[Paper Review] PointContrast: Unsupervised Pre-training for 3D Point Cloud Understanding
오랜만에 글을 다시 씁니다. 매번 너무 자세하게 정리하려다보니, 글을 쓸 엄두가 잘 안 나서 차일피일 미루던게 벌써 9개월이나 지나버렸네요. 앞으론 핵심 위주로 간략하게, 꾸준히 쓰는 것을 목표로 하려 합니다.
오늘 다룰 논문은 ECCV 2020에서 공개된 Facebook AI의 'PointContrast:Unsupervised Pre-training for 3D Point Cloud Understanding'[1]라는 논문입니다.
제목에서 알 수 있듯이 3D Point Cloud 관련 task를 수행하는 네트워크를 Unsupervised Pretraining하는 기법을 제안한 것인데요, detection, segmentation 등의 high-level task에 적용할 수 있는 Pretraining 방법을 처음으로 제안한 논문입니다. 이번 ICCV 2021에서는 Facebook AI에서 Self-Supervised Pretraining of 3D Features on any Point-Cloud라는 제목의 후속 논문을 발표하기도 하였는데요, 추후 별도의 글로 다루어보도록 하겠습니다.
Unsupervised Pre-training?
먼저 Pre-training이 무엇인지 간단히 짚고 넘어가겠습니다. Pre-training은 궁극적으로 수행하고자 하는 task를 위한 학습에 앞서, 보조적인 학습을 미리 수행하여 네트워크가 좋은 feature를 학습할 수 있도록 하는 방법입니다. 가장 대표적인 것이 컴퓨터 비전 분야에서의 ImageNet dataset을 이용한 Pre-training입니다. 사용하고자 하는 CNN backbone 네트워크를 ImageNet classificaiton을 수행하도록 학습시키면, backbone 네트워크는 class를 잘 구분할 수 있는 이미지의 feature를 잘 추출하도록 학습될 것입니다. 여기서 뒤에 classification을 위한 fully connected layer를 똑 뗀 다음, 대신 하고자 하는 task(e.g. detection, semantic segmentation, etc)를 수행하는 네트워크를 뒤에 붙여 본격적인(?) 학습을 수행합니다.
ImageNet Classification을 이용한 Pre-training은 class label이 존재하는 Supervised Pre-training방법이라고 할 수 있겠습니다. 이 논문에서는 이러한 label 없이 수행하는, 3D Point Cloud data만을 이용한 Unsupervised Pre-training 방법을 제안합니다.
Pre-training을 위한 삼박자: dataset, backbone, loss
Pre-training 방법을 제안하려면
1. dataset(e.g. ImageNet)
2. backbone network(e.g. ResNet)
3. loss(e.g. classification loss)
이 3가지가 정해져야할 것입니다. 논문에서도 이 3가지에 대해 논하고 있지만, 결국 핵심은 loss를 어떻게 만들었는지이므로 다른 부분들은 간단히 정리하면서 넘어가도록 하겠습니다!
1. Dataset
먼저 이 논문에서 다루는 pre-training의 목적을 다시 한 번 상기할 필요가 있습니다. 이 논문에서는 Point Cloud 기반의 object detection, semantic segmentation과 같은 high-level task를 위한 feature를 잘 학습할 수 있는 Pre-training 방법을 얻고자 합니다.
ShapeNet은 어떨까?
ShapeNet은 여러 가지 물체의 3D CAD model을 모아놓은 데이터셋이며, 3D point cloud 형태로 변환이 가능합니다. 아래 그림은 PointNet[2] 논문에서 가져왔습니다. 
ShapeNet은 Point Cloud 계의 ImageNet 같은 존재라고 할 수 있겠습니다. 이미지 기반 네트워크에서 하듯이 ShapeNet classification을 이용한 Pre-training, 즉 Supervised Pre-training을 수행한 뒤 학습된 backbone을 high-level task에 사용하는 방법을 먼저 떠올릴 수 있습니다. 3.1절에서 Pilot Study로서 수행한 실험을 보이고 있고, 결론적으로는 성능에 좋은 영향을 주지 못했습니다. 그 이유로 저자들은 다음 2가지 이유를 제시합니다.
- ShapeNet은 가상 데이터이고, Pose가 align되어 있고, scale은 normalize되어 있으며 context가 존재하지 않는 반면, detection, segmentation을 수행하는 S3DIS같은 데이터셋은 다양한 context가 존재하므로, Domain Gap이 크다.
- 3D deep learning에서는 local geometric feature(~= point-wise feature)가 중요한데, object 단위의 classification을 학습하는 것은 global representation, 즉 point cloud 전체의 feature를 중심으로 학습되므로 detection, segmentation과 같은 high-level task를 위한 point-wise feature의 학습이 이루어지기엔 불충분하다.
저자들이 제시한 이 2가지 이유로부터 논문의 이어지는 내용을 추측해 볼 수 있습니다. 당연하게도 scene 단위의 데이터셋을 사용하겠고, 뭔지는 몰라도 point-wise feature를 잘 학습할 수 있는 loss를 제안할 것 같습니다.
ScanNet을 씁시다!
저자들은 결론적으로 ScanNet이라는 indoor RGB-D Dataset을 사용합니다. ScanNet은 약 1500개의 indoor scene으로 구성되어 있는데요, 사용할만한 3D Dataset 중 가장 많은 양이기 때문에 이를 사용했다고 합니다. 아래는 ScanNet 논문[3]에서 가져온 예시입니다.
2. Backbone Network
pre-training을 위한 backbone으로 본 논문에서는 Sparse Residual U-Net(SR-UNet)을 사용합니다. convolution을 sparse convolution으로 바꾼 Resnet 기반 U-Net으로 생각하시면 될 듯 합니다. Minkowski Engine 논문에서 제안한 구조를 살짝 변형했다고 합니다. Sparse Convolution의 개념 자체는 이전에 등장했는데 이에 관한 설명은 생략하도록 하겠습니다.
point cloud를 3차원 voxel로 quantization하면 실제로는 대부분의 voxel이 비어있게 되어, 단순히 2D CNN을 3D CNN으로 확장하여 적용하게 되면 매우 비효율적입니다. 이에 따라 등장한 것이 Sparse Convolution이고, 자세한 내용은 이 논문을 참고해주세요.
3. Loss
본 논문에서는 contrastive learning 기반의 loss를 사용합니다. contrastive learning이란 같은 성질(e.g. class)을 갖는 대상의 feature는 가깝게, 다른 성질을 갖는 대상의 feature는 멀게 하는 학습 방법을 말합니다. 쉬운 예로, 강아지 사진들의 feature들끼리는 서로 비슷해야 하지만, 고양이 사진의 feature와는 다르도록 학습하는 것입니다.
위의 예시처럼 class, 즉 label이 있는 경우에는 굉장히 쉽게 constrastive learning 프레임워크를 생각할 수 있습니다. label 같으면 가깝게, 다르면 멀게 하면 됩니다. 하지만 본 논문은 Unsupervised pretraining 방법을 제안합니다. ScanNet 같은 indoor scene의 point cloud가 주어졌을 때, 어떻게 constrastive learning 구조를 만들 수 있을까요?
FCGF(Fully Convolutional Geometric Feature)
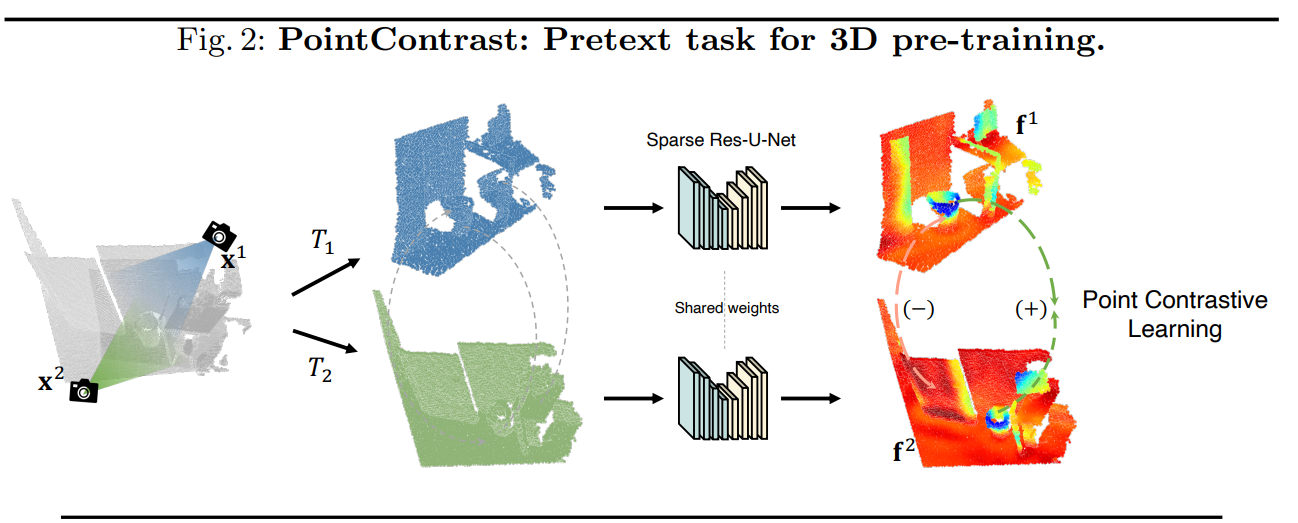
갑자기 FCGF? 부자연스럽게 등장하긴 했지만, 본 논문의 unsupervised contrastive learning 프레임워크의 기반이 되는 논문입니다. FCGF는 pretraining과 관련된 논문이 아니고, point cloud registration 문제를 위한 feature를 fully convolutional network를 통해 얻는다는 것을 처음 제안한 논문입니다. point cloud registration은 아래 그림과 같이 겹치는 영역이 있는 두 point cloud가 주어졌을 때, 같은 곳에 대응되는 point끼리 matching하는 문제입니다. 이 때 같은 곳에 대응되는 point의 feature는 유사하고, 다른 곳에 대응되는 point끼리는 feature가 다르다면 matching을 찾기가 아주 쉬워지겠죠!! 자연스럽게 위에서 설명드린 contrastive learning 프레임워크가 떠오르셨을 것입니다!! 이를 point-wise constrastive learning이라고 하겠습니다. PointContrast 역시 FCGF에서 제안한 point-wise contrastive learning 방식을 이용하고 있고, 이는 아래 그림에 잘 나타나 있습니다.
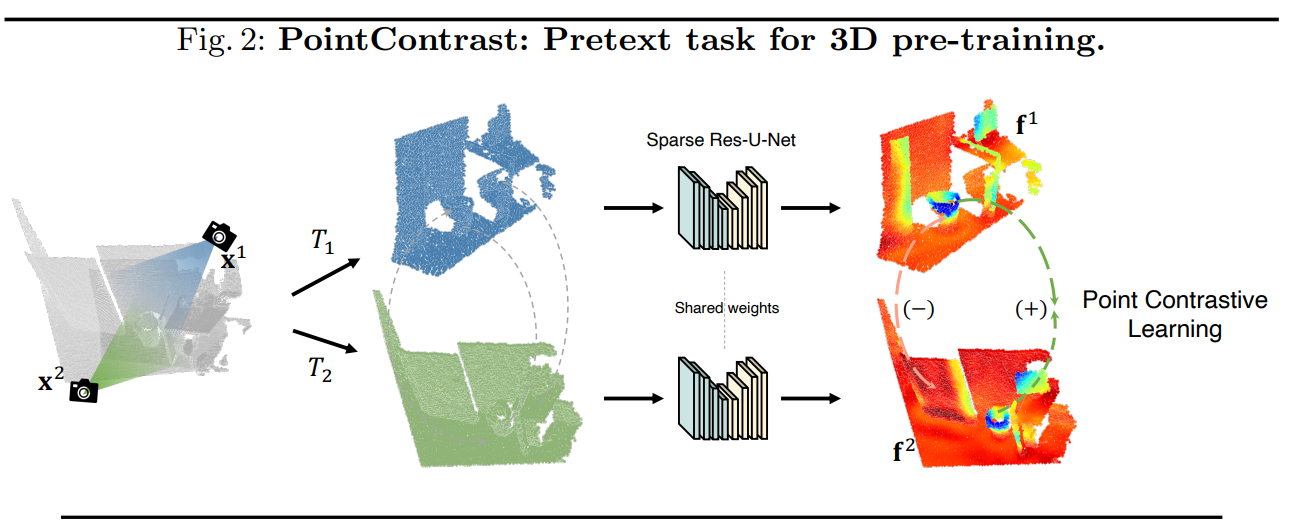
point-wise contrastive learning을 registration이 아니라, pretraining에 활용해보면 어떨까?
가 이 논문의 출발점입니다. FCGF를 학습시킬 때 label은 필요가 없고, 겹치는 영역이 있는 point cloud pair만 있으면 됐었습니다!! FCGF는 registration을 목적으로 했기 때문에, 위 사진 예시처럼 처음부터 pair 형태로 주어진 registration 데이터셋(Match3D)을 사용했습니다. 하지만 Pre-training은 좀 더 방대한 데이터셋을 필요로 합니다. 그래서 위에서 언급했던 ScanNet을 쓰기로 하였고, pair로 주어진 데이터셋이 아니라면 pair를 직접 만들면 됩니다!! ScanNet 데이터 각각을 2가지의 다른 view에서 바라볼 때 얻을 수 있는 point cloud를 만들어서 pair로 만들면 위 그림의 Match3D와 다를 것이 없게 됩니다(위 그림의 카메라 아이콘 2개가 이를 나타냅니다!). 이제 대응되는 point pair(positive pair), 대응되지 않는 point pair(negative pair)를 이용해 contrastive learning을 위한 loss를 설계하면 되겠습니다. 본 논문에서는 2가지 loss를 제안합니다.
1. Hardest-Contrastive Loss
이 loss는 FCGF 논문에서 제안한 loss들 중 가장 좋은 성능을 보인 loss입니다. contrastive learning에서 일반적으로 사용하는 contrastive loss에 hard negative mining을 곁들인 loss입니다.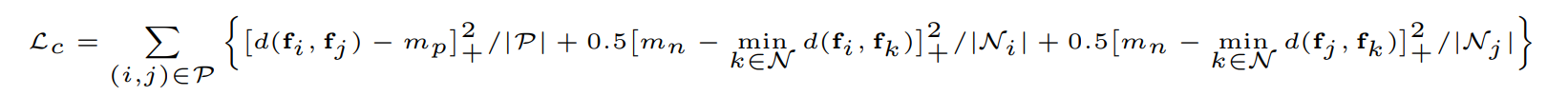
먼저 집합 을 살펴보면, 는 positive pair의 집합입니다. positive pair는 2개의 view에서 matching되는 point의 쌍입니다. 예를 들어 위 부엌 그림에서 의자 왼쪽 모서리 point는 2가지 view에 모두 존재하고, 이것이 positve pair가 됩니다. 은 random하게 sample된 negative point, 즉 matching이 이루어지지 않는 point들의 집합입니다.
이제 loss term들을 하나씩 설명드리겠습니다.
- 첫 번째 loss term인 는 positive pair인 두 point의 feature 사이의 거리가 margin 이하로 가까워지도록 유도하는 loss입니다. 괄호 안의 값이 0보다 작아지면 0으로 clamping하는 역할을 하는 때문에 가 보다 작아지면 loss가 발생하지 않습니다. 이 를 (positive)
margin이라고 합니다. - 두 번째, 세 번째 loss term은 동일한 형태를 지니고 있는데요, negative pair인 두 point의 feature가 멀어지도록 유도하는 loss입니다. 이 (negative)
margin의 역할을 하고 있고, 두 feature의 거리가 보다 커지면 더 이상 loss가 발생하지 않습니다.
여기서 가장 중요한 부분은 입니다. 이 부분이 이 loss의 이름이 Hardest contrastive loss인 이유가 됩니다. negative point 중 feature 거리가 가장 가까운 point를 loss 계산에 사용합니다. 거리가 멀어야 할 negative인데 가장 가깝다는 것은 가장 어려운 negative sample이라는 의미가 됩니다. 즉 가장 어려운 negative sample만을 loss 계산에 사용하는 것이죠. normalize에 사용된 는 에 의해 0으로 clamping되지 않은 pair의 개수입니다. 즉 실질적으로 loss 계산에 사용한 pair의 개수로 normalize해주는 것입니다.contrastive learning에서 negative mining, 즉 loss 계산에 사용할 적절한 negative pair를 선택하는 것은 아주 중요한 문제입니다. 일반적으로 positive pair는 class가 동일한 것 끼리 pair를 만들거나, point cloud의 경우 같은 위치에 대응되는 point pair로 정해지므로 수가 적습니다. 하지만 negative pair는 다른 class를 갖는 데이터끼리 pair를 만들면 되기 때문에 경우의 수가 훨씬 더 많이 생깁니다. point cloud의 경우에도 matching되는 point보다 matching되지 않는 point의 쌍을 만드는 것이 훨씬 쉽죠. 그래서 positive pair는 loss 계산에 사용하지만, negative pair는 적절히 선택할 필요가 있습니다. 이 때 단순히 random하게 선택하는 것이 아니라, 구분이 어려운(feature 거리가 가까운) negative pair를 선택해서 loss 계산에 사용하게 되고, 이를 hard negative mining이라고 합니다.
2. PointInfoNCE Loss
InfoNCE loss는 Representation learning with contrastive predictive coding이라는 논문에서 제안된 loss입니다. InfoNCE loss는 contrastive learning을 classification 문제 세팅으로 풀어내는 loss라고 볼 수 있습니다. 먼저 loss 식을 보겠습니다.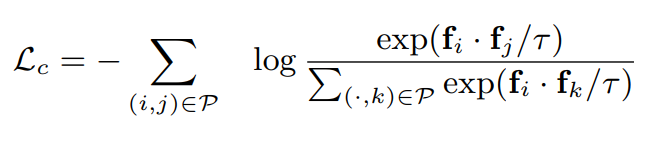
softmax에 log.. Cross Entropy Loss가 떠오르는 형태입니다! exponential 괄호 안에 들어간 값만 feature 사이의 inner product 값으로 바뀐 것이라고 보면 되겠습니다. 이 loss를 이용해 학습하게 되면 positive pair의 feature inner product는 커지고, negative pair의 feature inner product는 작아지게 될 것임을 쉽게 파악할 수 있습니다.
추가적으로, 이 loss를 계산할 때는 matching이 존재하지 않는 point는 아예 사용하지 않고(이를 negative로 사용했던 Hardest Contrstive Loss와 달리), matching이 존재하는 pair들만 사용합니다. 헷갈리실 수 있으니 예를 들어 설명해보겠습니다. 1번 pair (i, j), 2번 pair (k, l)이 있다고 해보겠습니다. point i에 대해서 positive pair는 j가 되고, negative pair는 k 또는 l이 될 수 있습니다. point k에 대해서는 positive pair는 l이 되고 negative pair는 i 또는 j가 될 수 있습니다. 즉 pair들로만 batch를 구성해도, 자신이 속한 pair의 point가 아니면 사실 다 negative로 볼 수 있기 때문에 loss 계산에 문제가 없습니다.
PointInfoNCE Loss는 Hardest Contrastive Loss에 비해 계산이 간단하고, negative가 많아서 mode collapsing에 보다 robust하다고 합니다. Hardest Contrstive Loss에서는 가장 어려운 negative만을 loss 계산에 사용한 데 반해, PointInfoNCE loss에서는 수식에 자연스럽게 모든 negative pair를 포함시키게 됩니다.
Conclusions
실험 파트는 결국 Pre-training을 통해 다양한 데이터셋, 다양한 task(segmentation, detection)에서 성능이 올라갔다는 것이 대부분이라 생략했습니다. PointContrast에서 제안한 pre-training방법으로 얻을 수 있는 feature가 좋은 generelization 능력을 보여준다고 볼 수 있겠습니다.
읽어주셔서 감사드립니다. 틀린 내용 혹은 논문에 대해 궁금한 점이 있으시면 댓글 부탁드립니다.
References
[1] Xie, Saining, et al. "Pointcontrast: Unsupervised pre-training for 3d point cloud understanding." European Conference on Computer Vision. Springer, Cham, 2020.
[2] Qi, Charles R., et al. "Pointnet: Deep learning on point sets for 3d classification and segmentation." Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
[3] Dai, Angela, et al. "Scannet: Richly-annotated 3d reconstructions of indoor scenes." Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
