- 논문이 나온지는 오래되었지만 나중에 복습을 하기위해 작성해보았습니다.
Summary
- SE Net (Squeeze and Excitation Network)
- 압축(Squeeze)한 정보를 이용하여 자극(Excitation)시킨다.
- Excitation ≒ Attention(주목), Emphasis(강조)
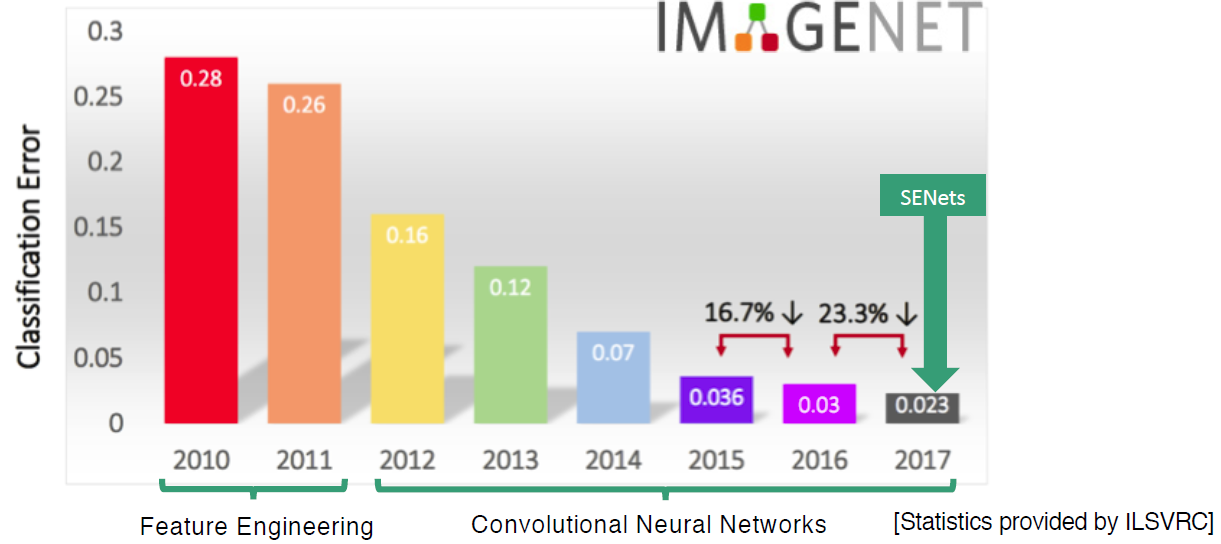
- ILSVRC 2017 classification 1위로 기존에 CNN기반 네트워크 대부분의 성능을 향상시킨다.
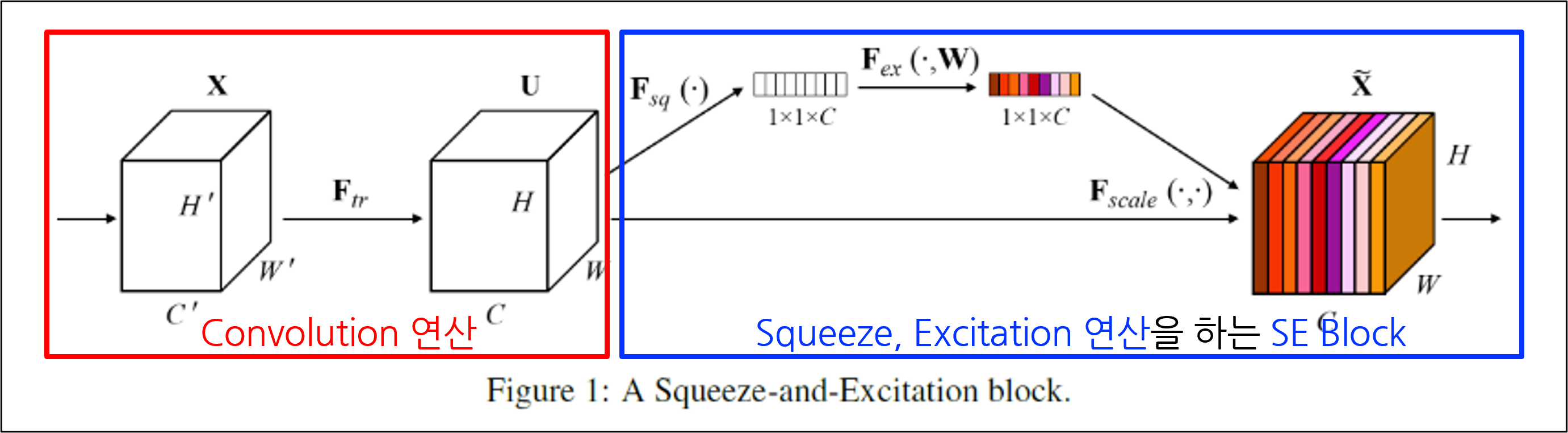
SE Block
- SE Net과 SE Block의 차이
- SE Net은 SE Block이 적용된 네트워크를 의미함.
- Ex) SE Block이 추가된 ResNet을 SE-ResNet으로 칭함.
- SE Block이란?
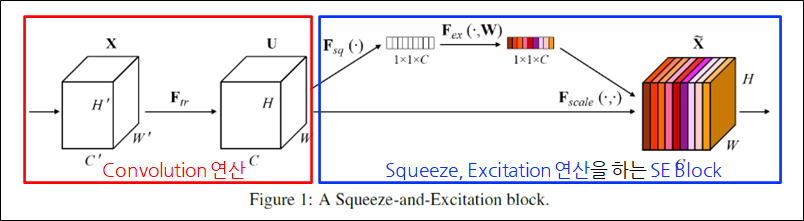
- SE Block: 정보를 압축하고, 자극시키는 연산을 수행하는 모듈
- Convolution layer 뒤에 SE Block을 추가.
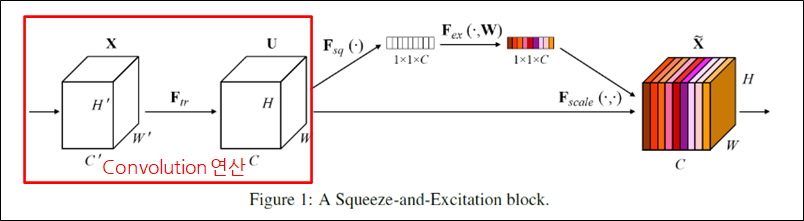
Convolution layer
-
Convolution layer를 사용하는 네트워크라면 적용 가능.
-
Convolution 연산인 𝐹_𝑡𝑟을 통해 X(input) => U(feature map)로 변환됨.
Squeeze
-
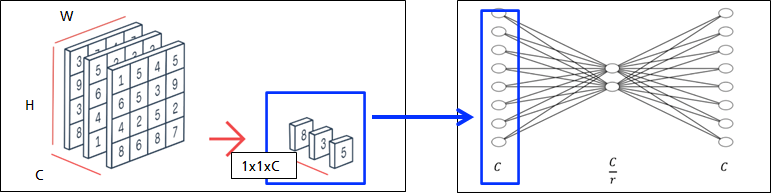
Squeeze 연산(𝐹_𝑠𝑞)을 Convolution의 결과에서, 각 채널 별로 수행
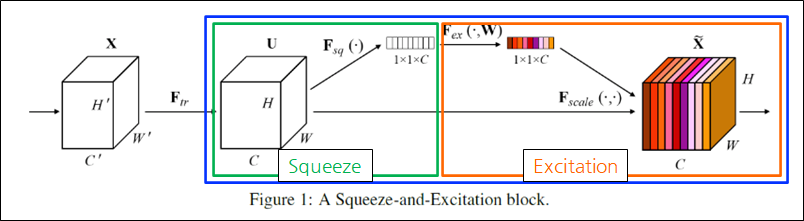
-
Squeeze 연산으로 Global Average Pooling(GAP)을 사용
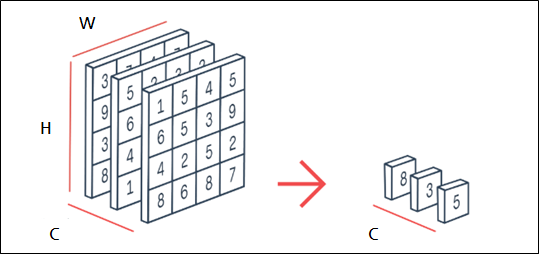
-
Squeeze의 효과는 ?
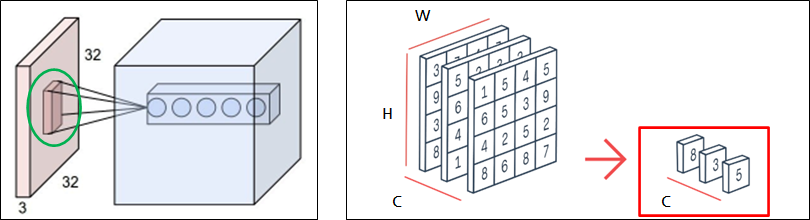
- local receptive field로 보지못하는 전체 영역(channel)도 보게한다.
- local receptive field: 출력 레이어의 뉴런에 영향을 미치는 입력 뉴런들의 공간 크기
- 채널을 압축(squeeze)한 정보로, 채널에 자극(excitation)을 줘서 Exploit의 효과를 얻음.
- Squeeze 연산의 결과를 channel descriptor라고 부름.
-
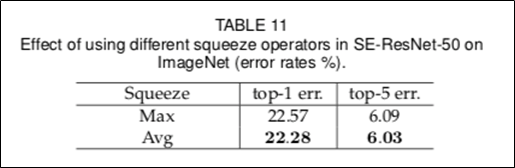
다른 Squeeze 연산으로 Max Pooling 등도 사용 가능함.
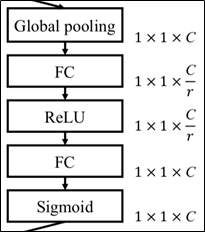
Excitiation
-
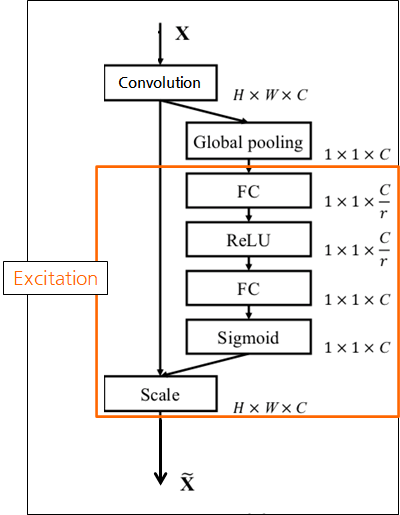
Excitiation의 전체 과정은 아래와 같음.
-
Reduction ratio(r)로 노드의 수를 줄였다 늘림.
-
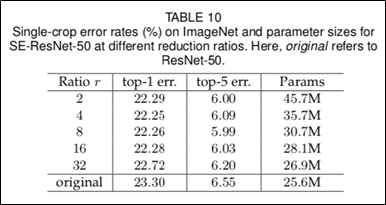
Reduction ratio는 default=16으로 가성비가 좋으며, 튜닝이 필요할 수 있음.
Fully connected layer
- FC의 효과는?
- channel descriptor를 이용하여 channel-wise dependencies(채널 간의 의존성)을 계산
- 각 채널이 얼마나 중요한지 계산되는 효과가 있음.
- 마지막에 Sigmoid를 통해 각 채널의 중요도가 0~1값으로 나옴
Scale
- GAP 적용 전의 값에 채널간의 의존성을 곱함
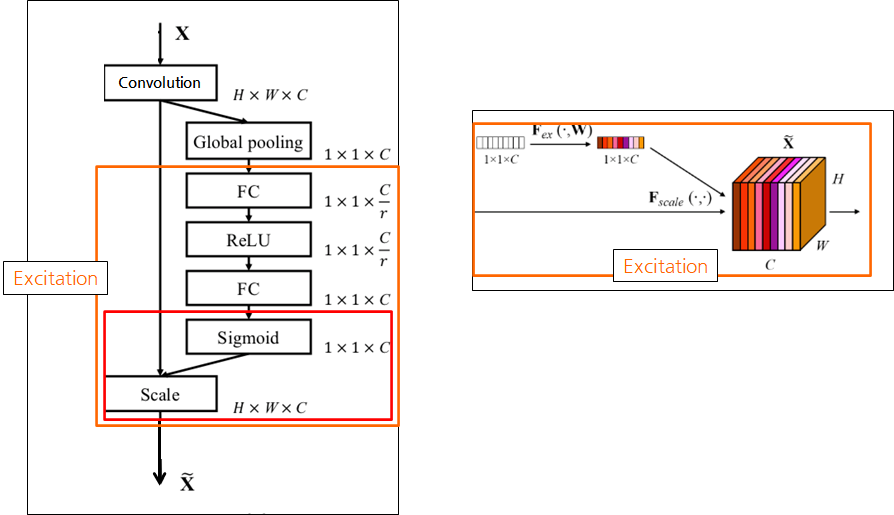
- 각 채널의 중요도가 강조됨
SE Network
- SE-Inception Module, SE-ResNet Module
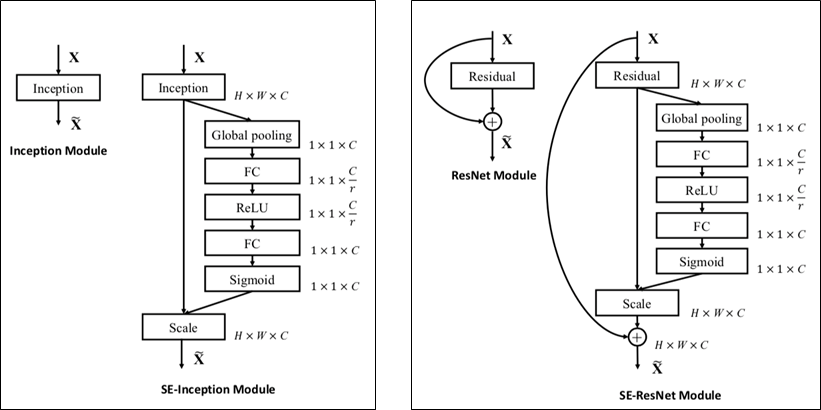
- SE-ResNet-50 = SE-ResNet Module * 50개
- ResNet의 Skip connection은 Excitation의 모든 과정이 끝난 후 수행함.
SE-ResNet Module
-
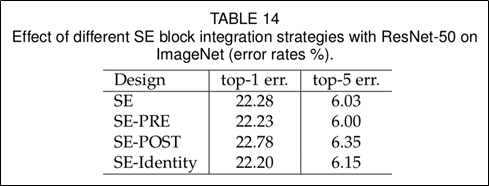
SE Block를 여러가지 순서로 배치하여 실험.
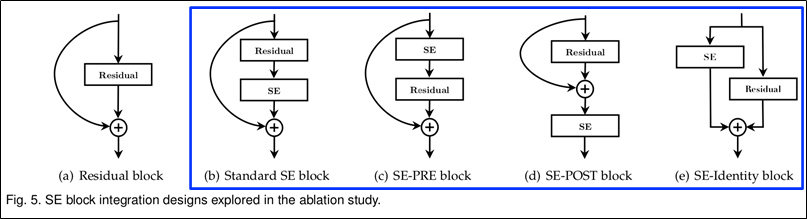
-
SE-POST를 제외하고는, Standard 이상의 성능을 보였음.
CNN based networks
- CNN기반 여러 네트워크에 대해 실험결과, 모두 성능 향상이 있었음.
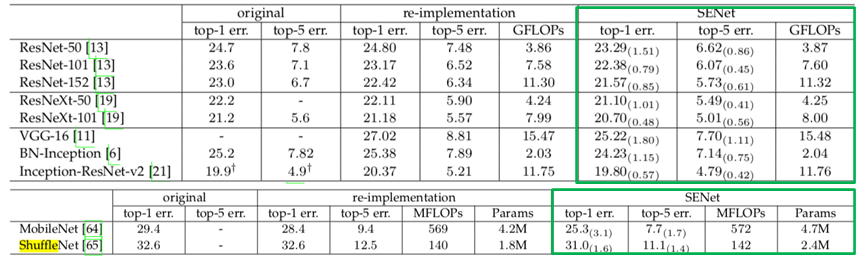
- SENet도 결국에는 블록을 더 쌓아서 성능을 향상시킨 것이지만..
- Squeeze 연산으로 GAP, Excitation 연산으로 2개의 작은 FC를 했음.
- 비교적 적은 계산 비용으로 양질의 성능 향상을 이루었다.
- SE Block을 사용했을 때, 전체 구간 중 어디서 좋아지는지 실험
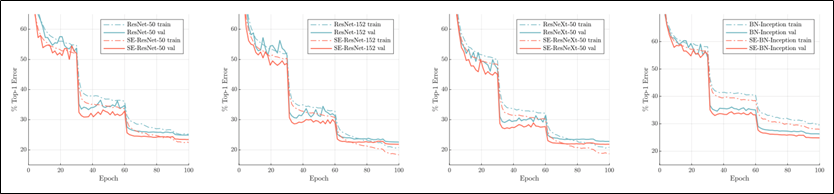
- 파란색이 오리지널 모델, 빨간색이 SE Network
- 실선이 validation error, 점선이 train error
- 전체 구간에서 일괄적으로 성능 향상이 있었음.
Hyperparameters
- Single machine
- GPU: 8 NVIDIA titanX
- Batch size: 256
- Momentum: 0.9
- Initial learning rate: 0.1
- Learning rate decay rate: 10 epoch
- Epochs: 약 400 epoch
- Dataset: ImageNet, Places365-Challenge, COCO, CIFAR 등
Other Experiments

-
TABLE12: Excitation 연산에서 연산자 선정
-
TABLE13: ResNet-50의 각 block별로 SE Block을 적용했을 때 성능
- SE_All: ResNet의 모든 block에 SE Block을 적용
-
ResNet에서는 excitation에서 FC의 bias를 제거하면 채널 의존성을 모델링하기 더 좋음
We found empirically that on ResNet architectures, removing the biases of the FC layers in the excitation operation facilitates the modelling of channel dependencies
Reference

개인 학습 및 복습을 위한 머신러닝 엔지니어의 블로그입니다 :)