Jolicoeur-Martineau, Alexia. "Less is More: Recursive Reasoning with Tiny Networks.", arXiv, 2025.
https://github.com/SamsungSAILMontreal/TinyRecursiveModels
시작하며
리뷰에 앞서: 2025년 10월, 삼성 AI 연구팀 SAIL Montreal에서 새로운 재귀 추론 모델을 공개했습니다.
국내 기사들에서는 “Google Gemini를 이겼다”라는 문구로 꽤 화제가 됐죠.
솔직히 결론부터 말하면, “맞지만, 반은 틀린 이야기”입니다. 왜 그런지 논문 내용을 차근차근 보며 이해해봅시다.
연구팀은 구현 코드를 GitHub에 공개했습니다. 직접 코드와 함께 보면 이해가 더 빨라요.
https://github.com/SamsungSAILMontreal/TinyRecursiveModels
LLM만 알면 부족하다? HRM부터 보자
우리가 익숙한 건 LLM(Large Language Model, 대규모 언어모델) 이고, HRM(Hierarchical Reasoning Model, 계층적 추론 모델) 은 생소할 수 있어요.
한 줄 요약: HRM은 “재귀(Recursion, 재귀)”를 활용해 작은 네트워크로 깊은 추론을 흉내 내는 방법론입니다.
“층과 파라미터를 더 쌓는 대신, 같은 네트워크를 여러 번 돌려 단계적으로 답을 개선한다”는 아이디어예요.
삼성 연구팀은 이 HRM을 더 단순하게 만든 TRM(Tiny Recursive Model, 초소형 재귀 모델, 파라미터 7M) 을 제안합니다.
논문에 따르면 ARC-AGI-1 45%, ARC-AGI-2 8% 성능을 냈고, 이는 공개된 일부 LLM(DeepSeek R1, Gemini 2.5 Pro 등)보다 높은 수치입니다. 여기서 “Gemini 이김” 헤드라인이 나왔죠. 하지만 비교 과제와 설정이 다릅니다. (아래에서 설명)
왜 HRM인가? LLM의 CoT/TTC 피로감
- CoT(Chain-of-Thought, 연쇄사고): 답을 한 번에 뽑지 않고 중간 추론 과정을 문장으로 풀어쓰는 방식.
- TTC(Test-Time Compute, 테스트 시 계산 증대): 추론 단계(샘플 수/깊이)를 늘려 정답률을 올리는 트릭.
이 방식들, 효과는 있어요. 하지만
- 계산비용이 크고,
- 잘못된 추론 경로(reasoning trace) 를 만들면 오히려 성능이 떨어집니다.
또 ARC-AGI(Abstraction & Reasoning Corpus, 추상화·추론 벤치마크) 같은 문제에서는 LLM이 여전히 취약합니다.
그래서 “말(텍스트)” 대신 “잠재표현(latent)”에서 단계적 추론을 하자는 접근, 즉 HRM이 주목받았습니다.
한 줄 설명:
HRM = “말로 생각하는(CoT) 대신, 내부 잠재상태(z) 를 여러 번 업데이트하면서 점점 답을 다듬는다.”
HRM 구조 요약
HRM은 4개 구성요소로 이루어집니다.
- 입력 임베딩 ( f_I ) (Input Embedding, 입력 임베딩)
- 저주파 재귀 네트워크 ( f_L ) (Low-level Recurrent Net, 세부 추론용)
- 고주파 재귀 네트워크 ( f_H ) (High-level Recurrent Net, 전체 통합용)
- 출력 헤드 ( f_O ) (Output Head, 분류/예측)
두 네트워크 (f_L, f_H) 를 서로 다른 주기로 반복 호출합니다.
- ( f_L ): 자주 돌아가며 세부(fine) 업데이트
- ( f_H ): 가끔 돌아가며 전체(coarse) 통합
Fast Forward(노그래드) → Detach → 1-step Grad

| 단계 | 함수 호출 | gradient | 의미 |
|---|---|---|---|
| ① | fL 2회 | ❌ no_grad | 세부 warm-up |
| ② | fH 1회 | ❌ no_grad | 전체 통합 |
| ③ | fL 1회 | ❌ no_grad | detach 직전 마지막 정련 |
| ④ | detach | — | 연산 그래프 차단 |
| ⑤ | fL 1회 | ✅ grad | 학습용 세부 업데이트 |
| ⑥ | fH 1회 | ✅ grad | 학습용 전체 업데이트 |
핵심 직관:
Fast forward = “모델이 먼저 몇 번 생각해보고, 마지막 생각만 학습한다.”
여기서 HRM은 ( (z_L, z_H) )가 고정점(fixed point) 으로 수렴한다고 가정하고,
IFT(Implicit Function Theorem, 암시함수정리) + 1-step gradient approximation(단일 단계 기울기 근사) 를 사용해 마지막 두 단계만 역전파합니다.
메모리를 크게 아낄 수 있죠.
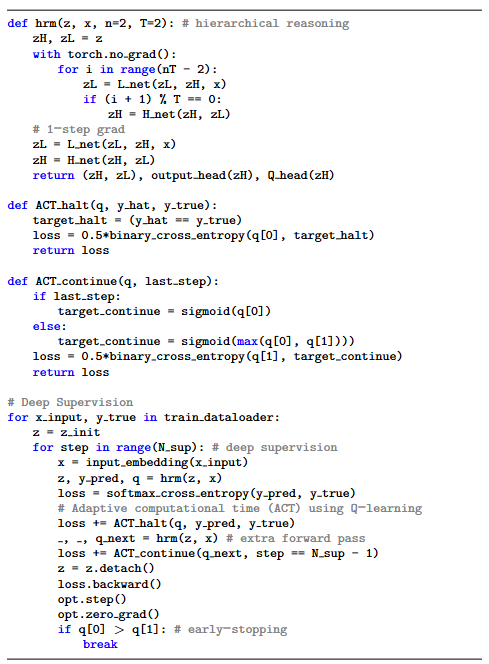
Deep Supervision(깊은 감독)과 Effective Depth(효과적 깊이)
이 과정을 여러 번 반복하며, 이전 잠재상태 ((z_H, z_L)) 를 다음 단계의 초기값으로 재사용합니다.
최대 16단계 반복. 이때 효과적 깊이는:
| 기호 | 의미 | 값 |
|---|---|---|
| (n) | (f_L) 반복 횟수 | 2 |
| (+1) | 사이클 내 (f_H) 1회 | 1 |
| (T) | 사이클 반복 | 2 |
| (N_{\text{sup}}) | supervision 단계 | 16 |
| (n_{\text{layers}}) | 각 네트워크 층 수 | 4 |
Tip — Deep Supervision, 깊은 감독
“중간 결과에도 정답 신호를 줘서, 점진적으로 더 나은 상태로 수렴하게 만든다”는 일반 기법.
ACT(Adaptive Computational Time, 적응적 계산시간)
각 입력별로 “여기서 멈출까? 더 돌릴까?”를 학습합니다.
HRM은 Q-learning으로 halt/continue 두 신호를 학습하는데,
continue 손실 계산 때문에 추가 forward가 한 번 더 필요(= 학습 시간 2배).
HRM의 한계
- IFT + 1-step gradient 를 쓰려면 고정점 수렴이 전제인데,
실험적으로 잔차가 0으로 가지 않아 수렴 가정이 흔들립니다. - ACT(Q-learning) 때문에 학습당 forward 2회 → 비용 상승.
- 생물학 비유(고저주파 뇌파 모방 등)에 기대는 설계 서사가 복잡도↑, 재현성↓.
TRM: 단 하나의 Tiny 네트워크로 전부 해결
핵심 컨셉: “Less is More(작을수록 낫다)”
-
Full Recursion Backprop
- 고정점 가정/IFT 미사용.
- Fast forward 제거, 모든 재귀 단계에 gradient. → 정보손실 없음.
-
z 해석 단순화
- ( z_H ) → 현재 답의 임베딩 (y)
- ( z_L ) → 잠재 추론 상태 (z)
- 결국 (x, y, z) 를 반복 입력하며 자기답을 스스로 개선.
-
Single Network
- ( f_L )·( f_H ) 를 하나로 통합 (입력 구성으로 역할 구분).
- 파라미터 27M → 7M.
-
단순 Halting (Non-RL ACT)
- Q-learning 삭제.
- “맞으면 멈춰라” 이진 halt loss만 학습.
- 추가 forward 불필요 → 학습 시간 ½.
-
Less is More
- 4층 → 2층으로 줄였더니 일반화 성능↑ (과적합↓).
- 작은 고정 길이 입력(예: Sudoku)에서는 Self-Attention → MLP 대체가 더 좋음.
-
EMA(Exponential Moving Average)
- 작은 데이터에서 학습 안정화 및 성능 상승.
실험 환경 & 하드웨어
- GPU: NVIDIA L40S(40GB), H100(80GB)
- Sudoku/Maze: L40S 1장 기준 36h 내 학습 가능
- ARC-AGI-1/2: H100 4장, 약 3일 학습
요지는 간단해요: 거대 LLM 없이도 비교적 작은 자원으로 강한 재귀 추론이 가능했다는 점.
데이터셋 안내
| Dataset | 설명 |
|---|---|
| Sudoku-Extreme | 9×9 스도쿠(Train 1K, Test 423K), 극난이도 |
| Maze-Hard | 30×30 미로, 최단경로 > 110 (경로 추론) |
| ARC-AGI-1/2 | 패턴 변환·추상화 벤치마크 (AI 난이도 최상) |
학습 세팅(요지): AdamW(β₁=0.9, β₂=0.95), hidden=512, N_sup=16
TRM: 2-layer, (T=3, n=6) / HRM: 4-layer×2, (T=2, n=2), EMA(0.999, TRM만)
(T, n) 은 경험적으로 최적 조합.
결과 핵심
Sudoku-Extreme: 동일 조건에서 TRM이 HRM을 크게 앞섬.
일부 세팅은 재귀가 깊어 TRM이 OOM 되기도 하지만, 정확도 이득이 큼.
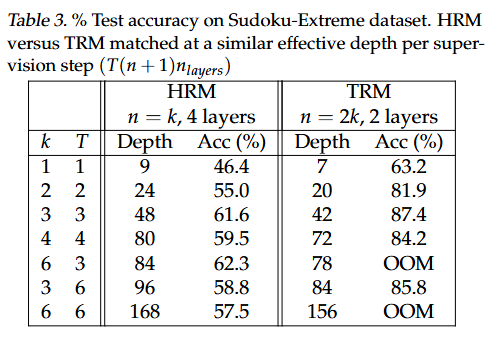
Puzzle 결과: 대형 LLM 다수는 퍼즐 자체를 못 풂(0%).
HRM/TRM만 퍼즐을 풀며, TRM이 큰 격차로 우세.
입력이 작을 땐 MLP-TRM, 클 땐 Attn-TRM 이 유리.
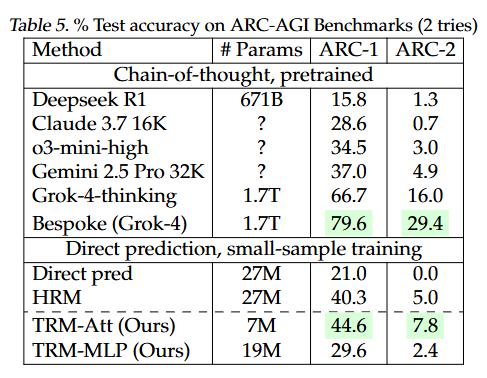
ARC-AGI: LLM 상위 모델(Grok-4 계열)이 리더보드 상단.
직접 지도학습 계열(TRM-Att) 은 7M 파라미터로 HRM(27M) 과 대형 LLM 일부를 능가.
“0.01% 파라미터로 Gemini를 이겼다”는 문구는 특정 설정/벤치마크 한정입니다.
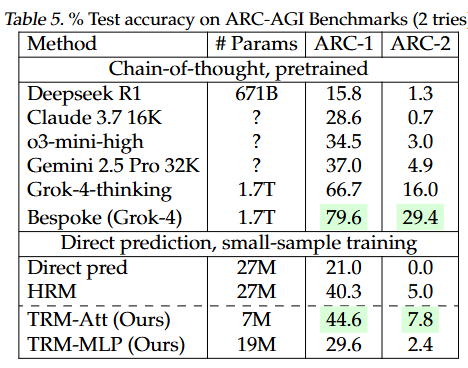
기여(Contributions)
| 구분 | 내용 | 효과 |
|---|---|---|
| ① 단일 네트워크 재귀 (Single-Network Recursion) | ( , ) 통합 | 27M → 7M, 단순+빠름 |
| ② 전체 재귀 역전파 (Full-Recursion Backprop) | IFT/1-step 미사용 | 이론적 불확실성 해소, 정보손실↓ |
| ③ 단순 Halting (Non-RL ACT) | Q-learning 제거 | forward 1회/step, 속도 2× |
| ④ Less is More | 4층→2층 | 일반화↑, 과적합↓ |
| ⑤ Attention-free 옵션 | 고정 짧은 L에서 MLP가 유리 | Sudoku SOTA(87%) |
| ⑥ EMA | 지수 이동 평균 | 학습 안정화/성능↑ |
| ⑦ 의미 | 작은 재귀 모델이 LLM 일부 능가 | “큰 모델만이 정답은 아니다” 증명 |
한계(Limitations)
| 항목 | 내용 | 영향 |
|---|---|---|
| ① Supervised 전용 | 입력→단일 정답 구조 | 생성형/복수 정답 확장 필요 |
| ② 이론 미완 | “재귀가 왜 강한 정규화인가?” | 경험적 성공 ↔ 이론 부족 |
| ③ 스케일 | 소규모 데이터셋 중심 | 대규모 도메인 검증 필요 |
| ④ 메모리 | full backprop로 (n,T)↑ 시 OOM | (n>6, T>3) 부담 |
| ⑤ 작업 의존 튜닝 | Sudoku=MLP, Maze/ARC=Attention | 완전 범용 아님 |
| ⑥ 해석성 | 단계별 (z) 변화 해석 어려움 | reasoning trace 분석 과제 |
그래서, “Gemini를 이겼다”는 말은?
- 특정 퍼즐/ARC 문제에서, 특정 세팅으로, 파라미터 0.01% 수준의 TRM 이 일부 LLM 점수보다 높다 → 사실.
- 하지만 일반 언어 과제 전반에서 TRM이 Gemini를 대체한다? → 아님.
- 요점: “거대 LLM 외에도, 작은 재귀 모델이 특정 추론 과제에서 매우 강력할 수 있다.”
마무리
이 논문은 “작아도 깊게 생각할 수 있다”는 걸 깔끔하게 보여줍니다.
Fast-forward/IFT/ACT의 복잡함을 걷어내고, 단일 작은 네트워크로 재귀 전체를 학습하게 만든 점이 포인트예요.
다음 과제는 생성형 확장, 대규모 데이터 검증, 그리고 재귀의 이론적 힘을 더 명확히 설명하는 일입니다.

아직 효과를 보기 위해서는 조건들이 여러 가지 달리고 방법론에 대한 확실한 규명이 안되었지만 적은 데이터로도 깊은 직관을 얻을 수 있다는 건 확실히 매력적이라고 생각됩니다..! 최근 이슈와 연계하여 설명해주셔서 더 흥미롭게 읽을 수 있었습니다