[Review] Accurate Parameter-Efficient Test-Time Adaptation for Time Series Forecasting (PETSA)
Paper Review
Medeiros, Heitor R., et al. "Accurate Parameter-Efficient Test-Time Adaptation for Time Series Forecasting." ICML 2025.
https://doi.org/10.48550/arXiv.2506.23424
https://github.com/BorealisAI/PETSA
문제 상황:
시계열 예측 모델은 기본적으로 입력 데이터에 대해 stationarity를 가정하고 있어 분포변화(distribution shift)에 대응하지 못함.
Time-Series Forecasting (TSF)
- Transformer 계열: self-attention을 통한 장기간 의존성 포착에 강점.
- 선형 변환(linear projection) 계열: 낮은 복잡도와 경쟁력있는 성능 제공.
- Multi-Layer Perceptron(MLP) 계열: global/local mixing을 통한 표현력과 효율성의 균형.
- 연속된 만큼의 관측을 포함하는 다변량 시계열 에 대해 모델 는 다가오는 만큼에 대한 예측을 실행. 따라서 .
계절성, 구조적 단절, domain shift 등으로 인한 non-stationarity 특성은 사전학습 예측 모델의 성능(정확도) 저하 원인.
Stationarity (정상성): 시계열의 통계적 성질(평균, 분산, 자기상관 등)이 시간에 따라 변하지 않는 경우.
Non-stationarity (비정상성): 시계열의 통계적 성질이 시간에 따라 변하는 경우.
기존 방법:
Test Time Adaptation(TTA)은 모델의 추론 과정 중에 모델을 조정해 이러한 문제를 해결.
그러나, 모델 전체의 파라미터를 수정하기 때문에 시간과 비용(자원)이 많이 요구됨.
Test-Time Adaptation
모델이 추론 단계에서 라벨링되어 있지 않은 데이터를 활용해 분포 변화에 적응하게 하는 기술.
시계열 예측에서 TTA는 test 입력만을 사용해 분포 변화를 완화하는 역할을 수행.
예측 직후의 부분 실측지와와 예측 구간 이후 확인 가능한 전체 실측치를 모두 적응에 활용
Adaptation window의 크기는 Fast Fourier Transform(FFT)로 계산한 주기로 설정해 주기성을 반영.
제안하는 방법(PETSA):
Parameter-Efficient Time-Series Adaptation(PETSA)을 제안.
Parameter-Efficient Fine-Tuning (PEFT)
거대한 모델을 적은 개수의 파라미터 조정만으로 적응시킬 수 있는 기술. LoRA가 대표적.
사전학습 모델은 조정하지 않고, 모델의 입력과 출력을 보정하는 경량화 프레임워크.
1) Low-rank adaptor와 dynamic gating을 활용해서 모델 재학습없이 모델의 입출력을 캘리브레이션.
2) 3가지로 구성요소를 포함하는 새로운 loss function을 도입해 정확도를 유지.
결과적으로, 연산량(파라미터 수)를 크게 줄이면서 기존 방법 대비 유사 혹은 상회하는 성능 달성.
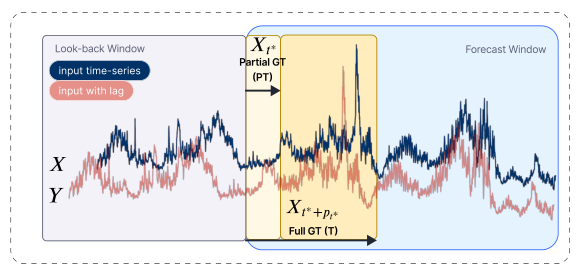
Figure 1. PETSA의 TTA Setup
X: 시계열 입력 / Y: 지연된 시계열 입력, 부분 실측치로 활용.
모델은 look-back window를 관찰하고 forecast window에 대한 예측을 실행.
예측한 직후 알 수 있는 Partial Ground Truth (PT, 부분 실측치)와 forecast window에 전체에 대한 지연된 Full Ground Truth (T, 전체 실측시)를 활용해 모델 업데이트.
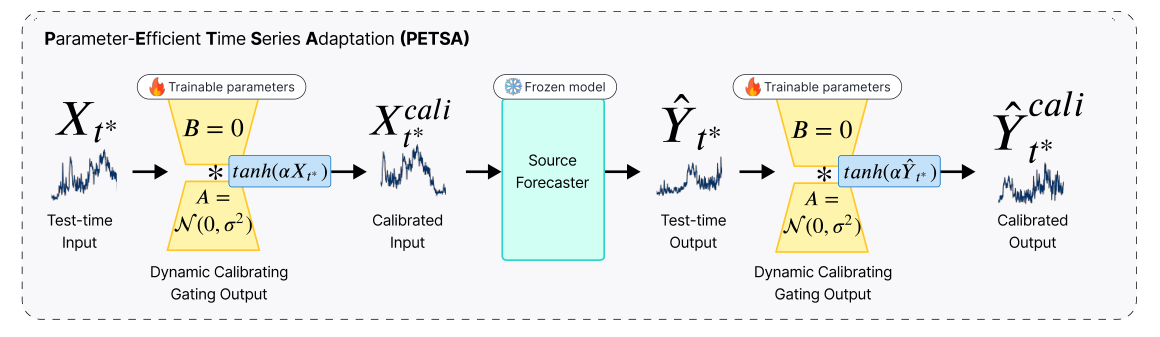
Figure 2. PETSA 구조
시계열 데이터 X를 모델의 dynamic input calibration module에 전달하면 gated low-rank transformation을 적용해 보정된 X를 생성.
예측 모델은 보정된 X를 바탕으로 예측을 수행하고, 그 예측결과를 output calibration module에 전달해 정제해 최종 예측값을 산출.
핵심은 calibration module에 대해서만 업데이트가 일어나고, 예측모델 자체는 조정하지 않는 것.
Dynamic Calibration Machanism
동결한 forecaster의 입출력에 대한 보정 방법:
- Low-rank adaptor: 으로 분해하여 parameter 개수 감소. 초기값으로 는 Xavier 분포를 따르고, 는 0으로 설정해 안정적이고 점진적 보정할 수 있는 환경 설정.
- Dynamic gating: , 를 통해 각 변수의 가중치를 조정하여 특정 성분을 얼마나 보정할지 결정.
PETSA 최적화
PETSA의 loss 항.
: 지연된 전체 ground truth, 를 사용해 계산
: 부분 관측된 라벨, 를 사용해 계산
각 loss 항은 3개의 요소로 구성됨.
Huber loss: 이상치에 대한 강건성 확보 목적
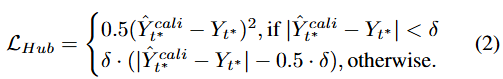
frequency-domain loss: 주기성을 보존하고 편향을 줄이기 위한 목적
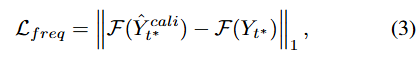
patch-wise structural loss: 지역 상관관계, 평균, 분산을 포착해 구조적 정렬을 향상시키는 목적.
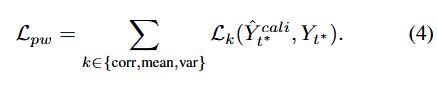
따라서 과 은 다음과 같이 구성됨.
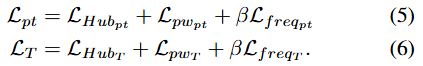
실험 결과
ETT 시리즈 + Exchange + Weather 데이터셋에 대한 벤치마크를 진행.
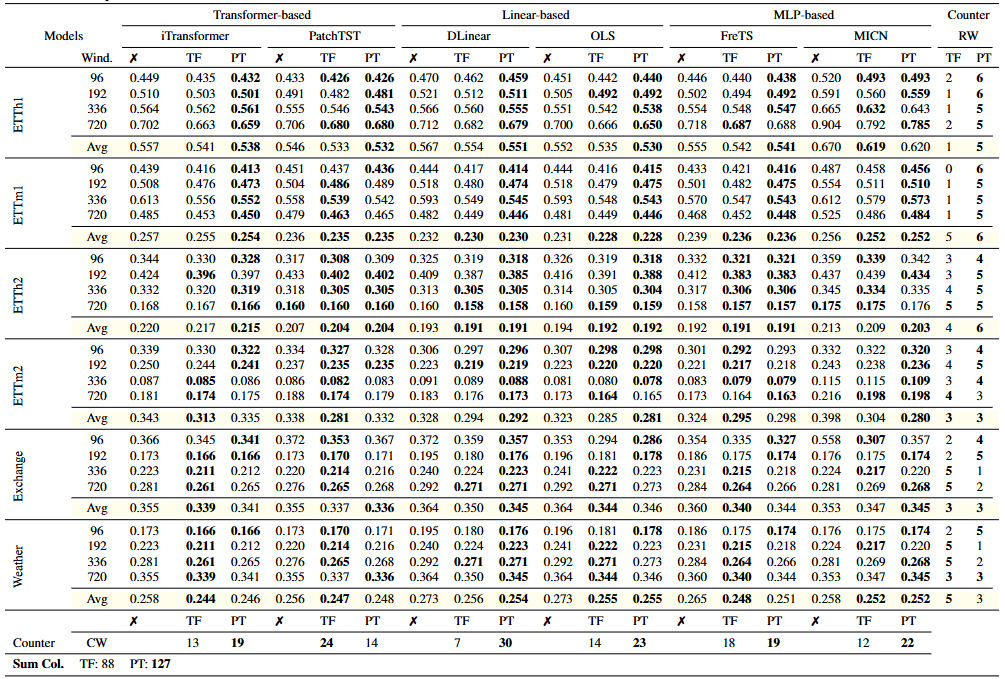
Table 1. 데이터셋 및 window 크기에 따른 MSE
모든 데이터셋 및 모델에서 PETSA가 가장 많은 'Best MSE'를 달성(127회)
TAFAS는 'Best MSE'88회 달성하며, PETSA를 크게 하회.
TSF 모델에 상관없이 일관된 성능 향샹과 적은 파라미터 수를 기록.
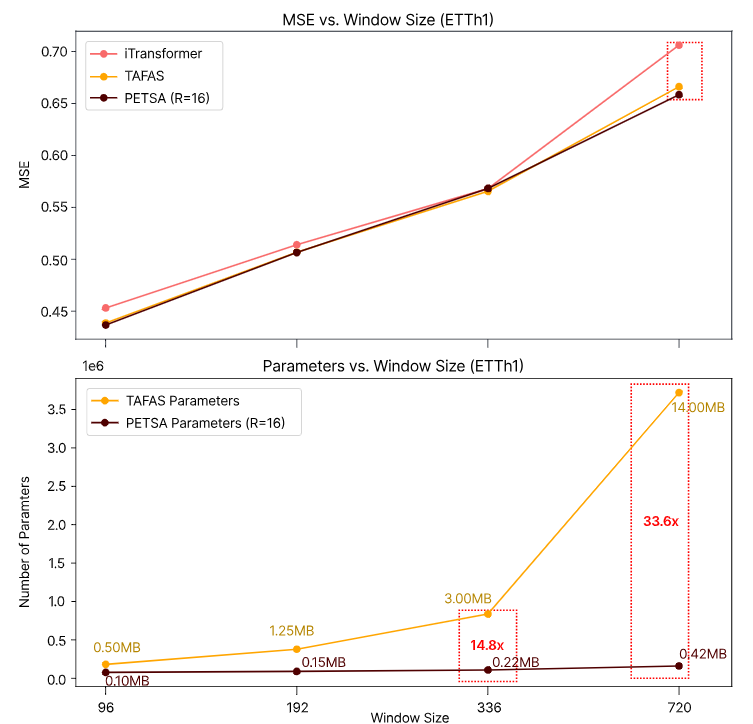
Figure 4. ETTh1 데이터셋에 대한 iTransformer 모델 기준 TAFAS와 PETSA 성능 비교
PETSA의 baseline 모델인 TAFAS와 비교했을 때, 성능은 유사하지만 요구하는 파라미터 개수가 window 크기가 커질수록 적어짐. 성능적 오버헤드가 크게 감소하는 효과.
결론
PETSA는 “작고 효율적인 모듈”만 업데이트해서, 기존 TTA보다 훨씬 가볍고 안정적으로 non-stationary 시계열에 적응할 수 있는 방법이다.
