
1. Redis란?
- 오픈소스 인 메모리 데이터 구조 저장소이며, 비관계형 DBMS(NoSQL) 입니다.
- Key-Value로 이루어졌으며, 데이터를 빠르게 조회/저장 하는 데 최적화 되어있습니다.
- 주로 캐싱, 세션 관리, pub/sub에 사용됩니다.
인 메모리란?
데이터를 컴퓨터의 SSD,HDD에 저장하는 대부분의 DBMS방식과는 달리, RAM에 저장하여 직접 접근하는 방식을 말합니다.
이미지 출처
2. Redis의 특징
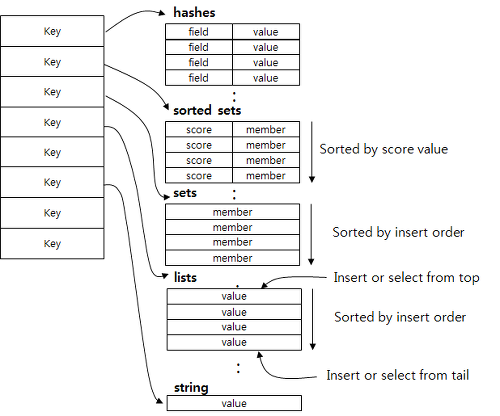
💡 key -> value 형태의 다양한 자료구조를 지원합니다.
-
String: 데이터는 키와 값의 쌍으로 저장됩니다
"mykey" -> "Hello" -
Sets: 중복을 허용하지 않는 문자열의 집합입니다.
"colors" -> {"red", "green", "blue"} -
Lists: 순서가 있는 문자열의 리스트 입니다.
"colors" -> ["red", "green", "blue"] -
Hashes: 키에 연결된 필드와 값의 쌍으로 구성됩니다.
"id:25" -> {"name": "Kim", "age": "30"} -
Sorted Sets: 점수와 함께 문자열을 저장하여 순서를 유지합니다.
"scores" -> {"player1" -> 100, "player2" -> 200}
이미지 출처
💡 유연하게 데이터를 관리합니다.
Redis의 강력한 장점 중 하나는 별도의 스키마가 필요 없다는 점입니다. 이는 한 Redis 인스턴스 내에서 다양한 타입의 데이터를 저장할 수 있다는 장점이 있습니다.
예시)온라인 쇼핑몰 애플리케이션
-
(String 이용) 각 사용자의 세션 ID를 저장합니다.
"session:user123" -> "session_id_456789" -
(Sets 이용) 특정 카테고리에 속하는 상품의 ID를 저장합니다.
"category:books" -> {"100", "101", "102"} -
(Lists 이용) 사용자가 장바구니에 추가한 상품 목록을 순서대로 저장합니다.
"cart:user123" -> ["100", "101", "102"] -
(Hashes 이용) 각 사용자의 프로필 정보를 필드와 값의 쌍으로 저장합니다.
"user:123" -> {"name": "Jane", "email": "jane@example.com"} -
(Sorted Sets 이용) 상품별 리뷰 점수와 리뷰어를 저장합니다.
"reviews:product100" -> {"user123" -> 5, "user456" -> 4}
이 예시에서, 하나의 Redis 인스턴스의 Key 값으로 "session:user123", "category:books", "cart:user123", "user:123" "reviews:product100" 가 존재하며, 이렇게 "접두어:식별자" 형태인 '키 네임스페이스' 패턴으로 Key 값이 구성됩니다.
💡 인 메모리 데이터 구조이기 때문에 속도가 빠릅니다.
데이터 처리시, 상대적으로 느린 HDD,SSD에 접근하는 방식이 아닌 메모리에 접근하는 방식이므로 속도가 빠릅니다.
💡 데이터 영속성을 지원합니다.
메모리 특성상 저장된 데이터가 휘발될 가능성이 있습니다. 이를 보완하고자 메모리에 있는 데이터를 백업할 수 있습니다.
다음은 Redis가 데이터를 백업하는 방식들 입니다.
- RDB(스냅샷): 정기적으로 메모리 데이터의 스냅샷을 생성하여 디스크에 저장합니다. 스냅샷 이후에 변경된 데이터는 복구할 수 없어 데이터 유실이 발생할 수 있습니다.
- AOF(추가 전용 파일): 모든 데이터 변경 사항을 로그에 기록합니다. 이 방법은 데이터 변경의 상세한 기록을 유지하므로 데이터 유실을 최소화하지만, 로딩 속도가 느리고 파일 크기가 큰 단점이 있습니다.
일반적으로 Redis는 RDB와 AOF를 병행하여 사용합니다.
예를 들어, 매일 특정 시간에 RDB 스냅샷을 생성하고, 그 이후의 변경사항은 AOF로 기록합니다.
💡 Redis는 보통 보조 DB로 사용됩니다.
MySQL과 같은 메인DB를 두고 서브DB로 많이 쓰이는데, 캐싱, 세션 관리, pub/sub, 인증 토큰 저장 등에 사용됩니다.
특히 캐싱의 경우,
자주 조회되면서 변경 가능성이 적은 데이터를 빠르게 접근할 수 있는 메모리에 저장함으로써, 메인 DB의 부하를 줄이고 응답 속도를 향상시킵니다.
캐시(Cache)란?
캐시는 한 번 조회된 데이터를 메모리와 같은 특정 공간 에 미리 저장해놓고, 이후 동일한 요청이 발생하면, DB에 다시 요청하는 대신 이 저장된 데이터를 활용하여 빠르게 응답하는 프로세스를 의미합니다.
💡 Redis는 싱글 스레드 입니다.
-
단일 스레드지만, I/O Multiplexing 이라는 기술을 사용하여 동시에 들어오는 여러 요청들을 감시하고, Event Loop를 사용하여 각 요청을 순차적으로 빠르게 처리합니다.
이는 멀티 스레드 환경에서 볼 수 있는 효율적인 요청 처리의 장점을 단일 스레드의 구조에서도 가능하게 합니다. -
멀티 스레드 사용 시 발생하는 context-switching 비용을 줄일 수 있습니다.
-
싱글 스레드 이면서 Redis의 자료구조가 Atomic 하기 때문에, 멀티 스레드 환경에서 자주 발생하는 race condition 을 피할 수 있습니다.
문맥교환(Context-Switching) 이란?
멀티 스레드 환경에서, CPU는 여러 스레드 간에 지속적으로 전환해야 합니다. 이 때마다, CPU는 현재 스레드의 상태를 저장하고, 다음 스레드의 상태를 불러오는 과정을 거치는데, 이 과정을 문맥교환이라고 합니다.
Race Condition 이란?
멀티 스레드 환경에서는 여러 스레드가 동시에 같은 데이터에 접근하여 이를 변경할 수 있습니다. 이 경우, 최종적으로 데이터가 어떤 상태가 될지는 스레드들이 데이터에 접근하고 수정하는 순서에 따라 달라질 수 있습니다. 이러한 현상을 경쟁 상태(Race Condition)라고 하며, 이는 예측할 수 없고 일관성 없는 데이터 상태를 발생시킬 수 있습니다.
🚩 Redis의 장점 정리
Redis는 간결한 Key-Value 구조를 사용합니다. 이는 복잡한 관계형 모델이나 JOIN 연산이 필요 없어 데이터의 저장과 조회 과정을 단순화시키며, 이로 인해 데이터 처리 속도가 더욱 빨라집니다.
또한 인 메모리 데이터 구조를 활용하여 뛰어난 속도를 제공합니다.
이러한 특성들로 인해 Redis는 빠른 데이터 처리/응답이 필요한 상황에서 매우 유리합니다.
4. Redis 사용 시 고려사항
📍 메모리의 용량은 한계가 있어 대용량 데이터 처리에는 적합하지 않을 수 있고, RAM은 비싸기 때문에 비용이 많이 들 수 있다는 단점이 있습니다.
📍 서버에 장애가 발생했을 경우 데이터 유실이 발생할 수 있기 때문에 이에 대한 대비책이 필요합니다.
Ref.
https://brunch.co.kr/@skykamja24/575
https://aws.amazon.com/ko/elasticache/what-is-redis/
https://zangzangs.tistory.com/72
[Redis] 레디스 알고 쓰자. - 정의, 저장방식, 아키텍처, 자료구조, 유효 기간
레디스(Redis) 와 싱글스레드(Single Thread)
