Intro.
RNN, LSTM은 언어 모델링, 기계 번역과 같은 분야들에서 비약적인 발전을 이루었지만 본질적으로 순차적( hidden state가 hidden state에 전달되는 구조)으로 이루어지는 특성으로 인해 시퀀스의 길이에서 오는 메모리의 제약, 계산에 부담 등 여러 제약을 받게 된다.
Attention Mechanism은 시퀀스 모델링에서 중요한 부분이 되었고, Transformer는 순환적인 구조를 피하고 Attention Mechanism에 전적으로 의지하는 모델로써, 병렬화를 통해 번역 품질에서 높은 수준을 달성하였다.
Model Architecture.
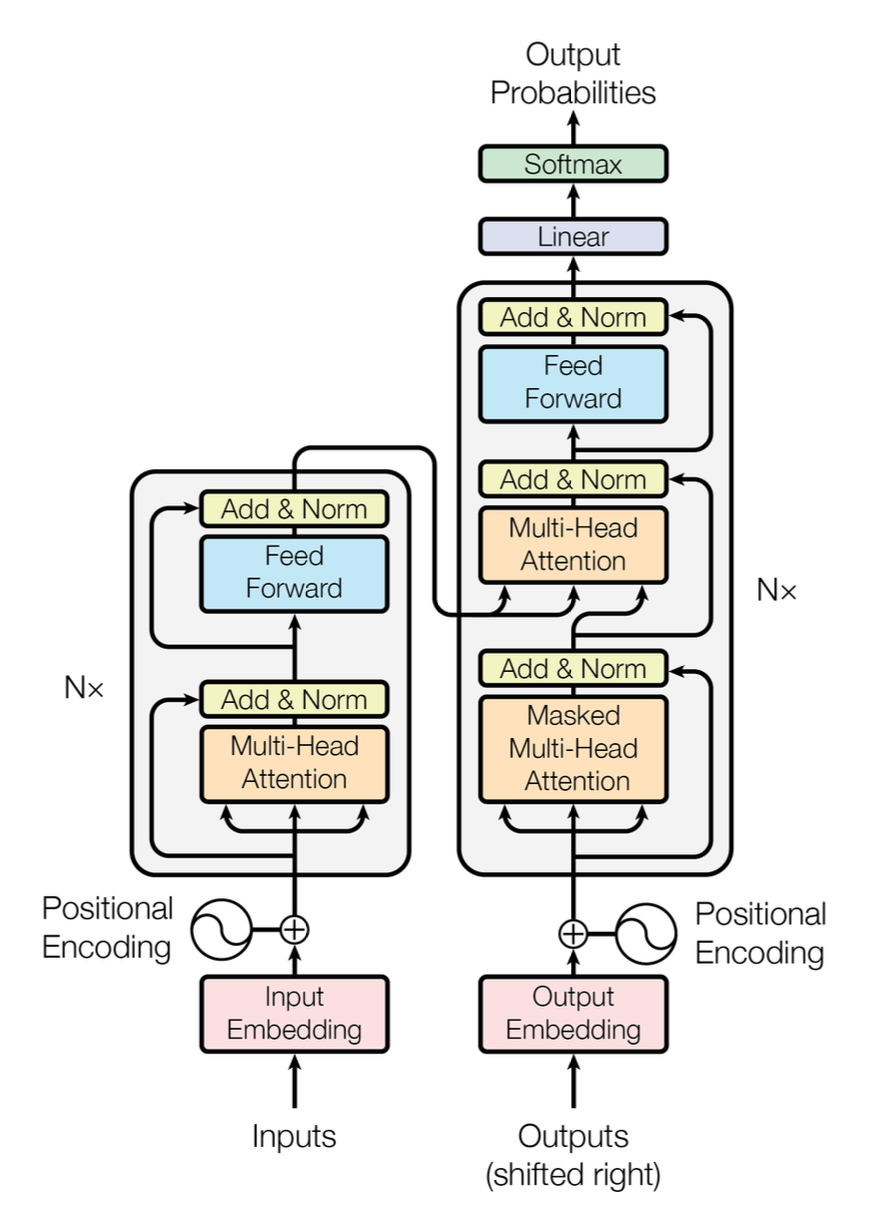
Transformer 출시 전후 대부분의 경쟁력 있는 신경망 기반 시퀀스 변환 모델은 인코더-디코더 구조를 가졌다. 이는 입력 시퀀스()는 인코더를 통해 연속적인 표현()으로 변환하고 디코더는 표현을 기반으로 Auto-Regressive 방식으로 출력 시퀀스를 출력하는 방식을 가지게 된다.
Transformer는 기존에 RNN, GRU, LSTM 기반 인코더-디코더와 달리 Self-Attetnion으로 입력의 각 부분 간 관계를 학습하고 병렬 처리와 효율적인 학습을 가능하게 한다.
1. Encoder and Decoder Stacks
1.1 Encoder
인코더는 6()개의 동일한 레이어로 구성되어 있으며, 각 레이어는 2개의 서브 레이어를 가진다. 첫번째 서브 레이어는 Multi-Head Attentiion이며, 두번째 서브 레이어는 단순한 Position-wise Feed-Forward이다.
각 서브 레이어의 입력과 출력 사이에 Residual Connection을 적용하여 학습 안정성을 높이고 Layer Normalization을 수행한다.
모든 서브 레이어와 임베딩 레이어는 동일한 출력 차원 를 유지한다.
Residual Connection
Residual Connection은 신경망 학습 중 기울기 소실(Vanishing Gradient) 문제를 완화하고, 깊은 네트워크의 학습을 안정화하기 위해 설계된 구조이다.
- : 레이어의 입력 (Residual Path)
- : 레이어의 연산 결과
- : 레이어의 최종 출력
입력 를 그대로 출력에 더해줌으로써, 네트워크가 학습 중에도 원래의 입력 정보를 보존하도록 하는 역할을 한다.
Decoder
디코더 또한 6()개의 동일한 레이어를 가진다. 서브 레이어로는 인코더와 동일한 두개의 서브 레이어와 인코더 스택의 출력을 기반으로 Multi-Head Attention 수행하는 서브 레이어를 추가로 가진다.
레이어 간 정규화 또한 인코더와 동일하게 Residual Connection을 통해 이루어진다.
디코더에 서브 레이어는 미래의 토큰(정답)을 미리 보지 못하도록 하기 위해 출력 임베딩을 한칸 오른쪽으로 이동하는 방식을 사용한다. 이는 현재 위치에서 이전 위치(, , ) 정보만을 의지하게 만든다.
2. Attention
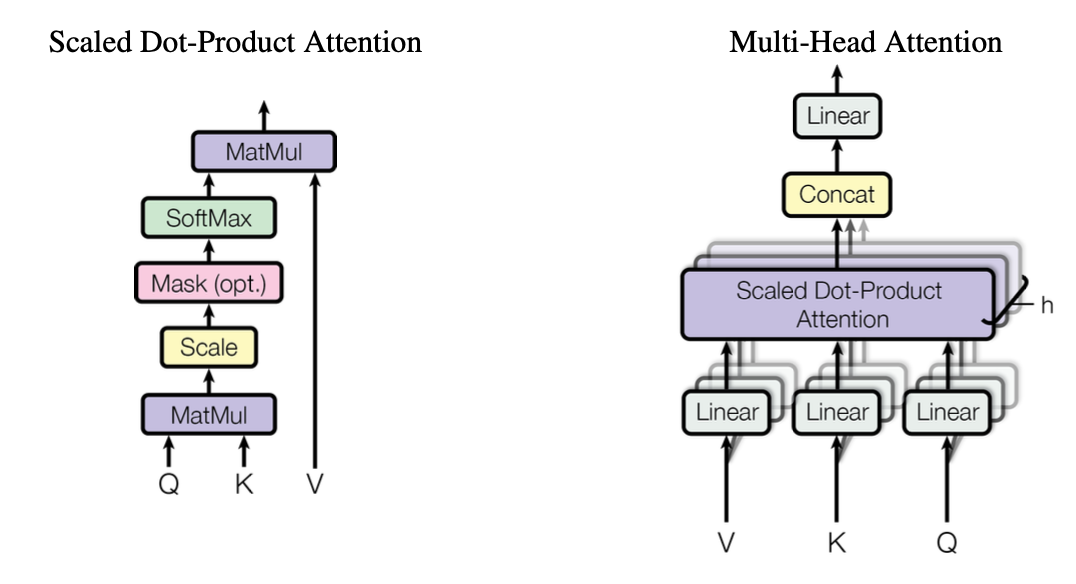
Attention 함수는 Q(Query)와 K-V(Key-Value) 쌍을 사용하여 출력을 생성하는 함수로 볼 수 있다. Transformer는 Scaled Dot-Product Attention을 사용해 multi-head로 나누어 계산한다.
2.1 Scaled Dot-Product Attention
Scaled Dot-Product Attention은 에 차원을 가지는 Q, K를 내적(Dot Product)으로 계산 한 뒤, 그 결과를 로 나누어 안정화(Scailing)를 수행하고 Softmax를 적용하여 V에 대한 가중치(Attention Weight)를 생성한다.
가 커질수록 내적 값이 커지므로, 너무 커져 Softmax 결과가 매우 작은 기울기를 가지는 기울기 소실(Vanishing Gradient) 문제를 방지한다.
Q(Query), K(Key), V(Value)
Transformer에서 Q, K, V를 나누는 이유는, 입력 데이터 내에서 단어 간의 관계(연관성, 중요도)를 계산하고, 최적의 정보를 추출하기 위함이다.
- Q, K, V의 역할
백터 역할 설명 Q(Query) 무엇을 찾을 것인가 특정 토큰이 다른 토큰과 얼마나 관련이 있는지 결정하는 기준점 K(Key) 저장된 정보 모든 토큰을 고유하게 식별하는 정보 V(Value) 실제 가져올 정보 최종적으로 가중 합을 계산하여 출력할 정보
- Q, K, V의 생성
- = 입력 시퀀스 (단어 임베딩)
- = 학습 가능한 가중치 벡터
- = Query, Key, Value 벡터
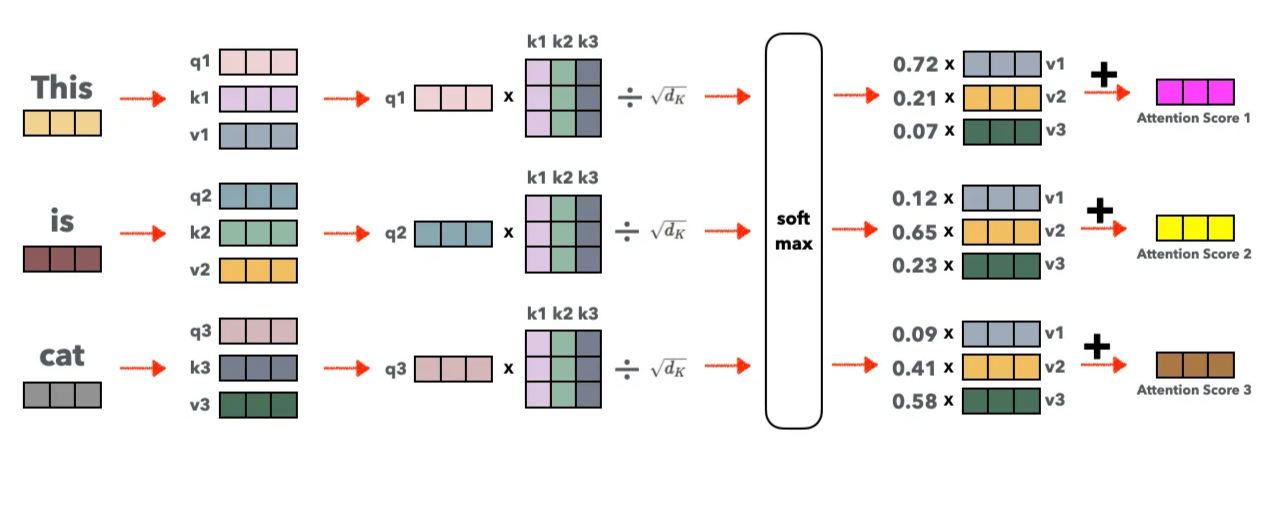
계산 과정을 좀더 자세히 살펴 보면 다음과 같다. 예를들어, “This is cat”이란 시퀀스를 처리 한다면, 아래에 그림과 같이 표현할 수 있다. 각각의 토큰으로 Q, K, V를 생성 후에 Q(현재 단어)와 K(다른 단어들)로 Similarity를 계산한 뒤, 스케일링() 처리 한다. softmax를 통과한 후에 V를 통해 Attention Score를 얻게 된다.
다시 논문으로 돌아와서, 가장 널리 사용 되는 두가지 Attention Function은 Additive Attention, Dot-Product Attention 두가지 이며 다음과 같은 차이를 가진다.
-
Additive Attention은 단일 은닉층(Single Hidden Layer)을 가진 작은 신경망(Feed-Foward Netwok)으로 유사도를 계산하지만, Dot-Product Attention은 내적을 사용해 유사도를 계산한다.
-
두 방법은 이론적으로 복잡도가 비슷하지만, Dot-Product Attention이 행렬 계산에서 최적화가 가능하므로 더 빠르고 공간 효율적이다.
-
작은 에서는 차이가 없으며, 큰 에서는 Additive Attention가 더 우수하다. 다만, 를 나누어 스케일링 할 경우 Dot-Product Attention이 더 좋은 성능을 보여준다.
최종적으로, Transformer에서는 스케일링된 Dot-Product Attention을 사용하여 연산 속도와 효율성을 극대화하였다.
2.2 Multi-Head Attention
단일 Attention Function을 사용하여 Q, K, V를 직접 처리하는 방식보다 각각 번씩 선형 변환 하여 개의 어텐션 연산을 병렬적으로 수행 한 후, 각 결과값을 연결(Concatenation)한다. 그 후, 다시 선형 변환하여 최종 출력값을 생성한다. 이러한 방식은 다음과 같은 이점을 가진다.
- 다양한 표현 공간에서 동시에 정보를 학습 가능
- 단일 어텐션 헤드에서 발생하는 정보 손실(평균화 효과) 방지
다양한 표현공간(Representation Subspaces) 이란?
- 다양한 위치
각각의 Attention Head가 문장 내 다른 위치에 집중할 수 있는 기회를 제공할 수 있다.
예를 들어,"The cat sat on the mat.”이라는 입력(영어) 문장과"Le chat s'est assis sur le tapis.”라는 출력(프랑스어) 문장에 대해 하나의 Head는"cat"↔"chat"을 학습에 집중하며, 다른 Head는"sat"↔"s'est assis"에 집중할 수 있는 환경이 마련된다.
- 다양한 표현 공간
단어 간의 관계는 단순한 의미적 관계뿐만 아니라 문법적, 위치적, 구문적 특징을 가진다.
예를들어, "The cat sat on the mat because it was tired." 문장에서 it은 문맥적으로 cat을 뜻하고, 문법적으로 주어이며, 위치적으로 접속사 뒤에 위치한다. 각 Head가 it 하나에 다양한 의미를 학습할 수 있다.
해당 논문에서는 8(=8)개의 병렬적인 Attention Layers(Head)를 사용했으며, 그에 따라 각 Head는 차원으로 설정되었다. Head 차원을 줄였기 때문에 전체 연산량은 단일 Attention Head를 사용할 때와 비슷한 수준을 유지할 수 있었다.
2.3 Applications of Attention in our Model
Transformer는 3가지의 다른 Multi-Head Attention을 사용한다.
-
Encoder-Decoder Attention
-
역할: 디코더가 인코더 정보를 활용하여 적절한 출력을 생성
-
Q(Query): 이전 디코더 레이어에서 출력
-
K(Key), V(Value): 인코더의 출력에서 가져옴
-
예시
-
입력문장(English):
“I love apples.” -
출력문장(French):
“J’aime les pommes.”→ 디코더가
“J’aime”을 생성할 때, 인코더의“I love”부분에 집중하여 번역할 수 있도록 어텐션 수행→ 디코더가
“les pommes”을 생성할 때는“apples”에 집중
-
-
-
Encoder Self-Attention
-
역할: 입력 문장 내 단어들이 서로 어떤 관계를 가지는지 학습
-
Q(Query): 인코더 내부에서 가져옴
-
K(Key), V(Value): 인코더 내부에서 가져옴
-
예시
-
입력문장(English):
"The cat sat on the mat."→
“cat”이“sat”과 강한 관련성(높은 Attention Score)을 가짐
-
-
-
Decoder Self-Attention
-
역할: 디코더가 미래 단어를 참조하지 않고 현재까지 생성된 단어만 이용하도록 제한 (마스킹 적용)
-
Q(Query): 디코더 내부에서 가져옴
-
K(Key), V(Value): 디코더 내부에서 가져옴
-
예시
-
출력 문장:
"J'aime les pommes."→
"J'aime"를 생성할 때"les pommes."를 참조하지 못하도록 마스킹 하며 마스킹은"les pommes"부분을 Softmax 연산 전에 로 세팅하여 무시하는 방식으로 이루어진다.
-
-
3. Position-wise Feed-Forward Networks
Attention Sub-Layers 이외에도, Transformer의 인코더, 디코더의 각 레이어에는 FFN(Fully Connected Feed-Forward Network)이 포함된다.
FFN은 각 단어(토큰)에 대해 독립적으로 동일하게 작용한다.
위 식에서 알 수 있듯이 FFN의 구성은 다음과 같다.
- 첫번째 선형 변환 (Linear Transformation)
- ReLU 활성화 함수 (ReLU Activation)
- 두번째 선형 변환 (Linear Transformation)
Transformer는 입력 및 출력 차원은 , Hidden Layer에서는 을 사용한다. (즉, 512 → 2,048 → 512로 구성)
4. Embeddings and Softmax
Transformer는 입력 및 출력 토큰을 차원 벡터로 변환하는 학습된 임베딩을 사용하며, 디코더의 최종 출력을 선형 변환과 Softmax를 통해 다음 단어 확률로 변환한다. 이 과정에서 임베딩과 Softmax 이전의 선형 변환 가중치를 공유하며, 임베딩 벡터는 로 스케일링해 사용한다.
5. Positional Encoding
Transformer 모델은 순환(Recurrent), 합성곱(Convolution)이 없으므로 토큰의 위치 정보를 제공하기 위해 Positional Encoding을 사용한다. → Tranformer는 순차적인 처리가 아닌 모든 토큰을 한번에 입력받아 병렬처리를 한다.
위치 인코딩 방법은 크게 두가지가 존재한다.
- Learned Positional Encoding
- Fixed Positional Encoding
Transformer는 Sin, Cosine 함수 기반의 고정된 위치 인코딩을 사용한다.
- : 단어의 위치
- : 임베딩 차원의 인덱스
해당 방식은 첫번째 장점은 “서로 다른 차원이 서로 다른 주파수를 가질 수 있다.” 이다. 이는 차원이 다르면 위치 정보를 표현하는 패턴도 달라지는 것을 의미한다. 즉, 다양한 위치 정보를 모델이 학습할 수 있게 된다.
두번째 장점은 “상대적 위치를 선형 변환으로 표현 가능하다.” 는 점이다. 예를 들어, 특정 위치 에서 만큼 이동한 는 기존 의 선형 변환으로 표현이 가능하다. 즉, 모델이 단어 간 상대적 위치 관계를 쉽게 학습할 수 있게 된다.
세번째 장점은 “긴 시퀀스에서도 안정적이다” 는 점이다. 학습 중 보지 못한 긴 문장에서 일반화 성능이 Learned Positional Encoding보다 안정적이다. 이는 Transformer가 Learned Positional Encoding이 성능 차이가 없었음에도 “Sin, Cosine 함수 기반의 고정된 위치 인코딩”을 채택한 이유가 되었다.
Why Self-Attention.
Transformer 모델에 Self-Attention 레이어는 기존에 순환(Recurrent), 합성곱(Convolution) 레이어와 비교하여 다음과 같은 이점을 가진다.
-
연산량 (Computational Complexity)
모델 연산량 (Complexity) Self-Attention RNN (LSTM, GRU) CNN (Convolution) -
병렬 처리 (Parallelization)
모델 병렬화 가능 여부 Self-Attention 완전 병렬화 가능 RNN (LSTM, GRU) 순차적(Sequential) 처리 필요 CNN (Convolution) 부분 병렬화 가능 (커널 범위 내에서만) -
긴 시퀀스 의존성 (Long-Range Dependencies)
모델 최대 경로 길이 (Path Length) Self-Attention 모든 단어가 한 번에 연결 되어 학습 RNN (LSTM, GRU) 멀리 있는 단어간 학습이 어려움 CNN (Convolution) 또는 커널 크기에 의존 Self-Attetion은 장기 의존성 학습에 매우 유리하다. RNN은 기울기 소실(Vanishing Gradient) 문제로 긴 시퀀스에 대한 정보 소실 문제는 항상 존재 해왔고 CNN은 여러 층을 쌓아야만 먼 거리에 학습이 가능했다.
-
모델의 해석 가능성 (Interpretability)
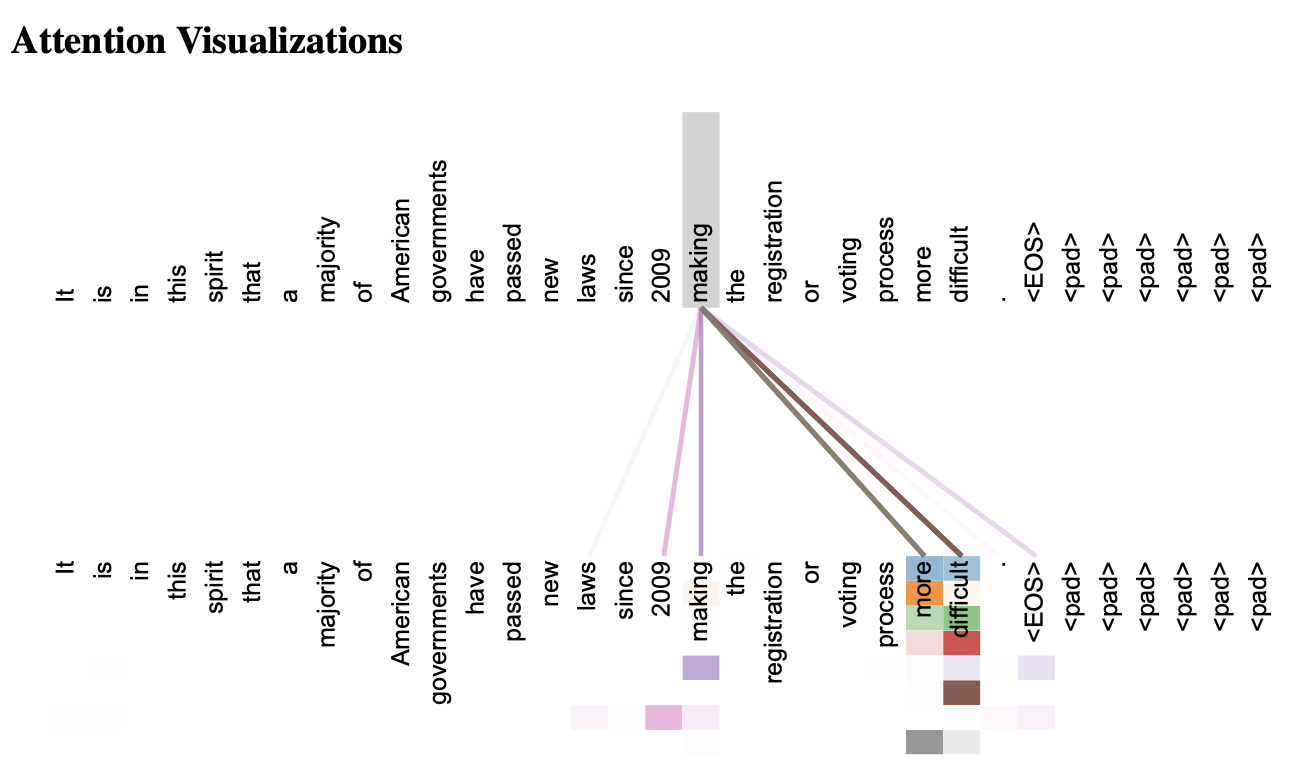
모델 해석 가능성 Self-Attention 어텐션 가중치를 시각화 가능 RNN (LSTM, GRU) 해석이 어려움 CNN (Convolution) 해석이 어려움 Attention Score를 계산하고 토큰 간 상관관계를 학습하는 Self-Attention 특성 상 Attention을 시각화 하는 것만으로도 어느 정도 모델의 결과를 해석할 수 있는 장점을 가진다.
End.
이후, Training과 Result는 여타 논문들과 그 구조가 다르지 않으며, 학습 방법과 그 결과가 주를 이룬다. 이는 논문에서 더 자세히 확인이 가능하다.
Transformer는 NLP에서 획기적인 변화를 가져왔으며, 최근에는 LLM에 근간이 되는 모델로써 AI 시대에 가장 필수적인 모델로 자리 잡았다. BERT, T5, ViT에 수많은 후속 모델이 Transformer 기반으로 설계되었으며, LLM의 핵심 엔진으로 GPT, Claude, LLaMA, Gemini 등의 현존 최고의 LLM 모델들 또한 Transformer를 기반으로 한다.
현대 AI 모델의 표준 아키텍쳐로 자리잡은 모델로써 앞으로의 AI 시대에서도 가장 근간이 되는 모델일거라 생각한다.
Reference.
- Attention Is All You Need (Google, 2008)
