(와아~ 벨로그 첫 게시글~~)
회사에서 작업을 자동화하기 위해서 Python을 사용하게 하는데 주로 csv나 엑셀 파일로 작업하기 때문에 아무래도 Pandas를 쓰게 된다. 그러나 문제는! 비전공자에 올해 처음 파이썬을 시작한 내가 너무 초짜라는 것이다. 짤 줄 아는 코드가 for문과 if문을 이용해서 반복문 돌리기 정도인데 Pandas에서는 왠만하면 for문을 돌리지 않는 것이 좋다는 것을 이번에 처음 알았다는 것이다! 그것도 for문을 두 개나 겹쳐서 돌리고 있으니 시간이 너무 오래 걸려서 이것을 도대체 어떻게 해결해야 하나 싶었다...
구글 검색을 진짜 열심히 해봤고 검색할 때 pandas two for loops 이런 식으로 검색을 하다보니 for문을 여러 개 겹친 걸 "nested for loops"라고 한다는 걸 알게 됐다. 검색어를 이렇게 바꾸자마자 검색의 질이 확 달라지더라. 역시 구글링도 방법을 알아야 잘 하게 되는 것...for문이 여러 개 겹친 것이 마치 둥지를 튼 것 같아서 그렇게 부르나보다.
사실 지금도 해결책을 완전히 찾았다고 하기엔 어려운데, 나와 같은 어려움을 겪고 있는 사람은 많지만 내 케이스에 해당되는 답변은 없었기 때문이다...그래서 직장 동료에게 도움을 받아서 일단은 코드를 작성해놓은 상태이다.
반복문을 돌릴 파일이 기껏해야 1000행 정도면 상관 없는데 이것이 몇 십, 몇 백만으로 확대되어야 하니까 for문을 두 개 돌리게 되면 시간이 어마어마하게 많이 들더라는 말이다ㅠ 그래서 일단은 내가 찾은 해결책을 적어두려고 한다. Numba와 같은 라이브러리 사용 말고 근본적으로 해결하는 방법을 말이다!
# Nested for loops
for i in range(len(df1)):
for j in range(len(df2)):
if df1[col1][i] == df2[col2][j]:
df2.loc[i, col1] = df1[col1][i]
내가 작업하려던 코드는 대략 이런 내용을 담고 있다. 두 개의 데이터프레임을 가지고 어떤 조건을 충족시키면 df1의 값을 df2의 값으로 변경하는 식이다. 그런데 이렇게 for문을 두 개 겹쳐서 돌리면 데이터프레임의 행이 많으면 많을수록 코드 돌아가는 데에 걸리는 시간이 기하급수적으로 늘어난다. 내가 가지고 있던 df1은 1200행이었고 df2는 81000행이었는데 여기에 조건도 3개를 걸어뒀더니 이 작업 완료하는데만 30분이 걸렸다...ㅠ 그런데 df2는 테스트용으로 81000행을 넣어본 것이고 나중에 300만 행짜리 파일을 돌린다고 하니까 동공에 지진이 난 것이다. 아니 그러면 그거 돌리는데 일주일은 걸리는 것 아니야??? 그래서 급하게 직장 동료에게 도움을 요청했다는 그런 이야기....
???: "iterrows()와 itertuples() 써보면 안되나요?"
iterrows와 itertuples 모두 데이터프레임을 iterate, 그러니까 쉽게 말하면 모든 행의 값을 확인할 수 있게 해주는 함수인데 기능이 조금 다르고 성능도 다르다고 한다. 구글 검색을 통해 스택오버플로우를 뒤져보면 iterrows는 느리니까 사용하지 말라는 글이 정말 많더라. itertuples가 훨씬 빠르니 itertuples를 사용하라고 한다. 그 이유를 찾아보면 iterrows는 series를 반환하고, itertuples는 named tuple을 반환하기 때문에 series를 반환하는 iterrows가 더 느린 것이라고 한다.
하지만 내 문제에서는 이 함수들을 사용하는 것으로는 해결되지 않았다. 왜냐하면 저 두 함수가 iteration을 빠르게 만들어주기는 하지만 nested for loops의 근본적인 시간 문제를 해결해줄 수는 없었기 때문이다...찾아보고 함수 사용법을 익히긴 했지만 내 문제를 해결해주지는 못해서 많이 슬펐다 흑흑...
List 활용하기!
이 문제는 리스트로 해결했다. 리스트가 정말 빠르긴 하더라. 제 문제를 해결해주신 직장 동료님 정말 고맙습니다ㅠ
조건을 걸어서 for문 돌릴 생각 하지 말고, 값을 입력해줄 컬럼의 index에 맞춰서 리스트를 만들고 그 리스트를 한꺼번에 컬럼에 대입하는 방법이다. 예를 들어서
df1 = pd.DataFrame([['Sam','Tom','Mike','Dan'],
['Michael','Elizabeth','Vicky','Kim'],
['Chris','Tom','Sam','Vicky'],
['Kim','Mike','Ash','Ray']],
columns=['A', 'B', 'C', 'D'])
df2 = pd.DataFrame([['Adrian','Trust','Fahrah','Daniel', 'Ben'],
['Mike','Elizabeth','Christian','Travis', 'Ash'],
['Ben','Sam','Tom','Kim', 'Brandon'],
['Kim','Peace','Ash','Ray', 'Guy']],
columns=['V', 'W', 'X', 'Y', 'Z'])
일부러 조금 난잡하게 만들었다. df1과 df2는 이런 형태일 것이다.
df1:
df2: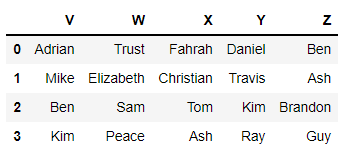
df1의 컬럼 A B C D의 값을 조건에 따라 변경하고 싶다고 하자. df1의 어떤 값이 df2['V']의 값과 같을 때 그 값을 nan값으로 변경하는 것이다. 예를 들어 df2['V'][3]의 값은 'Kim'인데 df1['A']에도 'Kim'이 존재한다. 그러면 그 값을 NaN값으로 바꿔주는 것이다.
# 평소라면 작성했을 코드:
for i in range(len(df2)):
for j in range(len(df1)):
if df2['V'][i] == df1['A'][j]:
df1.loc[j, 'A'] = np.nan
elif df2['V'][i] == df1['B'][j]:
df1.loc[j, 'A'] = np.nan
elif df2['V'][i] == df1['C'][j]:
df1.loc[j, 'A'] = np.nan
elif df2['V'][i] == df1['D'][j]:
df1.loc[j, 'A'] = np.nan
이런 느낌으로...아주 지저분한 코드가 완성됐을 것이다. 지금 가지고 있는 데이터프레임은 행 수가 적기 때문에 이렇게 해도 시간이 오래 걸리지 않을 것이다. 하지만 크기가 큰 데이터들은 이렇게 하면 정말정말정말 오래 걸린다. 그렇기 때문에 리스트를 이용해서 값을 한번에 바꿔치기 할 것이다.
이렇게 길어질 줄 몰랐는데...생각보다 길어져서 다음 게시글에 적도록 할 것이다!
