지도학습(Supervised Learning)
👉 정답(label)이 있는 데이터를 학습시키는 것이다. 입력값(X)에 대한 목적변수(Y)를 학습시키며, 지도학습은 목적변수(Y, label, 반응변수)의 형태에 따라 분류 혹은 예측으로 구분된다.
- 분류 : Y가 이산형(혹은 명목형)변수로, 고정된 값을 가질 때
- ex) 남/녀, 유/무, 정상/비정상, 긍정/중립/부정, MBTI ..
- 예측 : Y가 연속형 변수로, 어떠한 값도 가질 수 있을 때
- ex) 키, 몸무게, 연봉, 수치형태의 변수 ..
(👀 반면, 비지도학습은 데이터에 대한 명시적인 정답없이, 데이터 그 자체로 학습을 진행하는 방법임)
수치 예측을 위한 머신러닝
✔️ 활용영역
- 주식 가격 예측 / 경제 지표 예측 / 제품 판매량 및 가격 변화 예측 / 대출 채무 불이행에 대한 손실금액 예측 / 고객 LTV 예측 / 상품구매 가능성 예측 / 인구통계에 따른 의료비 증감 예측 등
✔️ 수치예측 알고리즘 종류
-
회귀분석(Regression Analysis)
-
의사결정트리 (Decision Tree)
-
인공 신경망 분석 (Artificial Neural Network)
-
랜덤포레스트 (Random Forest)
1️⃣ 회귀분석(Regression Analysis)
🔎 회귀분석
: 연속형 목적변수(Y)와 설명변수(X)의 관계를 함수식으로 모형화하는 기법
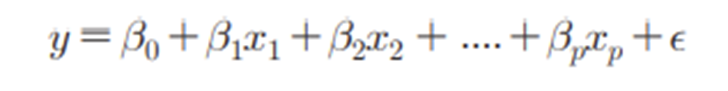
-
B0,B1,…,Bp는 데이터로부터 추정해야 하는 회귀계수이며, ε은 오차항이다.
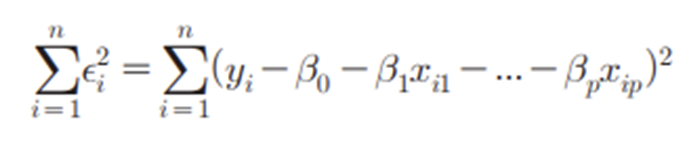
-
머신러닝에서 훈련 데이터 세트가 주어졌을 때, 오차의 제곱합을 최소로 만드는 B0, B1,…,Bp를 찾아서 함수식을 도출한다. (학습)
-
훈련데이터를 학습시킨 뒤, 테스트데이터를 통해 결과값을 확인하며 성능을 평가한다
-
모형구축의 단순성, 해석의 명료성 때문에 선형회귀분석을 주로 사용하며, 적절치 않은 경우, 변환(로그변환, 제곱근변환, 다항식 접근 등)을 취해 적절히 선형회귀모델화 가능하다.
-
f(x) 가
- 선형함수인 경우 -> 선형회귀분석
- 독립변수가 1개인 경우 -> 단순선형회귀분석
- 독립변수가 여러개인 경우 -> 다중선형회귀분석
- 로비스트가 함수인 경우 -> 로지스틱 회귀분석 (단, 이 경우는 Y가 이산형 변수임)
- 비선형 함수인 경우 -> 비선형 회귀분석
(선형회귀모형만큼 쉽지 않으며, 실질적으로 은닉층이 없는 인공신경망과 수학적으로 동일하기 때문에, 인공신경망 기법 등의 기법을 사용함)
➕ 장점
- 모형구축의 단순성, 해석의 명료성
- 각 독립변수의 영향력 파악하기 쉽다
- 빠른 훈련 시간
➖ 단점
- 결측치, 이상치에 민감
- 단순한 모형에 적합하는 경향이 있어 복잡한 데이터를 예측할 때는 정확도가 떨어진다
2️⃣ 의사결정트리(Decision Tree)
🔎 의사결정트리 분석
: 수치예측 목적의 의사결정트리는 목표변수(Y)의 평균, 표준편차, 절대편차와 같은 통계치의 불순도를 이용하여 마디를 분리시킨다.
- 분류목적(분류나무), 수치예측목적(회귀나무) 둘 다 사용될 수 있다.
- 목표변수(Y)의 평균 차이가 가장 두드러지게 나타나는 분리점을 사용한다.
➕ 장점
- 분류 및 수치예측 모두 활용 가능
- 결측치가 있는 데이터 효과적으로 처리 가능
- 선형성, 정규성, 등분산성 등의 가정이 필요없는 비모수적 모형임.
- 어떤 입력변수(X)가 목표변수(Y)에 영향력이 높은지 등의 통찰력을 얻을 수 있음
- 모형의 결과 이해가 쉽고, 분류결과의 이유를 설명하기 유용함.
➖ 단점
- 연속형 입력변수를 비연속적 값으로 취급하므로, - 예측오류 가능성 있음.
- 모형식을 수립해야 하는 경우 적용이 어려움.
- 훈련데이터에 대한 변경이 발생할 경우, 분류 결정 논리에 큰 변화를 가져옴.
- 쉽게 과적합화 되거나 과소적합 될 수 있음.
- 트리가 너무 커질 경우 패턴 이해하기가 쉽지 않음.
3️⃣ 랜덤포레스트 (Random Forest)
🔎 랜덤포레스트
: 여러 개의 다양한 의사결정트리를 만들어 각 의사결정트리의 예측결과를 합쳐 최종 결과를 결정하는 앙상블 형태의 기법
- 트리들의 상관성을 최소화하기 위해, 각 분할에서 사용되는 설명변수(X)들의 수(m개)는 전체 설명변수(X)의 개수(p개)보다 작다.
- 일반적으로 수치예측에서는 한 트리에서 p/3개의 설명변수를 사용한다.
- 어떤 랜덤 표본에는 약한 설명변수로 분할하는 경우도 있기 때문에, 상관성을 줄이게 되고, 트리들의 예측값 평균은 더 안정적으로 된다.
➕ 장점
- 분류문제(분류나무) 및 수치예측(회귀나무) 모두 활용 가능
- 대용량 데이터 처리에 효과적
- 과대적합 문제 최소화하여 모델의 정확도 향상
➖ 단점
- 데이터 크기에 비례해서 수백~수천개의 트리를 형성하기 때문에 학습 및 예측에 오랜시간이 걸림
- 생성하는 모든 트리 모델을 다 확인하기 어렵기에 해석력 떨어짐
4️⃣ 인공신경망(Artificial Neural Network)
🔎 인공신경망 분석
: 인간의 뉴런 작용에서 모티브를 얻은 기법으로, 입력 노드와 은닉 노드, 출력 노드를 구성하여 복잡한 분류나 수치예측 문제를 해결할 수 있도록 하는 분석 기법 (블랙박스 기법)
-
출력 활성함수 : 은닉층에서 최종 목표변수(출력노드)로 결과값을 결합하여 변환하는 활성함수
-> 수치목적에서는 목표변수가 제한된 범위가 없기 때문에 출력활성함수로 항등함수를 사용한다. -
목적함수 : 은닉층과 은닉마디 수가 결정되면, 계수값을 찾기 위해 목적함수(오차함수)를 최소화하는 문제를 해결한다.
-> 수치목적에서는 오차제곱합(SSE)를 목적함수로 사용한다
➕ 장점
- 입력변수(X)와 목적변수(Y)가 연속형이나 범주형인 경우 모두 처리 가능하여 다양한 분야에 적용가능
- 복잡한 데이터에 대해서도 좋은 결과 가능
- 예측력 우수하고, 견고하고 안정적인 기법
➖ 단점
- 최적의 모형을 구현하는 것이 상대적으로 어려움
- 도출된 입출력 변수의 연관관계에 대한 설명이 어려움
- 충분한 데이터 필요