[Review] Shift-Aware Test-Time Adaptation and Benchmarking for Time-Series Forecasting (DynaTTA)
Paper Review
Grover, Shivam, and Ali Etemad. "Shift-Aware Test Time Adaptation and Benchmarking for Time-Series Forecasting." ICML 2025.
https://github.com/shivam-grover/DynaTTA
문제상황
추론 과정에서, 실제 시계열 데이터의 Non-Stationarity 특성으로 인한 예측 모델의 일반화 성능 저하 발생.
Stationarity (정상성): 시계열의 통계적 성질(평균, 분산, 자기상관 등)이 시간에 따라 변하지 않는 경우.
Non-stationarity (비정상성): 시계열의 통계적 성질이 시간에 따라 변하는 경우.
기존 방법
Test-Time Adaptation을 적용해 분포 변화에 따른 영향을 완화하는 접근법이 제안됨.
Test-time 시점에서 모델이 스스로 업데이트할 수 있도록 허용함으로써 분포 변화에 대응. (재학습과는 다름.)
시계열 데이터는 강력하고 일시적인 구조를 따르는 데이터 스트림을 포함.
새로운 데이터가 들어오면 이전에 진행한 예측값에 대한 ground truth를 확인할 수 있음.
문제점 1) 시계열의 동적 특성: DynaTTA 제안
기존에 제안된 TSF-TTA 기법은 두가지 한계점 존재.
A. 고정된 adaptation rate 채택
분포 변화의 특성과 강도를 고려하지 않고 adapation 적용해 under/over-adaptation 유발
B. 분포 변화의 방향과 규모를 고려하지 않은 gating machanism
적응된 정보를 예측에 얼마나 활용할지 결정하는 gating machanism이 부재.
원본 모델과 적응 모델이 서로 얼마나 의존할 것인지 조정할 수 없음.
문제점 2) TSF-TTA를 위한 적절한 벤치마크의 부재: TTFBench 제안
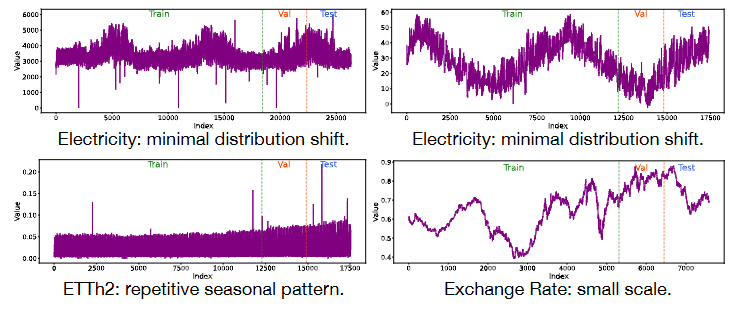
기존 TSF 데이터셋은 TTA-TSF의 성능을 제대로 평가하기에 test-time 변동성이 낮고 반복적 패턴이 나타나 부적절함.
제안하는 방법 (DynaTTA & TTFBench)
1. DynaTTA
분포 변화의 정도를 test-time에 평가.
이를 기반으로 모델을 언제 적응시키고, 얼마나 적응된 모델에 의존시킬지 동적으로 통제하는 방법.
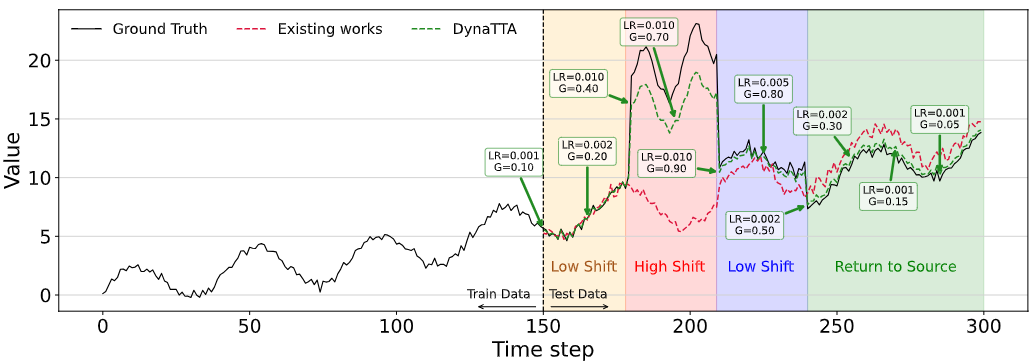
Figure 1. 동적으로 적용하는 adaptive rate(LR)과 gating parameters(G)를 적용한 DynaTTA의 예측 결과 비교
기존 TSF-TTA 방법인 TAFAS 대비 예측값이 ground truth에 빠르게 접근하는 모습을 확인할 수 있음.
문제 설명
개의 채널에서 단계 동안의 다변량 시계열
을 통해 학습한 모델 는 길이가 인 예측 window를 사용해 미래의 단계만큼 예측을 수행: for
목표 시퀀스, 에 대해 과 for 성립.
핵심은 source data에 대한 접근없이 test-time에 입력되는 테스트 스트림 만을 활용해서 모델의 파라미터 를 동적으로 업데이트하는 것.
분포 변화 측정
1. MSE Z-score
모델의 test-time MSE를 수집해 최신 성능 저하 정도를 추적.
Z-score의 튐 현상(spike)는 훈련 데이터 분포로부터 변화가 있다는 것을 의미.
2. Short-term Embedding Drift
최신 입력 임베딩과 이에 대응하는 부분/전체 MSE를 저장하는 실시간 적응 버퍼(RTAB)을 통해 Short-term Embedding Drift을 획득
3. Long-term Embedding Drift
가장 오차가 적었던 Top-k개의 임베딩을 저장하고 source data에 대한 프록시를 제공하는 참조분포버퍼(RDB)를 통해 Long-term Embedding Drift 획득.
RDB의 프록시를 활용해 장기간 변화에 대한 탐지 가능.
Shift-Conditioned Gating
TTA에서 어떻게, 언제, 얼마나 적응할지 결정하는 것은 매우 중요함.
분포 변화가 존재한다면 적응의 적용은 분명한 이득이지만, 현재 테스트 데이터가 훈련 데이터와 유사하다면 모델의 적응이 오히려 악영향을 미칠수도 있다는 것을 강조.
데이터 변동의 정도를 탐지해 적응의 강도를 조절할 수 있는 메커니즘의 필요성 대두.
3가지 변동 metrics(MSE Z-score, RTAB, RDB)의 집합 을 도입.
학습 가능한 파라미터 을 0으로 초기화.
를 MLP, 에 대입.
연산에 활용.
으로 모델 입력 보정의 가중치를 조절
와 는 일시적 보정을 위한 학습 가능한 가중치와 편향.
동적 Adaptaion Rate 조정
고정 adaptation rate의 문제점
1) adaptation rate가 너무 높은 경우: 입력의 변화는 크기 않은데, 모델이 불필요하게 공격적으로 입력에 적응
2) adpatation rate가 너무 낮은 경우: 모델이 직면한 급격한/중요한 분포 변화에 충분히 빠르게 적응하는데 실패.
각 를 정규화하고 모두 더해 변동 점수(shift score) 로 변환
스케일된 sigmoid 함수를 통한 multiplier 계산:
는 사전에 설정된 adaptation rate의 최대/최소값
는 민감도를 조절하는 스케일링 파라미터
목표 adapatation rate는
따라서, rate를 다음과 같이 업데이트:
는 exponential smoothing coefficient
Warm-up & Momentum 기반 Adaptation Rate 조정
적응 초기 단계에서는 데이터 부족으로 인해 신뢰도 있는 metrics를 계산하기 어려움.
Warm-up factor, 을 활용해 극복.
은 조정가능한 warm-up factor, 는 예측 길이.
목표 adaptation rate를 다음과 같이 계산:
전체 흐름
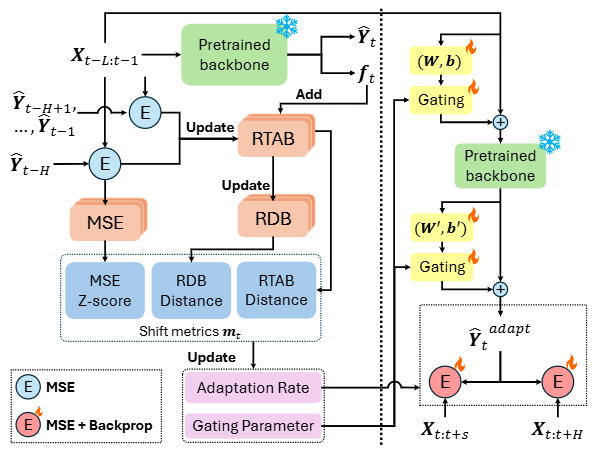
Figure 4. DynaTTA의 구조
왼쪽 파트:
과거 L 구간을 입력 context로 활용. 사전학습된 모델이 예측값()과 모델 임베딩 반환. 를 통해 즉각적인 분포 변화 포착 가능.
에 MSE 부분적으로 계산해 RTAB, MSE 버퍼에 저장. 에 대한 ground truth가 시점 에 탐지되므로, 이에 대한 MSE 계산 가능!
버퍼에 저장된 값을 활용해 metrics를 생성하고 이를 통해 최신 adapatation rate와 gating parameter 계산
오른쪽 파트: 와 을 통해 모델의 입출력을 정규화/비정규화 진행.
Gating parameter를 통해 부분 MSE()를 기반으로 입출력 보정의 강도를 결정.
Adaptation rate를 통해 입출력 보정 모듈의 파라미터를 얼마나 빠르게 적응시킬지 결정.
전체 MSE()를 통해 최종 backpropagation 진행. 장기적인 adaptor 파라미터 업데이트에 반영.
2. TTFBench
기존 TSF 데이터셋(ETT 시리즈, Weather, Exchange 등)은 test-time에서 분포 변화 거의 없음.
인위적인 분포 변화를 첨가한 벤치마크를 통해 TSF-TTA를 평가하는 것이 보다 적합함.
따라서, 기존 데이터셋에 다음과 같은 변화를 추가
- 추세 변화 (trend shift)
- 계절성 패턴 변화 (seosonality shift)
- 데이터 생성 규칙 변화 (regime shift)
- 국소 노이즈 (localized noise)
세부사항은 논문을 참조.
실험 결과 및 결론
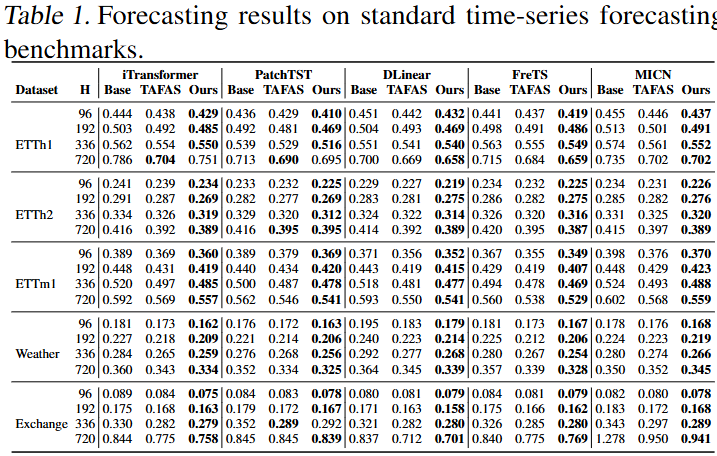
Table 1. 기존 데이터셋 기준 예측 성능 비교
기존 데이터셋에서 DynaTTA는 TAFAS 대비 6.1%, baseline(iTransformer) 대비 7.21% 상회하면서 유의미한 결과 도출.
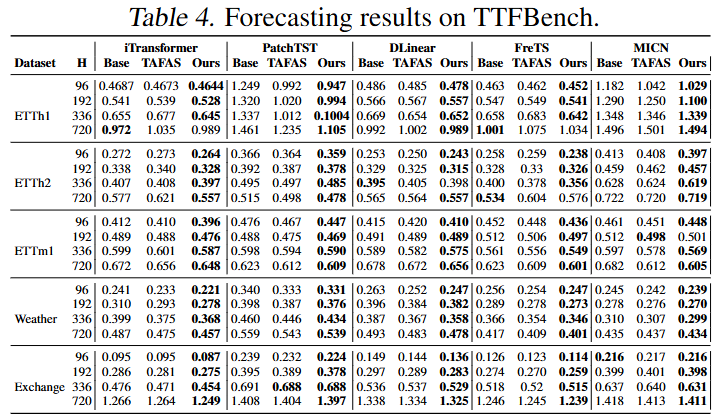
Table 4. TTFBench 데이터셋 기준 예측 성능 비교
TTFBench에서 DynaTTA는 TAFAS 대비 4.39%, baseline(PatchTST) 대비 8.41% 상회하면서 유의미한 결과 도출.
정리
- DynaTTA는 기존 TAFAS 대비 성능·안정성 모두 우수
- short-term + long-term shift 모두 대응 가능
- DynaTTA는 shift-aware 설계 덕분에 다양한 데이터 분포 변화에 강건함.
- TTFBench를 통해 실제 환경과 유사한 평가에서도 개선 효과 확인
