지도학습(Supervised Learning)
👉 정답(label)이 있는 데이터를 학습시키는 것이다. 입력값(X)에 대한 목적변수(Y)를 학습시키며, 지도학습은 목적변수(Y, label, 반응변수)의 형태에 따라 분류 혹은 예측으로 구분된다.
- 분류 : Y가 이산형(혹은 명목형)변수로, 고정된 값을 가질 때
- ex) 남/녀, 유/무, 정상/비정상, 긍정/중립/부정, MBTI ..
- 예측 : Y가 연속형 변수로, 어떠한 값도 가질 수 있을 때
- ex) 키, 몸무게, 연봉, 수치형태의 변수 ..
(👀 반면, 비지도학습은 데이터에 대한 명시적인 정답없이, 데이터 그 자체로 학습을 진행하는 방법임)
분류를 위한 머신러닝
✔️ 활용영역
- 고객 구매여부 예측 / 질병 발생여부 예측 / 고객이탈,유지 예측 / 스팸메일 분류 / 만족도 예측 등
✔️ 분류목적 알고리즘 종류
-
K-최근접 이웃(K-Nearest Neighbor)
-
의사결정트리 (Decision Tree)
-
랜덤포레스트 (Random Forest)
-
인공 신경망 분석 (Artificial Neural Network)
-
서포트 벡터 머신 (Support Vector Machine or Support Vector Regression)
-
나이브 베이즈 (Naive Bayes)
1️⃣ K-최근접 이웃(K-Nearest Neighbor)
🔎 K-최근접 이웃 기법 (K-NN)
-
K-최근접 이웃 기법은 특정 데이터 좌표점과 다른 나머지 데이터 좌표점들간의 거리가 가장 가까운 K개 점들의 목적변수(Y)값을 참조하여 분류예측을 하는 기법이다.
-
특정한 가설이나 모형 없이 주어진 데이터를 통해 범주의 분류결과만 판단한다.
-
데이터세트 간의 '유사성'을 측정하는 방법과 목표변수(Y) 범주를 분류할 때 주변 데이터 세트 몇개(K) 를 기준으로 분류할 것인가가 중요하다.
➕ 장점
- 알고리즘 이해가 쉽고 직관적
- 사전 모형 설정 및 가정이 필요 없음
- 빠른 훈련(학습) 시간
➖ 단점
- 모형이 없으므로, 가설검증이나 분석을 통한 통찰력을 얻기 어려움
- K(근접한 점들의 개수)에 대한 명확한 기준 없으며 시행착오적 접근 필요
- 느린 분류(예측) 시간
->새로운 데이터가 주어질 때마다 모든 데이터와의 유사성 계산해야 하므로 그만큼 시간 소요(Lazy Learning으로도 불림) - 많은 메모리 소요(대용량 데이터일 때 불리)
🌼 활용분야
- 몇몇의 단점에도 불구하고 산업에서 활발히 활용되고 있다.
- 온라인 상품 및 서비스 추천시스템 / 영화 선호도 예측 / 특정 단백질 발현을 위한 유전체 데이터 패턴 확인 / 이미지 또는 영상으로 구성된 광학적 문자인식(OCR) / 안면인식과 같은 컴퓨터 비전응용 분야
2️⃣ 의사결정트리 (Decision Tree)
🔎 의사결정트리
-
목표변수(Y)와 연관성이 높은 설명변수(X)의 순서대로 불순도나 엔트로피 등이 낮아지는 방향으로 트리의 가지를 분할하면서 뿌리노드부터 잎노드까지 분류규칙을 만들어 내는 기법 (분할 정복 기법)
-
각 노드가 iF-then의 형태로 분기되므로, 각 데이터의 속성값이 주어졌을 때 어떤 카테고리로 분류되는지 쉽게 파악할 수 있다.
➕ 장점
- 분류문제(분류나무) 및 수치예측(회귀나무) 모두 활용 가능
- 결측치가 있는 데이터 효과적으로 처리 가능.
- 선형성, 정규성, 등분산성 등의 가정이 필요없는 비모수적 모형임.
- 어떤 입력변수(X)가 목표변수(Y)에 영향력이 높은지 등의 통찰력을 얻을 수 있음
- 모형의 결과 이해가 쉽고, 분류결과의 이유를 설명하기 유용함.
➖ 단점
- 연속형 입력변수를 비연속적인 값으로 취급하므로, 예측오류 가능성 있음.
- 모형식을 수립해야 하는 경우 적용이 어려움.
- 훈련데이터에 대한 변경이 발생할 경우, 분류 결정 논리에 큰 변화를 가져옴.
- 쉽게 과적합화 되거나 과소적합 될 수 있음.
- 트리가 너무 커질 경우 패턴 이해하기가 쉽지 않음.
🌼 활용분야
- DB마케팅, CRM, 시장조사, 광고조사, 의학연구, 품질관리 등의 다양한 분야에서 활용
- 고객 타겟팅, 고객 신용점수화, 고객 행동예측, 고객세분화, 시장 세분화, 신상품 분석, 광고효과측정 등
3️⃣ 랜덤포레스트 (Random Forest)
🔎 랜덤포레스트
- 여러 개의 다양한 의사결정트리를 만들어 각 의사결정트리의 예측결과를 합쳐 최종 분류 결과를 결정하는 앙상블 형태의 기법
➕ 장점
- 분류문제(분류나무) 및 수치예측(회귀나무) 모두 활용 가능
- 대용량 데이터 처리에 효과적
- 과대적합 문제 최소화하여 모델의 정확도 향상
➖ 단점
- 데이터 크기에 비례해서 수백개~수천개의 트리를 형성하기 때문에 학습 및 예측에 오랜 시간이 걸림
- 생성하는 모든 트리 모델을 다 확인하기 어렵기에 해석력 떨어짐
🌼 활용분야
- 질병 분류, 금융 사기 검출, 콜센터 통화량 예측, 특정 주식 손익 예측 등
4️⃣ 인공 신경망 분석 (Artificial Neural Network)
🔎 인공신경망 분석 (ANN)
- 인간의 뉴런 작용에서 모티브를 얻은 기법으로, 입력 노드와 은닉 노드, 출력 노드를 구성하여 복잡한 분류나 수치예측 문제를 해결할 수 있도록 하는 분석 기법 (블랙박스 기법)
➕ 장점
- 입력변수(X)와 목적변수(Y)가 연속형이나 범주형인 경우 모두 처리 가능하여 다양한 분야에 적용가능
- 복잡한 데이터에 대해서도 좋은 결과 가능
- 예측력이 우수하고, 견고하고 안정적인 기법
➖ 단점
- 최적의 모형을 구현하는 것이 상대적으로 어려움
- 도출된 입출력 변수의 연관관계에 대한 설명이 어려움
- 충분한 데이터 필요
🌼 활용분야
- 재무, 회계, 마케팅, 생산 등의 분야에서 다양하게 활용
- 특히, 재무분야에 대한 응용연구는 매우 활발(주가지수예측, 기업신용평가, 환율예측 등)
5️⃣ 서포트 벡터 머신 (SVM or SVR)
🔎 서포트 벡터 머신 (Support Vector Machine or Support Vector Regression)
- 서로 다른 분류에 속한 데이터 간의 간격(마진)이 최대화가 되는 평면을 찾아 분류하는 기법 (선형 및 비선형)
➕ 장점
- 오류데이터에 대한 영향이 적고, 과적합을 피할 수 있음
- 신경망 모델보다 사용하기 쉬움
- 저차원이나 고차원의 적은 데이터에서 일반화 능력이 좋음
➖ 단점
- 해석이 어렵고 복잡한 블랙박스 형태임
- 여러개의 조합 테스트가 필요
- 느린 훈련(학습) 시간
- 고차원으로 갈수록 계산 부담, 스케일링에 민감
🌼 활용분야
- 이미지 및 영상을 분류하는 작업
- 화합물 및 단백질 구분(의학 분야에 유용하게 사용)
6️⃣ 나이브 베이즈 (Naive Bayes)
🔎 나이브 베이즈
- 베이즈정리에 근거하여, 목적변수(Y)가 발생할 조건부확률(P(A|B))을 사전 확률(P(A))과 우도 함수(P(B|A))의 곱으로 표현하여 어떤 분류항목에 속할지 확률이 높게 계산되는 쪽으로 분류하는 기법.
- 목표변수(Y)의 범주를 학습시키기 위해 베이즈 정리를 사용한다.
- 베이즈 정리(Bayes theorem) : 특정 사건이 발생할 확률을 다음과 같은 형태로 표현
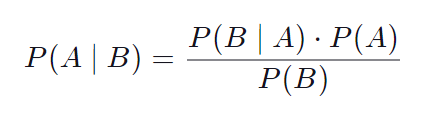 * 사전확률 P(A) : 이미 알고 있는 사건(들) 확률
* 사전확률 P(A) : 이미 알고 있는 사건(들) 확률
* 우도 P(B|A) : 이미 알고 있는 사건A(들)이 발생했다는 조건 하에, 다른 사건B이 발생할 확률
*사후확률 P(A|B): 사건 B가 일어났을 때 사건A가 일어날 확률, 사전확률과 우도확률을 통해서 알게되는 조건부확률 - 이때 모든 관측 값은 서로 다른 관측 값과 통계적으로 독립적으로 발생한다고 가정 (별다른 확신 없이 가정 하므로 Nave 모형이라고 부름)
➕ 장점
- 개념과 이론이 단순하고 계산이 빠름
- 노이즈 및 결측치가 있어도 잘 수행됨
- 고차원의 데이터 세트에 적합함
➖ 단점
- 모든 속성이 동등하게 중요하고 독립적이라는 결함가정에 의존함
- 독립변수(X)들이 범주형이 아닌 수치형일 경우 정확성이 떨어짐
- 범주 분류문제에는 적합하나, 예측된 범주의 확률 값을 활용해야 할 경우에는 적합하지 않음
🌼 활용분야
- 스팸메일 분류 (주로 텍스트 데이터 등에 근거한 문서 분류에 많이 사용됨)
- 침입자 검출 / 이상행동 검출 / 컴퓨터 네트워크 진단 / 질병 진찰 / 이탈 예측 / 민원 예측 등의 분야에도 활용되고 있음