Summary
-
복수의 커널을 사용하고(Split), 포괄적인 정보를 모아(Fuse), feature map을 선택(select)
-
아이디어
- 시각 피질 뉴런의 수용 영역의 크기가 시각 자극에 따라 조절됨.
- ex) 가까운 물체를 볼 때와, 먼 물체를 볼 때
-
CVPR 2019 발표 논문
-
관련 연구
- Multi-branch convolutional networks.
- Grouped/Depthwise/Dilated convolutions.
- Attention mechanisms
- Dynamic convolutions
SK Convolution
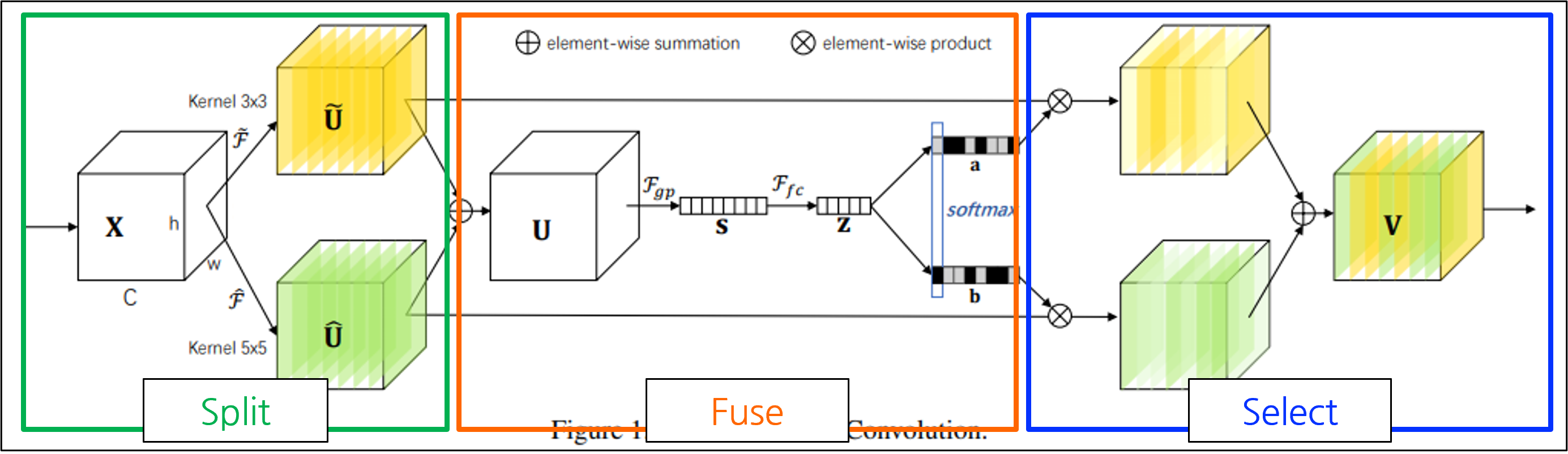
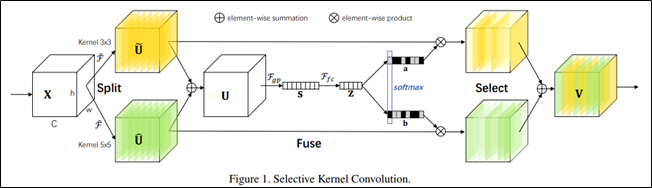
- SK Convolution 이란?
- Split: 다양한 kernel size로 여러 경로를 생성
- Fuse: 여러 경로의 정보를 결합하여 포괄적인 정보를 획득
- Select: 포괄적인 정보를 통해 여러 kernel의 feature map을 aggregate
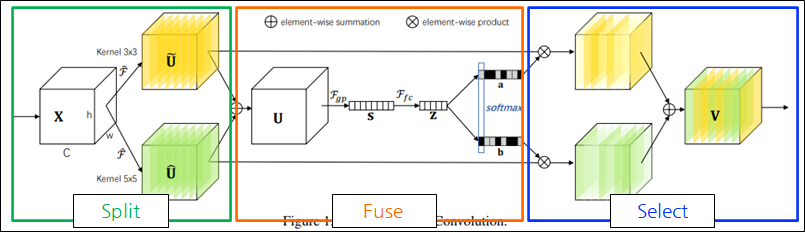
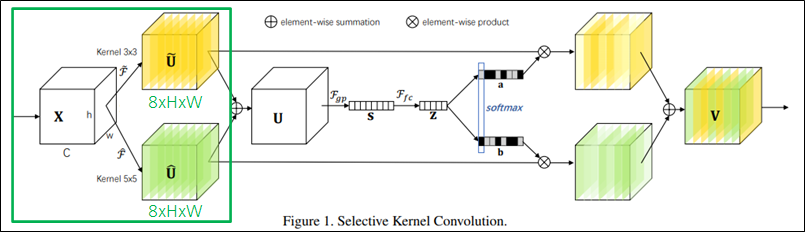
Split
-
Split: 다양한 kernel size로 여러 경로를 생성
-
Dilated convolution, Grouped convolution이 적용됨.
- Dilated convolution: 필터 내부에 zero padding을 추가해 receptive field를 늘림
- Grouped convolution: 입력 채널을 여러 그룹으로 나누어 독립적으로 Conv 수행
- ex) kernel_size=3x3, dilation_rate=2, groups=G
Fuse
-
Fuse: 여러 경로의 정보를 결합하여 포괄적인 정보를 획득
-
- Element-wise summation
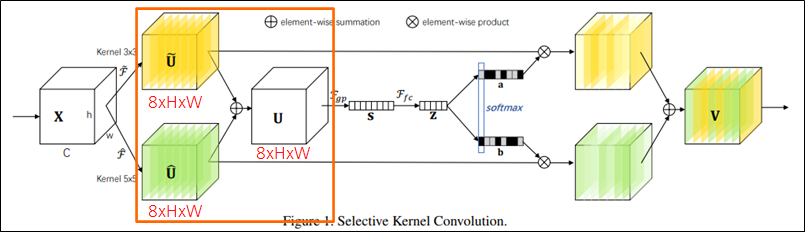
- Element-wise summation
-
- Global pooling
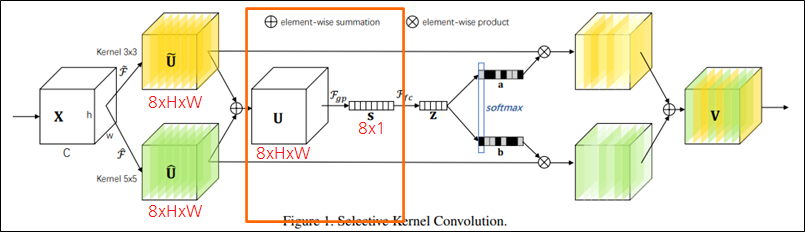
- Global pooling
-
- Fully connected layer
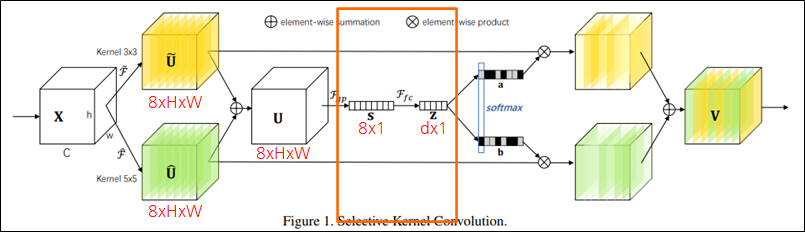
- Output shape: d=max(C/r,L)
- r: Reduction ratio, L: Minimal value (default 32)
- Fully connected layer
-
- Fully connected layer
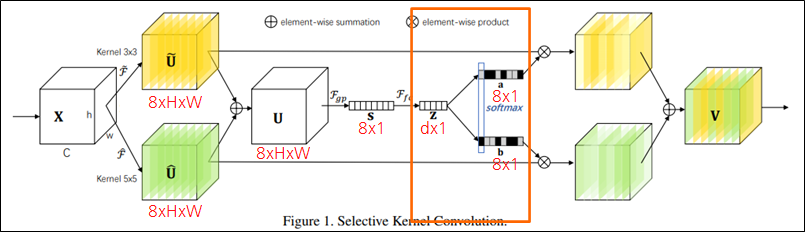
- Output shape: 𝑪x𝟏
- Attention weight: a, b
- Fully connected layer
-
- Softmax: 각 채널 인덱스에 해당하는 값을(예시에서는 2개) Softmax
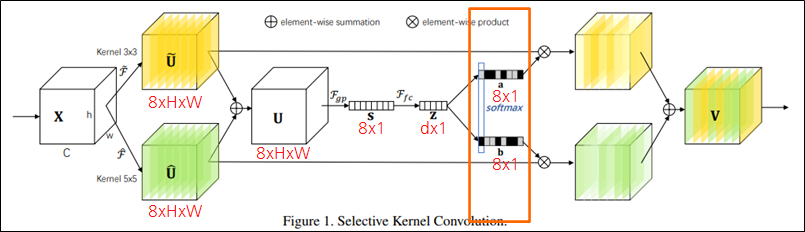
- Softmax를 하므로 당연히 a_c + b_c = 1
- Softmax: 각 채널 인덱스에 해당하는 값을(예시에서는 2개) Softmax
Select
-
Select: 포괄적인 정보를 통해 여러 kernel의 feature map을 aggregate
-
Feature map의 각 채널에 Softmax value를 곱함.
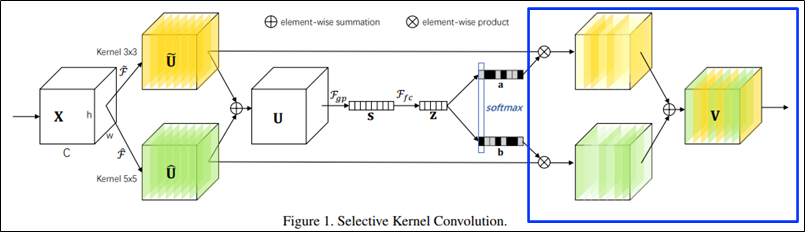
- 노란색 plane(kernel 3x3)과 초록색 plane(kernel 5x5)이 입력에 따라 attention됨.
Experiments
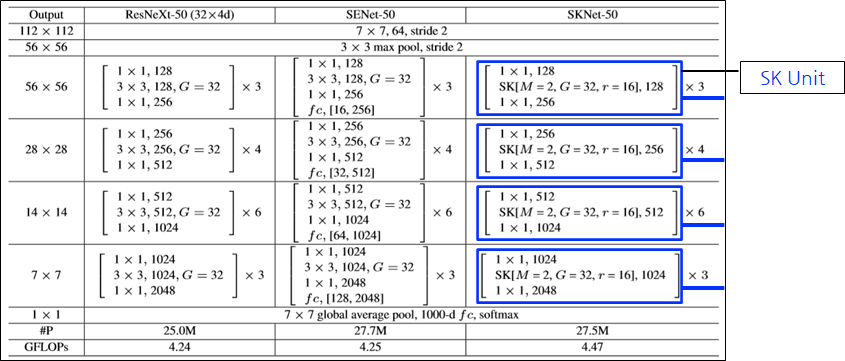
SKNet-50
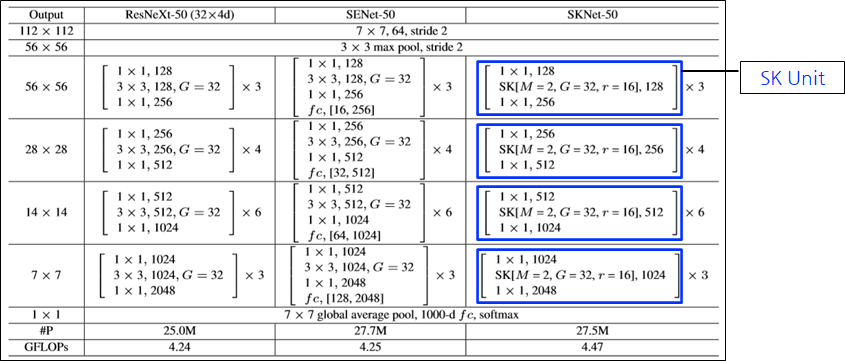
- M: number of paths
- G: number of groups
- r: reduction ratio
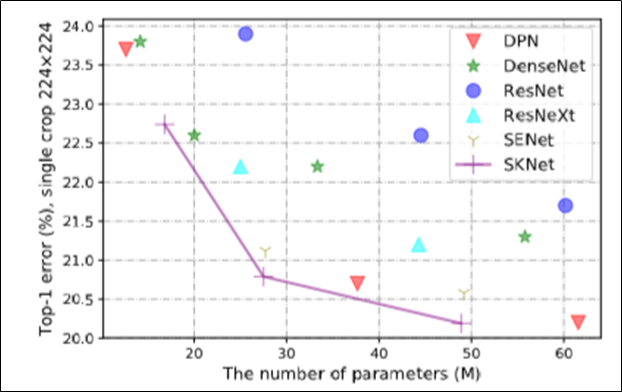
다른 네트워크들과 성능 비교
- ImageNet 2012 dataset
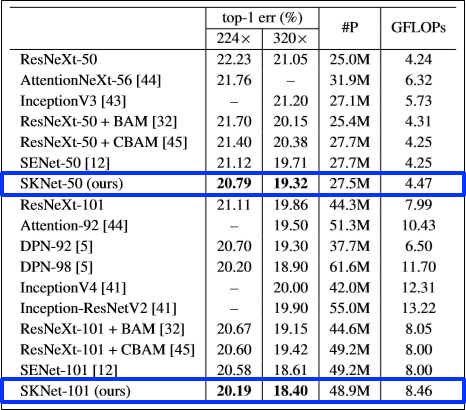
- ImageNet 2012 dataset
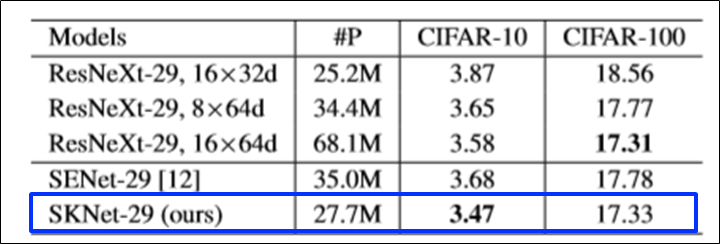
- CIFAR-10, CIFAR-100 dataset (작은 데이터 셋에 대해서도 테스트)
각각 다른 kernel의 경로가 잘 사용되는지 확인(1)
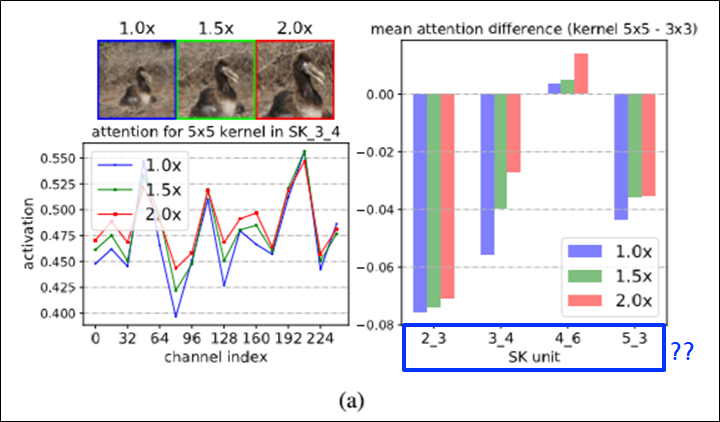
- SK 2_3: SK Unit 3개가 있는 2번째 stage
- SK unit?
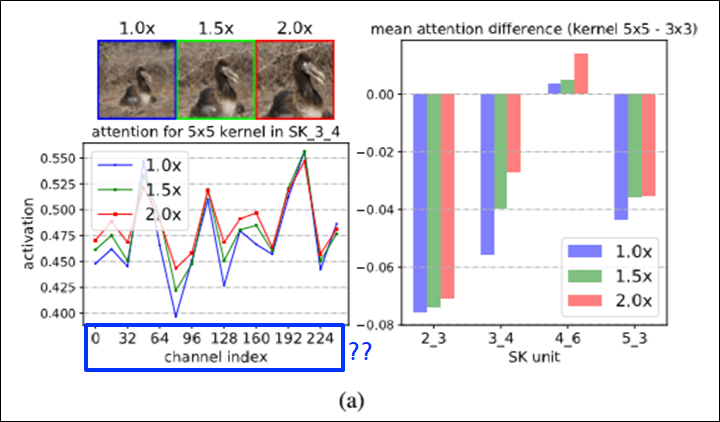
- 각 채널인덱스 별로, 어떤 커널사이즈의 것이 어텐션이 더 많이들어갔는지 보기위함.
- channel index: attention weight 배열의 인덱스
- attention for 3x3 kernel + attention for 5x5 kernel = 1
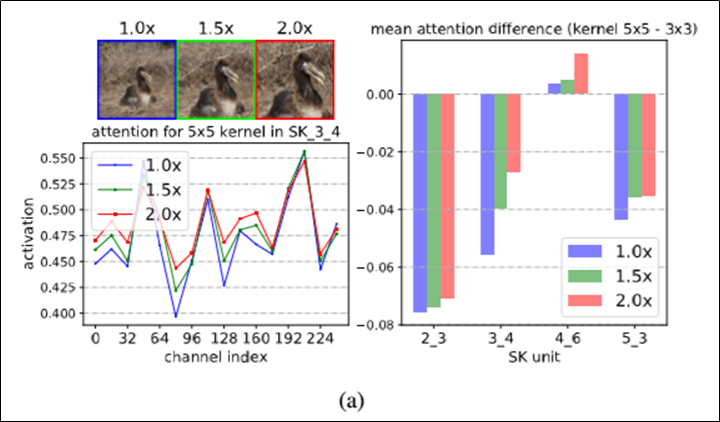
- 좌측 그래프: SK_3_4 (SK units)에서 kernel 5x5의 attention weight
- 우측 그래프: kernel 5x5 attention – kernel 3x3 attention
- 확대된 이미지를 사용할 수록, 더 큰 kernel size의 feature map이 강조됨
각각 다른 kernel의 경로가 잘 사용되는지 확인(2)
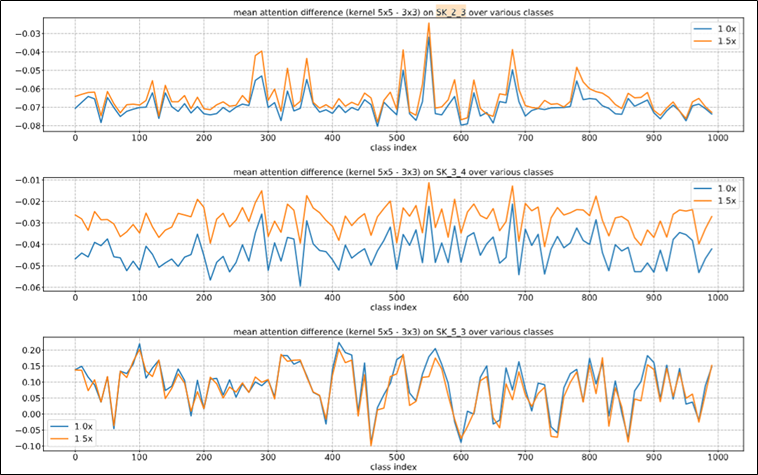
- ImageNet 2012 dataset의 1,000개 카테고리를 가진 validation sample으로 테스트
- 초반의 SK Units에서 attention이 잘 이루어지는 경향이 보였음
Hyperparameters
- Single machine
- GPU: 8 GPUs
- Batch size: 256
- Momentum: 0.9
- Initial learning rate: 0.1
- Learning rate decay rate: 30 epoch
- Epochs: 100 epoch
- Dataset: ImageNet 2012, CIFAR 등
Reference
- ✔ 논문: https://arxiv.org/abs/1903.06586!
- 구현코드

개인 학습 및 복습을 위한 머신러닝 엔지니어의 블로그입니다 :)