[논문 리뷰] Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
paper_review
Abstract
Neural Network를 학습시키는 과정에서 각 layer에 입력되는 input의 distribution은 각 훈련 단계마다 달라진다. 이는 이전 layer의 parameter가 학습 단계마다 새로운 값으로 업데이트 되기 때문에 발생한다.
이 현상을 Internal Covariate Shift라고 하며,
본 논문에서는 Internal Covariate Shift를 줄이기 위해 Batch Normalization을 제안하였다.
Batch Normalization의 장점
1. high learning rate을 사용 가능
2. regularization의 역할을 수행
3. 학습 시간을 단축
실제로 Ensemble Batch-Normalized Network를 사용해 ImageNet Classification를 수행했을 때, top-5 validation error가 human rater의 정확도를 훨씬 능가한 4.9%를 달성했다.
1. Introduction
Deep Neural Network를 학습할 때 SGD(Stochastic Gradient Descent)를 사용하면 효과적인 학습을 할 수 있다고 잘 알려져 있다. SGD에서는 각 훈련 단계마다 크기가 m인 mini-batch(, ..., )을 사용하여 학습을 한다.
SGD의 장점
1. Mini-batch의 loss의 gradient로 전체 training set의 gradient를 추정할 수 있다.
2. 크기가 m인 mini-batch의 계산량은 m개의 individual examples의 계산량보다 적다.
SGD의 주의점
1. model hyper-parameter를 튜닝하는데 주의해야한다.
2. model의 parameter의 initialization을 잘 해야한다.
그런데 모델 학습 과정에서 학습 성능을 낮추는 문제가 있다.
매 훈련 단계마다 backpropagation으로 layer의 parameter가 조금씩 바뀌게 되는데, 그 결과 그 뒤 layer들의 input distribution이 매번 변하게 된다. 그러므로 모델은 훈련 단계마다 각 layer의 변화하는 input distribution을 학습해야 한다. 이를 모델이 covariate shift 를 경험했다고 말한다.
모델의 전체 학습 과정에서 covariate shift를 경험하면 그동안 domain adaptation으로 해결했지만 모델의 sub-network나 하나의 layer에서 covariate shift를 경험한다면 다른 해결책이 필요하다. 또한, 만약 모든 sub-network가 고정된 input distribution을 가진다면 sub-network의 학습 뿐만 아니라 sub-network의 바깥 layer들의 학습에도 긍정적인 영향을 끼쳐 학습 성능이 높아질 수 있다.
예를 들어, 아래와 같은 식이 있을 때,
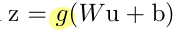
g: sigmoid 활성화 함수
u: input
W: weight
b = bias
추가적으로 Wu + b (=g의 input)을 x라고 하자.
sigmoid 활성화 함수 특성상 x의 절댓값이 커지면 g'(x)는 0에 가까워지고 u로 흘러들어가는 gradient가 사라지므로 u가 업데이트 되지 않아 학습 수렴 속도가 느려진다는 문제가 있다.
그러나 x는 W, b, 그리고 그 아래에 있는 모든 layer들의 parameter에 영향을 받기 때문에 x는 gradient가 0인 saturated 영역으로 빠질 확률이 높아진다.
이런 문제로 인해 지금까지는
1. sigmoid 활성화 함수 대신 ReLU 활성화 함수를 사용하거나
2. saturated 영역으로 빠지지 않도록 parameter inintialization에 매우 신경쓰거나
3. 작은 learning rate을 사용했다
하지만, nonlinearity inputs의 distribution을 고정할 수 있다면 최적화 단계에서 포화영역에 빠질 확률이 줄어들어 학습 속도가 빨라질 수 있다.
그래서 Network 내부의 layer에서 발생하는 input distribution의 변화, internal covariate shift를 줄여야 한다.
📌 본 논문에서는 Batch Normalization을 고안하여 internal covariate shift를 줄이고자 한다.
📌 BN (Batch Normalization)의 장점
1. 각 layer activation input을 안정적이고 gradient가 큰 영역에 위치시켜줌으로써 gradient에 효과적인 영향을 준다
2. Gradient가 parameter의 scale이나 initial value의 영향을 적게 받는다
3. Higher learning rate을 사용해도 된다
4. 모델을 regularize하는 효과가 있다
5. 포화 영역을 가지고 있는 활성화 함수(ex. sigmoid)를 사용할 수 있게 한다
2. Towards Reducing Internal Covariate Shift
➤ Internal Covariate Shift
: Change in the distribution of network activations due to the change in network parameters during training
모델이 학습하는 과정에서 parameter는 매 훈련 단계마다 업데이트될 것이고 이로 인해 각 layer의 input distribution은 변화한다. 이를 internal covariate shift라고 하는데 모델은 매번 이를 학습해야하므로 학습 수렴 속도가 느려질 수 밖에 없다.
그래서 Internal Covariate Shift를 줄이는 것이 중요한데, 그 방법으로 Whitening 기법 (mean = 0, variance = 1, parameter 간의 decorrelation)이 널리 사용되고 있다. 즉, 각 layer의 input에 whitening을 적용해 distribution을 고정시킬 수 있다.
➤ Whitening 과정
모델 학습 과정에서 정규화를 적용하면 모델이 정규화하는 부분을 인지하지 못해 정규화가 parameter에 끼친 영향을 고려하지 못한다. 이렇게 되면 parameter를 업데이트하면서 parameter 값이 계속 커져도 정규화로 인해 output 값은 변하지 않아 loss 값이 그대로 유지가 되는 문제가 발생한다. 이는 결국 parameter가 무한대로 커지는 것을 초래한다.
그래서 gradient descent를 계산하는 과정에서 normalization parameter들이 있다는 것을 인지하는 것이 매우 중요하다. Parameter를 업데이트하는 과정에서 input인 training example x로부터 받는 영향 뿐만 아니라 전체 training example set X로부터 받는 영향도 고려해야 한다.
그러기 위해서 backpropagation 단계에서 아래의 두 Jacobian을 계산해야한다.
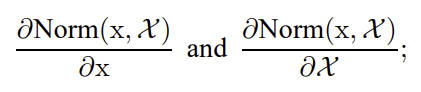
❗그러나 모든 layer의 input을 whitening 하는 것, 즉 full-whitening을 하는 것은 computation cost가 높고 모든 곳에서 미분이 가능하지 않다는 문제가 있다.
그래서 본 논문에서는 whitening의 대안인 Batch Normalization을 제안하며 이는 모든 곳에서 미분 가능하고 parameter update 과정에서 전체 training set에 대한 계산을 할 필요가 없다.
3. Normlization via Mini-Batch Statistics
위에서 언급한 full-whitening의 문제를 해결하기 위해 whitening에 두 가지 변형을 가해줬다.
- 각 feature를 scalar feature로 간주하고 독립적으로 평균 0, 분산 1로 정규화한다.
- 각 layer의 1부터 d 차원까지로 구성된 input을 mini-batch에서 추정한 평균과 분산으로 각 차원별 정규화를 한다.
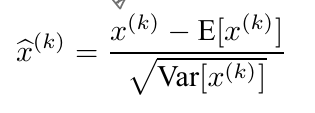
이 두 변형을 가해주면 더이상 feature 간의 decorrelation은 보장할 수 없지만 그럼에도 불구하고 정규화 학습의 수렴 속도가 빨라져 위의 두 단순화 변형을 가해주었다.
❗그런데 layer의 input에 정규화를 가해주면 해당 input이 표현하는 바가 변할 수 있다. 정규화를 해도 input의 표현력을 어느정도 유지하기 위해 학습 가능한 parameter인 r와 B를 사용해 linear transformation을 가해준다.
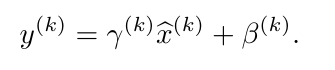
각 activation 에 대해 scale value 와 shift value 로 나타낼 수 있다.
정규화로 인해 소실된 input의 표현력을 복구하고 싶다면 적절한 와 를 사용해 입력(BN 적용 전 입력)과 출력이 같아지는 identity transformation를 해주면 된다. 이때, 와 는 hyper parameter가 아니라 learnable parameter다.
➤ Mini-batch setting을 사용하는 이유:
Batch setting에서는 모든 학습 단계마다 전체 학습 데이터셋을 사용하므로 전체 학습 데이터셋의 평균과 분산으로 정규화를 진행한다. 하지만 이는 stochastic optimization를 사용한다면 비효율적인 방식이다.
-> mini-batch별로 stochastic gradient training을 진행할 때 각 mini-batch로 평균과 분산을 추정하는 방식이 효율적이다.
✏️ Mini-batch setting에서 BN을 적용한 학습 과정
하나의 mini-batch는 m개의 샘플을 가지고 있으며 각 샘플은 dimention을 가진다. 편의상 는 생략하여 표기한다.
앞서 언급한대로, 각 는 독립적으로 정규화가 적용된다.
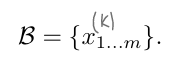
BN을 적용하고 추가적으로 linear transformation을 적용한 output은 아래와 같이 표기한다. (Batch Normalizing Transform)
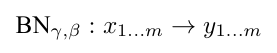
이제 모델의 학습 과정에서 BN이 어떻게 적용되는지 아래의 그림에서 알 수 있다.

각 mini-batch별로 평균과 분산을 구하여 mini-batch안의 학습 데이터를 정규화해주고 와 로 linear transform을 한 후, 최종 output을 도출한다.
이때, 와 는 learnable parameter로 학습하는 과정에서 업데이트된다. 이때 BN transform은 각 학습 데이터별로 독립적으로 수행하는 것이 아니라 다른 학습 데이터셋에 의존하여 와 를 가지게 된다.
input을 normalize하게 된 결과는 BN transform의 input으로 들어가게 되는데 이 internal에만 영향을 주는 것 뿐만 아니라 이 존재가 굉장히 중요하다. normalize를 해줌으로써 sub-network로 들어가는 input set의 distribution이 모두 고정된 평균과 분산을 갖게 된다.
이렇게 정규화된 input으로 인해 sub-network의 학습 성능이 높아질 것이며, 결과적으로 전체 네트워크의 학습 성능 또한 높아질 것이다.
3.1 Training and Inference with Batch Normalized Networks
아래의 알고리즘은 BN이 train과 inference 단계에서의 어떻게 적용되는지 보여준다.

: inference 단계에서의 BN Network
: train 단계에서의 BN Network
- 1: 초기화
- 2: 모든 k (input의 dimension)에 대해 반복한다
- 3: 에 BN + linear transformation 적용해 새로운 인풋 구하기
- 4: 의 input을 에서 로 수정
- 5: 반복문 종료
- 6: , 를 포함한 파라미터 최적화
- 7: 최적화된 파라미터를 그대로 에서 사용
- 8: 모든 k (input의 dimension)에 대해 반복한다
- 9: 이때 , ,
- 10: 여러 개의 크기가 m인 mini-batch를 훈련시킨 후, 각 mini-batch에서 나온 평균과 분산을 모두 더하고 평균낸다.
- 11: 이렇게 구한 평균과 분산을 에서 평균과 분산으로 사용해 BN transform을 진행한다.
- 12: 반복문 종료
📕 결론적으로, 본 논문에서 핵심적인 주장은 BN을 사용하면 Internal Covariate Shift를 줄이면서 모델의 학습 능력을 향상시킬 수 있다는 것이다.
