IntroToPandas
1.Create a DataFrame from List (#01)
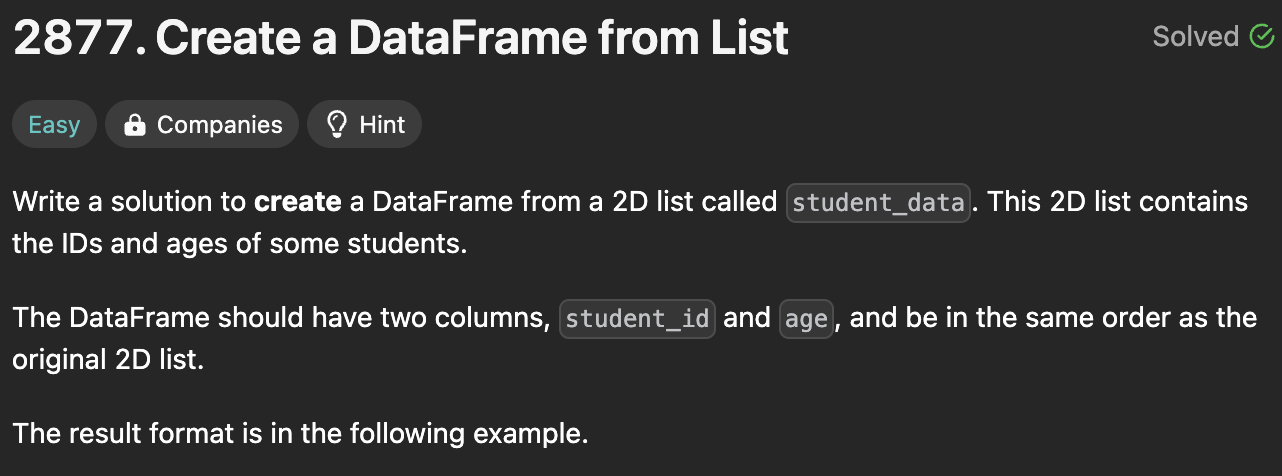
LeetCode 01.25.df = pd.DataFrame(List, columns=\["student_id", "age"])요러케 한번에 column명을 적어줘도 됨df.colums = \['변경할', '열이름']모든 column명을 적어주어야 한다. 원본이 바뀐다.
2.Get the Size of a DataFrame (#02)
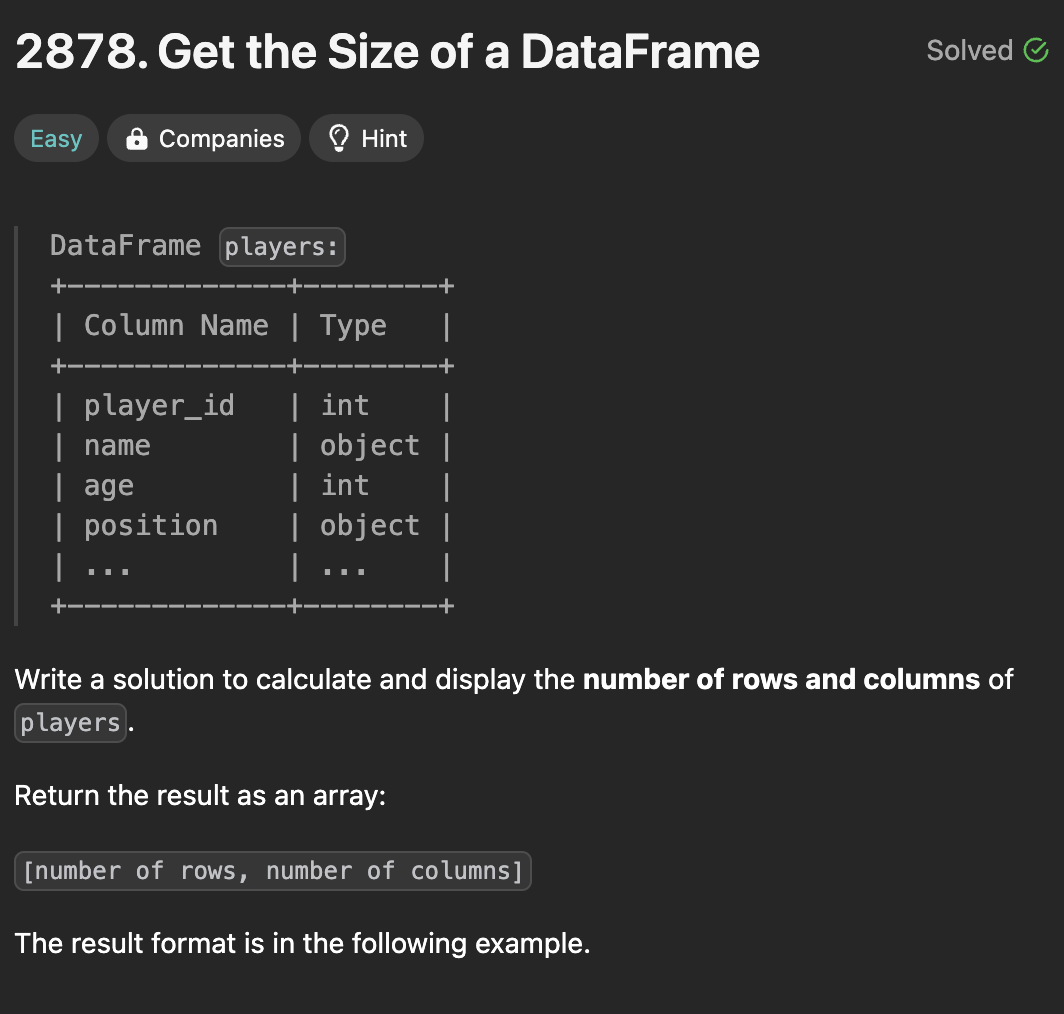
01.27. LeetCodedf.shape(행, 열)로 출력되며 데이터타입은 tuple.\* tuple: list랑 유사하지만, 값 변경이 불가능한 자료형이다(immutable type). string도 immutable type임.값이 한 개 일 때는 콤마를 꼭 붙여
3.Display the First Three Rows (#03)
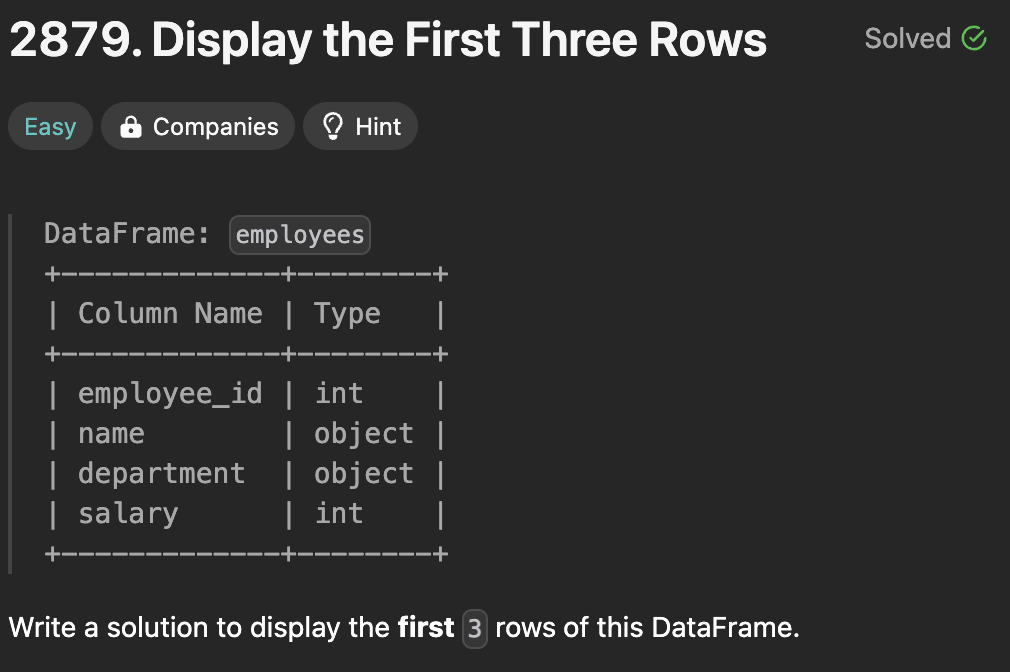
01.28. LeetCode df.head(3) 인덱스와 상관없이 데이터프레임의 처음 3개의 행을 반환한다. 간단히 데이터를 미리 보고 싶을 때 good df.loc\[0:2] 인덱스 값이 0, 1, 2인 행을 반환한다. (2를 포함한다..!) 인덱스 값이 중요하거
4.Select Data (#04)
0 True 1 False2 False3 FalseName: student_id, dtype: boolean student_id name age0 101 Ulysses 13
5.Create a New Column (#05)

df.insert(loc, column, value, allow_duplicates=False)특정 위치에 열(column)을 삽입하는 메서드loc은 행 번호, columns은 칼럼명, value는 (보통) list이다.allow_duplicates를 True로 하면,
6.Drop Duplicate Rows (#06)
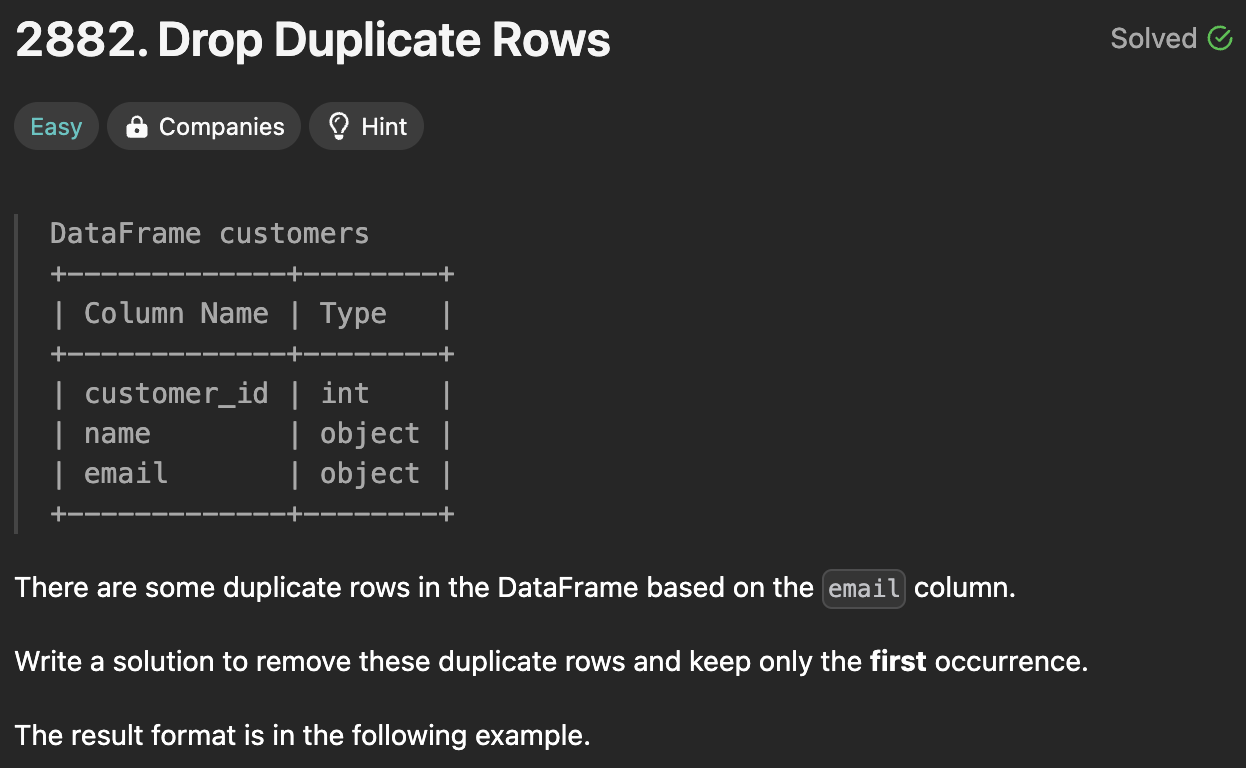
df.drop_duplicates(subset=None, keep='first', inplace=False, ignore_index=False)subset : 기준이 되는 열(column). 지정하지 않을 시 모든 열을 기준으로 검사한다. keep : 중복일 때 남길
7.Drop Missing Data (#07)
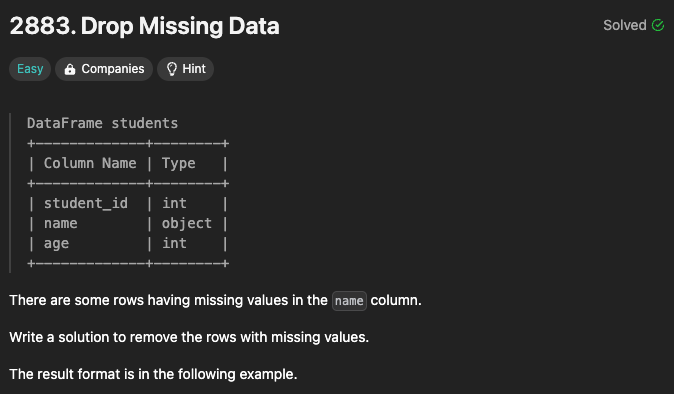
0 False1 True2 False3 FalseName: name, dtype: bool이걸 몰라서 바로 못풀었네df.dropna() 또는 df.dropna(axis=0)로 하면, 결측치가 있는 행 제거df.dropna(axis=1) 하면, 결
8.Modify Columns (#08)
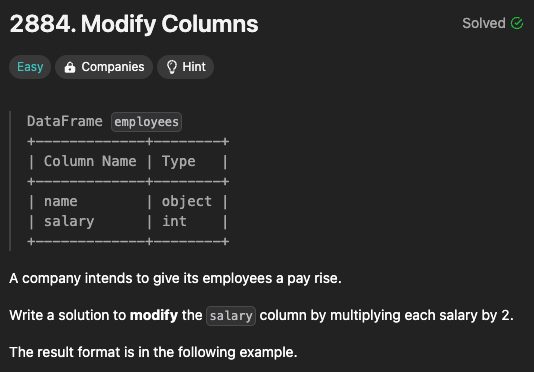
다른 풀이들도 다 똑같이 풀었다.<그나마 달랐던..>(굳이) lambda를 쓴 코드인데 공부겸 불러왔다..apply(함수)는 pandas(dic, series)에서 사용되는 메서드로, 각 원소에 대해 주어진 함수를 적용한다.employees\["salary"].a
9.Rename Columns (#09)
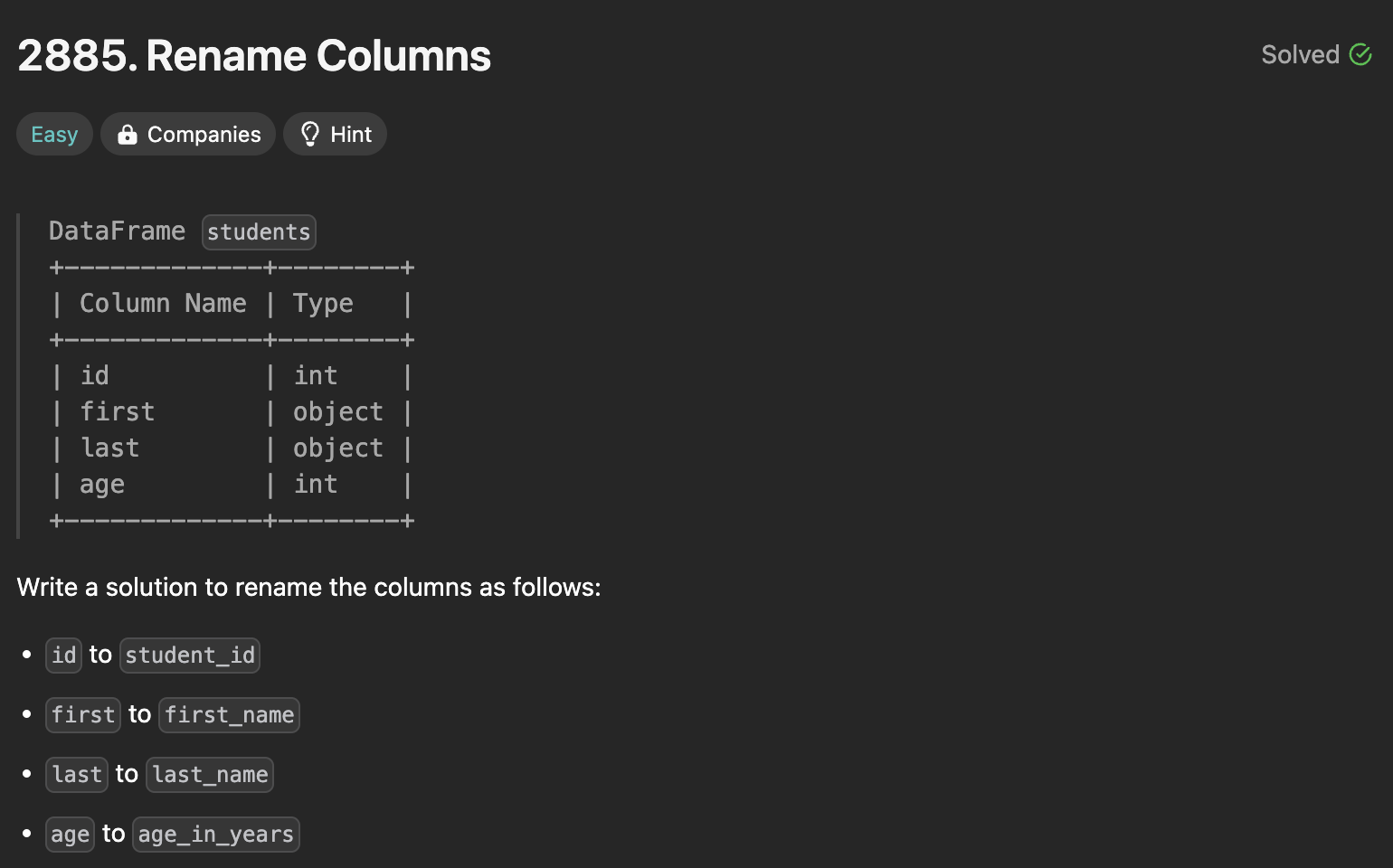
df.rename(columns={기존명:바꿀이름, 기존명:바꿀이름}, inplace='False')inplace=True이면 원본을 직접 수정, False이면 복사본을 업데이트.(cf. 열을 바꾸려면 index="")df.rename({기존명:바꿀이름, 기존명:바꿀이