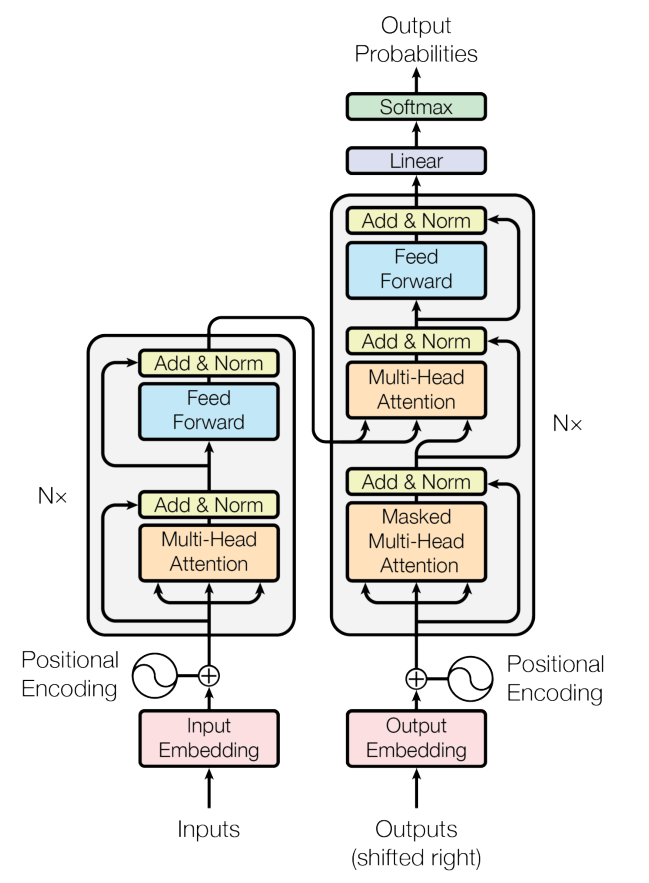
- input 임베딩 + Position Encoding (Encoder)
- Q, K, V 생성
- Multi-Head Attention 사용
- Skip-Connection + Layer Normalization
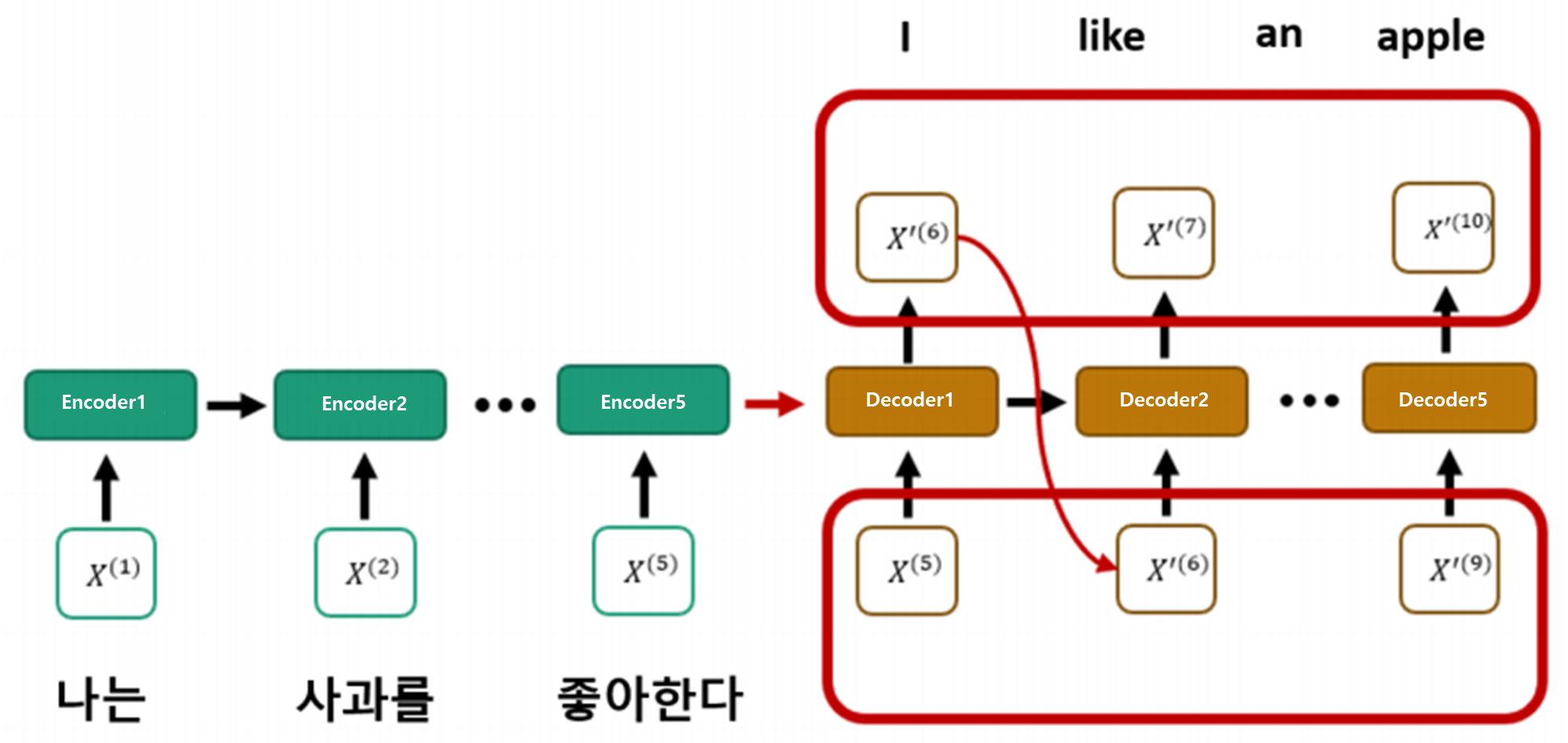
- Self-attention 반복수행
- Encoder의 출력값을 Decoder가 받아서 학습을 진행
- Linear모델과 softmax을 통해서 최종결과(확률)를 도출
