
시작하기에 앞서 나는 블로그를 작성하는 것이 익숙해지기 전까지 TIL을 "Today I Learned"가 아닌 "This week I Learned"로 정의하고 매주 최소 한 번씩 기록해보려고 한다.
이번주는 Python EDA 프로젝트를 진행하기 전 주로 그동안 배웠던 numpy, pandas, seaborn 지식들을 바탕으로 여러 데이터셋에 적용해보며 분석을 진행하였다.
EDA에는 목적에 따라 분석 방법이 조금씩 다르다.
데이터 분석을 위한 EDA와 ML 전처리를 위한 EDA가 있다.
데이터 분석을 위한 EDA
공공데이터 상권 정보를 이용해
1. 필요한 데이터를 추출
# 사용할 column을 찾기 위해 데이터의 일부를 사용
df = data[:10000]
# sampling
df = data.sample(n=10000, random_state=42)
data = data[['상호명', '상권업종대분류명','상권업종중분류명', '시도명']]2. 각 지역별 음식점(한식) 비율을 계산
areas = data['시도명'].unique()
for area in areas :
sido = data.loc[data['시도명']==area]
sido_kor = sido.loc[sido['상권업종중분류명'] == '한식']
print(f'{area} 한식 비율 : {len(sido_kor) / len(sido) * 100: .2f}%')3. 한식 음식점들이 많이 사용하는 단어 찾기 (PeCab)
- Pecab은 Mecab의 python 버전으로 형태소 분석기 중 하나다. (tokenization)
from pecab import PeCab
from tqdm.auto import tqdm
from collections import Counter
pecab = PeCab()
corpus = data.loc[data['상권업종중분류명'] == '한식', '상호명']
tokenized_corpus = []
# tqdm은 progress bar를 보여주는 라이브러리
for doc in tqdm(corpus) :
tokenized_corpus.append(pecab.nouns(doc))
total_tokens = []
for tokens in tqdm(tokenized_corpus) :
total_tokens = total_tokens + tokens
# 각 단어가 몇 번씩 등장했는지
counter = Counter(total_tokens)를 진행하였다.
ML 전처리를 위한 EDA
titanic 데이터를 이용해
1. 결측치가 존재하는지 확인
titanic[titanic.isnull().any(axis=1)]2. dtype이 obeject인 column이 있는지 확인
titanic.columns[titanic.dtypes == 'object']3. target value(예측 대상)의 distribution이 어떻게 되는지 확인
titanic.Survived.value_counts()
sns.countplot(data=titanic, x='Survived', palette='Pastel1')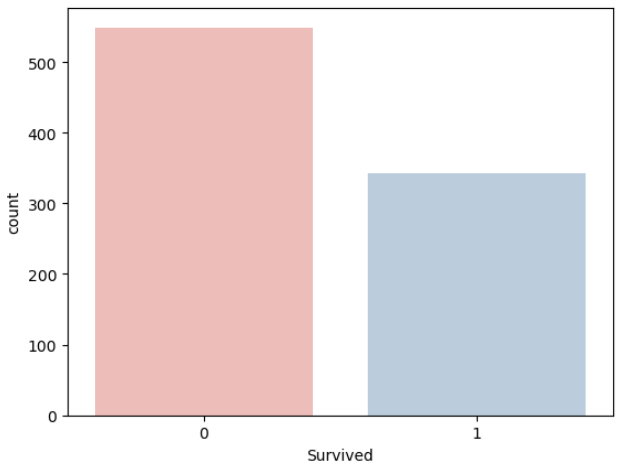
4. correlation matrix heatmap
corr = titanic.corr()
sns.heatmap(data=corr, annot=True, fmt='.3f', cmap='Blues')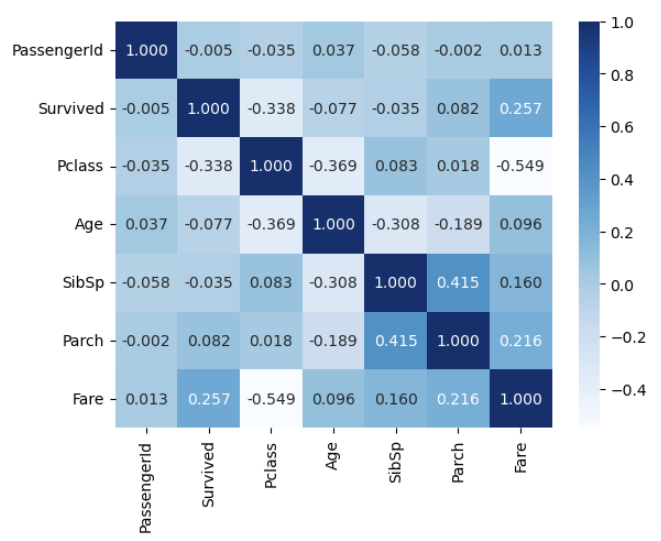
5. 결측치에 대한 EDA
1) 결측치에 대한 전처리
# Cabin -> is_cabin
# Age --> Age의 평균값
# Embarked --> drop
# True/False를 1/0으로 바꾸기
titanic['is_cabin'] = ~titanic.Cabin.isnull() * 1
# na 평균값으로 채우기
titanic.Age = titanic.Age.fillna(titanic.Age.mean())
titanic = titanic.drop(columns=['PassengerId', 'Name', 'Ticket', 'Cabin'])
titanic = titanic.dropna()2) dtype이 object인 column들에 대한 전처리
# Ordinal Encoding (숫자로 변환)
# factorize (순서대로 변환)
titanic.Sex = pd.factorize(titanic.Sex)[0]
titanic.Embarked = pd.factorize(titanic.Embarked)[0]를 진행하였다.
느낀점 및 회고
EDA 강의를 진행해 주셨던 김용담 강사님께서 EDA를 잘하려면 다음이 중요하다고 조언을 해주셨다.
- 파이썬을 잘 하는 것이 중요
- 전처리 기법들에 익숙
- 분석하고 찾고싶은 것을 구현하는 능력
- 아이디어
- 인사이트를 도출하는 능력
- 잘하는 사람들의 EDA를 보면 효율적으로 공부할 수 있음
지금까지 나는 구현을 잘 해내는 것이 중요한 코딩을 해왔다면 EDA를 배우고 나서는 데이터를 보고 인사이트를 잘 도출해 내는 것이 중요하다는 것을 직접 경험할 수 있었다. 스스로 생각하고 그래프로 확인을 하는 과정이 너무 어렵지만 조언 해주신대로 여러 EDA를 보고 그들의 생각 과정을 따라가다 보면 익숙해질 것이라고 생각한다.
EDA 수업이 다 끝난 지금도 나는 자신있게 EDA를 잘 한다고 얘기는 못한다. 그러나 다음주부터 시작되는 프로젝트에 적극적으로, 열심히 참여하며 배웠던 부분들을 최대한 적용시켜서 배운 것들을 잘 익힐 수 있도록, 그리고 완성도 있는 결과물을 낼 수 있도록 노력 할 것이다.
