
안녕하세요! 메랜샵 개발자로서 좌충우돌 개발 및 운영을 하고있는 이삭입니다.
지난번 검색 자동완성 최적화에 대한 이야기에 이어, 이번에는 서버의 확장없이 성능과 사용자 경험을 끌어올렸던 경험을 공유해 보려고 합니다.
사이트가 느려요!
서비스를 운영하다보면 개발자의 등골을 서늘하게 만드는 문장이 있습니다. 바로 '사이트가 느려요!' 라는 사용자 피드백입니다. 저희 팀 역시 최근 사용자가 늘어나면서 특정 API 의 응답 속도가 눈에 띄게 저하되는 현상을 인지했습니다.
특히 사용자가 많이 몰리는 인기 사냥터의 거래글 목록을 조회하는 API 에서 두드러지게 나타났었습니다.
결론부터 말하자면 저희는 데이터가 쌓일수록 점점 더 느려지는 이 문제를 해결하기 위해 DB 인덱스와 로컬 캐시라는 두 가지 무기를 사용했습니다.
두 가지 이야기를 한 번에 풀기에는 내용이 너무 길어져, 이번 포스팅에서는 인덱스를 활용해 쿼리 성능을 극적으로 개선한 과정을 먼저 자세하게 공유해 보려고 합니다.
문제 상황: 너무 느린 조회 API
사용자가 인기 지역의 거래글 목록을 볼 때, 서버는 DB 에 아래와 같은 SQL 쿼리를 보내고 있었습니다.
SELECT * FROM trade
WHERE region = ? -- 특정 지역
AND create_at >= ? -- 특정 시간 이후에 생성된 글
AND deleted = false -- 삭제되지 않은 글
ORDER BY create_at DESC; -- 최신순으로 정렬이 쿼리는 아주 단순합니다.
trade 라는 테이블에서 특정 지역의 특정 시간 이후에 생성됐으면서 삭제되지 않은 게시글을 찾아 최신순 으로 보여주는 역할을 하죠.
하지만 이 간단해 보이는 쿼리가 왜 느렸을까요?
바로 DB가 풀 테이블 스캔을 하고 있었기 때문입니다.
trade 테이블에 거래글이 적을 때는 괜찮았지만, 이후 데이터가 많아질수록 조회 시간은 계속 길어졌습니다.
그리고 개선하기 전에 우선 비교를 위해 부하테스트를 진행했습니다.
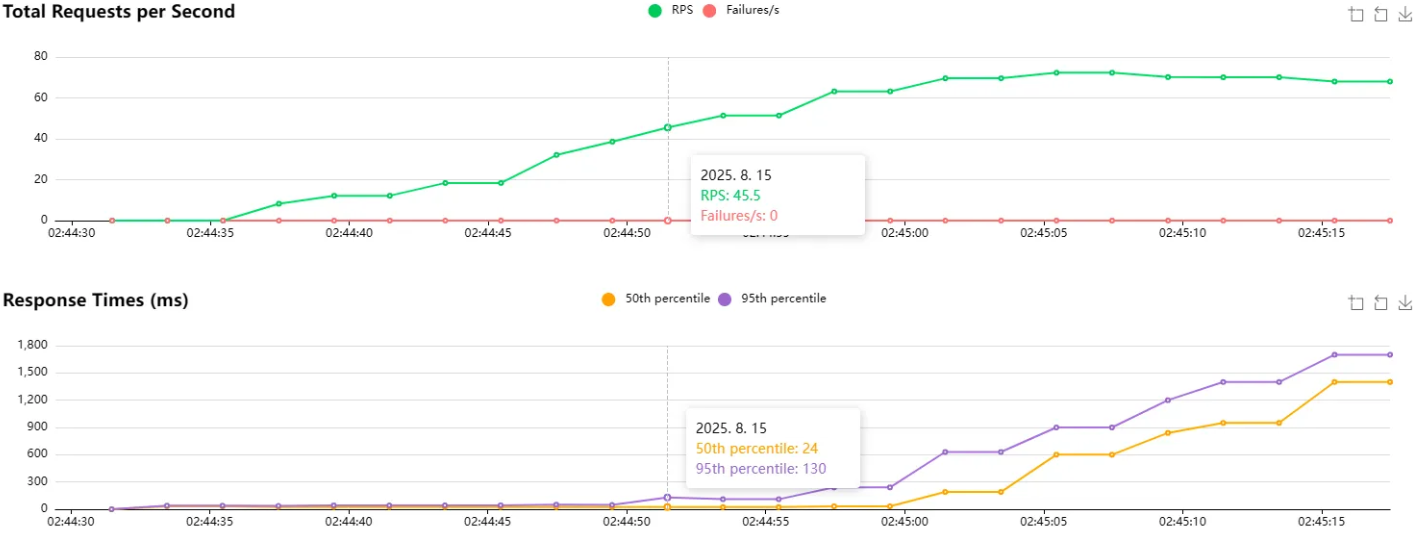
45 RPS 부터 DB에서 병목현상이 조금씩 나타나는 것을 확인했습니다.
구원자, 인덱스의 등장

이 문제를 해결할 첫 번째 열쇠는 바로 인덱스(Index)였습니다.
인덱스는 모든 내용을 다 담고 있지는 않지만, [찾을 내용, 실제위치] 의 쌍으로 이루어진 별도의 데이터 구조를 미리 만들어 두는 것입니다.
DB는 인덱스를 통해 매우 많은 데이터 속에서도 단 몇 번의 탐색만으로 원하는 데이터가 어디 저장되어 있는지 정확하게 찾아낼 수 있습니다. 풀 테이블 스캔처럼 모든 데이터를 다 뒤지는 대신, 잘 정리된 목차를 보고 원하는 페이지로 바로 점프하는 것과 같습니다.
하지만 공짜 점심은 없듯이 인덱스에게도 트레이드오프가 존재합니다.
읽기 속도는 빨라지지만, 쓰기 속도는 느려지기에 쓰기 빈도가 높은 서비스에서는 오히려 성능 저하를 불러올 수 있습니다.
단일 인덱스의 예상치 못한 함정 - Random I/O
풀 테이블 스캔을 해결하기 위해, WHERE 절의 핵심 조건인 region(지역) 컬럼에 단일 인덱스를 생성했습니다.
CREATE INDEX idx_trade_region ON trade (region);그리고 곧바로 부하테스트를 진행했습니다.
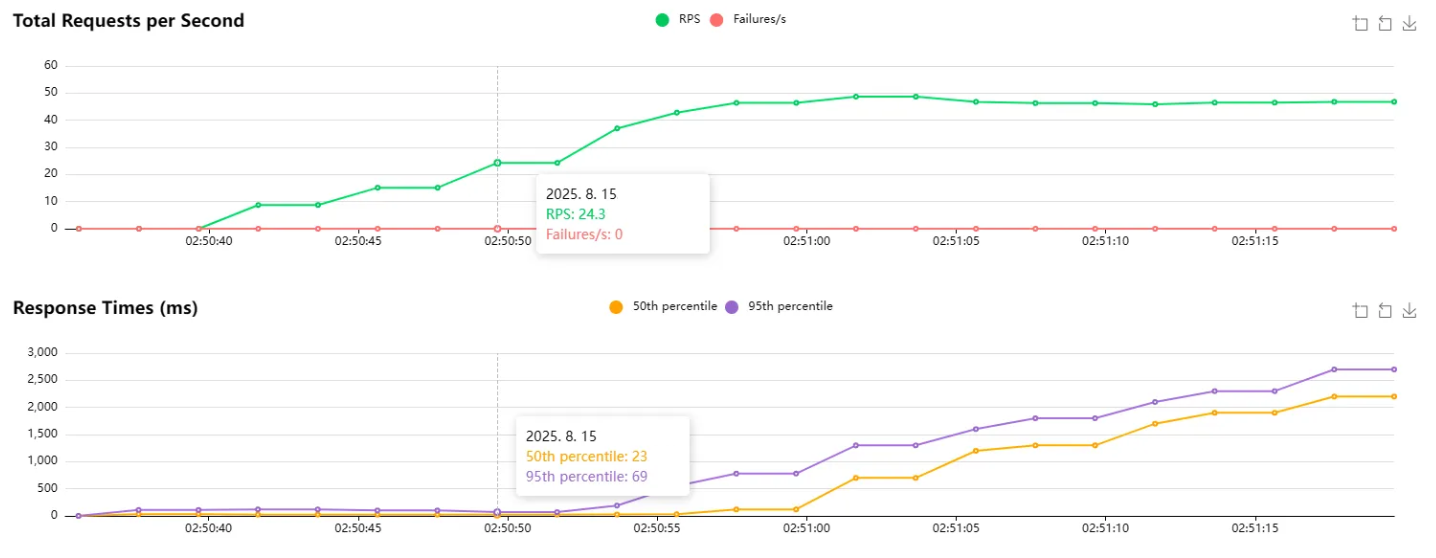
그런데 여기서 예상치 못한 일이 벌어졌습니다.
인덱스를 추가하기 전보다 오히려 성능이 더 나빠진 것입니다!
분명 인덱스를 사용하기 전에는 45 RPS 부터 병목현상이 일어났었는데
인덱스를 사용하고 나니 24 RPS 부터 병목현상이 일어나는 것입니다...
왜 단일 인덱스가 성능을 떨어뜨렸을까?
이 현상의 원인을 파악하기 위해 두 상황의 실행 계획을 비교해보았습니다.
- 인덱스 없을 때:
Using where; Using filesort - 단일 인덱스 적용 후:
Using index condition; Using where; Using filesort
둘 다 filesort 가 발생하는 건 같았지만, 부하 테스트에서는 인덱스 버전이 더 느렸습니다.
filesort 란 무엇인가?
filesort는 인덱스를 통해 정렬을 처리할 수 없을 때, DB가 별도의 메모리 공간이나 디스크를 사용해 데이터를 직접 정렬하는 작업을 의미합니다. 이는 데이터량이 많을 경우 I/O 부하가 커질 수 있습니다.
추가 분석 결과, 인덱스를 통해 찾은 데이터들이 실제 테이블에서 무작위로 흩어져 있어 Random I/O 가 대량 발생하는 것이 주원인이었습니다.
핵심: 풀 스캔은 느리지만 Sequential I/O로 안정적이었고, 단일 인덱스는 적어진 데이터를 읽지만 Random I/O로 인해 더 불안정했습니다.
Random I/O와 Sequential I/O의 성능 차이에 대해서는 다른 포스팅에서 자세히 다루겠습니다.
단일 인덱스의 또 다른 함정 - filesort
단일 인덱스가 성능을 저하시킨 또 다른 이유는 정렬 문제였습니다.
idx_trade_region 인덱스는 다음과 같이 동작했습니다.
- 인덱스 사용:
region = ?조건으로 해당 조건에 맞는 행을 빠르게 찾음 - Random I/O 발생: 찾은 행들의 실제 데이터를 읽기 위해 테이블 곳곳을 접근
- 정렬 작업 필요: 가져온 데이터들이
create_at순서가 아니므로 별도 정렬 필요 - filesort 실행: 조건에 맞는 행을 메모리(또는 디스크)에서 정렬

결과적으로 풀 테이블 스캔은 없앴지만, "차라리 풀 스캔이 나았다" 는 역설적인 상황이 발생했습니다...
최적의 인덱스를 찾아서 - 복합인덱스
단일 인덱스의 실패를 통해 깨달은 것은, 무작정 인덱스를 거는 것보다 WHERE 절과 ORDER BY 절을 종합적으로 분석하여 가장 효율적인 인덱스를 만드는 것이 중요하다는 점이었습니다.
ORDER BY 절까지 인덱스로 처리하기 위해, 기존 인덱스를 버리고 새로운 복합 인덱스를 설계했습니다. 핵심은 ORDER BY 에 사용되는 컬럼을 인덱스의 마지막에 포함시키는 것이었습니다.
복합 인덱스 생성 팁
- 컬럼 순서의 중요성: 카디널리티가 높거나, 등호(=) 로 비교하는 컬럼을 우선적으로 고려
- 정렬과 필터링의 조화:
ORDER BY컬럼을 마지막에 배치하여 정렬 최적화
CREATE INDEX idx_trade_region_deleted_createdat ON trade (region, deleted, created_at DESC)이 인덱스는 다음과 같이 동작합니다:
region와deleted컬럼으로WHERE조건에 맞는 데이터를 빠르게 찾습니다.- 중요한 점은, 이렇게 찾은 데이터들이 이미 인덱스 내에서
created_at DESC순서로 정렬되어 있다는 것입니다. - 따라서 DB는 별도의 정렬 작업(
filesort) 없이, 그저 인덱스에 있는 정렬된 순서 그대로 데이터를 읽어오기만 하면됩니다. - Sequential I/O: 인덱스가 정렬 순서를 보장하므로, 데이터 접근 패턴이 더욱 예측 가능해집니다.

드디어 Using filesort 문구가 깨끗하게 사라진 것을 볼 수 있었습니다. 그리고 인덱스를 타고 읽어들인 모든 행이 바로 최종 결과에 포함되어서 filtered = 100 이라는 만족스러운 결과가 나왔습니다.
filtered값은 인덱스 등을 통해 읽어온 행 중WHERE조건을 통과하는 행의 비율(%)을 의미합니다. 즉,filtered값이 낮을 수록 DB가 불필요한 데이터를 잔뜩 읽어왔다는 뜻입니다.
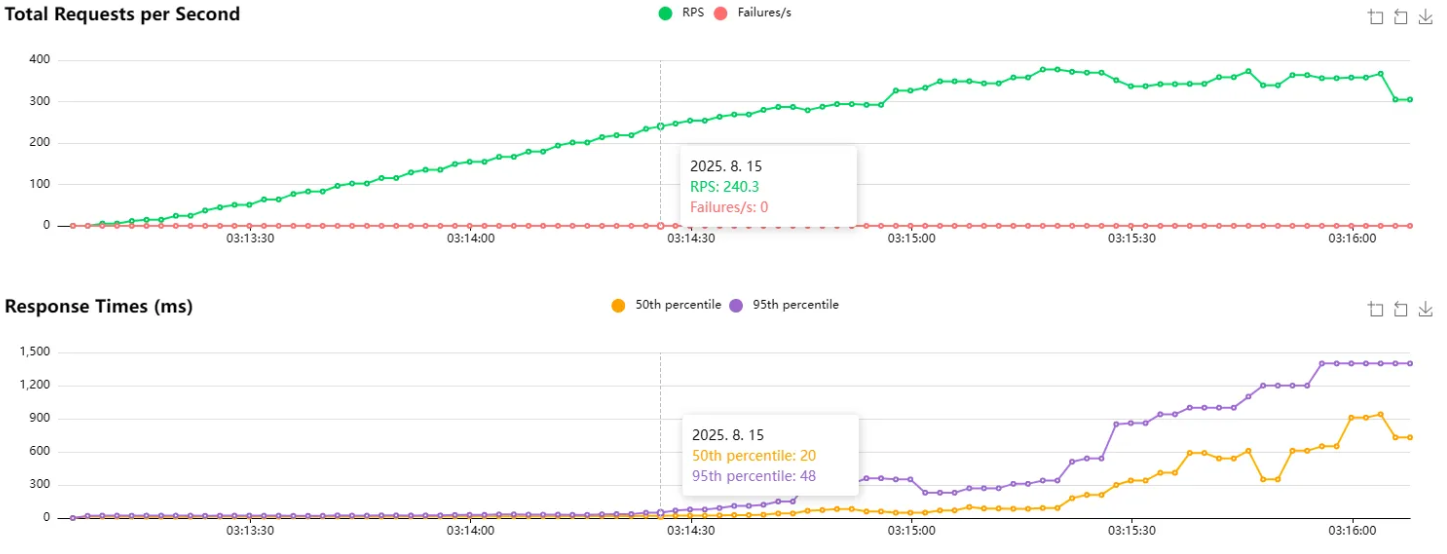
결과: 매우 적어진 DB 조회 범위와 부하 테스트 성능 개선
최종 복합 인덱스를 적용한 후, EXPLAIN 결과와 부하 테스트 결과 모두 확인해보니 인덱스 덕분에 불필요한 데이터 스캔이 줄어, 조회 범위가 대폭 축소되었고 성능도 눈에 띄게 향상되었습니다.
(총 데이터 10만건 인기 지역 조회 기준)
| 단계 | 스캔 행 수 | EXPLAIN 추가 정보 | filtered (%) | 병목 RPS | 설명 |
|---|---|---|---|---|---|
| 최적화 전 (풀 테이블 스캔) | 100,000 | Using where; Using filesort | 2.08 | 45 | 모든 데이터를 전체 탐색 및 정렬, 매우 비효율적 |
| 단일 인덱스 적용 후 (region) | 50,000 | Using index; Using where; Using filesort | 16.66 | 24 | 일부 필터링을 하지만 Random I/O와 filesort로 인해 오히려 악화! |
| 복합 인덱스 적용 후 (region, deleted, created_at DESC) | 5,000 | Using index | 100 | 240 | 필터링과 정렬 모두 인덱스 범위 내에서 처리, filesort 완전 제거 |
최종 결과로 스캔하는 행의 수가 5%가 되었고, 부하 테스트에서도 45 RPS -> 240 RPS 로 약 433% 의 성능 향상을 확인했습니다!
마무리하며

이번 사례에서 배운 중요한 교훈들:
- 인덱스는 만능이 아니다: 잘못 설계된 인덱스는 오히려 성능을 헤칠 수 있습니다.
- 부하 테스트의 중요성: 단순한 쿼리 실행계획 확인만으로는 실제 부하 상황에서의 성능을 예측하기 어렵습니다.
- 종합적인 접근이 필요:
WHERE조건과ORDER BY조건을 함께 고려한 인덱스 설계가 필요합니다. - Random I/O vs Sequential I/O: 인덱스 설계 시 데이터 접근 패턴도 고려해야 합니다.
결과적으로 복합 인덱스를 통해 스캔 범위를 5%로 줄이고, 부하 테스트 성능에서 433% 라는 큰 향상을 이끌어낼 수 있었습니다.
DB 스캔 범위를 줄여서 이미 충분히 빨라졌지만,
다음글에서는 DB 호출 수 자체를 줄이는 로컬 캐싱 을 통해
응답 속도 및 DB 부하를 더욱 개선한 이야기를 해보도록 하겠습니다.
메랜샵에 대한 저의 세 번째 이야기를 읽어주셔서 감사합니다!!
