
시작하기에 앞서 나는 블로그를 작성하는 것이 익숙해지기 전까지 TIL을 "Today I Learned"가 아닌 "This week I Learned"로 정의하고 매주 최소 한 번씩 기록해보려고 한다.
Numpy
arange와 linspace
- np.arange() : N만큼 차이나는 숫자 생성
- 구간, 간격 강조할 때 사용하면 코드 가독성 높임 - np.linspace() : N 등분한 숫자 생성
- 개수 강조할 때 사용하면 코드 가독성 높임
인덱싱 (indexing) 슬라이싱
-
기존의 배열의 index에 1차원 배열이나 2차원 배열을 넣으면 기존 배열에 있는 해당 위치의 값이 새로운 배열의 값으로 들어감
# a 배열 생성 a = np.arange(8)**2 # i 1차원 배열 생성 i = np.array([1, 1, 3, 5]) # j 2차원 배열 생성 # a 배열의 index로 j를 삽입하여 출력 j = np.array([[3, 4], [2, 5]])
데이터 합치기
- np.vstack() : axis=0(열) 기준으로 쌓음
- np.hstack() : axis=1(행) 기준으로 쌓음
# a, b는 2차원 데이터 np.vstack((a, b)) np.hstack((a, b))
데이터 쪼개기
-
np.hsplit() :
- 숫자 1개가 들어갈 경우 x개로 등분- 리스트로 넣을 경우 axis=1 기준 인덱스로 분할
# [2,6] => [2,2] 데이터 3개로 등분 np.hsplit(a, 3) # a를 3번째 열 ~ 4번째 열 미만 기준으로 분할하여 3개의 array를 반환 np.hsplit(a, (3, 4))
Pandas
데이터 필터링
- .isin() : 각각의 요소가 데이터프레임 또는 시리즈에 존재하는지 확인 (True/False)
# Pclass 변수의 값이 1일 경우, True/False 값 반환 titanic.Pclass.isin([1]) - .isna() : 결측값은 True, 아니면 False
- .notna() : 결측값은 False, 아니면 True
- .sort_values(by='col_name', ascending=True/False) : col_name열을 기준으로 정렬
결측치 제거
- .dropna( ) : 결측 값이 들어있는 행 전체 삭제
- .dropna(axis=1) : 결측 값이 들어있는 열 전체 삭제
- .notna( ) : 결측 값은 False 반환, 그 외에는 True 반환
데이터 통계
- agg() : 여러 개의 열에 다양한 함수를 적용
titanic.agg({"Age" : ["min", "max", "median", "std"], "Fare" : ["min", "max", "mean", "median"]}) - group_by() : 그룹별 집계
# 성별을 묶은 다음, 생존율의 평균 구하기 titanic.groupby(["Sex", "Pclass"])[["Age", "Fare"]].mean()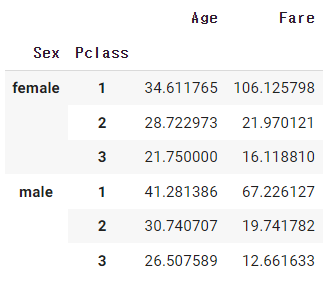
- value_counts() : 개수 구하기
# 클래스 별 인원 수 구하기 titanic.Pclass.value_counts()
fancy indexing
- 전체 데이터에서 원하는 일부의 데이터를 찾아오는 방법
df.loc[row에 대한 조건, col에 대한 조건] - boolean indexing과 함께 자주 쓰인다 (boolean masking)
vlookup in Pandas
- 단일요건 merge() : how 위치에 on 기준으로 시트 결합
- on에 list를 넣으면 다중요건으로 결합 가능df.merge(df2, how='left', on='음료') - merge_asof() : 유사일치를 통해 범위로 병합
- 기준이 되는 열은 항상 오름차순으로 정렬# 사이즈와 종류는 정확히 일치시키고 수량은 범위로 병합한다 df = pd.merge_asof(df1, df2, on='수량', by=['사이즈', '종류']) - concat() : 데이터프레임 결합
- join = inner : col이 교집합으로 결합- join = outer : col이 합집합으로 결합
데이터 가공 (feature engineering)
- 기존 데이터로 더 유용한 새로운 특성(feature)을 만드는 것
- rank() : 등수 매기기
- astype() : 자료형 바꾸기 (바꿀 수 없는 자료형이면 에러 발생)
- cut() : 데이터를 구간별로 나눠서 범주화(categorizing) 하는 함수
# 구간 분류해 지정한 레이블을 부여하기 pd.cut(s, [0, 70, 80, 90, 100], labels=['F', 'C', 'B', 'A']) - apply() : 함수를 적용하게 해주는 함수
- lambda 함수와 자주 같이 쓰인다# 답안 col의 문자열을 뒤집어 역순 col에 넣기 df['역순'] = df['답안'].apply(lambda x: x[::-1])
데이터 시각화 라이브러리 (matplotlib, Seaborn)
Matplotlib (자주 쓰이는 함수 & 파라미터 모음)
# 그래프 보이기
1. plt.show()
# 앞의 리스트는 x, 뒤의 리스트는 y축의 값
2. plt.plot([1, 2, 3, 4], [1, 4, 9, 16])
# x, y축에 대한 레이블 표시
3. plt.xlabel('label') & plt.ylabel('label')
# 데이터의 종류 표시, plot()에 label 파라미터 값으로 삽입
4. plt.legend()
# 축 범위 지정
5. xlim([min, max]), ylim([min, max]), axis([xmin, xmax, ymin, ymax])
# 타이틀 설정
6. plt.title('title', loc='center', pad=10)
# 눈금 표시
7. plt.xticks(), plt.yticks()
# 한 좌표 평면 위에 여러 개 그래프 시각화
8. plt.subplots(row, column, index) : Seaborn (자주 쓰이는 함수 & 파라미터 모음)
# 데이터 불러오기
1. sns.load_dataset('dataset')
# 그래프 객체 생성 (여러 그래프 한번에 표시)
2. fig = plt.figure(figsize=(15, 5))
ax1 = fig.add_subplot(1, 2, 1)
ax2 = fig.add_subplot(1, 2, 2)
# 그래프 제목 설정
3. ax1.set_title('title1')
ax2.set_title('title2')그래프의 종류는 다른 게시물에 작성해놓았습니다
Python EDA 데이터 시각화 라이브러리 - 그래프의 종류
느낀점 및 회고
python 기초 과정을 끝내고 이번주 부터는 python EDA에 대한 수업이 시작되었다.
데이터 분석쪽은 처음 접해보아서 방대한 양을 모두 익히는 것이 매우 벅찼고 조금이라도 미루면 걷잡을 수 없는 상황이 올 것 같아 악착같이 집중했다. 그래도 다행히 개념들은 잘 이해 되어서 쓰이는 함수들과 파라미터들을 익히는 것에 집중할 수 있었다.
다양한 시각화를 통해 가공된 데이터를 여러 모양과 색깔로 확인할 수 있어서 상당히 재미있기도 하고 더 다양한 데이터를 내가 원하는대로 가공해보고 싶다는 열정도 생겼다.
2주 뒤에 시작될 첫 팀프로젝트를 위해 그 전까지 배운 내용들을 계속해서 복습하고 어느정도 능숙하게 쓸 수 있게 연습해서 프로젝트에 팀의 아이디어를 많이 구현할 수 있도록, 그리고 완성도 있게 끝낼 수 있도록 노력해야겠다.

좋은 글 감사합니다. 자주 방문할게요 :)