Depth vs Width: ResNet vs Wide Residual Networks
Depth vs Width: ResNet vs Wide Residual Networks 비교 연구
이 블로그 포스트는 딥러닝에서 네트워크의 깊이(Depth)와 너비(Width) 중 어느 것이 성능 향상에 더 효율적인지 비교 분석한 연구입니다.
1. 문제 정의
1.1. 잔차 신경망(ResNet)이란 무엇인가? [1]
잔차 학습(Residual Learning)은 기존 신경망에서 발생하는 성능 저하 문제(Degradation Problem)를 해결하기 위한 방법론으로 제안되었습니다. 이를 통해 기존 방법론(VGGNet)으로는 불가능했던 152개의 레이어를 가진 네트워크 구축이 가능해졌습니다.
1.1.1. 성능 저하 문제
단순한 직관:
네트워크가 더 깊어질수록(레이어 수가 증가할수록) 더 많은 특징을 학습할 수 있어야 합니다. 따라서 네트워크 성능은 네트워크의 깊이(레이어 수)에 비례할 것이라고 가정되었습니다.
실제 문제:
일반적인 직관과 달리, 특정 수 이상의 레이어를 가진 네트워크는 포화 상태 이후 성능이 급격히 저하되는 것으로 발견되었습니다. 일부는 이를 모델 과적합(overfitting)으로 언급할 수 있지만, 이 문제는 단순히 과적합으로 치부할 수 없습니다.
과적합과 성능 저하 문제의 차이:
과적합: 모델이 훈련 데이터의 노이즈까지 학습하여 훈련 오차는 최소화하지만 일반화 성능이 저하되어 테스트 오차가 증가하는 현상입니다.
성능 저하 문제: 더 깊은 신경망이 더 얕은 네트워크보다 높은 훈련 오차를 보이는 상황입니다.
성능 저하 문제는 훈련 데이터 자체를 학습하는 것조차 어려운 상황을 의미합니다. 이는 훈련 데이터를 과도하게 학습하는 과적합과는 명확히 구별되는 문제입니다.
1.1.2. 잔차 학습
구조적 해결책:
얕은 네트워크 에 여러 레이어를 추가하여 깊은 네트워크 를 만들고, 추가된 모든 레이어가 항등 매핑(identity mapping)을 수행한다면, 는 절대 보다 성능이 나쁠 수 없습니다.
현실과의 모순:
구조적 해결책에도 불구하고 성능 저하 문제는 여전히 발생합니다. 이는 모델의 최적화 알고리즘이 항등 매핑을 근사하거나 제약된 시간 내에서 더 나은 해를 탐색하는 데 어려움을 겪는다는 것을 의미합니다.
잔차 학습 개념:
여러 레이어가 학습해야 할 이상적인 매핑이 일 때, 저자들은 잔차 함수 를 학습하는 것이 를 직접 학습하는 것보다 쉬울 것이라는 가정을 설정했습니다. 레이어가 추구해야 할 매핑 는 로 표현될 수 있으며, 이 아이디어를 바탕으로 저자들은 ResNet의 핵심인 단축 연결(shortcut connection)을 제안했습니다.
잔차 학습이 작동하는 이유:
레이어가 항등 매핑()을 학습해야 하는 상황을 가정해봅시다:
- 일반 네트워크는 수많은 비선형 조합을 통해 를 직접 학습해야 합니다.
- ResNet은 잔차 함수를 사용하므로 이 되도록 학습하기만 하면 됩니다. 모든 가중치를 0으로 만드는 것은 여러 레이어를 통해 를 복잡하게 재현하는 것보다 훨씬 간단한 작업입니다.
그러나 모든 레이어가 항상 항등 매핑을 학습하는 것은 아닙니다. 그렇다면 왜 이 접근 방식이 효과적인 결과를 가져올까요?
논문은 레이어가 찾아야 할 가 처음부터 모든 것을 시작해야 하는 초기값 보다는 로 시작하는 것이 더 낫다고 가정합니다. 입력을 완전히 수정하는 것보다 입력을 약간 개선하고 조정하는 것이 정답에 접근하는 더 효율적인 방법입니다. 또한 덧셈으로 구성된 간단한 잔차 함수는 추가 파라미터나 계산 복잡도를 도입하지 않습니다.
요약:
ResNet은 입력()을 전달하는 것을 기본값으로 설정하고, 모델이 정답에 도달하기 위해 필요한 '차이'()만 학습하도록 유도합니다.
1.2. 깊이 vs 너비 [2]
깊이
딥러닝 연구에서 네트워크 깊이는 가장 중요한 요소 중 하나로 간주됩니다. 이는 깊이가 증가할수록 정확도가 증가하기 때문입니다.
ResNet이 발표될 당시, 152개의 레이어를 구성하여 낮은 복잡도와 높은 정확도를 모두 달성한 모델이었으며, 이는 이미지 분류 모델의 최첨단(SOTA) 수준이었습니다.
그러나 깊이와 정확도라는 두 요소는 직접적으로 비례하지 않습니다. 원하는 성능이 높을수록 1%의 정확도 향상을 위해 더 많은 깊이가 필요하며, 때로는 깊이를 두 배로 늘려야 할 수도 있습니다. 50%에서 51%로 증가하는 "비용"은 98%에서 99%로 증가하는 "비용"과 크게 다릅니다. 성능 향상에는 명확한 한계가 있습니다. 이를 수익 체감(diminishing returns)이라고 합니다.
극단적인 깊이의 추가 문제:
-
특징 재사용 감소: 네트워크가 너무 깊어지면 단축 연결이 "남용"됩니다. 그래디언트가 항등 단축 연결을 통해 학습이 필요한 레이어를 우회하여, 수많은 레이어가 실제로 아무것도 하지 않거나 최종 결과에 대한 기여를 급격히 감소시킵니다.
-
계산 비용: 이러한 문제는 훈련 시간을 지수적으로 증가시킬 뿐만 아니라 계산 비용을 크게 증가시키는 단점이 있습니다.
-
과적합 위험: 또한 작은 데이터셋의 경우 너무 깊은 네트워크는 과적합 위험이 있습니다.
ResNet이 네트워크 깊이를 크게 확장하는 데 성공했지만, 반대로 새로운 문제를 제기했습니다: 극단적인 깊이의 비효율성입니다.
너비
지금까지 우리는 확장의 한 축(깊이)에서 벗어나 다른 방향을 검토해야 합니다. 네트워크 깊이를 증가시키는 것이 유일한 해결책일까요? 네트워크가 깊지 않더라도 넓은 네트워크가 감소한 깊이를 충분히 보상할 수 있을까요? WRN은 반대 아이디어에 초점을 맞춥니다: 깊이보다는 너비입니다.
1.3. 넓은 잔차 네트워크(WRN)란 무엇인가? [2]
넓은 잔차 네트워크(Wide Residual Networks, WRN)는 이름에서 알 수 있듯이 ResNet을 기반으로 합니다. 여기서 차이점은 얇고 깊은 네트워크에서 벗어나 넓고 얕은 네트워크를 추구한다는 것입니다.
너비 이해하기
우리는 이미 깊이의 개념을 다뤘지만, 너비의 개념은 여전히 생소합니다. 여기서 너비는 무엇을 의미할까요?
이는 ResNet 블록 내부의 conv3x3 레이어가 생성하는 특징 맵의 채널 수를 의미합니다. WRN은 이 출력 채널 수를 배 증가시키는 확장 인자(widening factor) 를 도입합니다.
작동 방식:
원본 ResNet의 conv3 블록이 32개의 출력 채널을 생성한다고 가정해봅시다. 이는 32개의 3D 필터가 사용되었다는 의미입니다. 여기서 중요한 점은 하나의 필터가 입력의 모든 채널을 한 번에 스캔하여(예: 이전 레이어의 출력이 16개 채널이었다면 16개 채널) 하나의 출력 채널을 생성한다는 것입니다. 이 과정이 32개의 서로 다른 필터로 반복되어 32개의 출력 채널을 생성합니다.
WRN은 이러한 필터의 총 개수(32)를 배 증가시킵니다. 즉, 이면 320개의 필터를 사용하여 320개의 출력 채널을 생성합니다. 이것은 레이어 자체의 수(깊이)를 줄이면서 하나의 컨볼루션 레이어가 더 많은 특징을 추출하도록 표현력을 증가시키는 개념입니다.
비유: 통행료 징수소 예시
원본 ResNet (얇은 블록):
- 16개 차선의 통행료 징수소
- 하나의 통행료 징수소(블록)는 한 번에 16가지 유형의 특징(차량)만 구별하고 처리할 수 있습니다
- 더 복잡한 처리를 수행하려면 1000개의 이러한 16차선 통행료 징수소를 순차적으로(깊게) 통과해야 했습니다
WRN (넓은 블록):
- 160개 차선의 통행료 징수소(확장 인자 적용)
- 하나의 통행료 징수소(블록)가 동시에 160개의 훨씬 더 다양하고 복잡한 특징을 구별하고 처리할 수 있습니다
- 하나의 블록의 '정보 처리 능력' 또는 '학습 능력(표현력)'이 10배 강해졌습니다
결론:
WRN 논문의 핵심은 1000개의 저성능 16차선 블록을 사용하는 것보다 16개의 고성능(강력한) 160차선 블록을 사용하는 것이 더 나은 결과를 가져온다는 것입니다.
2. 데이터셋
2.1. 데이터셋 정의
이 프로젝트는 가이드라인에서 예시로 제안된 표준 데이터셋 중에서 CIFAR-10 [3]을 선택했습니다.
- 선택된 데이터셋: CIFAR-10 [3]
- 작업: 10개 클래스에 대한 이미지 분류
- 데이터셋 구성: CIFAR-10 데이터셋은 각각 32×32 픽셀 해상도의 컬러 이미지 60,000개로 구성됩니다. 데이터셋은 표준 분할에 따라 50,000개의 훈련 이미지와 10,000개의 테스트 이미지로 나뉩니다. 데이터셋은 10개의 상호 배타적인 클래스를 포함합니다: 비행기(airplane), 자동차(automobile), 새(bird), 고양이(cat), 사슴(deer), 개(dog), 개구리(frog), 말(horse), 배(ship), 트럭(truck). 각 클래스는 6,000개의 이미지를 가지고 있습니다(훈련 세트에 5,000개, 테스트 세트에 1,000개).
- 프로젝트 관련성: 이 데이터셋은 이 프로젝트의 핵심 연구 질문을 탐구하기 위해 선택되었습니다: "CNN 성능에 더 효율적인 요소는 무엇인가—모델 깊이인가 너비인가?"
2.2. 데이터셋 선택 근거
-
실험을 위한 실질적인 문제: 이 프로젝트는 ResNet [1]의 "얇고 깊은" 철학과 WRN [2]의 "넓고 얕은" 철학을 비교하고 분석하는 것을 목표로 합니다. 두 기초 논문 모두 아키텍처를 검증하기 위한 주요 실험 벤치마크로 CIFAR-10 [3]을 사용했습니다. 따라서 CIFAR-10은 이 "실질적인" 연구 주제를 재현하고 분석하기에 가장 적합하고 논리적인 데이터셋입니다.
-
가이드라인 실험 설계와의 일치: 이 프로젝트는 기준선(baseline)에 상대적인 "중요한 변형"을 비교하고 분석해야 합니다.
- 기준선: ResNet [1] ("얇고 깊은")
- 수정된 모델: WRN [2] ("넓고 얕은")
가이드라인은 이러한 변형의 예시적인 사례로 "모델의 깊이 또는 너비 조정"을 명시적으로 지정합니다. ResNet을 기준선으로 설정하고 WRN을 "너비" 변형 모델로 설정하는 것은 가이드라인의 의도와 완벽하게 일치합니다.
2.3. 데이터 분할 및 전처리
2.3.1. 데이터 분할
우리는 표준 CIFAR-10 분할을 따르며, 50,000개의 훈련 이미지와 10,000개의 테스트 이미지를 사용합니다. 훈련 세트에서 10%(5,000개 이미지)를 검증 세트로 분리하여 훈련 중 모델의 일반화 성능을 모니터링합니다.
실제 데이터 분할:
- 훈련 세트: 45,000개 이미지 (원본 훈련 세트의 90%)
- 검증 세트: 5,000개 이미지 (원본 훈련 세트의 10%)
- 테스트 세트: 10,000개 이미지 (표준 CIFAR-10 테스트 세트)
- 총계: 60,000개 이미지
재현성 설정:
- 랜덤 시드: 42 (데이터 분할 및 모든 랜덤 연산에 고정)
torch.Generator().manual_seed(42)를 사용하여 실행 간 동일한 데이터 분할을 보장합니다
2.3.2. 데이터 전처리 및 증강
두 모델(ResNet과 WRN) 간의 공정한 비교를 위해 WRN [2] 논문에서 사용된 표준 증강 기법을 구현합니다.
훈련 세트 증강 (순서대로 적용):
- 패딩:
padding_mode='reflect'를 사용한 4픽셀 패딩 (이미지 경계를 반사하여 패딩) - 랜덤 수평 뒤집기: 50% 확률로 이미지를 수평으로 랜덤하게 뒤집습니다
- 랜덤 크롭: 패딩된 이미지에서 32×32 패치를 랜덤하게 크롭합니다
- ToTensor: PIL 이미지를 텐서로 변환 (값 범위: [0, 1])
- 정규화: 채널별 정규화를 적용합니다
검증 및 테스트 세트 전처리:
- 증강 없이 정규화만 적용됩니다 (원본 이미지에서 평가)
- 순서대로 적용: ToTensor → 정규화
정규화 값:
- 표준 CIFAR-10 정규화 값이 사용됩니다 (WRN 논문 [2] 참조)
- 평균 (RGB): [0.4914, 0.4824, 0.4467] (원본: [125.3, 123.0, 113.9] / 255.0)
- 표준편차 (RGB): [0.2471, 0.2435, 0.2616] (원본: [63.0, 62.1, 66.7] / 255.0)
2.3.3. DataLoader 구성
공통 설정:
- 배치 크기: 128
- 워커 수: 4 (병렬 데이터 로딩용)
- Pin Memory: True (GPU 전송 최적화용)
데이터셋별 설정:
-
훈련 DataLoader:
shuffle=True(각 에포크마다 데이터 순서를 섞음)- 에포크당 총 352개 배치 (45,000 / 128 ≈ 352)
-
검증 DataLoader:
shuffle=False(일관된 평가를 위한 고정 순서)- 총 40개 배치 (5,000 / 128 ≈ 40)
-
테스트 DataLoader:
shuffle=False(일관된 평가를 위한 고정 순서)- 총 79개 배치 (10,000 / 128 ≈ 79)
구현 세부사항:
- 검증 세트는 원본 훈련 세트에서 분할되지만 증강 없이 별도의 변환을 사용합니다.
- 검증 세트에 특별히 다른 변환을 적용하기 위해
TransformDataset클래스가 구현되었습니다.
3. 모델 설계 및 구현
핵심 연구 질문 "CNN 성능 향상을 위해 어느 요소가 더 중요한가—깊이인가 너비인가?"에 답하기 위해, 파라미터 수를 통제 변수로 하여 세 가지 모델을 비교합니다.
3.1. 공통 잔차 블록 구조
공정한 비교를 위해 모든 모델은 ResNet-v2와 WRN 논문에서 제안된 Pre-Activation 구조(BN-ReLU-Conv)를 공통 잔차 블록 아키텍처로 채택합니다. 이 구조는 기존 Conv-BN-ReLU 구조에 비해 우수한 성능과 훈련 효율성을 보이는 것으로 알려져 있습니다.
3.2. 기준선: ResNet-110
ResNet [1]은 잔차 학습을 통해 그래디언트 소실 및 성능 저하 문제를 해결하며 "깊이" 중심의 아키텍처 설계를 제시했습니다. 이 실험에서는 기준선으로 ResNet-110을 채택하며, "깊고 얇은" 모델(파라미터: 약 1.7M, 확장 인자 : 1)로 "깊이" 철학을 대표합니다.
3.2.1. 네트워크 구조
CIFAR-10 데이터셋을 위해 설계된 표준 ResNet-110 구조를 사용합니다. CIFAR-10용 ResNet의 깊이는 다음과 같이 정의됩니다:
ResNet-110은 인 네트워크입니다. 네트워크는 conv1 레이어 이후 3개의 스테이지(16, 32, 64 채널)로 구성되며, 각 스테이지는 , 즉 18개의 잔차 블록을 포함합니다.
3.3. 변형 모델: WRN
WRN [2]은 단순히 깊이를 증가시키는 것이 비효율적임(특징 재사용 감소)을 지적하고, ResNet 블록의 너비(채널 수)를 증가시키는 것이 더 효과적일 수 있다는 관점을 제시합니다. 따라서 WRN은 "너비" 중심 철학의 대표 모델로 채택됩니다.
3.3.1. 변형 1: WRN-28-2
이 실험의 핵심은 "파라미터 예산"을 통제하는 것입니다. 우리는 첫 번째 변형 모델로 WRN-28-2를 채택하며, 이는 기준선 ResNet-110(약 1.7M)과 가장 유사한 파라미터 수(약 1.5M)를 가지면서도 "너비" 철학을 명확히 보여줍니다.
모델 구조: WRN-28-2는 총 28개의 컨볼루션 레이어와 확장 인자 를 가집니다.
핵심 비교: 이 설계를 통해 약 1.5M~1.7M의 동일한 파라미터 예산 하에서 어떤 모델이 우수한 성능과 효율성을 보이는지 직접 비교합니다: "110 레이어/너비 인자 1의 ResNet" 대 "28 레이어/너비 인자 2의 WRN".
3.3.2. 변형 2: WRN-28-2 + Dropout
잔차 블록의 너비가 증가하면(파라미터 증가) 과적합 위험도 증가할 수 있습니다. 이를 완화하기 위해 WRN 논문에서 제안한 접근 방식을 따라 WRN-28-2 모델의 잔차 블록에 Dropout을 삽입합니다.
모델 구조: Dropout은 잔차 블록 내부의 두 Conv(3×3) 레이어 사이에 위치합니다 (즉, BN-ReLU-Conv-Dropout-BN-ReLU-Conv).
실험 목적: 이 모델을 통해 WRN-28-2의 일반화 성능을 더욱 개선할 수 있는지 검증할 수 있습니다.
3.4. 기준 모델(ResNet) 구현
# ResNet-110
import torch
import torch.nn as nn
import torch.nn.functional as F
class PreActBlock(nn.Module):
"""Pre-Activation Residual Block (BN-ReLU-Conv)"""
def __init__(self, in_channels, out_channels, stride=1):
super(PreActBlock, self).__init__()
self.bn1 = nn.BatchNorm2d(in_channels)
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
# Shortcut connection
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False)
else:
self.shortcut = nn.Identity()
def forward(self, x):
# Pre-activation: BN -> ReLU -> Conv
out = F.relu(self.bn1(x))
out = self.conv1(out)
out = F.relu(self.bn2(out))
out = self.conv2(out)
return out + self.shortcut(x)
class ResNet110(nn.Module):
"""
ResNet-110 for CIFAR-10
Depth = 6n + 2 = 110, where n = 18
Pre-Activation structure (BN-ReLU-Conv)
"""
def __init__(self, num_classes=10):
super(ResNet110, self).__init__()
n = 18 # 6n + 2 = 110
# First conv layer: 3 -> 16 channels
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1, bias=False)
# Stage 1: 16 channels, 18 blocks (32x32)
self.stage1 = self._make_layer(16, 16, n, stride=1)
# Stage 2: 16 -> 32 channels, 18 blocks (16x16)
self.stage2 = self._make_layer(16, 32, n, stride=2)
# Stage 3: 32 -> 64 channels, 18 blocks (8x8)
self.stage3 = self._make_layer(32, 64, n, stride=2)
# Final BN and ReLU
self.bn = nn.BatchNorm2d(64)
# Global Average Pooling and FC
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(64, num_classes)
# Initialize weights
self._initialize_weights()
def _make_layer(self, in_channels, out_channels, num_blocks, stride):
layers = []
# First block may have stride > 1 or different channels
layers.append(PreActBlock(in_channels, out_channels, stride))
# Remaining blocks have same channels and stride=1
for _ in range(1, num_blocks):
layers.append(PreActBlock(out_channels, out_channels, stride=1))
return nn.Sequential(*layers)
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.constant_(m.bias, 0)
def forward(self, x):
# First conv
x = self.conv1(x)
# Three stages
x = self.stage1(x)
x = self.stage2(x)
x = self.stage3(x)
# Final BN, ReLU, and pooling
x = F.relu(self.bn(x))
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x3.5. 수정된 모델(WRN) 구현
# WRN-28-2
import torch
import torch.nn as nn
import torch.nn.functional as F
class WideBasicBlock(nn.Module):
"""Wide Residual Block with Pre-Activation structure"""
def __init__(self, in_channels, out_channels, stride=1, dropout_rate=0.0):
super(WideBasicBlock, self).__init__()
self.bn1 = nn.BatchNorm2d(in_channels)
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.dropout = nn.Dropout(dropout_rate) if dropout_rate > 0 else nn.Identity()
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
# Shortcut connection
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False)
else:
self.shortcut = nn.Identity()
def forward(self, x):
# Pre-activation: BN -> ReLU -> Conv
out = F.relu(self.bn1(x))
out = self.conv1(out)
# Second conv: BN -> ReLU -> [Dropout] -> Conv
out = F.relu(self.bn2(out))
out = self.dropout(out)
out = self.conv2(out)
# Shortcut connection
if self.shortcut.__class__.__name__ != 'Identity':
shortcut = self.shortcut(x)
else:
shortcut = x
return out + shortcut
class WRN28_2(nn.Module):
"""
Wide Residual Network-28-2 for CIFAR-10
Depth = 6n + 4 = 28, where n = 4
Widening factor k = 2
Pre-Activation structure (BN-ReLU-Conv)
"""
def __init__(self, num_classes=10, dropout_rate=0.0):
super(WRN28_2, self).__init__()
n = 4 # 6n + 4 = 28
k = 2 # widening factor
# First conv layer: 3 -> 16 channels
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1, bias=False)
# Stage 1: 16 -> 32 channels (16*k), 4 blocks (32x32)
self.stage1 = self._make_layer(16, 16 * k, n, stride=1, dropout_rate=dropout_rate)
# Stage 2: 32 -> 64 channels (32*k), 4 blocks (16x16)
self.stage2 = self._make_layer(16 * k, 32 * k, n, stride=2, dropout_rate=dropout_rate)
# Stage 3: 64 -> 128 channels (64*k), 4 blocks (8x8)
self.stage3 = self._make_layer(32 * k, 64 * k, n, stride=2, dropout_rate=dropout_rate)
# Final BN and ReLU
self.bn = nn.BatchNorm2d(64 * k)
# Global Average Pooling and FC
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(64 * k, num_classes)
# Initialize weights
self._initialize_weights()
def _make_layer(self, in_channels, out_channels, num_blocks, stride, dropout_rate):
layers = []
# First block may have stride > 1 or different channels
layers.append(WideBasicBlock(in_channels, out_channels, stride, dropout_rate))
# Remaining blocks have same channels and stride=1
for _ in range(1, num_blocks):
layers.append(WideBasicBlock(out_channels, out_channels, stride=1, dropout_rate=dropout_rate))
return nn.Sequential(*layers)
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.constant_(m.bias, 0)
def forward(self, x):
# First conv
x = self.conv1(x)
# Three stages
x = self.stage1(x)
x = self.stage2(x)
x = self.stage3(x)
# Final BN, ReLU, and pooling
x = F.relu(self.bn(x))
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x3.5. 학습 설정 및 하이퍼파라미터
공정한 비교를 위해 모든 모델(ResNet-110, WRN-28-2, WRN-28-2 + Dropout)에 동일한 학습 환경과 하이퍼파라미터를 적용합니다. 이러한 설정은 WRN 논문 [2]의 표준 실험 구성을 따릅니다.
3.5.1. 공통 하이퍼파라미터
최적화 설정:
- 옵티마이저: 모멘텀을 사용한 SGD (확률적 경사 하강법)
- 초기 학습률: 0.1
- 모멘텀: 0.9
- 가중치 감쇠: 0.0005 (L2 정규화)
- 학습률 스케줄: 다단계 감소
- 초기 학습률 0.1로 시작
- 에포크 60, 120, 160에서 학습률이 0.2배씩 감소합니다 (즉, 0.1 → 0.02 → 0.004 → 0.0008)
- 이는 WRN 논문에서 제안한 표준 스케줄입니다
학습 설정:
- 배치 크기: 128
- 총 에포크: 200
- WRN 논문 [2]의 표준 설정을 따릅니다
- ResNet 논문 [1]은 64k 반복(약 164 에포크)을 사용했지만, WRN과의 공정한 비교를 위해 200 에포크로 통일했습니다
- 45,000개 샘플의 훈련 세트와 배치 크기 128: 1 에포크 ≈ 352 반복, 200 에포크 ≈ 70,400 반복
- 손실 함수: 교차 엔트로피 손실
- 랜덤 시드: 42 (재현성을 위해 고정)
데이터 로딩:
- 워커 수: 4 (병렬 데이터 로딩용)
- Pin Memory: True (GPU 전송 최적화용)
3.5.2. 모델별 설정
WRN-28-2 + Dropout:
- Dropout 비율: 0.3
- Dropout은 WideBasicBlock 내부의 두 번째 Conv 레이어 앞에 적용됩니다 (BN-ReLU-Dropout-Conv 구조)
ResNet-110 & WRN-28-2 (기준선):
- Dropout을 사용하지 않습니다
3.5.3. 학습 과정
- 검증 모니터링: 각 에포크마다 검증 세트에서 성능을 평가하여 모델의 일반화 성능을 모니터링합니다.
- 조기 종료: 검증 손실이 일정 에포크 동안 개선되지 않으면 조기 종료를 고려할 수 있습니다 (선택사항).
- 모델 체크포인트 저장: 최고 검증 성능을 보인 모델이 저장됩니다.
3.5.4. 하이퍼파라미터 선택 근거
이러한 하이퍼파라미터 설정은 다음과 같은 이유로 선택되었습니다:
- 논문 재현성: WRN 논문 [2]과 ResNet 논문 [1] 모두에서 CIFAR-10 실험에 사용된 표준 설정을 따릅니다.
- 공정한 비교: 모든 모델에 동일한 하이퍼파라미터를 적용함으로써 모델 아키텍처의 차이만 비교할 수 있습니다.
- 검증된 설정: 이러한 설정은 CIFAR-10에서 널리 사용되며 검증된 성능을 보장합니다.
4. 평가 및 분석
4.1. 모델 학습
4.2. 모델 테스트

혼동 행렬 (Confusion Matrix) - 각 모델의 클래스별 예측 정확도
4.2.1. 테스트 요약
4.2.1.1. 전체 성능 비교
세 모델(ResNet-110, WRN-28-2, WRN-28-2-Dropout)의 테스트 결과를 비교하면, WRN-28-2-Dropout 모델이 최고의 전체 성능을 보였으며, WRN 시리즈 모델은 대부분의 작업에서 기준선 ResNet-110 모델을 일반적으로 능가했습니다.
| 모델 | 테스트 손실 | 테스트 정확도 | 검증 정확도 | 체크포인트 에포크 |
|---|---|---|---|---|
| ResNet-110 | 0.266 | 94.29% | 94.36% | 172 |
| WRN-28-2 | 0.215 | 94.62% | 95.24% | 195 |
| WRN-28-2-Dropout | 0.199 | 94.75% | 95.14% | 196 |
WRN-28-2-Dropout은 정확도와 손실 측면에서 최고 성능을 달성했습니다. 다음 증거들은 Dropout이 모델의 일반화 성능을 개선했음을 시사합니다:
-
테스트 정확도 개선: WRN-28-2-Dropout의 테스트 정확도(94.75%)는 WRN-28-2(94.62%)보다 0.13%p 높습니다. 테스트 정확도는 보지 못한 데이터에 대한 성능을 평가하는 가장 중요한 지표입니다.
-
테스트 손실 감소: WRN-28-2-Dropout의 테스트 손실(0.199)은 WRN-28-2(0.215)보다 약 7.5% 낮습니다. 낮은 테스트 손실은 모델이 더 정확한 예측을 한다는 것을 나타냅니다.
-
검증-테스트 격차 감소:
- WRN-28-2: 검증 정확도(95.24%)와 테스트 정확도(94.62%)의 차이는 0.62%
- WRN-28-2-Dropout: 검증 정확도(95.14%)와 테스트 정확도(94.75%)의 차이는 0.39%
- 격차가 0.23%p 감소했습니다. 이는 Dropout이 모델의 일반화 능력을 개선하여 검증 세트와 테스트 세트 간의 성능 차이를 줄였다는 것을 나타냅니다.
-
과적합 방지 효과: WRN-28-2가 약간 더 높은 검증 정확도(95.24% vs 95.14%)를 보이지만, Dropout 모델은 더 높은 테스트 정확도를 보입니다. 이는 Dropout이 모델이 검증 세트에 과적합되는 것을 방지하고 실제 테스트 세트에서의 성능을 개선했다는 것을 시사합니다.
이러한 발견 사항을 바탕으로, Dropout이 모델의 일반화 성능 개선에 도움이 되었다고 결론지을 수 있습니다.
4.2.1.2. 기준선 vs 개선된 모델 성능 비교
ResNet-110 (기준선) vs WRN-28-2:
- 테스트 정확도: 94.29% → 94.62% (+0.33%p)
- 테스트 손실: 0.266 → 0.215 (-19.2%)
- WRN-28-2는 더 얕은 깊이(28 레이어)로 더 나은 성능을 달성했습니다
WRN-28-2 vs WRN-28-2-Dropout:
- 테스트 정확도: 94.62% → 94.75% (+0.13%p)
- 테스트 손실: 0.215 → 0.199 (-7.4%)
- Dropout 적용으로 일반화 성능이 개선되었습니다
수정 사항의 효과:
WRN 아키텍처의 "넓은" 접근 방식(채널 너비 증가)이 CIFAR-10에서 ResNet의 "깊은" 접근 방식보다 더 효과적임을 확인했습니다. 또한 Dropout의 도입은 모델의 일반화 능력을 개선하여 테스트 손실을 현저히 감소시켰습니다. 이는 Dropout이 모델이 훈련 데이터에 과적합되는 것을 방지하고 보지 못한 데이터에 대한 예측 성능을 개선하기 때문입니다.
4.2.1.3. 분류 보고서 분석
전체 성능 지표 비교
-
매크로 평균 (클래스별 평균):
- ResNet-110: 정밀도 0.9429, 재현율 0.9429, F1-점수 0.9428
- WRN-28-2: 정밀도 0.9461, 재현율 0.9462, F1-점수 0.9461
- WRN-28-2-Dropout: 정밀도 0.9474, 재현율 0.9475, F1-점수 0.9474
- WRN 시리즈 모델은 모든 지표에서 ResNet-110을 능가하며, WRN-28-2-Dropout이 최고 성능을 보입니다.
-
가중 평균 (지지도 가중 평균):
- 모든 모델에서 매크로 평균과 가중 평균이 거의 동일합니다. 이는 각 클래스가 동일한 지지도(1000개 샘플)를 가지기 때문입니다.
정밀도, 재현율, F1-점수 분석
-
정밀도: 모든 양성 예측 중 진짜 양성의 비율
- ResNet-110: 평균 0.9429
- WRN-28-2: 평균 0.9461 (+0.0032)
- WRN-28-2-Dropout: 평균 0.9474 (+0.0045)
- WRN 시리즈 모델이 더 정확한 예측을 합니다.
-
재현율: 모든 실제 양성 중 올바르게 예측된 양성의 비율
- ResNet-110: 평균 0.9429
- WRN-28-2: 평균 0.9462 (+0.0033)
- WRN-28-2-Dropout: 평균 0.9475 (+0.0046)
- WRN 시리즈 모델이 더 많은 양성 샘플을 올바르게 식별합니다.
-
F1-점수 (정밀도와 재현율의 조화 평균):
- ResNet-110: 평균 0.9428
- WRN-28-2: 평균 0.9461 (+0.0033)
- WRN-28-2-Dropout: 평균 0.9474 (+0.0046)
- WRN 시리즈 모델이 정밀도와 재현율 사이의 더 나은 균형을 보입니다.
클래스별 성능 패턴 분석
-
가장 높은 F1-점수를 가진 클래스:
- ResNet-110: '말' (0.9717), '자동차' (0.9691), '배' (0.9642)
- WRN-28-2: '자동차' (0.9733), '말' (0.9700), '개구리' (0.9657)
- WRN-28-2-Dropout: '자동차' (0.9756), '배' (0.9705), '말' (0.9644)
- WRN 시리즈 모델에서는 '자동차' 클래스가 최고 F1-점수를 달성했으며, ResNet-110에서는 '자동차'가 두 번째로 높은 성능을 보였습니다.
-
가장 낮은 F1-점수를 가진 클래스:
- ResNet-110: '고양이' (0.8778), '개' (0.9009), '새' (0.9291)
- WRN-28-2: '고양이' (0.8842), '개' (0.9051), '새' (0.9370)
- WRN-28-2-Dropout: '고양이' (0.8877), '새' (0.9349), '개' (0.9126)
- 모든 모델이 '고양이' 클래스에서 가장 낮은 F1-점수를 기록했습니다.
-
정밀도-재현율 균형 분석:
- ResNet-110:
- '고양이' 클래스에서 재현율(0.8510)이 정밀도(0.9063)보다 낮아 많은 고양이 샘플을 놓쳤습니다(높은 거짓 음성).
- '개' 클래스에서 정밀도(0.8844)가 재현율(0.9180)보다 낮아 많은 거짓 양성이 발생했습니다. 그러나 재현율이 높아 거짓 음성은 낮습니다.
- WRN-28-2:
- '고양이' 클래스에서 재현율(0.8820)과 정밀도(0.8864)가 균형을 이룹니다.
- '개' 클래스에서 정밀도(0.9092)가 재현율(0.9010)보다 약간 높습니다.
- WRN-28-2-Dropout:
- '고양이' 클래스에서 재현율(0.8770)과 정밀도(0.8986)가 균형을 이룹니다.
- '개' 클래스에서 재현율(0.9190)이 정밀도(0.9063)보다 약간 높아 더 많은 개 샘플을 올바르게 식별합니다.
- ResNet-110:
모델별 관찰
-
ResNet-110:
- '말' 클래스에서 매우 높은 정밀도(0.9836)를 보이지만, 재현율(0.9600)은 상대적으로 낮습니다.
- '고양이' 클래스에서 낮은 재현율(0.8510)로 인해 많은 고양이 샘플을 놓칩니다.
-
WRN-28-2:
- '자동차' 클래스에서 높은 재현율(0.9840)을 보여 대부분의 자동차를 올바르게 식별합니다.
- '고양이' 클래스에서 WRN-28-2-Dropout에 비해 더 높은 재현율(0.8820)을 보입니다.
-
WRN-28-2-Dropout:
- '자동차' 클래스에서 최고 F1-점수(0.9756)를 기록했습니다.
- '배' 클래스에서 균형 잡힌 정밀도(0.9700)와 재현율(0.9710)을 보입니다.
- 대부분의 클래스에서 정밀도와 재현율이 균형을 이루어 안정적인 성능을 보여줍니다.
4.3. 결과 분석
4.3.1. 학습 곡선 분석
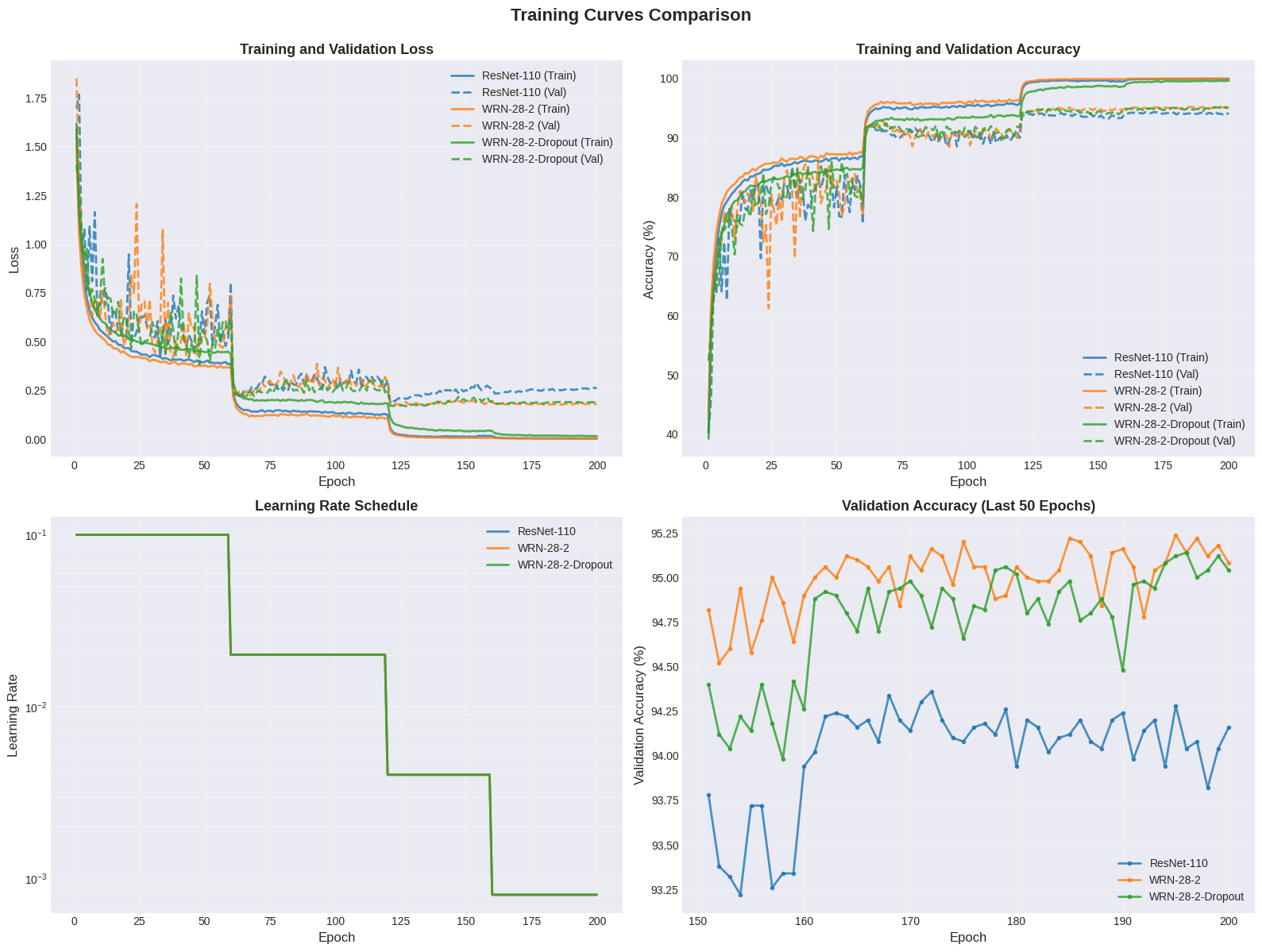
그림: 학습 곡선 비교 - 세 모델의 학습 및 검증 손실, 정확도, 학습률 스케줄
이 시각화에서 도출할 수 있는 주요 분석 통찰은 다음과 같습니다.
4.3.1.1. 전체 성능 비교 (손실 및 정확도)
- 최고 성능: WRN-28-2와 WRN-28-2-Dropout 모델은 ResNet-110에 비해 더 높은 최종 검증 정확도(Val)를 달성하고 더 낮은 최종 검증 손실(Val)에 도달했습니다.
- WRN 시리즈 모델은 100 에포크 후 약 95%의 검증 정확도로 수렴하는 반면, ResNet-110은 초기 94% 범위에서 수렴합니다.
- 학습 속도:
- 세 모델 모두 초기 50 에포크까지 빠른 성능 개선을 보이지만, WRN 시리즈 모델은 ResNet-110보다 더 빠르게 높은 정확도에 도달하는 경향이 있습니다.
- 특히 ResNet-110은 다른 모델에 비해 에포크 50과 100 사이에서 손실/정확도의 더 큰 변화를 보였습니다.
4.3.1.2. 과적합 진단
- ResNet-110: 훈련 손실(Train Loss)과 검증 손실(Val Loss) 사이에 상대적으로 큰 격차가 있습니다. 특히 100 에포크 이후 훈련 손실은 계속 감소하는 반면 검증 손실은 평평하게 유지되거나 약간 증가하는 경향이 있어 과적합 가능성을 시사합니다.
- WRN-28-2: 훈련 손실과 검증 손실 사이의 격차가 ResNet-110과 유사하게 넓어집니다.
- WRN-28-2-Dropout: 이 모델은 다른 두 모델에 비해 훈련 손실과 검증 손실 사이의 가장 작고 안정적인 격차를 보입니다. 이는 Dropout 정규화 기법이 모델의 일반화 성능을 개선하고 과적합을 완화하는 데 효과적이었음을 시사합니다.
4.3.1.3. WRN-28-2 vs WRN-28-2-Dropout 비교
- 두 모델 모두 약 95%에서 유사한 최고 성능을 보이지만, WRN-28-2의 검증 정확도 곡선(주황색 점선)은 WRN-28-2-Dropout(녹색 점선)보다 더 많이 변동하는 경향이 있습니다.
- Dropout의 적용은 학습 과정을 더 안정적으로 만들었으며, 이는 오른쪽 하단의 '검증 정확도 (마지막 50 에포크)' 그래프에서 더 명확하게 볼 수 있습니다.
4.3.1.4. 검증 정확도 (마지막 50 에포크)
- 이는 에포크 150부터 200까지의 검증 정확도를 확대한 뷰를 보여줍니다.
- **ResNet-110 (파란색)**은 초기 94% 범위에서 가장 낮고 가장 안정적인(낮은 변동성) 정확도를 유지합니다.
- **WRN-28-2 (주황색)**은 초기 95% 범위 주변에서 진동하며 최고 피크(95.5% 이상)를 기록하지만, 세 모델 중 가장 높은 변동성을 보입니다.
- **WRN-28-2-Dropout (녹색)**은 약 95% 주변에서 가장 안정적이고 일관된 성능을 유지합니다. 이는 일반화 측면에서 가장 신뢰할 수 있는 모델일 가능성을 높입니다.
4.3.2. 모델 성능 분석
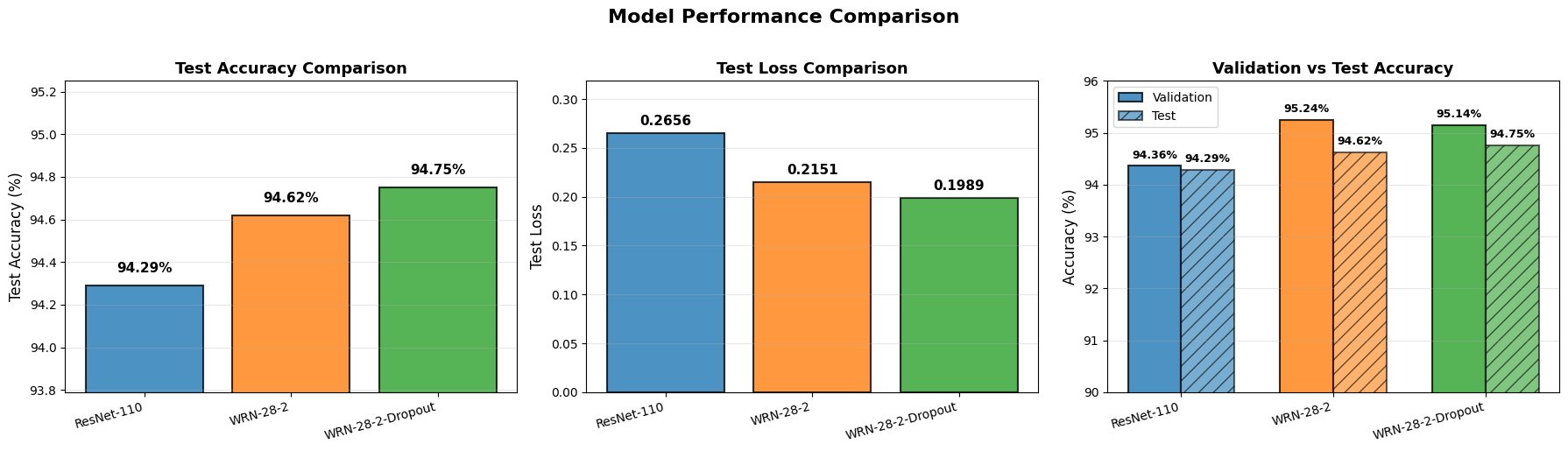
그림: 모델 성능 비교 - 테스트 정확도, 테스트 손실, 검증 vs 테스트 정확도
이 시각화는 세 모델의 최종 성능을 비교 분석할 수 있게 해줍니다.
4.3.2.1. 테스트 정확도 비교
- WRN-28-2-Dropout은 최고 테스트 정확도 94.75%를 기록했습니다.
- WRN-28-2는 두 번째로 높은 성능인 94.62%를 보였습니다.
- ResNet-110은 세 모델 중 가장 낮은 정확도인 94.29%를 기록했습니다.
- WRN 시리즈 모델은 ResNet-110보다 약 0.3-0.5%p 높은 성능을 달성했습니다.
4.3.2.2. 테스트 손실 비교
- WRN-28-2-Dropout은 최저 테스트 손실 0.1989를 기록했습니다.
- WRN-28-2는 두 번째로 낮은 손실인 0.2151을 보였습니다.
- ResNet-110은 가장 높은 손실인 0.2656을 기록했습니다.
- 테스트 정확도 결과와 일관되게, WRN 시리즈 모델은 더 낮은 손실로 더 나은 성능을 보여주었습니다.
4.3.2.3. 검증 vs 테스트 정확도 비교
-
일반화 성능 분석:
- 모든 모델이 테스트 정확도보다 약간 높은 검증 정확도를 보였습니다. 이는 정상적인 현상이며 검증 세트와 테스트 세트 간의 미세한 차이를 반영합니다.
-
ResNet-110:
- 검증 정확도: 94.36%, 테스트 정확도: 94.29% (차이: 0.07%p)
- 가장 낮은 성능을 보였지만, 검증-테스트 격차는 작습니다.
-
WRN-28-2:
- 검증 정확도: 95.24%, 테스트 정확도: 94.62% (차이: 0.62%p)
- 최고 검증 정확도를 기록했지만, 검증-테스트 격차는 세 모델 중 가장 큽니다.
- 이는 검증 세트에서의 성능이 테스트 세트로 완전히 전이되지 않았음을 시사합니다.
-
WRN-28-2-Dropout:
- 검증 정확도: 95.14%, 테스트 정확도: 94.75% (차이: 0.39%p)
- 검증-테스트 격차가 WRN-28-2보다 작아 최고의 일반화 성능을 보여줍니다.
- 이는 Dropout 정규화가 모델의 일반화 능력을 개선했음을 확인합니다.
4.3.2.4. 종합 분석
- 성능 순위: WRN-28-2-Dropout > WRN-28-2 > ResNet-110
- 일반화 능력: WRN-28-2-Dropout은 가장 작은 검증-테스트 격차로 가장 안정적인 일반화 성능을 보여줍니다.
- Dropout의 효과: Dropout의 적용은 WRN-28-2의 일반화 성능을 개선하고 검증 세트와 테스트 세트 간의 성능 격차를 줄였습니다.
4.3.3. 클래스별 성능 분석
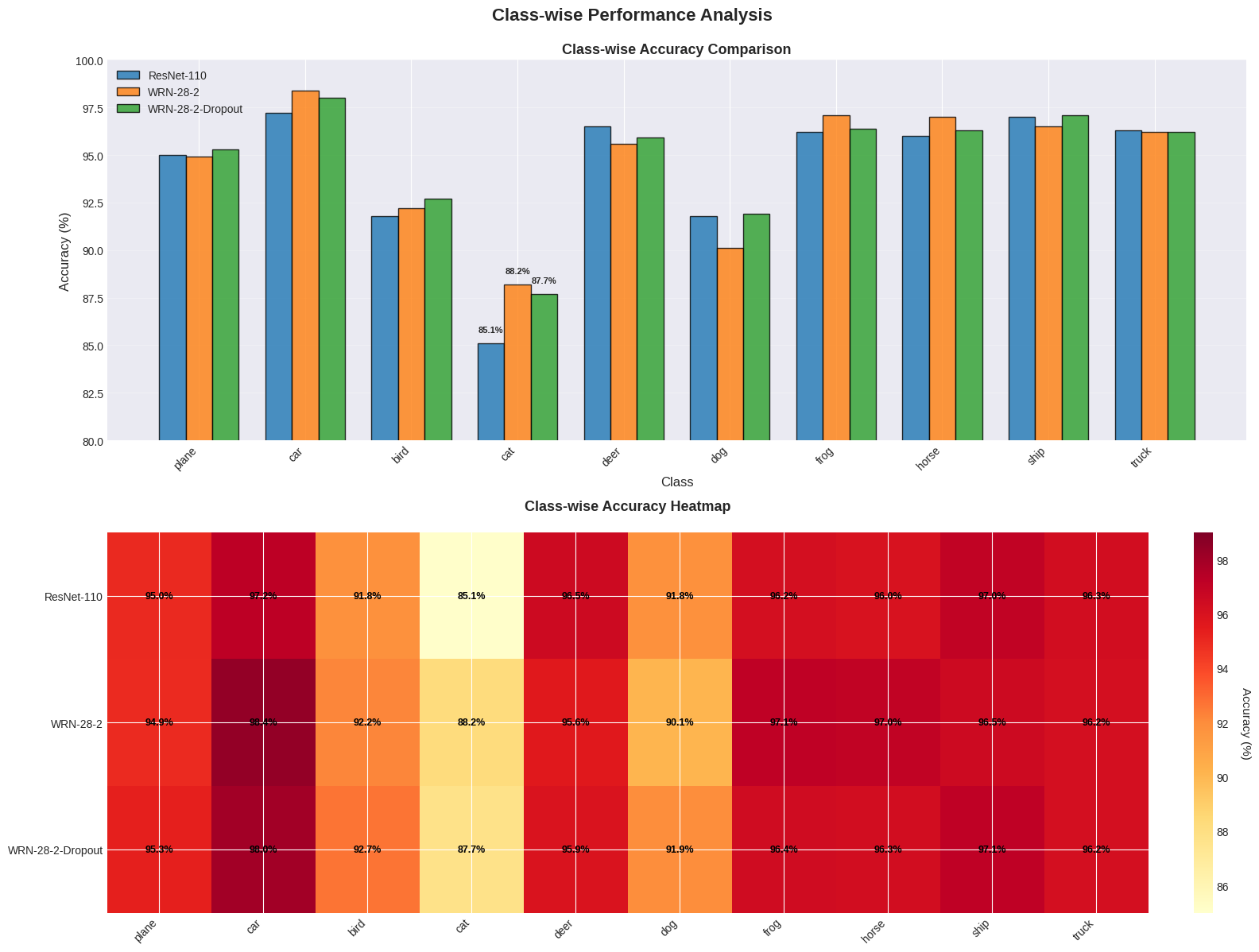
그림: 클래스별 성능 분석 - 클래스별 정확도 비교 및 히트맵
이 시각화는 세 모델의 클래스별 성능을 상세히 분석할 수 있게 해줍니다.
4.3.3.1. 클래스별 정확도 비교
전체 성능 추세
- WRN 시리즈 모델의 우위: WRN-28-2와 WRN-28-2-Dropout은 대부분의 클래스에서 ResNet-110보다 높은 정확도를 보입니다.
- 성능 개선 범위: WRN 시리즈 모델은 평균적으로 ResNet-110보다 1-3%p 높은 정확도를 달성했습니다.
클래스별 상세 분석
-
가장 잘 분류된 클래스: '자동차'
- 모든 모델이 97% 이상의 높은 정확도를 기록했습니다.
- WRN-28-2가 98.40%로 최고 성능을 보였습니다.
- '자동차' 클래스는 명확한 형태학적 특징(바퀴, 창문, 도로 위 위치 등)으로 인해 상대적으로 구별하기 쉬운 것으로 보입니다.
-
가장 어려운 클래스: '고양이'
- 모든 모델이 가장 낮은 정확도를 기록한 클래스입니다.
- ResNet-110: 85.10% (최저)
- WRN-28-2: 88.20% (ResNet-110 대비 3.1%p 개선)
- WRN-28-2-Dropout: 87.70% (ResNet-110 대비 2.6%p 개선)
- '고양이' 클래스는 다른 동물 클래스(새, 사슴, 개 등)와의 유사성으로 인해 분류하기 어려운 것으로 보입니다.
-
높은 성능을 보인 클래스
- '배': WRN-28-2-Dropout이 97.10%로 최고 정확도를 기록했습니다.
- '트럭': ResNet-110이 96.30%로 최고 정확도를 기록했습니다.
- '사슴': ResNet-110이 96.50%로 최고 정확도를 기록했습니다.
- '개구리': WRN-28-2가 97.10%로 최고 정확도를 기록했습니다.
- '말': WRN-28-2가 97.00%로 최고 정확도를 기록했습니다.
-
모델별 관찰
- '개' 클래스: ResNet-110(91.80%)이 WRN-28-2(90.10%)보다 약간 높은 성능을 보였지만, WRN-28-2-Dropout(91.90%)이 ResNet-110보다 약간 높은 성능을 달성했습니다.
- '비행기' 클래스: WRN-28-2-Dropout(95.30%)이 최고 정확도를 기록했습니다.
4.3.3.2. 클래스별 정확도 히트맵
-
색상 분포 분석:
- ResNet-110 행은 전반적으로 밝은 색상(낮은 정확도)을 보이는 경향이 있지만, '사슴'과 '트럭' 클래스에서는 상대적으로 어두운 색상을 보입니다.
- WRN-28-2와 WRN-28-2-Dropout 행은 전반적으로 어두운 색상(높은 정확도)을 보이며, 특히 '자동차', '개구리', '배' 클래스에서 진한 빨간색이 눈에 띕니다.
-
'고양이' 클래스 특이성:
- 세 모델 모두 '고양이' 클래스에 대해 가장 밝은 노란색 톤을 보이며, 이는 막대 그래프에서 확인된 낮은 정확도와 일치합니다.
- ResNet-110이 가장 밝은 노란색을 보여 가장 낮은 정확도(85.1%)를 나타냅니다.
4.3.3.3. 최고/최저 성능 클래스 요약
-
ResNet-110:
- 최고: '자동차' (97.20%)
- 최저: '고양이' (85.10%)
- 성능 차이: 12.1%p
-
WRN-28-2:
- 최고: '자동차' (98.40%)
- 최저: '고양이' (88.20%)
- 성능 차이: 10.2%p
-
WRN-28-2-Dropout:
- 최고: '자동차' (98.00%)
- 최저: '고양이' (87.70%)
- 성능 차이: 10.3%p
4.3.3.4. Dropout 효과 분석
클래스별 최고 성능 비교
-
클래스별 최고 성능 분포:
- ResNet-110 최고 성능: '사슴' (96.50%), '트럭' (96.30%) - 2개 클래스
- WRN-28-2 최고 성능: '자동차' (98.40%), '고양이' (88.20%), '개구리' (97.10%), '말' (97.00%) - 4개 클래스
- WRN-28-2-Dropout 최고 성능: '비행기' (95.30%), '새' (92.70%), '개' (91.90%), '배' (97.10%) - 4개 클래스
-
흥미로운 관찰:
- 클래스별 최고 성능 측면에서, WRN-28-2와 WRN-28-2-Dropout은 각각 4개 클래스에서 최고 성능을 달성하여 동일한 수를 보입니다.
- 그러나 전체 테스트 정확도는 WRN-28-2-Dropout(94.75%)이 WRN-28-2(94.62%)보다 높습니다.
- 이는 최고 성능을 보인 클래스 수가 동일하더라도 평균 성능 분포가 다를 수 있음을 시사합니다.
Dropout의 일반화 효과 해석
-
평균 정확도 vs 최고 성능 차이:
- WRN-28-2-Dropout이 더 높은 평균 정확도를 보이는 이유는 성능 분산이 감소했기 때문입니다.
- WRN-28-2는 일부 클래스에서 매우 높은 성능을 보입니다(예: '자동차' 98.40%, '개구리' 97.10%, '말' 97.00%), 하지만 다른 클래스에서는 상대적으로 낮은 성능을 보입니다(예: '개' 90.10%, '비행기' 94.90%).
- 대조적으로, WRN-28-2-Dropout은 최고 성능을 보인 클래스 수는 동일하지만, 최고 성능을 달성하지 못한 클래스에서도 더 안정적이고 균형 잡힌 성능을 보입니다.
-
Dropout의 역할:
- Dropout은 모델이 특정 클래스에 과도하게 특화되는 것을 방지하고 모든 클래스에 걸쳐 균등하게 학습하도록 장려합니다.
- 이는 개별 클래스에 대한 최고 성능을 낮출 수 있지만, 전체 평균 성능과 일반화 능력을 개선합니다.
- WRN-28-2-Dropout의 더 작은 검증-테스트 성능 격차(0.39%p vs 0.62%p)가 이러한 일반화 효과를 뒷받침합니다.
-
특별 참고사항: '고양이' 클래스에서 WRN-28-2(88.20%)가 WRN-28-2-Dropout(87.70%)보다 약간 높은 성능을 보였습니다. 이는 Dropout이 특정 클래스에 대한 성능을 약간 감소시킬 수 있지만, 전체 일반화 성능 개선이라는 더 큰 목표를 달성하는 데 도움이 됨을 시사합니다.
4.3.3.5. 종합 분석
- WRN 시리즈 모델의 우위: WRN-28-2와 WRN-28-2-Dropout은 전반적으로 ResNet-110에 비해 우수한 클래스별 분류 정확도를 보입니다. 그러나 ResNet-110은 '사슴'과 '트럭' 클래스에서 최고 성능을 기록했습니다.
- 클래스별 난이도: '고양이' 클래스는 모든 모델에 대해 가장 어려운 작업이었으며, WRN 시리즈 모델은 이 클래스에서 ResNet-110에 비해 더 나은 성능을 달성했습니다.
- 성능 분산: WRN 시리즈 모델은 ResNet-110보다 클래스 간 성능 차이가 작아 더 균형 잡힌 성능을 보여줍니다.
- Dropout의 효과:
- WRN-28-2와 WRN-28-2-Dropout은 각각 4개 클래스에서 최고 성능을 기록하여 동일한 수를 보입니다.
- 그러나 WRN-28-2-Dropout은 전체 테스트 정확도(94.75%)에서 더 높은 성능을 보이는데, 이는 최고 성능을 달성하지 못한 클래스에서도 더 안정적이고 균형 잡힌 성능을 보이기 때문입니다.
- 특히, 더 작은 검증-테스트 성능 격차(0.39%p vs 0.62%p)는 Dropout이 모델의 일반화 능력 개선에 기여했음을 확인합니다.
4.4. 모델 효율성 분석
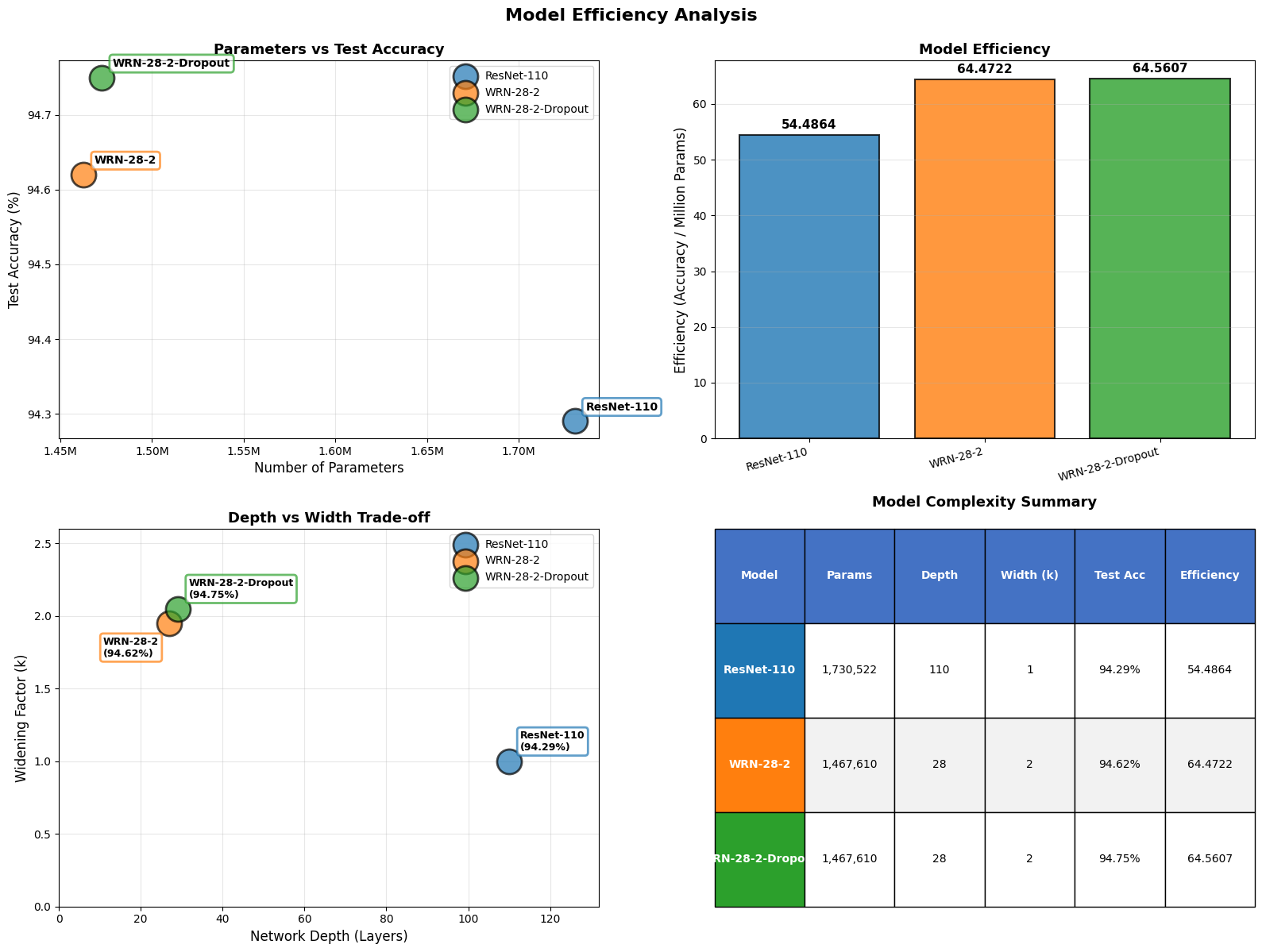
그림: 모델 효율성 분석 - 파라미터 vs 정확도, 효율성, 깊이 vs 너비 트레이드오프
이 시각화는 세 모델의 효율성을 종합적으로 분석할 수 있게 해줍니다.
4.4.1. 파라미터 vs 테스트 정확도
-
WRN 시리즈 모델의 우위:
- WRN-28-2와 WRN-28-2-Dropout은 ResNet-110에 비해 약 15% 적은 파라미터(1.47M vs 1.73M)로 더 높은 정확도를 달성했습니다.
- WRN-28-2-Dropout은 ResNet-110보다 약 262,000개 적은 파라미터로 최고 정확도(94.75%)를 기록했습니다.
-
효율성 비교:
- ResNet-110: 1.73M 파라미터로 94.29% 정확도
- WRN-28-2: 1.47M 파라미터로 94.62% 정확도 (+0.33%p 개선, 15% 파라미터 감소)
- WRN-28-2-Dropout: 1.47M 파라미터로 94.75% 정확도 (+0.46%p 개선, 15% 파라미터 감소)
4.4.2. 모델 효율성
-
효율성 지표: 효율성 = 테스트 정확도 / (파라미터 / 1,000,000)
- 이 지표는 백만 파라미터당 달성된 정확도를 나타냅니다.
- 높은 효율성은 더 적은 파라미터로 더 높은 성능을 달성함을 의미합니다.
-
효율성 비교:
- ResNet-110: 54.4864
- WRN-28-2: 64.4722 (+18.3% 개선)
- WRN-28-2-Dropout: 64.5607 (+18.5% 개선)
- WRN 시리즈 모델은 ResNet-110보다 약 18% 높은 효율성을 보입니다.
-
해석:
- WRN 시리즈 모델은 ResNet-110에 비해 파라미터당 약 18% 높은 성능을 달성했습니다.
- 이는 동일한 파라미터 예산으로 더 높은 정확도를 얻을 수 있음을 의미합니다.
4.4.3. 깊이 vs 너비 트레이드오프
-
아키텍처 비교:
- ResNet-110: 깊고 얇은 구조 (깊이: 110 레이어, 너비: k=1)
- WRN-28-2 & WRN-28-2-Dropout: 얕고 넓은 구조 (깊이: 28 레이어, 너비: k=2)
-
성능 비교:
- ResNet-110은 110 레이어를 사용하여 94.29% 정확도를 달성했습니다.
- WRN 시리즈 모델은 28 레이어(약 75% 감소)로 더 높은 정확도(94.62%, 94.75%)를 달성했습니다.
-
핵심 통찰:
- "넓고 얕은" 구조가 CIFAR-10에서 "깊고 얇은" 구조보다 더 효율적입니다.
- WRN의 확장 인자(k=2)가 ResNet-110의 깊이(110 레이어)보다 더 효과적인 표현력을 제공했습니다.
- 이는 WRN 논문의 핵심 주장인 "너비가 깊이보다 더 효율적"임을 뒷받침합니다.
4.4.4. 모델 복잡도 요약
-
파라미터 수:
- ResNet-110: 1,730,522 (가장 많음)
- WRN-28-2 & WRN-28-2-Dropout: 1,467,610 (약 15% 적음)
-
네트워크 깊이:
- ResNet-110: 110 레이어 (가장 깊음)
- WRN-28-2 & WRN-28-2-Dropout: 28 레이어 (약 75% 감소)
-
네트워크 너비:
- ResNet-110: k=1 (기본값)
- WRN-28-2 & WRN-28-2-Dropout: k=2 (2배 확장)
-
성능:
- ResNet-110: 94.29% (최저)
- WRN-28-2: 94.62% (+0.33%p)
- WRN-28-2-Dropout: 94.75% (+0.46%p, 최고)
4.4.5. 종합 분석
-
효율성 우위: WRN 시리즈 모델은 ResNet-110보다 약 18% 높은 효율성을 보이며, 더 적은 파라미터로 더 높은 성능을 달성합니다.
-
아키텍처 효율성: "넓고 얕은" 구조(WRN)가 CIFAR-10에서 "깊고 얇은" 구조(ResNet-110)보다 더 효율적입니다. 28개의 넓은 레이어가 110개의 얇은 레이어보다 더 나은 성능을 제공했습니다.
-
Dropout의 효과:
- 파라미터 효율성 개선: WRN-28-2-Dropout은 WRN-28-2와 동일한 파라미터 수(1,467,610)를 사용하면서 더 높은 정확도(94.75% vs 94.62%)와 효율성(64.5607 vs 64.4722)을 달성했습니다. 이는 동일한 파라미터 예산으로 더 높은 성능을 얻을 수 있음을 의미합니다.
- 일반화 능력 향상: Dropout은 모델의 일반화 능력을 개선하여 검증 세트와 테스트 세트 간의 성능 격차를 줄였습니다(WRN-28-2: 0.62%p → WRN-28-2-Dropout: 0.39%p). 이는 더 안정적이고 신뢰할 수 있는 성능을 제공하여 실용적 효율성을 높입니다.
- 과적합 방지: Dropout은 모델이 특정 클래스나 패턴에 과도하게 특화되는 것을 방지하여 모든 클래스에 걸쳐 균형 잡힌 성능을 제공합니다. 이는 개별 클래스에 대한 최고 성능을 낮출 수 있지만, 전체 평균 성능과 효율성이 개선됩니다.
- 실용적 가치: 동일한 모델 크기와 파라미터 수를 유지하면서 성능을 개선할 수 있어, 추가 계산 비용 없이 효율성을 향상시킬 수 있습니다.
-
실용적 함의: 동일한 파라미터 예산으로 더 높은 성능을 달성할 수 있으며, 더 적은 레이어는 학습 시간과 추론 시간을 모두 줄일 수 있습니다.
5. 결론
5.1. 발견 사항 및 주요 통찰
이 실험은 CNN 성능 향상을 위해 어느 요소가 더 효율적인지 비교하고 분석하는 것을 목표로 했습니다: '깊이' 또는 '너비'. 이를 위해 유사한 파라미터 예산(약 1.5M ~ 1.7M)을 가진 '깊고 얇은' 모델(ResNet-110)과 '넓고 얕은' 모델(WRN-28-2)을 CIFAR-10 데이터셋에서 학습하고 평가했습니다.
실험을 통해 다음과 같은 주요 통찰을 도출했습니다:
-
'너비' 효율성의 증명 (예산 하에서 너비 > 깊이):
'넓고 얕은' WRN-28-2 모델(1.5M 파라미터)은 '깊고 얇은' ResNet-110 모델(1.7M 파라미터)보다 약 15% 적은 파라미터를 사용함에도 불구하고 테스트 정확도(94.29% vs 94.62%)에서 약간의 우위를 보였습니다. 이는 ResNet을 통해 증명된 '깊이'의 중요성에 더하여, 잔차 블록의 '너비' 확장이 모델 성능 향상을 위한 매우 효과적이고 효율적인 접근 방식임을 시사합니다. -
테스트 손실의 현저한 감소:
성능 차이는 테스트 손실에서 더욱 두드러졌습니다. WRN 시리즈 모델은 ResNet-110(0.2656)에 비해 현저히 낮은 손실 값을 기록했습니다(WRN-28-2: 0.2151). 이는 '넓은' 모델이 더 확신 있는 예측을 하고 더 나은 일반화 성능을 가진다는 것을 나타냅니다. -
Dropout을 통한 일반화 성능 개선:
WRN-28-2 모델에 Dropout(0.3)을 적용한 WRN-28-2-Dropout 모델은 테스트 정확도(94.75%)와 테스트 손실(0.1989) 모두에서 최고 성능을 달성했습니다. 특히 ResNet-110에 비해 약 25% 낮은 손실을 기록하여, Dropout이 과적합을 효과적으로 방지하고 모델의 일반화 성능을 최대화하는 데 기여한다는 것을 실험적으로 증명했습니다. -
계산 비용 감소 및 병렬 처리 이점:
15% 적은 파라미터에도 불구하고 더 높은 성능을 달성한다는 것은 모델 학습 및 추론에 필요한 계산 비용의 감소를 기대할 수 있음을 의미합니다. 또한 ResNet-110(110 레이어)보다 훨씬 적은 레이어(28)를 가진 WRN 아키텍처는 순차 계산에 대한 의존성이 낮고 넓은 레이어를 가지므로, GPU 기반 병렬 처리 환경에서 더 빠른 계산 속도의 잠재력을 보여줍니다.
결론적으로, 이 실험은 '깊이'의 무조건적인 확장이 최적이 아닐 수 있으며, 제한된 자원 내에서 '너비'를 확장하는 것이 더 효율적인 성능 개선 전략이 될 수 있음을 보여줍니다.
5.2. 향후 연구 방향
이 연구의 발견 사항을 바탕으로 모델을 더욱 발전시키기 위한 다음과 같은 향후 연구 방향을 제안합니다:
-
병렬 환경에서의 계산 효율성 검증:
GPU 병렬 처리 환경에서 '넓고 얕은' 모델의 이점을 정량적으로 분석할 필요가 있습니다. ResNet-110과 실제 학습 시간 및 추론 속도를 비교하고 측정함으로써, 너비 확장이 계산 효율성에 미치는 영향을 검증할 수 있습니다. -
다른 데이터셋 및 도메인에의 적용:
CIFAR-10을 넘어서 ImageNet 및 CIFAR-100과 같은 더 크고 복잡한 데이터셋이나 다른 도메인의 데이터(예: 의료 영상 또는 위성 이미지)에 WRN 모델을 적용하여 '너비'의 효율성이 일반화될 수 있는지 확인할 필요가 있습니다. -
다양한 일반화 기법의 적용:
이 연구는 Dropout의 효과를 확인했습니다. 향후 연구는 최근 데이터 증강 기법(예: CutMix, Mixup)이나 Label Smoothing과 같은 다른 일반화 방법을 WRN 아키텍처에 적용하여 성능을 최대화할 수 있는 조합을 탐구해야 합니다.
참고 문헌
-
He, Kaiming, et al. "Deep residual learning for image recognition." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
-
Zagoruyko, Sergey, and Nikos Komodakis. "Wide Residual Networks." Proceedings of the British Machine Vision Conference (BMVC). 2016. https://github.com/szagoruyko/wide-residual-networks
-
CIFAR-10 Dataset: https://www.cs.toronto.edu/~kriz/cifar.html
