네트워크 Application Layer
앞서 네트워크 입문 1에서 실제로 패킷이 다음 라우터에 도달할 때의 속도는 빛의속도라고 했다.
또한 패킷의 비트들이 다음 라우터에 도달한다고 해서 물 흐르듯이 다음 라우터로 가는 게 아니라 패킷이 모두 도달한 뒤, 다음 라우터로 간다고 했다.
패킷이 한 묶음으로 가는 것이 패킷 교환 방식이고, 4가지 문제점(딜레이)과 해결 방법에 대해 얘기했다.
이번 시간에는
TCP/IP 4계층의 전체적인 클라이언트-서버 아키텍처와 전송계층의 특징 일부분을 알아보자.
Client - Server Architecture
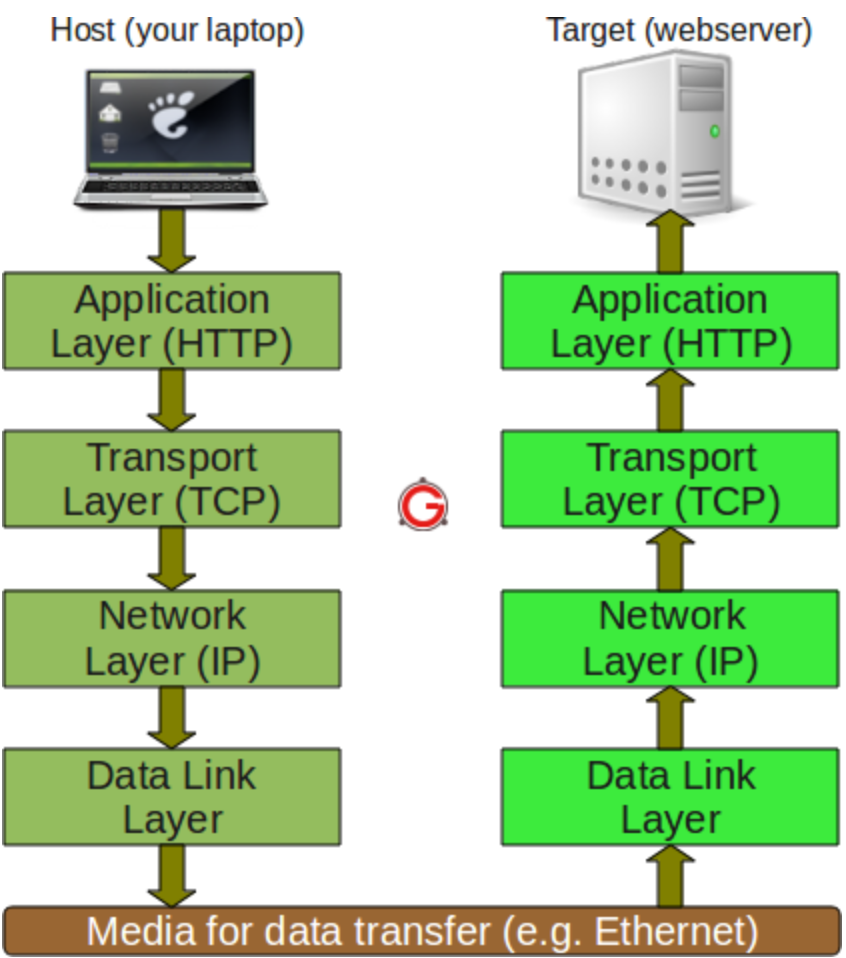
서버의 특징부터 살펴보자. 서버는 우리가 흔히 아는 웹서버를 기준으로 풀어보자.
서버의 특징은 뭘까?
..........
우리가 어디에 있던 스마트폰으로 사파리를 켜서 네이버에 들어갈 수 있는 것처럼, 웹 서버는 항상 켜져있다.
이 말은 고정된 IP 주소를 갖고, 고정된 포트 번호를 사용한다는 얘기다.
그래야 클라이언트(우리들) 입장에서 서버가 어디있는지 알아내기 쉽고 언제든지 찾아갈 수 있다.
예를 들어보자.
서버라는 교수님이 있고, 주소라는 장소가 있다.
교수님이 계신 장소는 공학관 304호로 고정되어 있어야 클라이언트(우리들)이 찾아갈 수 있다.
만약 교수님(서버)이 계신 장소가 102호, 201호, 강당 등으로 계속 바뀐다면? 우리들은 찾아갈 수 없다.
정리하면 서버의 특징은
1) 항상 켜져있다.
2) 고정된 IP 주소와 Port 번호를 갖는다.
그렇다면 클라이언트는?
서버와는 반대로 유동적인 IP 주소를 가진다.
실제로 Google, Naver와 같은 웹 서버에 연결하기 위해서는 클라이언트가 서버의 IP Address, Port Number를 알아야 한다.
이를 외우는 게 번거롭기 때문에 IP 주소를 도메인(naver.com)으로 변환한다.
웹 서버의 포트번호는 80으로 사용하는 게 일반적인 약속이다.
서울대, 고려대, 연세대의 컴퓨터 공학을 가르치는 교수님은 공학관 304호(포트번호)에 있다라는 예시처럼 클라이언트들이 찾아가기 쉽게 포트 번호를 대부분 80으로 약속을 했다.
즉, 구글 아마존 네이버와 같은 웹 서버는 포트 번호를 80으로 사용하고 있다.
www.naver.com:80에서 80이 생략된 형태다.
참고로 여기서 www는 2차 도메인으로 네이버에서 만들어낸 도메인 주소다.
클라이언트와 서버는 어떻게 통신을 할까?
애플리케이션 계층에서 서버의 프로세스와 클라이언트의 프로세스의 소통은 소켓 인터페이스(Socket API)를 사용한다.
즉, 서로 소켓의 주소를 알고 있어야 한다.
IP 주소의 경우는 어떤 컴퓨터인지
Port 번호는 해당 호스트(컴퓨터)의 많은 프로세스 중 어떤 프로세스인지
확인하기 위해 필요한 정보들이다.
여기서 전송계층의 TCP/UDP에 따라 TCP Socket, UDP Socket 두 가지 타입으로 분류된다.
TCP Socket API를 살펴보자.
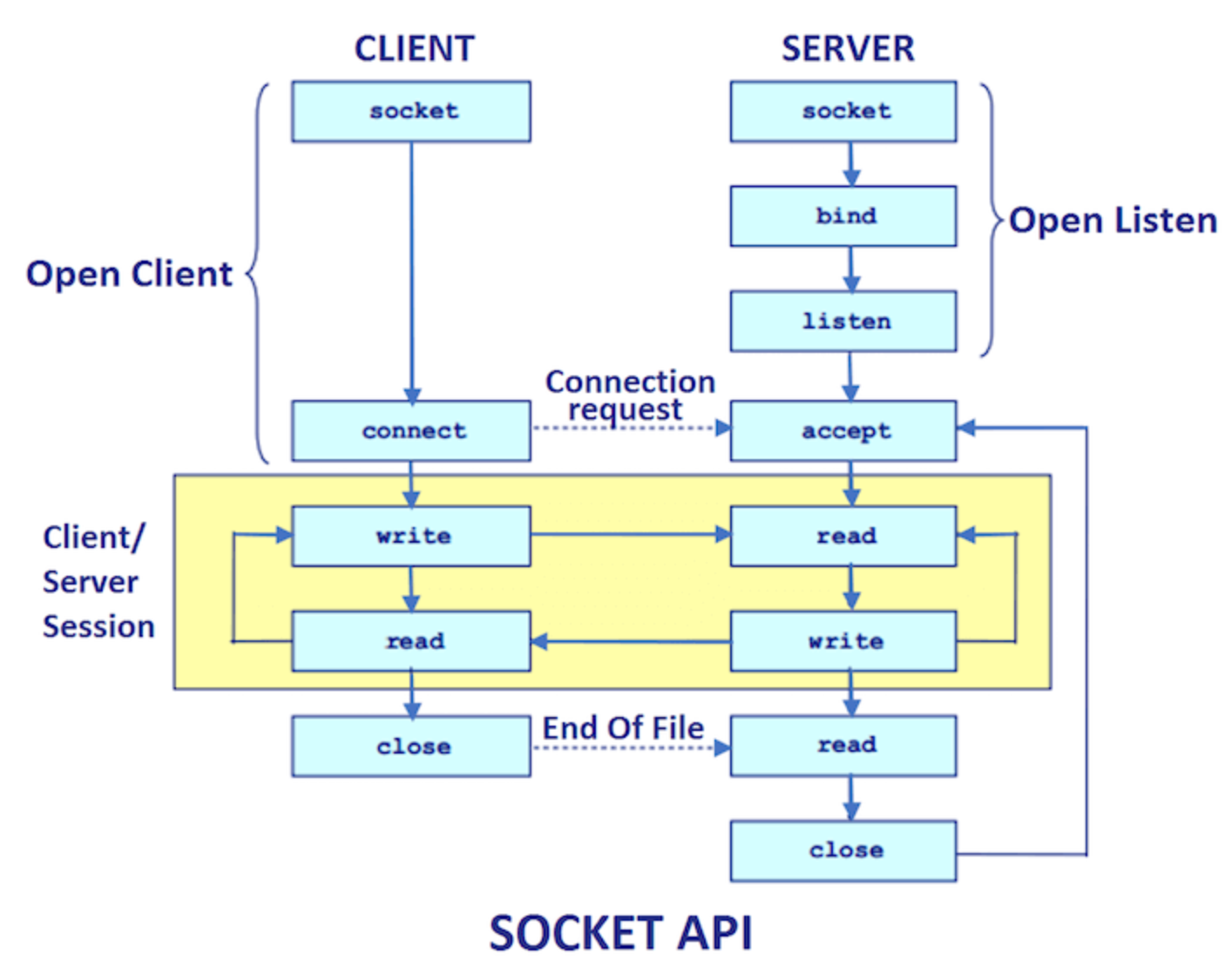
우측 그림의 서버부터 살펴보면
서버는 소켓을 생성하는데 이 때 TCP Socket / UDP Socket을 선택한다.
이 때 소켓함수의 파라미터에는 도메인, TCP/UDP Socket Stream(소켓 종류), 프로토콜이 필요한데 선택해서 넣을 수 있다.
서버는 소켓을 생성한 뒤, 특정 포트에 bind 시킨다. 아까 웹 서버는 80번 포트를 사용한다고 했다.
그리고 listen 상태를 거쳐, accept 상태가 된다.
여기서 부터 서버는 blocking 상태다.
즉, 클라이언트쪽에서 커넥션할 때까지 기다린다.
자 그럼 클라이언트 측을 보자.
클라이언트도 마찬가지로 소켓함수를 사용해서 TCP or UDP 소켓을 생성한다.
하지만 서버처럼 특정 포트에 바인드 시키지는 않는다. 왜냐?
클라이언트는 서버처럼 특정 포트가 아닌, 많은 포트 중에 하나를 골라 쓰면 되기 때문에 특정할 필요가 없다.
그리고 connect를 통해 서버와 연결고리를 생성한다.
그 후 서버와 클라이언트간의 데이터를 주고 받는 write, read 과정이 반복된다.
마지막으로 close를 시키는데, 이 때 한동안은 운영체제쪽에서 소켓을 바로 release 시키지 않고
특정 딜레이를 가진 후 릴리즈 시킨다.
이는 TCP의 4-way handshake와 연관되어 있는데, 전송 계층을 따로 포스팅 할 예정이니 그 때 자세히 알아보자.
각 계층의 데이터 타입
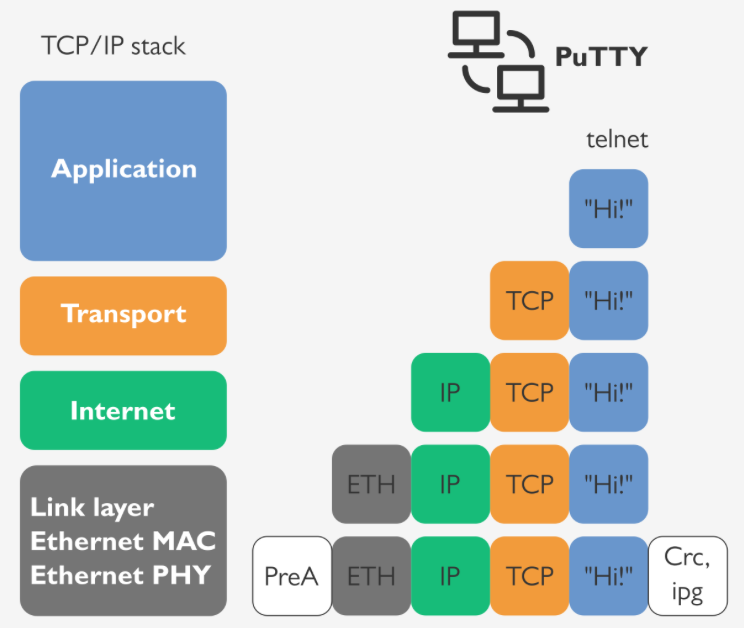
우선 상단의 애플리케이션 계층은 메세지(Message)라는 데이터 타입을 갖는다.
보내고자 하는 HTTP 메세지가 담기는 부분이다.
HTTP(Hypertext Transfer Protocol)
HTTP는 애플리케이션 계층이다. 따라서 실제 HTTP 메세지가 교환되기 이전에 TCP Connection이라는 것을 해야한다.
TCP Connection을 사용하는 방식에 따라 두 가지로 나뉘게 된다.
1) 연결성(Keep Alive) 방식
HTTP 메세지를 주고 받고도 TCP Connection을 연결한다.
2) 비연결성 방식
HTTP 메세지를 주고받은 후 TCP Connection을 해제한다.
HTTP는 대표 특성이 비연결성이며, 무상태(stateless), HTTP 상태 코드와 메서드 그리고 헤더를 가진다.
HTTP 비연결성의 장점
비연결성의 특징은 한 번 맺은 연결을 끊는다.
왜냐면 HTTP는 인터넷 상에서 불특정 다수의 통신 환경을 기반으로 설계되어 있기 때문이다.
만약 서버에서 다수의 클라이언트와 연결을 계속 유지해야 한다면 많은 네트워크 리소스가 발생하게 된다.
따라서 연결을 유지하기 위한 리소스를 줄이면 더 많은 연결을 할 수 있다.
HTTP 비연결성의 단점
서버는 클라이언트를 기억하고 있지 않으므로(Stateless, 무상태) 동일한 클라이언트의 모든 요청에 대해
매번 새로운 연결을 시도하고 해제하는 과정을 거쳐야 하므로 오버헤드가 발생한다.
무상태를 해결하기 위해 쿠키와 세션 그리고 토큰을 사용하는 OAuth, JWT와 같은 개념도 나왔다.
하지만 HTTP, TCP Connection만으로도 내용이 방대하니 이런 방식이라는 점만 우선 알아두자.
이렇게 애플리케이션에서 만들어진 Message는 다음 계층인 Transport Layer(전송 계층)으로 보내진다.
그럼 Application Layer에서 Transport Layer에 원하는 기능은?
TCP 연결은 신뢰성 기반이다.
특성을 나열해보면
- 신뢰성(Message가 보낸 그대로 도착, 데이터 무결성)
- 순서를 지킴
- Flow Control(흐름 제어)
- Congestion Control(혼잡 제어)
애플리케이션 계층은 전송 계층에게 메세지가 보낸 그대로 타겟 애플리케이션 계층으로 도착하는 신뢰성을 원한다.
그럼 이제 전송계층의 TCP가 어떻게 신뢰성을 기반으로 전송하는지 알아보자.
전송 계층
전송 계층의 단위는 세그먼트다.
이는 바로 위 계층인 애플리케이션 계층에서 내려온 메세지를 데이터(Data) 부분에 담아 패키징해서 만들어진다.
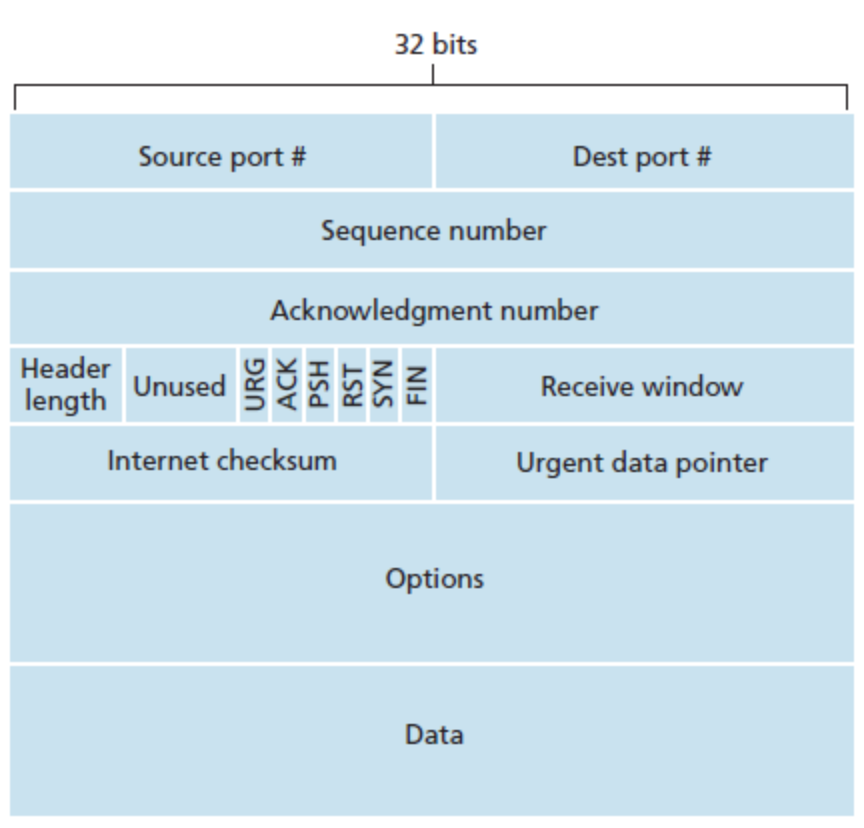
TCP와 UDP의 세그먼트 구조는 다르다.
우선 TCP/UDP가 모두 가지는 특성은 Multiplexing, Demultiplexing 이 있다.
애플리케이션 계층에서 내려온 다양한 네트워크 프로세스들로부터 메세지가 들어오면 세그먼트로 저장해 밑 계층으로 전달한다.
참고로 각 네트워크 프로세스(혹은 스레드)는 소켓을 갖고 있다.
즉, 멀티플렉싱이란 애플리케이션 계층에서 패킷이 소켓에 의해 전송계층으로 전달될 때, 여러 소켓의 패킷을 수집하여 하나의 세그먼트에 캡슐화하여 네트워크 계층으로 전달하는 과정이다.
각 계층을 지날 때마다 포장하고, 포장하고 포장하는 과정의 연속이라고 생각하자.
또 수신측에서는 포장을 풀고, 풀고.. 결국 목적지 소켓에 도달하게 된다.
디멀티플렉싱은 반대로 수신측에서는 데이터를 받을 때 해당 소켓에 제대로 전달해야 하는데 이 때 헤드에 들어있는 포트번호를 확인해서 전달한다.
세그먼트의 구조를 보면 Data 영역을 제외한 헤더에 Source Port Number, Dest Port Number가 각각 16bit로 할당되어 있다.
이 필드에 적힌 값으로 멀티플렉싱과 디멀티플렉싱이 가능해진다.
Source Port Num은 자신의 포트 번호이며, Dest Port Num은 상대의 Port 번호다.
참고로 세그먼트 헤더의 source port, dest port의 범위는 각각 16bits 이므로 0~65536 범위를 가진다.
TCP와 UDP의 차이
TCP는 보내는 쪽의 Source IP / Source Port와 수신 측의 Dest IP / Dest Port를 가지고 어떤 소켓으로 보낼지 결정한다.
하지만 UDP의 경우 Dest IP / Dest Port만을 통해 어떤 소켓으로 올릴지 디멀티플렉싱을 진행한다.
따라서 UDP는 보내는 쪽의 IP와 포트번호가 없기 때문에 데이터가 정확하게 전달됐는지, 중간에 에러나 유실이 발생했는지 파악하기 힘들다.
(UDP 세그먼트 헤더에도 체크섬 필드는 있지만 모든 에러나 유실을 판단하긴 힘들다)
현재 IP에 대해서는 언급하지 않았으니, UDP는 신뢰성을 보장하지 않는 프로토콜이다 라고만 알아두자.
지금 보면 세그먼트의 헤더가 굉장히 중요한 역할을 해주고 있다.
예를 들어 편지를 보낸다고 생각해보자.
우편 배달부는 편지의 내용을 보고 전달할까?
아니다. 편지 봉투에 적힌 것을 보고 판단한다.
편지 봉투에 해당하는 내용이 세그먼트의 헤더이고, 데이터 부분에는 실질적으로 호스트가 보낸 Message가 들어있다.
다음 시간에는 전송계층 TCP가 제공하는 신뢰성 전달에 대해 더 알아보자.
정리
- 서버의 특징은 항상 켜져있고, 대부분 고정된 IP와 고정된 Port를 가진다
- 클라이언트와 서버가 통신을 할 땐 TCP Connection을 해야하며, 소켓 인터페이스를 사용한다.
- 애플리케이션 계층은 메세지라는 타입의 데이터를 갖고, 전송계층은 메세지를 패키징한 세그먼트를 갖는다.
- 전송계층 헤더에는 Source Port, Dest Port가 있으며 이를 통해 멀티플렉싱과 디멀티플렉싱이 가능하다.
- TCP는 Source IP/Source Port/Dest IP/Dest Port로 신뢰성 기반 통신을 하며
UDP는 Dest IP/Dest Port만 가지고 데이터를 전송한다. - 따라서 TCP는 신뢰성이 있다고 말하며, 반대로 UDP는 헤더의 Checksum 필드를 통해 에러 체킹정도만 가능하다.
