[Review] Communication-Efficient Learning of Deep Networks from Decentralized Data (FedAvg)
Paper Review

McMahan, Brendan, et al. "Communication-efficient learning of deep networks from decentralized data." Artificial intelligence and statistics. PMLR, 2017.
https://doi.org/10.48550/arXiv.1602.05629
리뷰에 앞서
저번 FFTS 논문 리뷰가 매우 단조로운 정보 전달에 치우친 것 같아, 이번에는 최대한 간결하고 쉽게 설명을 해보겠습니다.
이번 논문은 "연합학습"이라는 개념 자체를 처음 제시한 연구입니다. 2017년에 발표된 만큼 (벌써 8년전...) 2025년의 상황과는 약간 어색한 점도 있을 수도 있습니다.
문제상황
휴대폰, 태블릿 등 개인기기의 보급으로 우리는 엄청난 양의 데이터를 생산합니다.
이 기기들은 GPS, 카메라, 마이크 등 다양한 센서를 통해 데이터를 수집할 수 있습니다.
과학자들은 생각했습니다.
“저 데이터를 모델 학습에 활용할 수 있다면 얼마나 좋을까?”
그러나, 이러한 접근은 수많은 않은 장벽에 의해 제지당합니다. 바로 "프라이버시" 때문이죠.
물론 사람들은 쉽게 이해할 수 있습니다. 우리의 일상생활을 담은 데이터를 인공지능에 학습시킨다면 엄청난 성능과 편의성을 가져다 주겠죠. 그러나, 동시에 사람들은 빅브라더를 경계합니다.
그래서 오늘 소개할 논문, "Communication-Efficient Learning of Deep Networks from Decentralized Data" 는 사생활 침해를 하지 않으면서, 각 기기의 데이터를 활용해 모델을 학습시키는 방법을 제안합니다.
제안 방법: FedAvg
논문이 제시하는 방법은 간단합니다.
데이터 접근과 모델 학습의 분리
이 방법은 데이터를 중앙 서버에 저장하고 모델을 학습시키지 않습니다.
대신, 로컬 기기(휴대폰 등)에서 기기에 저장된 데이터로 모델을 학습한 후에 학습 결과(모델의 가중치)만 중앙 서버에 전송하는 겁니다.
즉,
- 데이터는 절대 서버로 전송되지 않고,
- 모델 업데이트 정보만 서버로 전달됩니다.
논문에서는 이 방법을 "FedAvg(Federated Averaging)"라는 알고리즘으로 구현했습니다.
왜 averaging라는 단어가 포함되어 있는지는 알고리즘과 함께 그 이유를 설명드리겠습니다.
FedAvg는 연합학습의 시초격 모델이며, 이후 모든 FL 연구의 기반이 되었습니다.
FedAvg 알고리즘 구조
기본 구성

연합학습을 설명하기에 앞서 두 가지 단어에 대한 의미를 짚고 가겠습니다.
-
서버(Server)
- 전체 학습을 총괄하며, 클라이언트에게 글로벌 모델을 배포합니다.
- 클라이언트가 학습한 결과를 수집하고 평균하여 글로벌 모델을 갱신합니다.
-
클라이언트(Client)
- 서버로부터 받은 모델을 자신의 로컬 데이터로 학습합니다.
- 학습이 끝나면 모델 파라미터를 서버로 전송합니다.
비유:
ChatGPT를 우리가 사용하면, ChatGPT는 사용자가 입력하는 데이터를 학습하죠?
완벽한 비유는 아니지만, 쉽게 말해 ChatGPT 서비스는 서버이고, 사용자는 클라이언트입니다.
사용자가 자신의 데이터를 ChatGPT가 학습하는 게 싫지만, ChatGPT의 성능을 향상시키고 싶어하는 상황인거죠.
FedSGD (Federated Stochastic Gradient Descent)
FedAvg를 설명하기에 앞서, FedSGD(Stochasitc Gradient Descent, 확률적 경사 하강법)에 대한 이해가 필요합니다.
FedAvg는 FedSGD를 일반화한 형태이기 때문인데요.
SGD(Stochastic Gradient Descent)는 모델 파라미터 를
손실 함수를 최소화하는 방향으로 점진적으로 갱신하는 방법입니다.
- GD (Gradient Descent): 경사하강법은 모든 데이터를 이용해서 한번에 가중치를 업데이트합니다.
만약 데이터가 엄청 크다면, 업데이트를 하는데 걸리는 시간이 매우 오래걸리겠죠?
그래서 SGD를 통해 확률을 도입합니다.
- SGD: 전체 데이터 중 일부(미니배치)만을 사용해서 기울기를 계산하는거죠. 덕분에 실시간 업데이트도 가능할 정도로 빠르게 갱신할 수 있습니다. 그러나, 미니배치에 편향이 있을 수도 있으니까 약간의 진동이 발생할 수 있습니다.
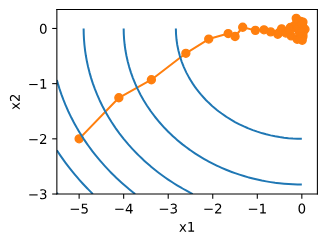
FedSGD의 절차는 다음과 같습니다.
- 서버는 매 라운드마다 한 명의 클라이언트를 선택합니다.
- 해당 클라이언트가 로컬 데이터로 gradient를 계산합니다.
- 서버는 그 gradient를 사용해 글로벌 모델을 업데이트합니다.
하지만, 매 라운드마다 통신이 필요해 비효율적이라는 단점이 있습니다.
- : 라운드 의 글로벌 모델
- : 클라이언트 의 데이터 개수
- : 전체 데이터 개수
- : 학습률 (Learning Rate)
- : 클라이언트 의 gradient
각 클라이언트 는 자신의 로컬 데이터에 대해 gradient 를 계산합니다.
서버는 전체 gradient의 가중평균으로 글로벌 모델 파라미터를 갱신합니다.
Averaging이라는 단어가 나온 이유가 바로 여기서 나옵니다. FedAvg는 각 클라이언트의 데이터량에 비례해서 gradient를 가중 평균내기 때문인 것이죠.
FedAvg의 확장
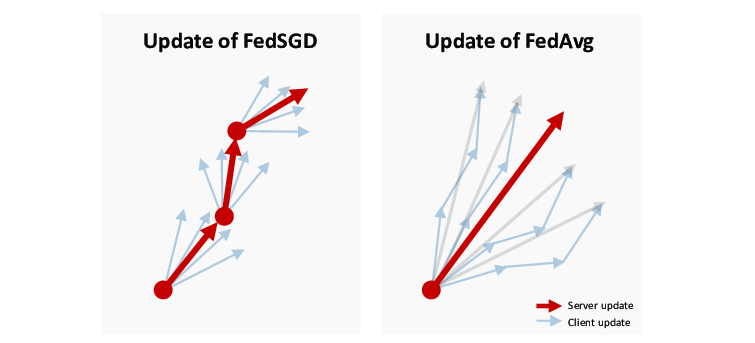
FedAvg는 FedSGD의 일반화된 형태입니다.
가장 큰 차이점은 클라이언트가 자체적으로 여러번 모델을 학습시킨 이후에, 그 결과를 서버에 공유한다는 점입니다.
클라이언트가 같은 데이터로 여러번 학습하는 것을 우리는 local epoch를 여러번 돌린다고 표현합니다.
아까 FedSGD가 매 라운드마다 통신해야 해서 효율이 낮다고 했었죠? FedAvg의 방식을 채택하면 FedSGD가 여러번 통신해야 얻을 수 있는 결과를 한 번의 통신 라운드만으로 얻어낼 수 있으니, 통신의 효율성이 상승한겁니다.
주요 하이퍼파라미터
| 기호 | 의미 | 설명 |
|---|---|---|
| 참여 비율 | 각 라운드에서 참여할 클라이언트 비율 | |
| 로컬 에포크 수 | 클라이언트가 로컬 학습을 반복하는 횟수 | |
| 배치 크기 | 로컬 SGD에서 사용하는 미니배치 크기 |
알고리즘 요약
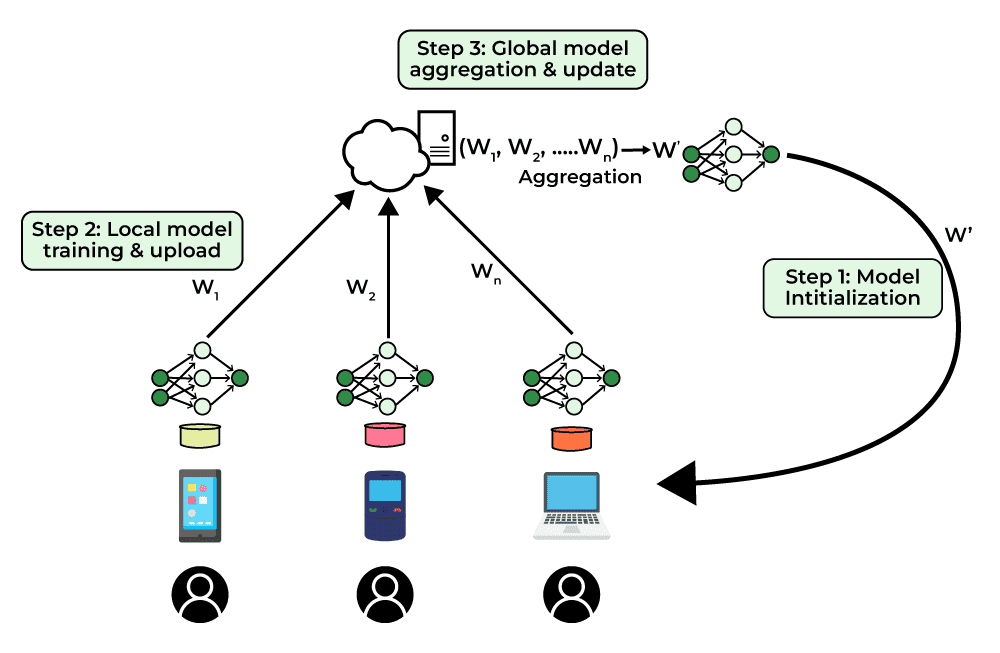
서버 측
- 글로벌 모델 초기화
- 매 라운드 에서 무작위로 비율의 클라이언트 선택
- 선택된 클라이언트에게 모델 전송
- 각 클라이언트의 학습 결과 수신
- 가중평균하여 새로운 글로벌 모델 생성
클라이언트 측
- 로컬 데이터 를 배치 크기 로 분할
- 에포크 동안 각 미니배치 로 SGD 업데이트
- 학습 완료 후 모델 을 서버로 전송

성능 분석
데이터셋
- MNIST (손글씨 인식)
- CIFAR-10 (이미지 분류)
- Shakespeare (문자 기반 언어모델, 각 인물이 하나의 클라이언트)
데이터 분포
-
IID (Independent and Identically Distributed)
→ 모든 클라이언트가 동일한 분포의 데이터를 가짐 -
Non-IID (Non-Independent and Identically Distributed)
→ 각 클라이언트의 데이터 분포가 다름 (편향 존재)
| 문제 | 설명 |
|---|---|
| Local Drift (로컬 드리프트) | 각 클라이언트가 다른 방향으로 학습되어 서버 평균 시 수렴이 느림 |
| 성능 불균형 | 특정 클라이언트 데이터에는 잘 맞지만, 다른 곳에서는 성능 저하 |
| 모델 불안정성 | 통신 라운드 간 업데이트 편차로 인해 진동(oscillation) 발생 |
주요 결과
참여한 클라이언트 수가 많을수록 모델의 수렴 속도가 빨라짐.
단, 모든 클라이언트를 매번 사용하는 것은 비효율적.
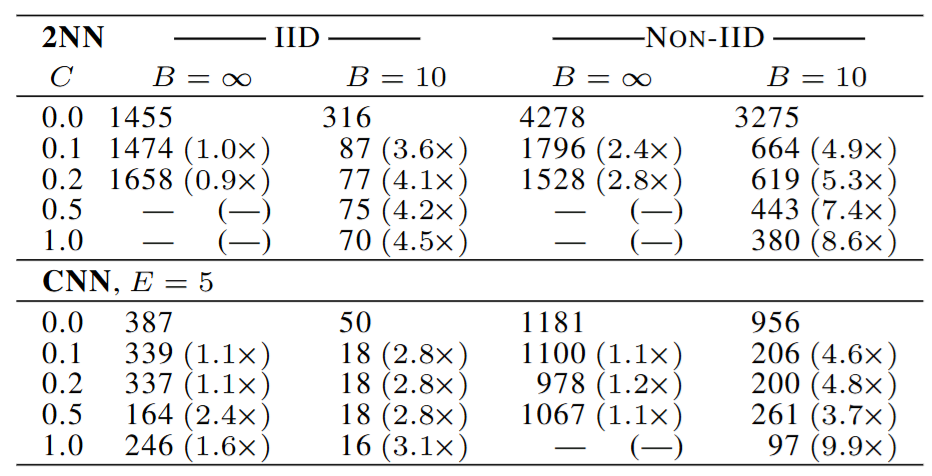
로컬 학습 횟수 증가 또는 배치 크기 감소 → 연산량 ↑, 통신량 ↓
IID에서 높은 성능 향상, Non-IID에서도 안정적 성능 유지
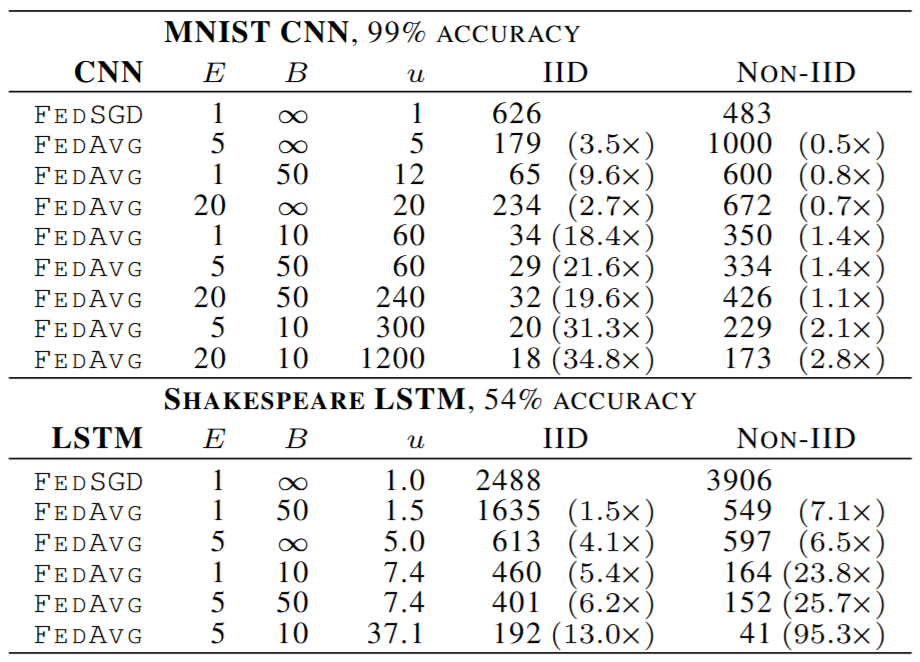
로컬 에포크 수 가 과도하게 많으면 수렴 실패(local drift) 또는 성능 저하 발생

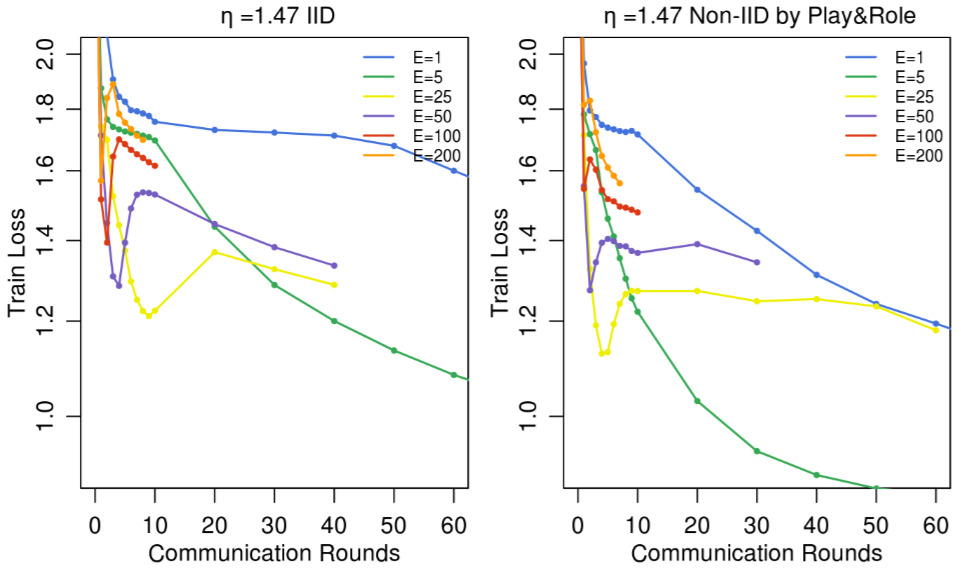
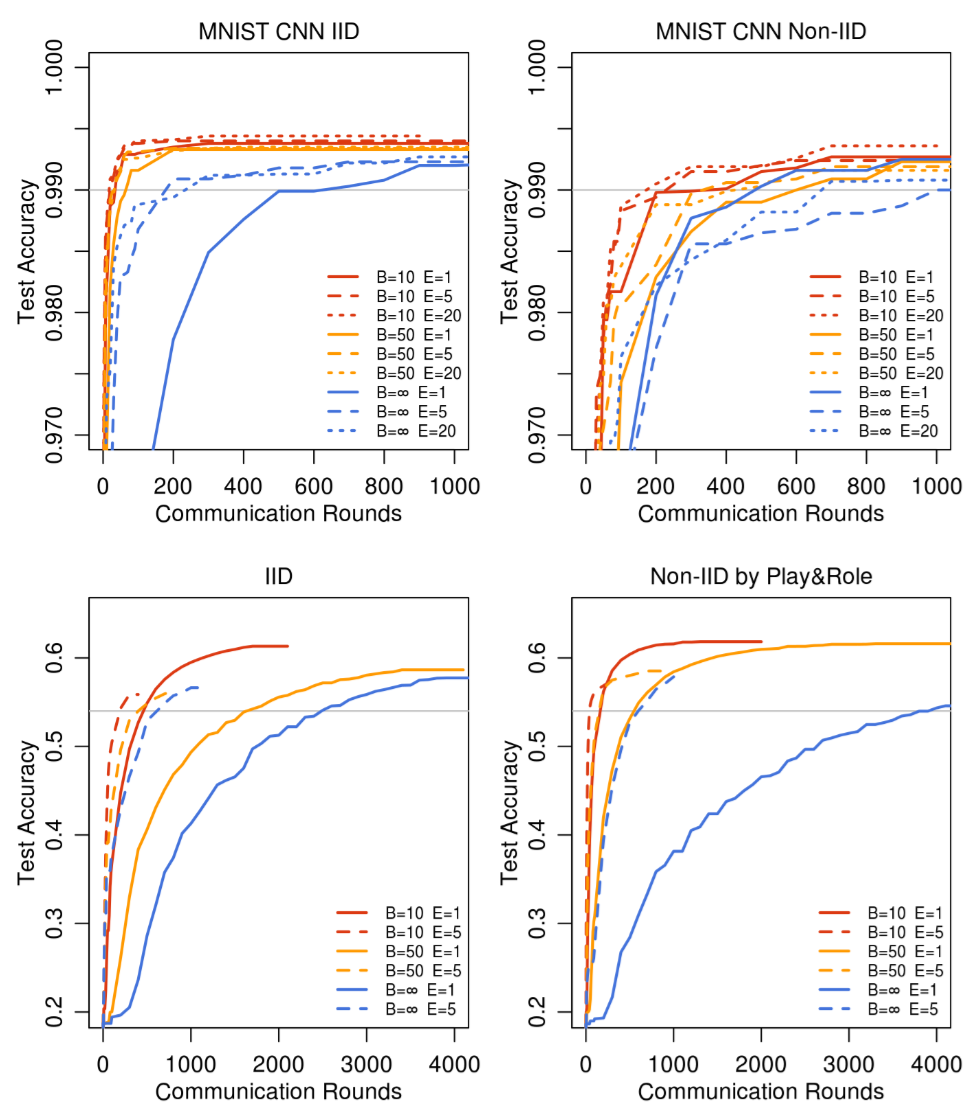
FedAvg는 FedSGD 대비 빠른 수렴과 Non-IID 환경에서의 우수한 정확도를 보임.
정리
FedAvg의 핵심 아이디어
- 각 클라이언트가 자신의 데이터로 모델을 업데이트합니다.
- 서버는 이를 종합하여 새로운 글로벌 모델 생성합니다.
- 데이터는 절대 중앙 서버로 이동하지 않습니다.
장점
- 데이터 보안 유지 (Privacy-preserving)
- 통신 효율 향상
- 다양한 모델(Multi-Layer Perceptron, CNN, LSTM 등)에 적용 가능
- Non-IID 환경에서도 견고한 성능
추가 확장 가능성
- Differential Privacy
- Secure Multi-party Computation 등 보안 강화 기술 도입 필요

6개의 댓글

활용할 수 있는 데이터의 양이 중요한 시대에 사용자 정보 수집은 말로만 들었지 실제 모델에는 어떻게 적용될 수 있는지는 몰랐는데 이런 방식으로 적용해볼 수 있겠군요..! 중간 중간 그래프와 이미지로 설명해주셔서 더 이해가 잘 되었습니다! 나중에 한번 원문을 읽어보며 더 알아보고 싶네요

유튜브에서 불가사리가 자기 위를 밖으로 빼내서... 사냥한다는 영상을 본 적이 있는데, 데이터가 있는 곳에 학습 파라미터를 보내는 모양이 마치 불가사리가 사냥하는 방법 같군요(..?)
뭔가 학습되는 데이터가 제각각 다른 특성값을 띠게 되어 학습결과 각각이 편향이 심하고 분산돼있을것 같은데, 그러한 문제점은 후속연구 등을 통해 해결됐는지도 궁금합니다!
개인정보를 직접 수집하지 않고 가중치만 서버에 전달해서 학습한다는 발상이 인상깊어요! 시각자료가 다양해서 이해가 잘 됩니당