강화학습 lecture1
State
Actor = agent
- action
- observation (subset of state)
Environment - reward
Google Data Centre
Cooling Bill by 40%
(스위치 언제끄고 키고 등)
로보틱스 - 관절의 움직임
비지니스 - 재고 관리, 자원 할당
재무 : 투자 결정, 포트폴리오 디자인
이커머스/미디어 - 어떤 콘텐츠를 사용자에게 보여줄지
- 어떤 광고를 보여줄지
강화학습 Lecture 2: Playing OpenAI GYM Games
Frozen Lake World (OpenAI GYM)
Start, Hole, Goal
Agent
- action(right, left, up, down) -> Env
- state, reward <- Env
import gym
env = gym.make("FrozenLake-v0")
observation = env.reset()
for _ in range(1000):
env.render()
action = env.action_space.sample()
observation, reward, done, info = env.step(action)처음엔 아무것도 보이지 않고 한 걸음 가야 보임
Lab2 : Playing OpenAI GYM Games
keyin and move
Lecture 3 : Dummy Q-learning
각각의 행동에 대해서 잘했는지 못했는지 말해주지 않음
- 게임이 끝나서야 보상 혹은 패널티 받음
Frozen Lake : Even if you know the way, ask.
"아는 길도, 물어가라"
Q 라는 형님 : 그 길이 좋은지 안좋은지 알려줌. 내가 해봐서 아는데...
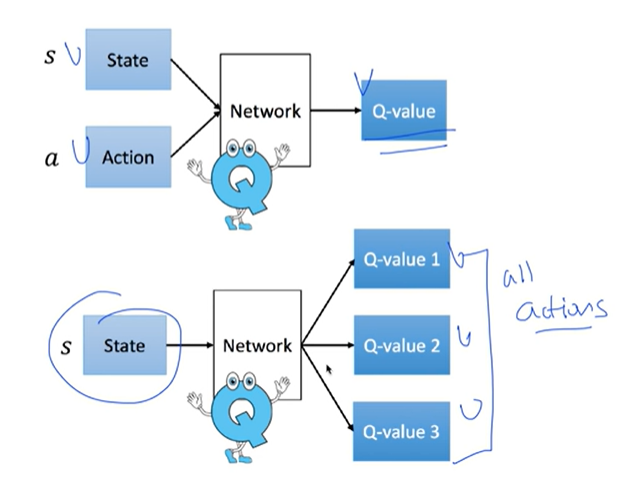
Q(state, action)
- 입력 1 : state
- 입력 2 : action
- 출력 : quality (reward)
Policy using Q-function
- Q maximum value 찾기 -> max를 주는 argument를 찾음
. 이걸 수학적으로 정의
. max{a} Q(s1, a) = Max Q
. argmax{a} Q(s1,a) -> Right = pi(s)
. = optimal
Optimal Policy, pi and Max Q
Q를 어떻게 구할 수 있을까?
-
가정 : Assume (believe) Q in s' exists!
즉 다음 상태에서의 Q 값이 존재한다. -
My condition
-
I am in s
-
when I do action a, I'll go to s'
-
When I do action a, I'll get reward r
-
Q in s', Q(s',a') exists!
R_t = r_t +
R(t) = r_t + R(t+1)
R(t)* = r_t + maxR(t+1)
Q(s,a) = r + max_a'Q(s',a')
Learning Q(s,a) table
Q(s,a) = r + maxQ(s',a')
Learning Q(s,a) Table (with many trials)
initial Q values are 0
Q(s14, a_right) = r = 1
Dummy Q-learning algorithm
For each s,a initialize table entry Q(s,a) <- 0
Observe current state s
Do forever:
- selelct an action a and execute it
- Receive immediate reward r
- Observe the new state s'
- Update the table entry for Q(s,a) as follows:
Q(s,a) <- r + max_a'Q(s',a') - s <-s'
Lab3 : Dummy Q-learning
# Initialize table with all zeros
Q = np.zeros([env.observation_space.n, env.action_space,n]) #16x4
# Set learning parameters
num_episodes = 2000
# create lists to contain total rewards and steps per episodes
rList = []
for i in range(num_episodes):
# Reset environment and get first new observation
state = env.reset()
rAll = 0
done = False
# The Q-Table learning algorithm
while not done:
action = rargmax(Q[state, :]) # Q 값이 똑같다면 랜덤하게 간다
# 즉, 값이 다 0이면 랜덤하게 이동시킴
# Get new state and reward from environment
new_state, reward, done,_ = env.step(action)
# Update Q-Table with new knowledge using learning
Q[state, action] = reward + np.max(Q[new_state, :])
state = new_state
rList.append(rAll)
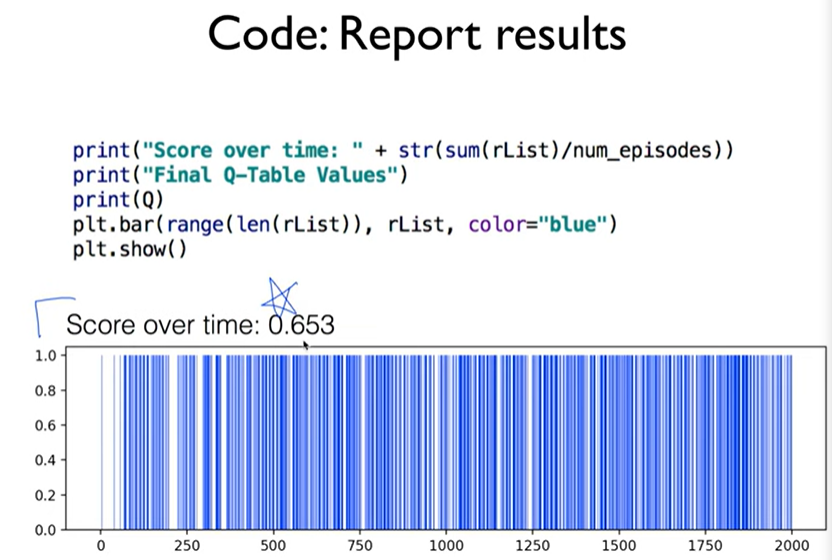
# post processing
print("Success rate: " + str(sum(rList)/num_episodes))
print("Final Q-Table Values")
print("Left down right up")
print(Q)
plt.bar(range(len(rList)), rList, color="blue")
plt.show()import gym
import numpy as np
import matplotlib.pyplot as plt
from gym.envs.registration import register
import random as pr
def rargmax(vector):
""" Argmax that choose randomly among eligible maximum indices. """
m = np.amax(vector)
indices = np.nonzero(vector == m)[0]
return pr.choice(indices)
register(
id='FrozenLake-v3',
entry_point='gym.envs.toy_text:FrozenLakeEnv',
kwargs={'map_name':'4x4',
'is_slippery': False}
)
env = gym.make('FrozenLake-v3')Lecture 4: Q-learning (table) exploit&exploration and discounted reward
dummy 로 부른 이유
새로운 길을 가지 않음. -> Exploit vs Exploration
Exploit (weekday) vs Exploration(weekend)

Exploit vs Exploration: E-greedy
e=0.1
if rand <e:
a = random
else:
a=argmax(Q(s,a))Exploit vs Exploration: decaying E-greedy
- 초반부에는 explore하게 학습 후반부는 exploit 하게 행동
for i in range(1000):
e = 0.1/(i+1)
if random(1) < e:
a = random
else:
a=argmax(Q(s,a))Exploit vs Exploration: add random noise
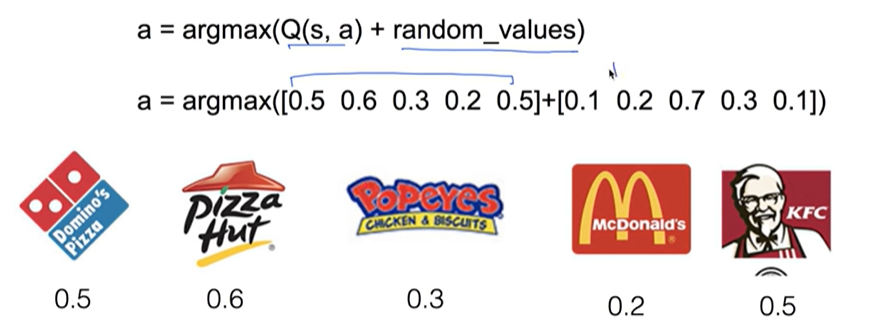
- 가장 좋은 식당말고 두 번쨰, 세 번째 좋은 식당도 가보자
for i in range(1000):
a = argmax(Q(s,a) + random_values / (i+1))
어디로 가야하오...
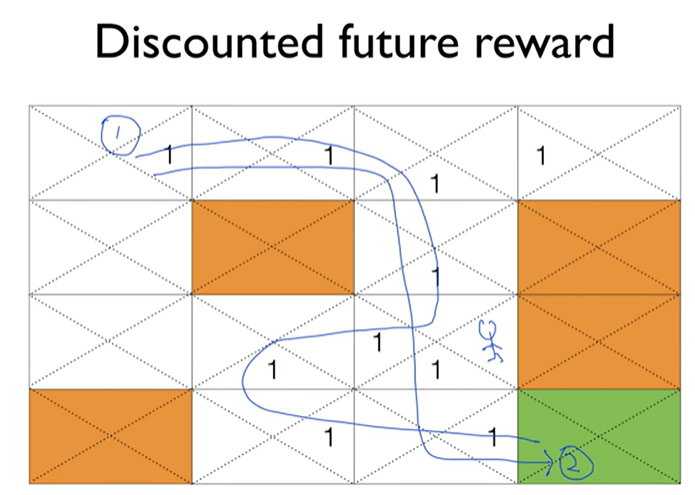
Learning Q(s,a) with discounted reward
오늘 일한건 오늘 받으면 제일 좋음!
다음에 받는건 gamma를 곱하여 할인한다.
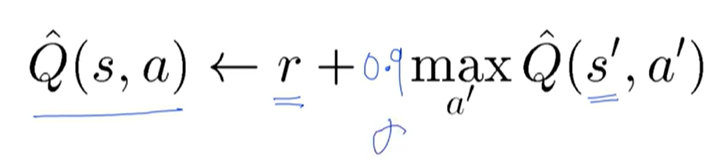

이제 에이전트는 어디로 갈지 알게 되었다!
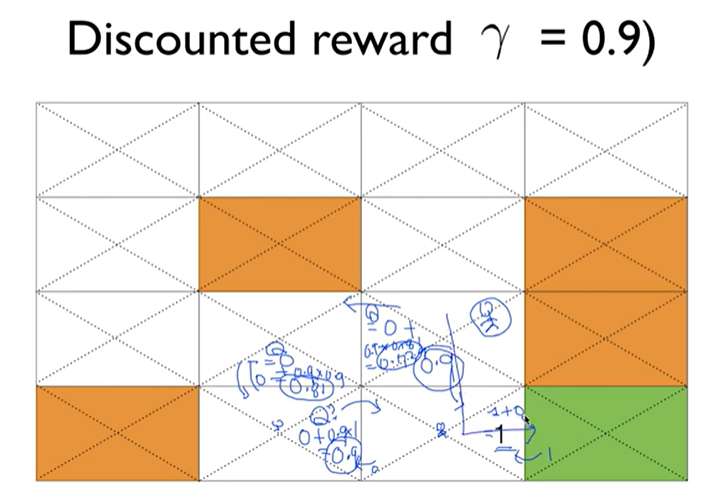
Convergence
Q-hat : 실제로 Q 값을 모르기에 근사치로 표현
Q-hat -> Q로 수렴한다 아래의 가정 시
- In deterministic worlds
- In finite states
Lab4 : Q-learning (table) exploit&exploration and discounted reward
Exploit vs Exploration: decaying E-greedy
for i in range(num_episodes):
e = 1. / ((i/100)+1)
# The Q-Table learning algorithm
while not done:
# Choose an action by e-greedy
if np.random.rand(1) < e:
action = env.action_space.sample()
else:
action = np.argmax(Q[state, :])Exploit vs Exploration: add random noise
# Choose an action by greedily (with nois)e picking from Q table
action = np.argmax(Q[sate, :] + np.random.randn(1, env.action_space.n) / (i+1))Learning Q(s,a) with discounted reward

Lecture5 : Q-learning on Nondeterministic Worlds - Windy Frozen Lake
오른쪽으로 한 칸 가고 싶어도 항상 그럴수는 없음.

Deterministic vs Stochastic (nondeterministic)
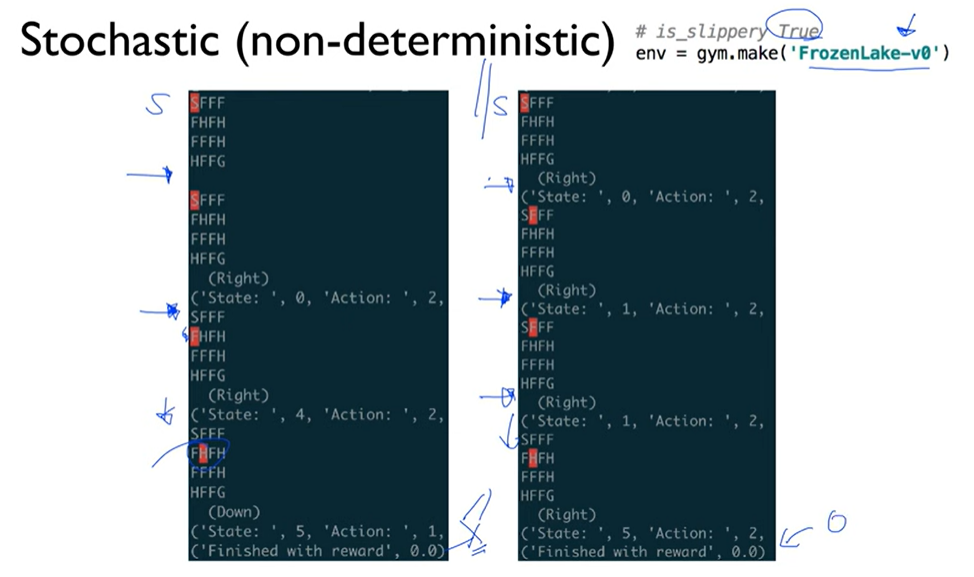
- Unfortunately, our Q-leaning (for deterministic world) does not work anymore..
멘토가 많아야 된다!
- Solution?
- Listen to Q(s') (just a little bit)
- Update Q(s) little bit (learning rate)
- Like our life mentors
- Don't just listen and follow one mentor
- Need to listen from many mentors

- 즉, Q형님의 말을 대충 듣는다.. Ex. 10%만큼만
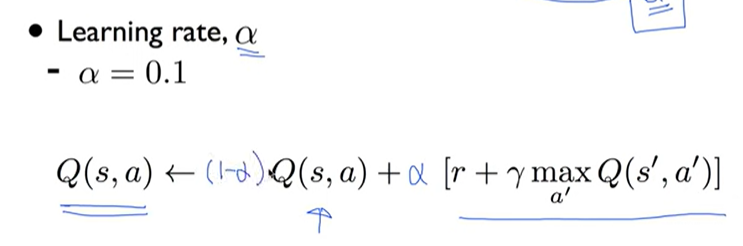
Q-leaning algorithm

Convergence
Q-hat 이 상상의 Q와 같아질까요..?
=> 네 수렴합니다.

Lab 5: Windy Frozen Lake - Nondeterministic world
Q[state,action] = (1-learning_rate) * Q[state,action] \
+ learning_rate*(reward + dis * np.max(Q[new_state, :]))
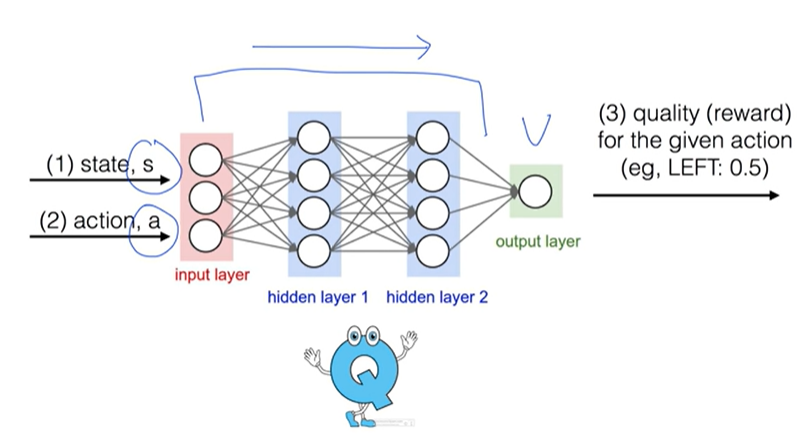
Lecture 6: Q-Network
더 큰 세상에 적용해보자..!
- 100 x 100 x 4 - Q table
- 화면/카메라 입력을 받아서 .. 80x80 pixel에 색상이 2개인 경우 Q-table의 사이즈는
픽셀 하나마다 0과 1 2가지의 경우가 80x80으로 가능하므로 2^(80x80) 사이즈의 Q-table이 필요함..즉, 너무 큼!

Q-function Approximation
상태를 입력으로 받고, 가능한 모든 action에 대해서 Q값들을 알려줌.
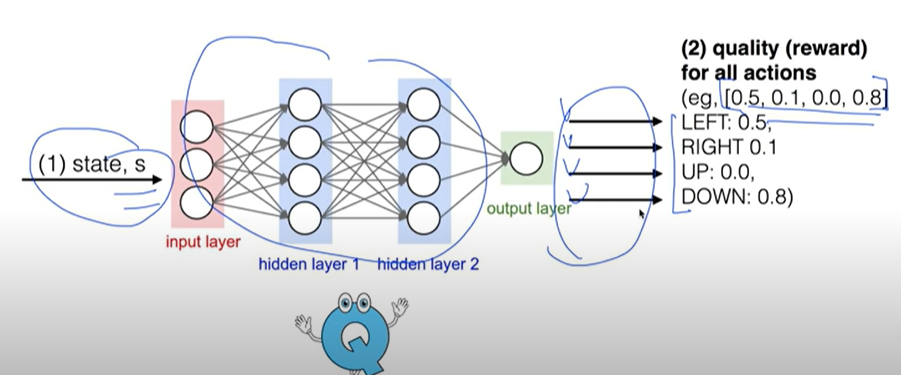
Q-Network training (linear regression)
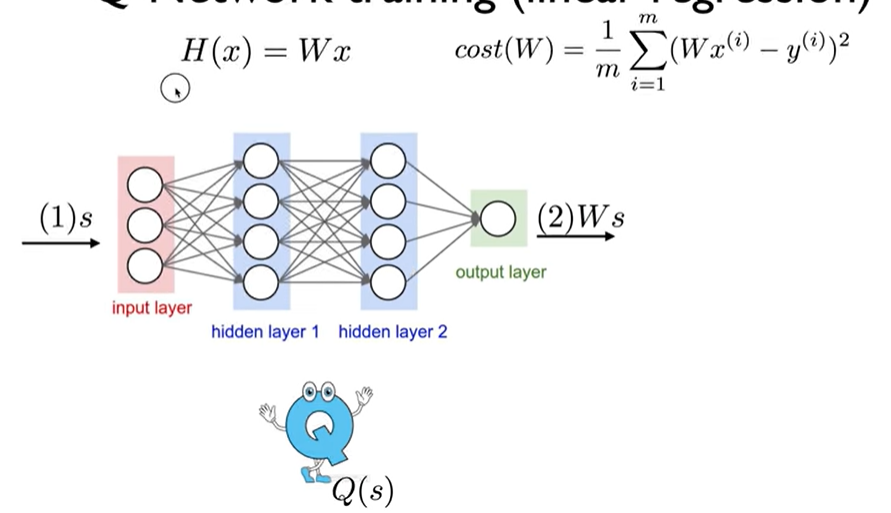
y label은 optimal Q*임
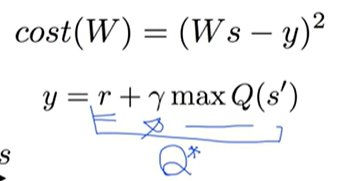
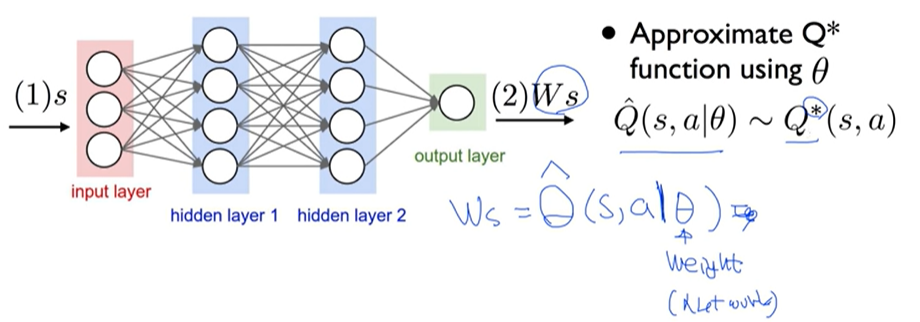

Algorithm
- 초기 random weight
- 최초 상태를 만듦, 전처리하여 파이... s와 같음
- e-greedy를 이용해서 랜덤하게 액션을 고르거나, 현재 알고 있는 네트웤에서 가장 좋은 액션 하나를 고름
- 액션을 하면 상태와 리워드를 돌려줌

Y label and loss function
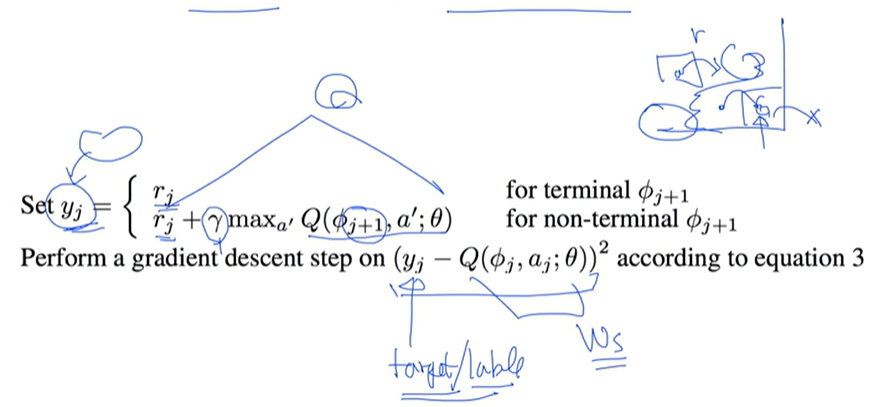
Deterministic or Stochastic?
왜 target은 stochatic으로 안하지?
그럴 필요가 없음. 학습하는 과정 자체가 stochastic world의 Q를 학습하는 것과 같음

Convergence

발산이 되서 학습이 이러나지 않았음!

다음 시간에 해결방법에 대해 알아보자!
Lab 6-1: Q-Network frozen lake
State(0~15) as input
- np.identity
- state: np.identity(16)[s1:s1+1]
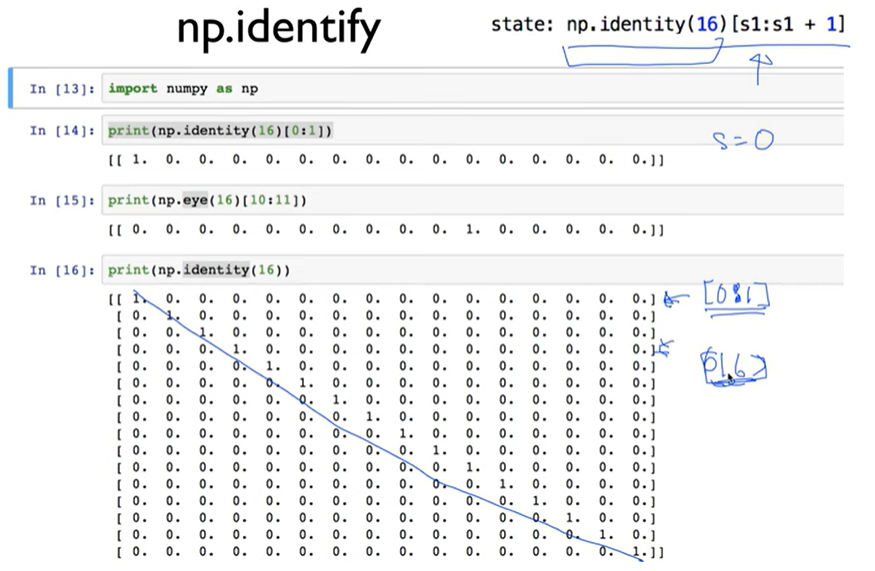
def one_hot(x):
return np.identity(16)[x:x+1]Q-Network training (linear regression)
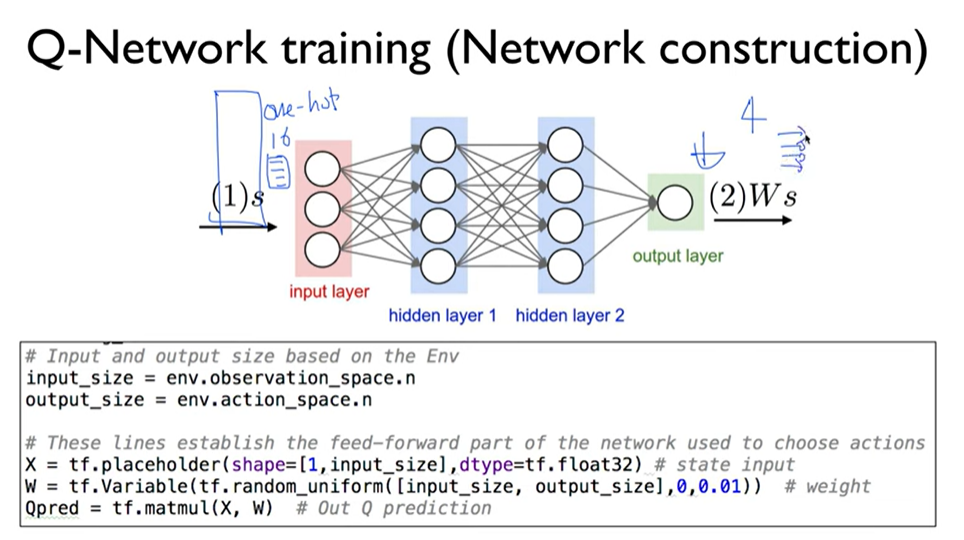
# input and output size based on the Env
input_size = env.observation_space.n
output_size = env.action_space.n
# These lines establish the feed-forward part of the network used to choose actions
X = tf.placeholder(shape=[1,input_size], dtype=tf.float32) # state input
W = tf.Variable(tf.random_uniform([input_size, output_size],0,0.01)) # weight
Qpred = tf.matmul(X, W) # Out Q prediction
Y = tf.placeholder(shape=[1, output_size], dtype=tf.float32) # Y label
loss = tf.reduce_sum(tf.square(Y - Qpred))
train = tf.train.GradientDescentOptimizer(learning_rate=learning_rate).minimize(loss)
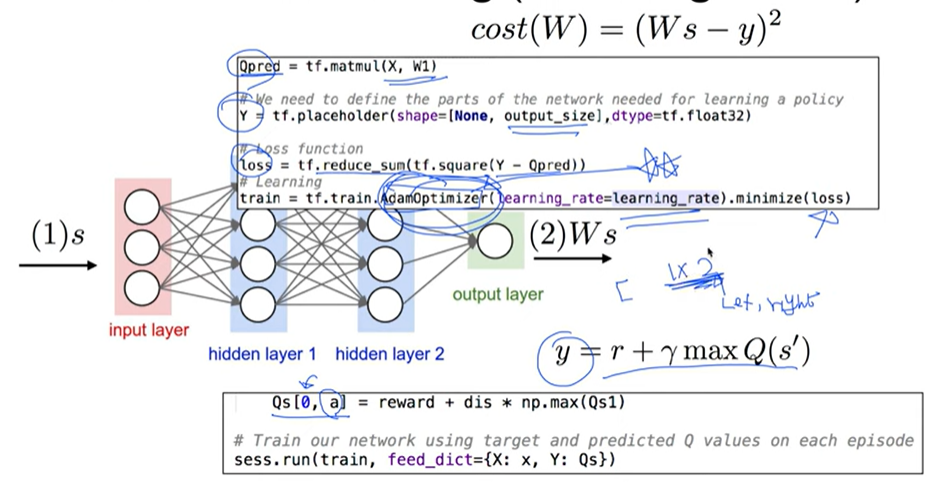
Qs[0, a] = reward + dis * np.max(Qs1)
# Train our network using target (Y) and predicted Q (Qpred) values
sess.run(train, feed_dict={X: one_hot(s), Y: Qs})Algorithm

Y label and Loss function
- terminal 상태 or not

Code: Network and setup
import gym
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
env = gym.make('FrozenLake-v0')
# input and output size based on the Env
intput_size = env.observation_space.n
output_size = env.action_space.n
learning_rate = 0.1
# These lines establish the feed-forward part of the network used to choose actions
X = tf.placeholder(shape=[1,input_size],dtype=tf.float32) # state input
W = tf.Variable(tf.random_uniform([input_size, output_size],0,0.01)) # weight
Qpred = tf.matmul(X, W) # Out Q prediction
Y = tf.placeholder(shape=[1, output_size], dtype=tf.float32) # Y label
loss = tf.reduce_sum(tf.square(Y-Qpred))
train = tf.train.GradientDescentOptimizer(learning_rate=learning_rate).minimize(loss)
# Set Q-learning related parameters
dis = .99
num_episodes = 2000
# Create lists to contain total rewards and steps per episode
rList = []
with tf.Session() as sess:
sess.run(init)
for i in range(num_episodes):
# Reset environment and get first new observation
s = env.reset()
e = 1. / ((i/50) + 10)
rAll = 0
done = False
local_loss = []
# The Q-Network training
while not done:
# Choose an action by greedily (with e change of random action) from the Q-network
Qs = sess. run(Qpred, feed_dict={X: one_hot(s)})
if np.random.rand(1) < e:
a = env.action_space.sample()
else:
a = np.argmax(Qs)
# Get new state and reward from environment
s1, reward, done, _ = env.step(a)
if done:
# Update Q, and no Qs+1, since it's a terminal state
Qs[0, a] = reward
else:
# Obtain the Q_s1 value s by feeding the new state through our network
Qs1 = sess.run(Qpred, feed_dict={X: one_hot(s1)})
# Update Q
Qs[0, a] = reward + dis * np.max(Qs1)
# Train our network using target (Y) and predicted Q (Qpred) values
sess.run(train, feed_dict={x: one_hot(s), Y: Qs})
rAll += reward
s = s1
List.append(rAll)
Q-Table vs Network
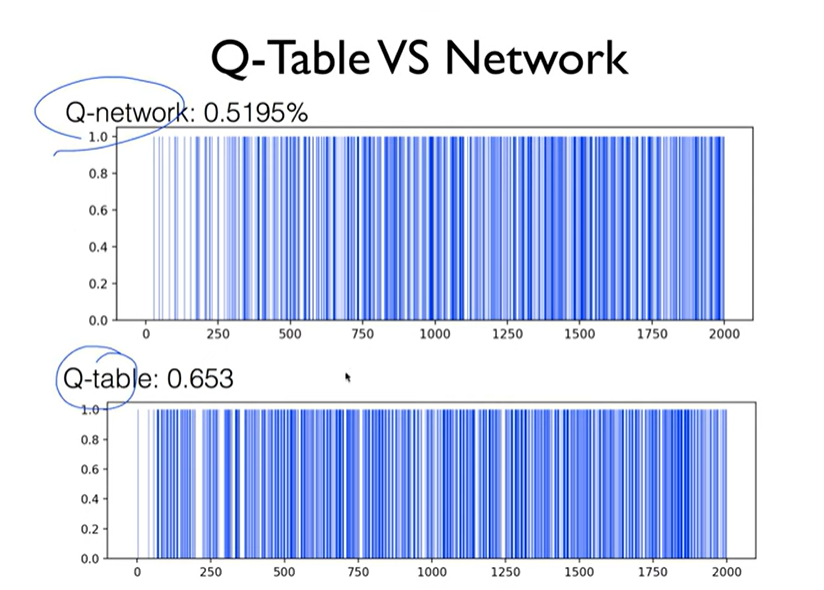
converge하지 못하기 때문에 상대적으로 성능이 떨어짐..
Exercise
- Too slow
- Minibatch?
- A bit unstable?
Lab 6-1: Q-Network for Cart Pole
Cart pole
import gym
env = gym.make('CartPole-v0')
env.reset()
random_episodes = 0
reward_sum = 0
while random_episodes < 10:
env.render()
action = env.action_space.sample() # take random action
observation, reward, done, _ = env.step(action)
print(observation, reward, done)
reward_sum += reward
if done:
random_episodes +=1
print("Reward of this episodes was:", reward_sum)
reward_sum = 0
env.reset()Rewards
# Get new state and reward from environment
s1, reward, done, _ = env.step(a)
if done:
Qs[0, a] = -100
else:
x1 = np.reshape(s1, [1, input_size])
# Obtain the Q' values by feeding the new state through our network
Qs1 = sess.run(Qpred, feed_dict={X: x1})
Qs[0, a] = reward + dis * np.max(Qs1)Q-Network training (Network construction)
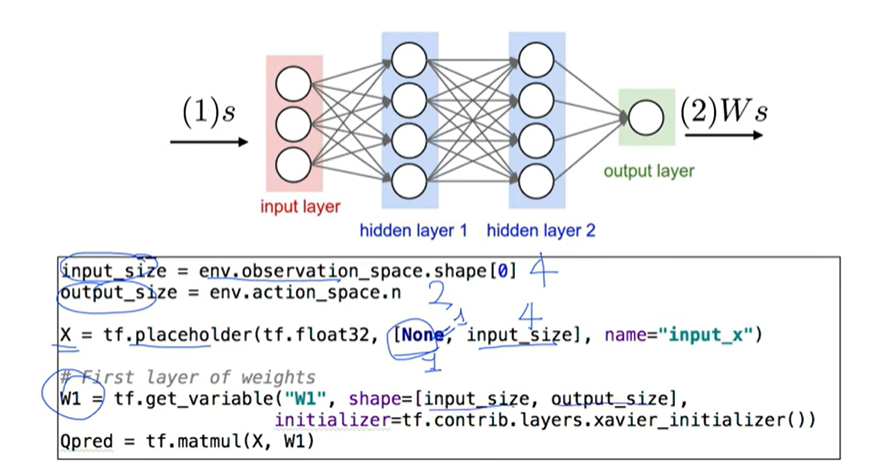
Code: Network and setup
import numpy as np
import tensorflow as tf
import gym
env = gym.make('CartPole-v0')
# COnstants defining our neural network
learning_rate = 1e-1
input_size = env.observation_space.shape[0] # 4
output_size = env.action_space.n # 2
X = tf.placeholder(tf.float32, [None, input_size], name="input_x")
# First layer of weights
W1 = tf.get_variable("W1", shape=[input_size, output_size],
initializer=tf.contrib.layers.xaver_initializer())
Qpred = tf.matmul(X, W1)
# We need to define the parts of the network needed for learning a policy
Y = tf.placeholder(shape=[None, output_size], dtype=tf.float32)
# Loss function
loss = tf.reduce_sum(tf.square(Y - Qpred))
# Learning
train = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss)
# Values for q learning
num_episodes = 2000
dis = 0.9
rList = []Code: Training
for i in range(num_episodes):
e = 1. / ((i/10) + 1)
rAll = 0
step_count = 0
s = env.reset()
done = False
# The Q-Network training
while not done:
step_count += 1
x = np.reshape(s, [1, input_size])
# Choose an action by greedily (with e chance of random action) from the Q-network
Qs= sess.run(Qpred, feed_dict={X: x})
if np.random.rand(1) < e:
a = env.action_space.sample()
else:
a = np.argmax(Qs)
# Get new state and reward from environment
s1, reward, done, _ = env.step(a)
if done:
Qs[0, a] = -100 # label = target Q
else:
x1 = np.reshape(s1, [1, input_size])
# Obtain the Q' values by feeding the new state through our network
Qs1 = sess.run(Qpred, feed_dict={X: x1})
Qs[0, a] = reward + dis * np.max(Qs1) # label = target Q
# Train our network using target and predicted Q values on each episode
sess.run(train, feed_dict={X: x, Y: Qs})
s = s1
rList.append(step_count)
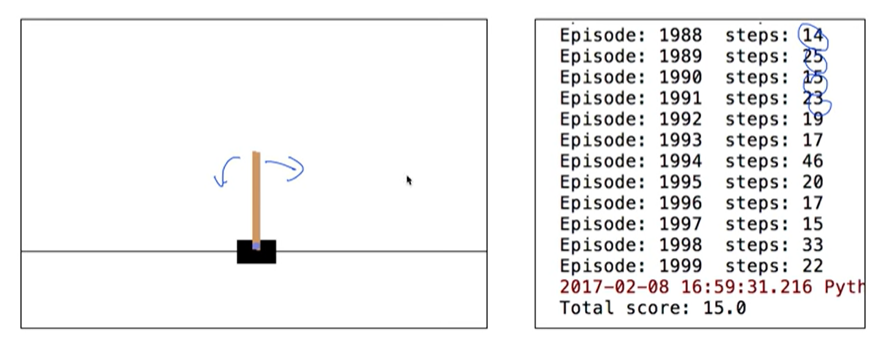
print("Episode. {} steps: {}".format(i, step_count))
# If last 10's avg steps are 500, it's good enough
if len(rList) > 10 and np.mean(rList[-10:]) > 500:
break
# See our trained network in action
observation = env.reset()
reward_sum = 0
while True:
env.render()
x = np.reshape(observation, [1, input_size])
Qs = sess.run(Qpred, feed_dict={X: x})
a = np.argmax(Qs)
observation, reward, done, _ = env.step(a)
reward_sum += reward
if done:
print("Total_score: {}".format(reward_sum))
break결과는..?

Why does not work? Too shallow
- diverge..
- 샘플간 correlation 존재
- target이 정해지지 않음. 타겟도 움직임
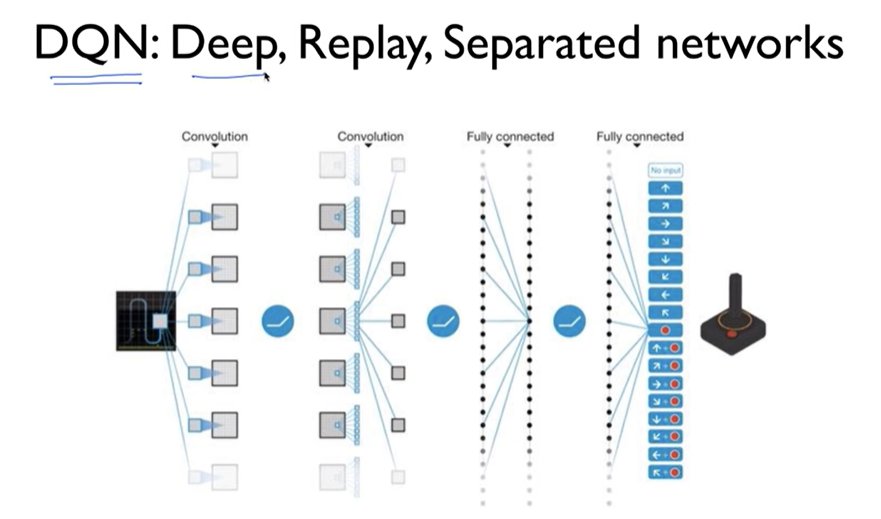
Lecture 7 : DQN
Q-Netw are unstable
Convergence
- Q^ 은 converge 하지 않음.
- Deepmind라는 회사가 두 가지 문제를 해결함
- 샘플간 correlation 존재- target이 non-stationary
Two big issues
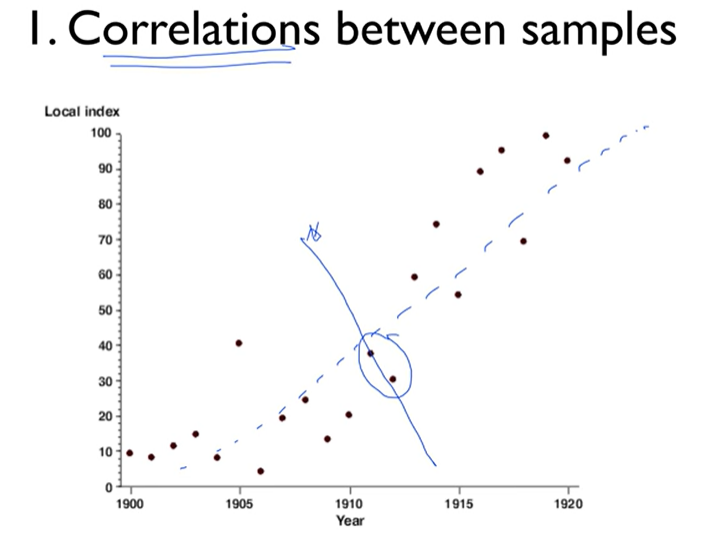
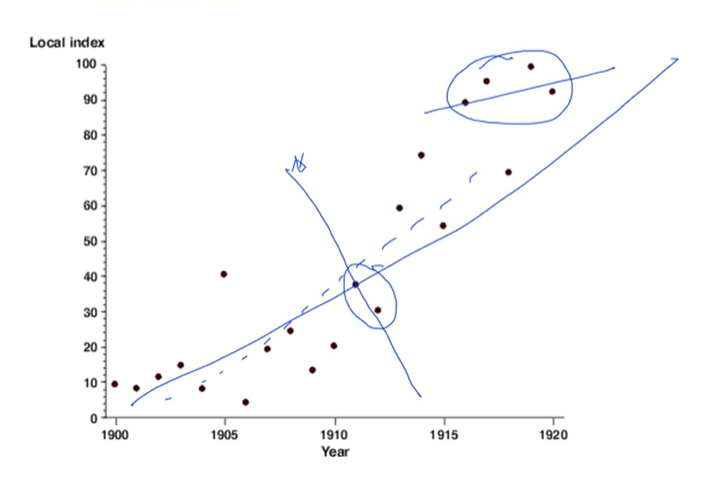
1. Correlations between samples

- 받아오는 샘플들이 너무 비슷함
오직 두 개만 가지고 학습 시키면? 이상한 선을 만듦
오직 4개만 가지고 학습 시키면?
2. Non-stationary targets
Target = Y
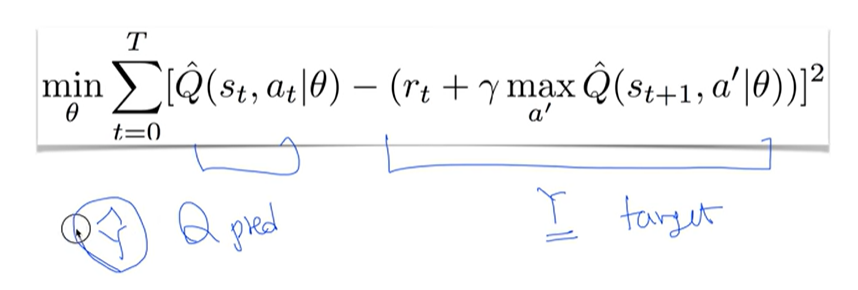
같은 네트워크 세타를 사용하기 때문에 타겟 값 Y 값도 변함
화살을 쏘자마자 과녁이 움직이는 셈... 즉, Non-stationary targets
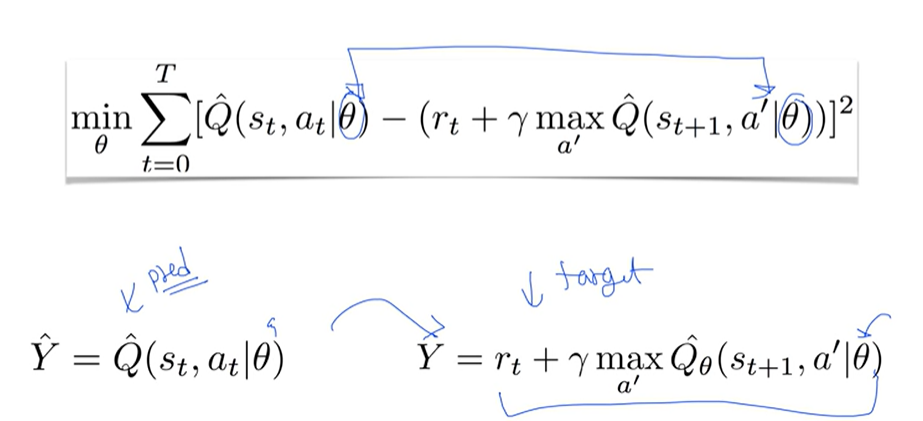
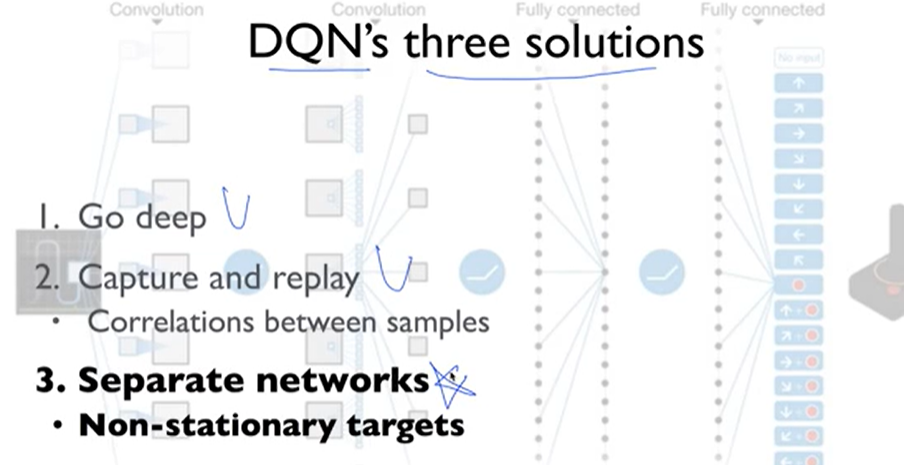
DQN's three solutions
- Go deep
Solution 1: go deep
- Capture and replay
Solution 2: experience replay
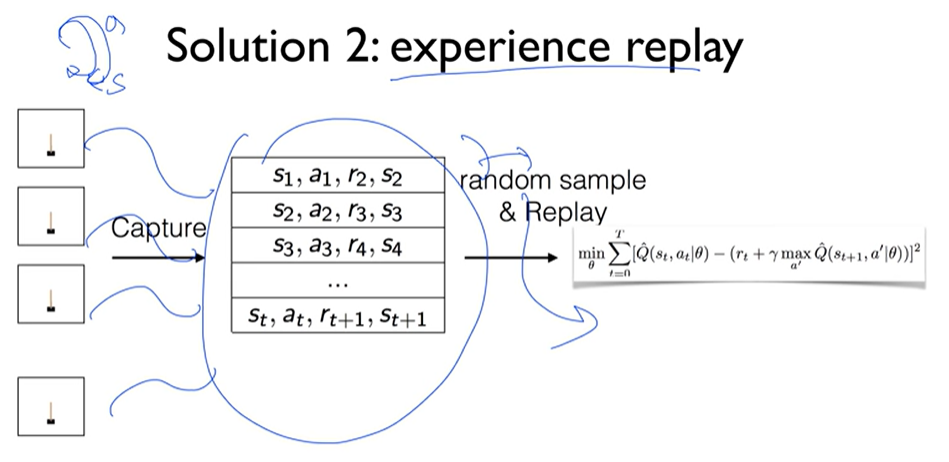
버퍼에서 랜덤하게 샘플링을 하자. 그걸로 미니배치를 만들어서 학습

- Separate Network
Problem 3: non-stationary network
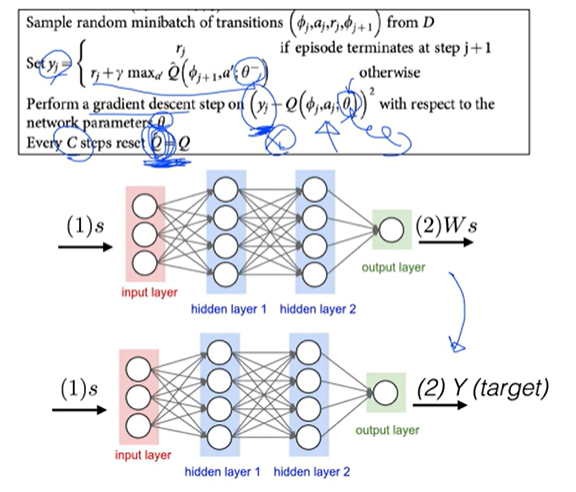
solution 3: separate target network
네트워크를 하나 더 만들자!
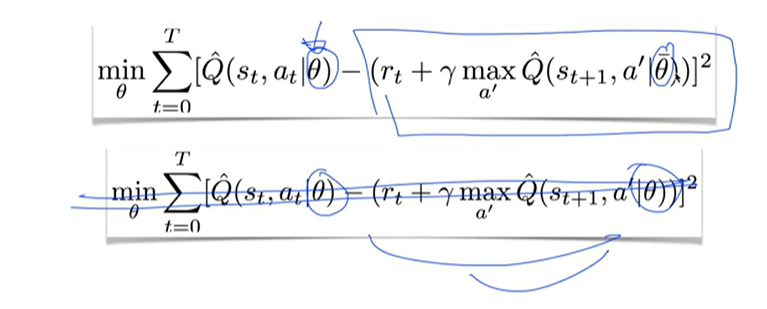
Solution 3: Copy network

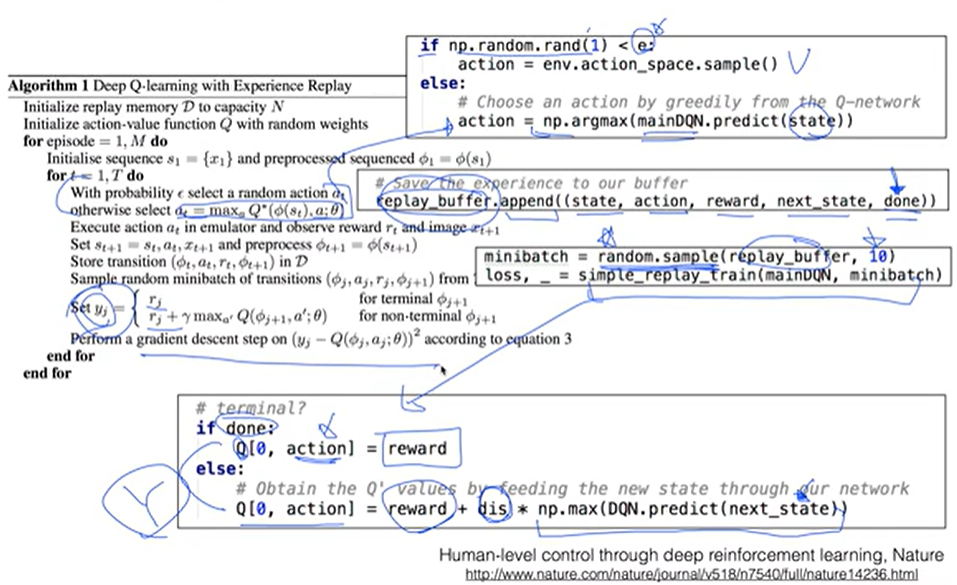
Lab7-1: DQN1 (NIPS 2013)
- random 샘플을 하여 미니배치를 뽑아서 학습
1. Go deep

2. Replay memory
# store the previous observations in replay memory
replay_buffer = deque()- 사이즈 일정하게 유지 ~ 앞에꺼 꺼내버리기
- episode를 10번에 한번씩 10개씩 가지고 학습

np.stack
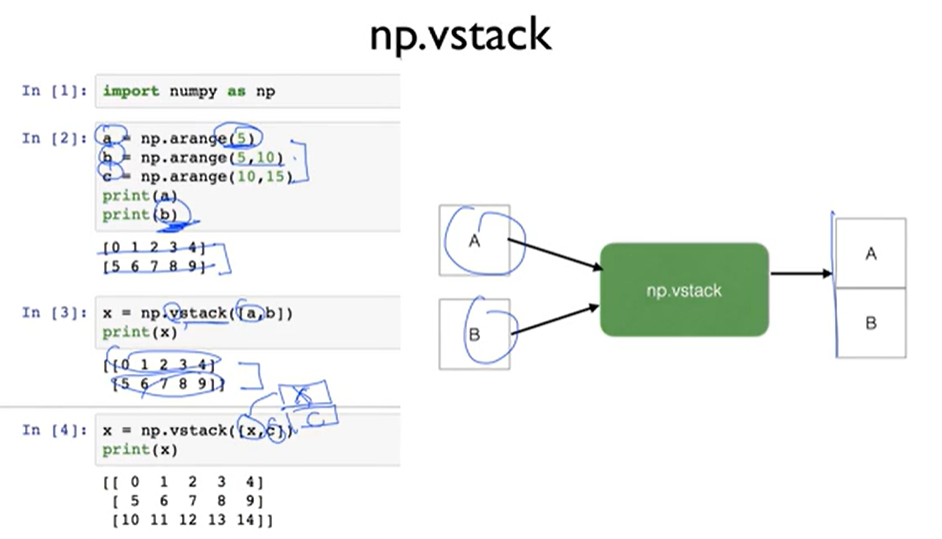
Train from replay memory

- 스텍에 쌓은 뒤 한꺼번에 업데이트 시킴!
- Net - Build - init
- Env
- action 선정
- env.step(a)
- 버퍼에 저장
- n번에 한번 랜덤하게 버퍼에 있는 데이터를 꺼내서 네트워크 학습
Code1: setup
import numpy as np
import tensorflow as tf
import random
import dqn
from collections import deque
import gym
env = gym.make('CartPole-v0')
# Constants defining our neural network
dis = 0.9
REPLAY_MEMORY = 50000Code2: Network
class DQN:
def __init__(self, ...)
def _build_network(self, ...)
def predict(self, state):
def update(self,x_stack, y_stack):Code3: Train from Replay Buffer
def simple_replay_train(DQN, train_batch):
x_stack =
y_stack = ...
# Get stored information from buffer
for state, action, reward, next_state, done in train_batch:
Q = DQN.predict(state)
# terminal?
if done:
else:
return DQN.update(x_stack, y_stack)Code 4: bot play
def bot_play(mainDQN):
s = env.reset()
reward_sum = 0
while True:
env.render()
...Code 5: main
def main():
max_episodes = 5000
replay_buffer = deque()
with tf.Session() as sess:
mainDQN = dqn.DQN(sess, input_size
Result
제한한 스탭만큼 막대기를 세울 수 있는 정도로 학습됨.
하지만 학슴 중간에 불안정한 결과들이 있음
Lab 7: DQN2(Nature, 2015)

Solution 3: separate target network
DQN vs targetDQN

Network class
- 이름으로 scope 구분함

Handling two networks
- 학습 도중에는 mainDQN만 업데이트 됨
- 매번 C step마다 targetDQN = mainDQN

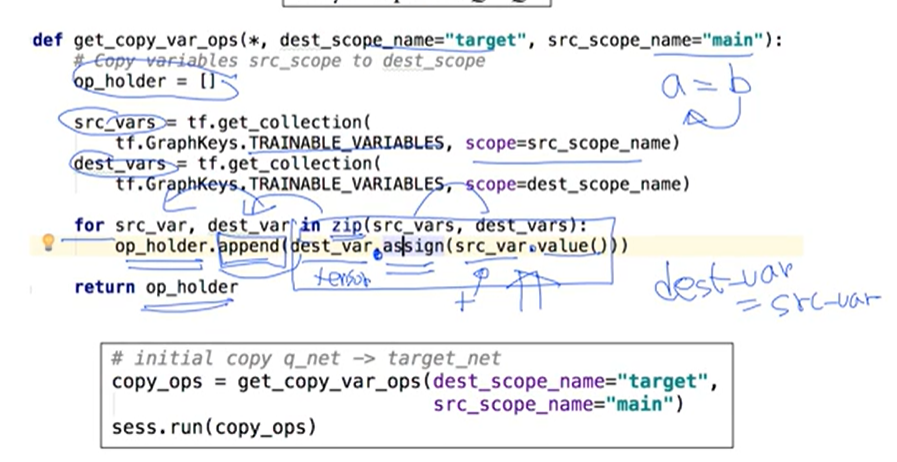
Copy network(trainable variables)
- weight = trainable variables
Recap
- Net * 2
- target = main net
- env
- loop : a=> s, r, ... => D(buffer)저장
- D(buffer)를 가져와서 학습
- Y를 빌드업할 때는 target network 사용
- 이 Y를 이용해서 main network 학습
- C 번마다 taget network = main network
Exercise 1
- Hyper parameter tuning
- Learning rate
- Sample size
- Decaying factor
- Network structure
- add bias
- test tanh, sigmoid, relu, etc.
- improve TF network to reduce sess.run() calls
- Reward redesign
- 1,1,1,1,.. -100
- 1, 0.9, 0.99, ... 0
Exercise 2
- Simple block based car race

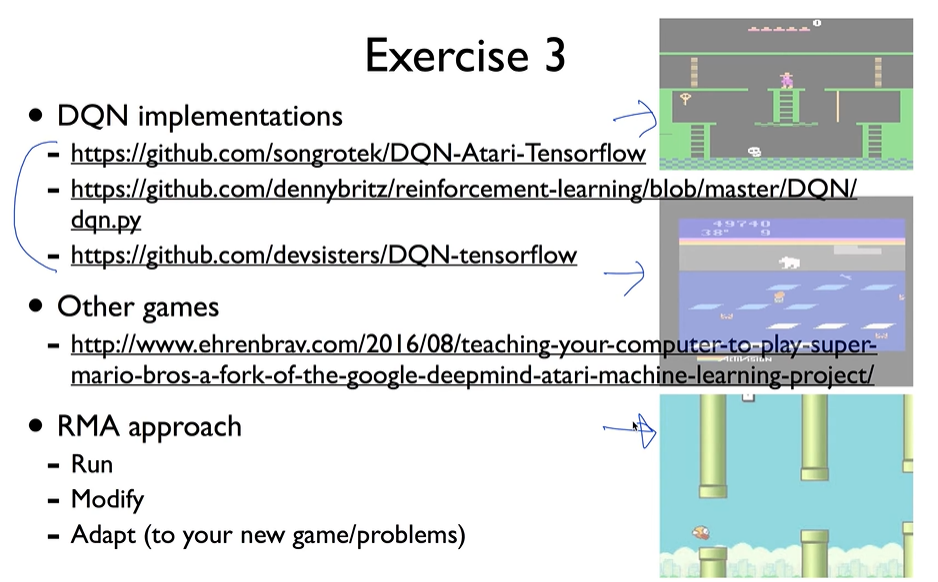
Exercise 3