paper_review
1.[논문 리뷰] Learning Deep Features for Discriminative Localization

논문 리뷰 Learning Deep Features for Discriminative Localization\- 본 포스팅은 Class Activation Map을 중심으로 리뷰한다GAP(global average pooling)는 CNN이 image-level lab
2.[논문 리뷰] Probabilistic Weather Forecasting with Deterministic Guidance-based Diffusion Model

Probabilistic Weather Forecasting with Deterministic Guidance-based Diffusion Model 논문 리뷰
3.[논문 리뷰] Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
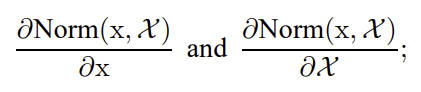
Abstract Neural Network를 학습시키는 과정에서 각 layer에 입력되는 input의 distribution은 각 training step마다 달라진다. 이는 이전 layer의 parameter가 새로운 값으로 update되기 때문에 발생하며 이 현상을
4.[논문 리뷰] Attention Is All You Need
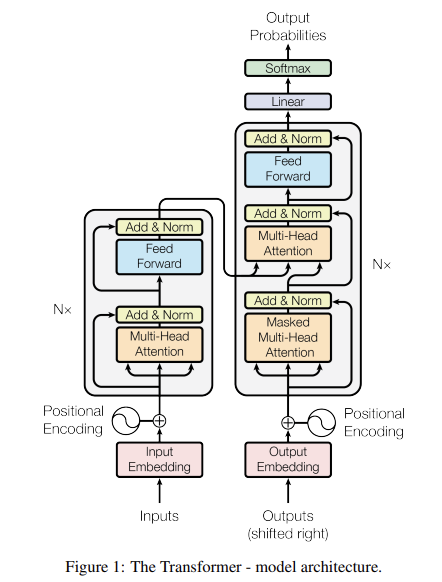
Sequence Modeling으로 Sota 성능을 내는 모델은 RNN, LSTM, GRU과 같은 recurrent model이다. 하지만 이른 recurrent model은 계산의 병렬화가 어렵다는 문제가 있다. 왜냐하면 recurrent model은 sequence
5.[논문 리뷰] Decoupled Weight Decay Regularization

1. Introduction Adaptive Gradient Method (ex. AdaGrad, RMSProp, Adam)은 feed forward nework나 RNN의 디폴트 optimizer가 되었지만, image classification dataset에 대해
6.[논문 리뷰] Improving Language Understanding by Generative Pre-Training
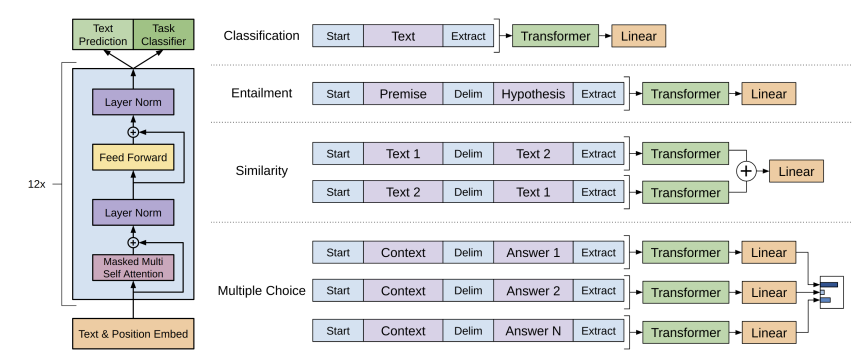
Abstract 주요 Natural language understanding tasks Textual Entailment Question Answering Semantic Similarity Assessment Document Classification 이 task
7.[논문 리뷰] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
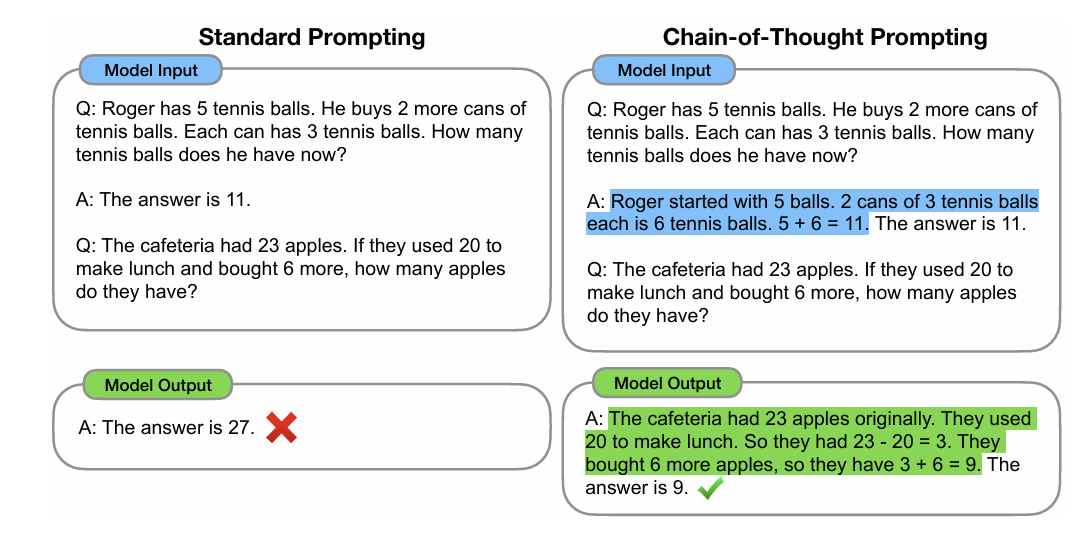
본 논문은 Chain of Thought (중간 단계에서 추론한 series)를 생성함으로써 여러 large language 모델의 추론 성능을 높일 수 있다는 것을 밝혀냈다. 구체적으로 CoT prompting, 즉 prompting에 몇 가지 예시 CoT를 추가하는
8.[논문 리뷰] Emergent Abilities of Large Language Models

논문 출처: https://arxiv.org/pdf/2206.07682 Abstract 다양한 downstream 테스크들에서 모델의 스케일을 키웠을 때 성능과 데이터 효율성이 좋아진다는 것을 예측할 것 있다고 알려져 있다. 반면, 본 논문에서는 LLM 모델의 Eme
9.[논문 리뷰] Layer Normalization
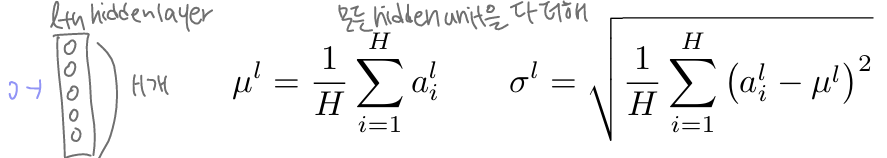
Batch Normalization을 사용하면 아래와 같은 장점이 있다.1\. training time 감소2\. regularization 효과 ❗그러나 Batch Normalization을 사용하며 아래와 같은 단점이 있다.RNN에서 BN을 사용하기 어려움RNN 같
10.[논문 리뷰] Training language models to follow instructions with human feedback
문제 상황 LM을 크게 만든다고 해서 사용자의 의도를 맞추는 것이 나아지지 않는다. 즉, LLM은 사용자에게untruthful, toxic, not helpful한 아웃풋을 생성할 수 있다. 이 맥락에서 모델은 사용자의 의도와 align하지 않다고 말한다. 이런 아웃풋