해당 글은 제로베이스데이터스쿨 학습자료를 참고하여 작성되었습니다
추천시스템
- 사용자 또는 제품을 기준으로 새로운 제품을 추천하는 알고리즘
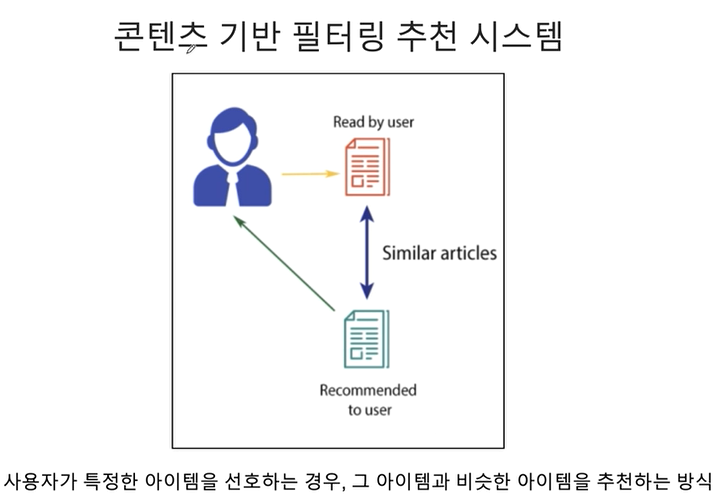
콘텐츠 기반 필터링 추천 시스템
- 사용자가 특정 아이템을 선호하는 경우, 그 아이템과 비슷한 아이템을 추천하는 방식
tmdb_5000_movies
- CountVecotrize를 사용하여 유사도기준 추천
데이터 가져오기
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
movies = pd.read_csv('https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/tmdb_5000_movies.csv')
print(movies.shape)
--------------------
(4803, 20)movies.head(3)
필요칼럼만 사용
- id : 아이디
- title : 영화제목
- genres : 장르
- vote_average : 평균평점
- vote_count : 투표수
- popularity : 인기
- keywords : 키워드
- overview : 영화개요
movies_df = movies[['id', 'title', 'genres', 'vote_average', 'vote_count', 'popularity', 'keywords', 'overview']]
movies_df.head(3)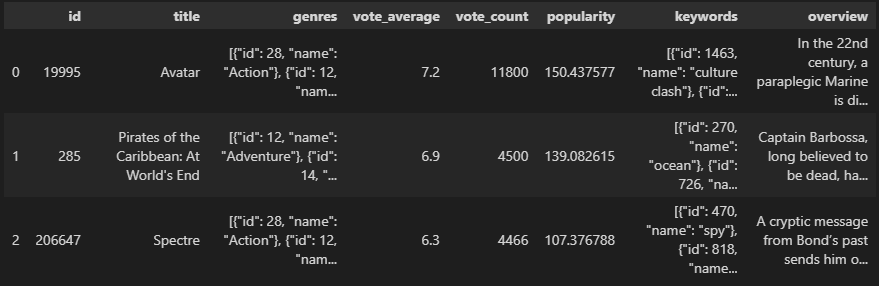
장르 정보가 str 안의 dict 형태로 존재함
movies_df[['genres']][:1].values
----------------------------------
array([['[{"id": 28, "name": "Action"}, {"id": 12, "name": "Adventure"}, {"id": 14, "name": "Fantasy"}, {"id": 878, "name": "Science Fiction"}]']],
dtype=object)장르와 키워드의 내용을 list와 dict로 복구
from ast import literal_eval
movies_df['genres'] = movies_df['genres'].apply(literal_eval)
movies_df['keywords'] = movies_df['keywords'].apply(literal_eval)
movies_df.head()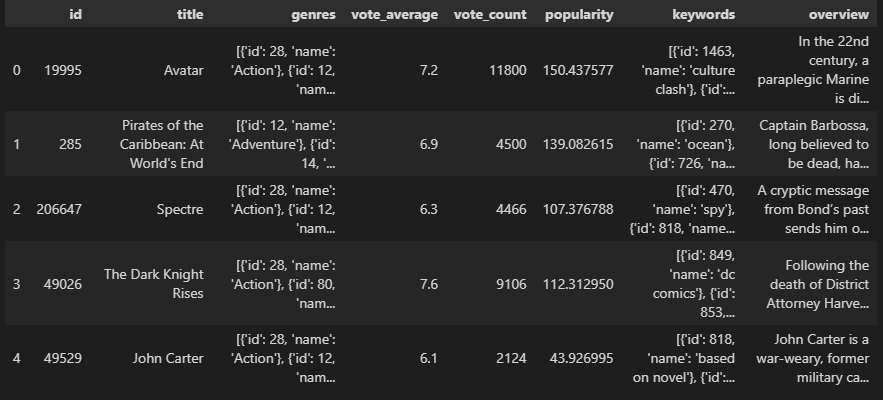
데이터를 복구하기는 했지만 id는 불필요
movies_df['genres'][0]
-----------------------------------------
[{'id': 28, 'name': 'Action'},
{'id': 12, 'name': 'Adventure'},
{'id': 14, 'name': 'Fantasy'},
{'id': 878, 'name': 'Science Fiction'}]movies_df['genres'] = movies_df['genres'].apply(lambda x: [y['name'] for y in x])
movies_df['keywords'] = movies_df['keywords'].apply(lambda x: [y['name'] for y in x])
movies_df[['genres', 'keywords']]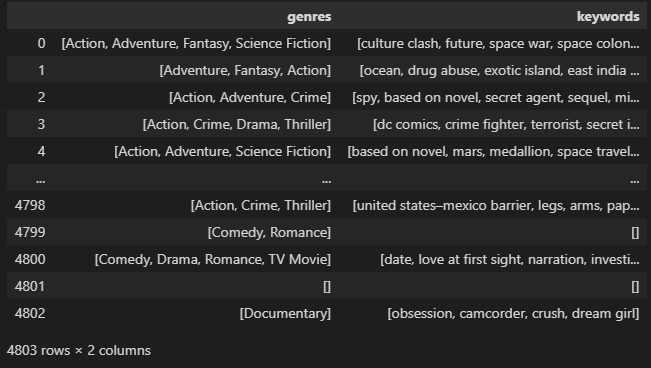
장르를 문자열로 치환
movies_df['genres_literal'] = movies_df['genres'].apply(lambda x: (' ').join(x))
movies_df.head(3)
문자열로 변환된 genres를 CountVecotrize 수행
from sklearn.feature_extraction.text import CountVectorizer
count_vect = CountVectorizer(min_df=0, ngram_range=(1,2))
genre_mat = count_vect.fit_transform(movies_df['genres_literal'])
print(genre_mat.shape)
------------------------
(4803, 276)코사인 유사도 측정

from sklearn.metrics.pairwise import cosine_similarity
genre_sim = cosine_similarity(genre_mat, genre_mat)
print(genre_sim.shape)
print(genre_sim[:2])
---------------------------------------------------------------------------
(4803, 4803)
[[1. 0.59628479 0.4472136 ... 0. 0. 0. ]
[0.59628479 1. 0.4 ... 0. 0. 0. ]]코사인 유사도 확인
- 행(item0)과 열(itme1)의 유사도=0.59628479
genre_sim
-------------------------------------------------------------------------
array([[1. , 0.59628479, 0.4472136 , ..., 0. , 0. ,
0. ],
[0.59628479, 1. , 0.4 , ..., 0. , 0. ,
0. ],
[0.4472136 , 0.4 , 1. , ..., 0. , 0. ,
0. ],
...,
[0. , 0. , 0. , ..., 1. , 0. ,
0. ],
[0. , 0. , 0. , ..., 0. , 0. ,
0. ],
[0. , 0. , 0. , ..., 0. , 0. ,
1. ]])코사인유사도 행렬변환
genre_sim_sorted_ind = genre_sim.argsort()[:, ::-1]
print(genre_sim_sorted_ind[:1])
--------------------------------------
[[ 0 3494 813 ... 3038 3037 2401]]추천 영화를 DF로 반환
- 데이터 결과를 보면 'Mi America'의 평점이 0 -> 오류발생
def find_sim_movie(df, sorted_ind, title_name, top_n=10):
title_movie = df[df['title'] == title_name]
title_index = title_movie.index.values
similar_indexes = sorted_ind[title_index, :(top_n)]
print(similar_indexes)
similar_indexes = similar_indexes.reshape(-1)
return df.iloc[similar_indexes]
similar_movies = find_sim_movie(movies_df, genre_sim_sorted_ind, 'The Godfather', 10)
similar_movies[['title', 'vote_average']]
------------------------------------------------------
[[2731 1243 3636 1946 2640 4065 1847 4217 883 3866]]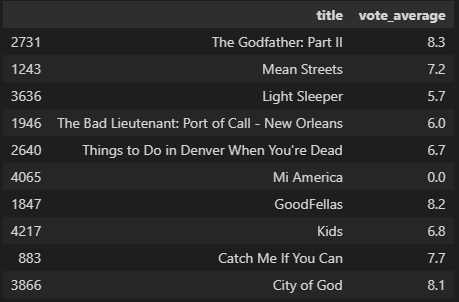
오류확인
movies_df[['title', 'vote_average', 'vote_count']].sort_values('vote_average', ascending=False)[:10]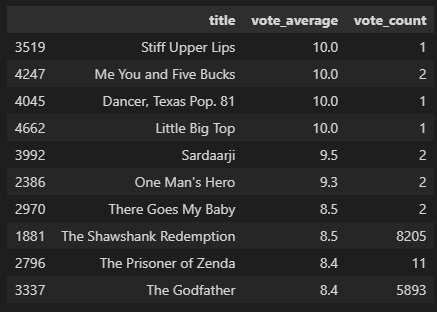
가중치 부여
영화 전체 평균평점과 최소 투표 횟수를 60% 지점으로 지정

C = movies_df['vote_average'].mean()
m = movies_df['vote_count'].quantile(0.6)
print('C:', round(C,3), 'm:',round(m,3))
------------------------------------------
C: 6.092 m: 370.2가중치가 부여된 평점을 계산하기
def weighted_vote_average(record):
v = record['vote_count']
R = record['vote_average']
return ( (v/(v+m))*R + (m/(v+m))*C )
movies_df['weighted_vote'] = movies_df.apply(weighted_vote_average, axis=1)
movies_df.head()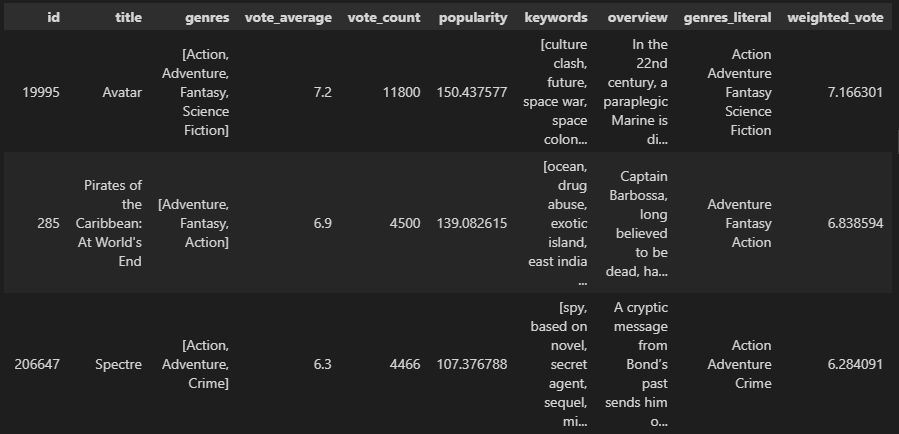
횟수가 적은 데이터
- 평균 평점은 높았지만 가중치를 부여하니 값이 많이 내려감
movies_df[movies_df['vote_count'] < 10]
전체 데이터에서 가중치가 부여된 평점 순으로 정렬한 결과
movies_df[['title', 'vote_average', 'weighted_vote', 'vote_count']].sort_values(by='weighted_vote', ascending=False)[:10]
유사 영화를 찾는 함수 변경
대부와 유사한 영화 찾기
def find_sim_movie(df, sorted_ind, title_name, top_n=10):
title_movie = df[df['title'] == title_name]
title_index = title_movie.index.values
similar_indexes = sorted_ind[title_index, :(top_n*2)]
print(similar_indexes)
similar_indexes = similar_indexes.reshape(-1)
similar_indexes = similar_indexes[similar_indexes != title_index]
return df.iloc[similar_indexes].sort_values(by='weighted_vote', ascending=False)[:top_n]
similar_movies = find_sim_movie(movies_df, genre_sim_sorted_ind, 'The Godfather', 10)
similar_movies[['title', 'vote_average', 'weighted_vote']]
------------------------------------------------------------------------
[[2731 1243 3636 1946 2640 4065 1847 4217 883 3866 3112 4041 588 3337
3378 281 1663 1464 1149 2839]]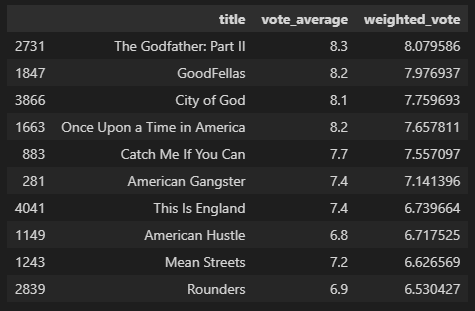
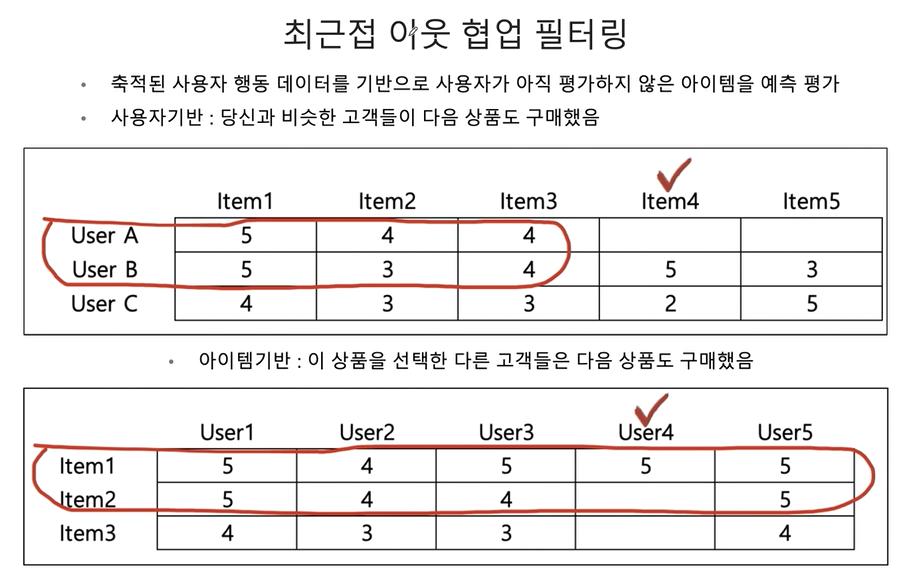
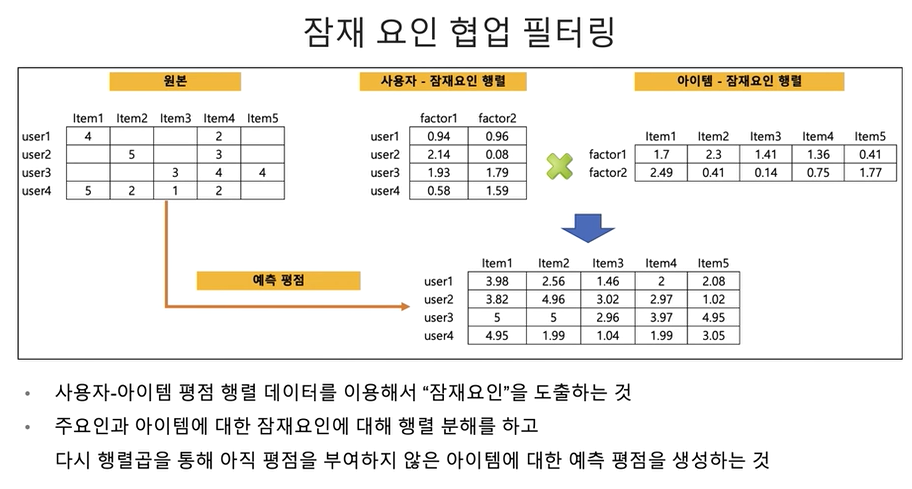
최근접 이웃 협업 추천 시스템
- 축적된 사용자 행동 데이터를 기반으로 사용자가 아직 평가하지 않은 아이템을 예측 평가
- 사용자 기반 : 당신과 비슷한 고객들이 다음 상품도 구매했음
- 아이템 기반 : 이 상품을 선택한 다른 고객들은 다음 상품도 구매했음
- 일반적으로는 사용자 기반보다는 아이템 기반 협업 필터링이 정확도가 더 높음
ml-latest-small-movies
데이터 읽기
import pandas as pd
import numpy as np
movies = pd.read_csv('./data/ml-latest-small/movies.csv')
ratings = pd.read_csv('./data/ml-latest-small/ratings.csv')
print(movies.shape)
print(ratings.shape)
---------------------
(9742, 3)
(100836, 4)movies.head()
ratings.head()
데이터 변환
- id별로 나오니 이를 타이틀로 변경해준다
ratings = ratings.drop('timestamp', axis=1)
ratings_matrix = ratings.pivot_table(index='userId', columns='movieId', values='rating')
ratings_matrix.head()
데이터 통합
rating_movies = pd.merge(ratings, movies, on='movieId')
rating_movies.head()
데이터 title별로 정리
ratings_matrix = rating_movies.pivot_table(index='userId', columns='title', values='rating')
ratings_matrix
nan -> 0
ratings_matrix = ratings_matrix.fillna(0)
ratings_matrix.head()
유사도 측정을 위해 행렬 변환
ratings_matrix_T = ratings_matrix.transpose()
ratings_matrix_T.head()
코사인 유사도 측정
from sklearn.metrics.pairwise import cosine_similarity
item_sim = cosine_similarity(ratings_matrix_T, ratings_matrix_T)
item_sim_df = pd.DataFrame(data=item_sim, index=ratings_matrix.columns, columns=ratings_matrix.columns)
print(item_sim_df.shape)
item_sim_df
--------------
(9719, 9719)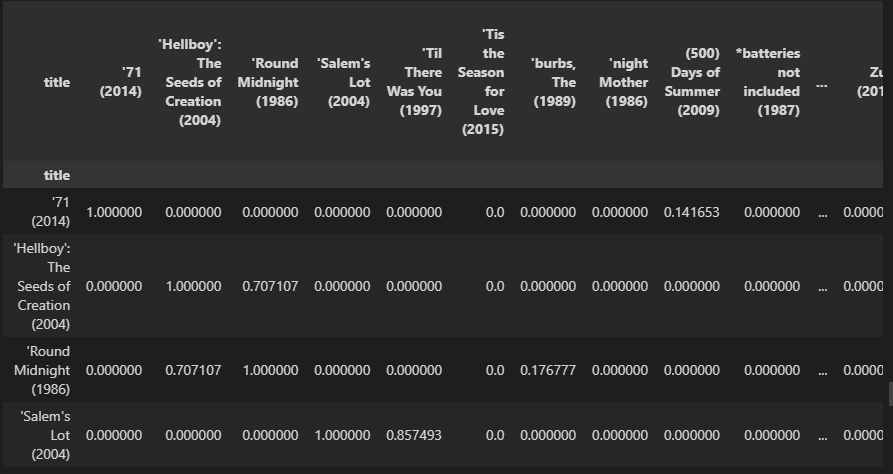
대부와 유사한 영화 찾기
item_sim_df['Godfather, The (1972)'].sort_values(ascending=False)[:6]
---------------------------------------------------------
title
Godfather, The (1972) 1.000000
Godfather: Part II, The (1974) 0.821773
Goodfellas (1990) 0.664841
One Flew Over the Cuckoo's Nest (1975) 0.620536
Star Wars: Episode IV - A New Hope (1977) 0.595317
Fargo (1996) 0.588614
Name: Godfather, The (1972), dtype: float64인셉션과 유사한 영화 찾기
item_sim_df['Inception (2010)'].sort_values(ascending=False)[:6]
------------------------------------------
title
Inception (2010) 1.000000
Dark Knight, The (2008) 0.727263
Inglourious Basterds (2009) 0.646103
Shutter Island (2010) 0.617736
Dark Knight Rises, The (2012) 0.617504
Fight Club (1999) 0.615417
Name: Inception (2010), dtype: float64