Ai (Artificial Intelligence) / ML (Machine Learning) / DL (Deep Learning)
Ai 란, 인간의 지능을 모방하는 모든 기술
ML 이란, 인공지능 Ai 를 구현하기 위한 하나의 방식으로 컴퓨터가 데이터에서 어떠한 패턴 또는 특징들을 스스로 학습하고 기억하게 하는 기술
Dl 이란, ML 방법중 하나로 인공신경망(neural network)을 깊게 쌓은 심층 인공신경망(deep neural network)을 통해 데이터로부터 의미 있는 정보를 학습하여 인공지능을 구현하는 방식

source : https://levity.ai/blog/difference-machine-learning-deep-learning
인공지능은 사람의 지능을 '모방' 하기 때문에 사람이 학습하는 방식을 알아야하짐만 사람이 학습하는 방식을 그대로 따라할 수는 없다. 사람은 성장하면서 학습을 통해 지능을 습득하며 적은 정보들을 가지고 다양하게 표현하고 활용할 수 있지만, Ai 는 다르다.
예시로 딥러닝 모델이 개와 고양이를 구별하는 아주 간단한 능력을 구사하기 위해서는 고양이와 개의 사진들이 많이 요구된다. 이마저도 작은 노이즈 하나로 예상과는 완전히 다른 결과로 나올 수 있다.
ML, 머신러닝 기본 유형
- Prediction : Supervised learning, Semi-supervised learning, Active learning
- Understanding : Clustering, non-parametric probability, distribution estimation, novelty detection
- Policy (control) : Reinforcement learning
Prediction, 어떤 것을 예측하는 것을 학습
supervised learning(지도 학습) 의 경우 데이터 셋에 모델의 입력으로 사용되는 데이터와 정답을 알려주는 라벨 데이터가 모두 존재
그래서 머신러닝 모델에 input data 를 넣어줬을 때 정답을 알려주면서 모델이 학습
모든 데이터에 정답이 있지는 않다. 오히려 정답 라벨이 없는 데이터가 더 많다. 이럴때는 Semi-supervised learning 을 통해 모델을 학습시킬 수 있음
만약, 정답이 없는경우 ?
이게 정답이다!! 라는 걸 제공하지 않음
Understanding, 데이터 자체를 학습
Unsupervised learning(비지도 학습) 을 통해 학습을 시킨다. 여러 데이터들의 비슷한 점들을 모아 군집화(clustering)하여 예측하는 방식
Policy, 룰을 찾아 학습
예측하는 방식에 Reinforcement learning(강화 학습)이 있는데, 이는 예측하는 과정에서 규칙을 넣어 보상과 처벌을 주어 행동을 억제하면서 학습하게 하는 방식
그래서? 뭘 알고 가야하지?
Ai, 머신러닝을 이용하여 데이터를 가지고 무언가를 하려 한다면 먼저 구조를 이해해야 함
먼저,
DATA SET

데이터는 머신러닝에서 가장 중요한 부분으로 전체 데이터량을 목적에 맞게 미리 분할하여 사용하게 된다. 복잡한 데이터의 경우 학습하기위해 더 많은 데이터를 필요로 하게 된다.
LOSS
- inference(추론) - 데이터를 모델의 입력값으로 넣고 에측하는 것
- estimation(추정) - 노이즈가 있는 training set 을 바탕으로 최적의 모델을 찾는 것
- evaluation(평가) - 모델의 예측값과 실제 정답 사이의 차이를 평가
=> 이 차이를 나타내는 함수가 loss function
보지 못한 데이터에 대해 낮은 loss를 가지는 능력을 일반화(generalization) 라고 한다.
즉, 보지못한 데이터에 대해 일반화가 잘 될수록 모델이 잘 학습되었다고 할 수 있다.
그래서 학습과정은,
training dataset 을 입력값으로 사용하여 모델에서 예측을 실행 -> 예측과 실제 정답을 비교하는 loss function을 통해 예측값과 정답간의 차이를 구한다. 차이를 줄이는 방향으로 학습해야하므로, 오차의 미분을 네트워크에 전달하는데 이를 역전파라고 한다. 학습은 training loss 를 줄이는 방향으로 진행되지만 모델의 일반화능력을 평가하기 위해서 test loss 를 확인하게 된다.
세상의 모든 데이터를 모을 수는 없다. training/test set 은 데이터중에서 몇개를 뽑아온 일부데이터일 뿐이다. 또한 이 과정에서 노이즈가 추가된다. (나무사진에 새가 날아들어서 찍히거나 다른종류의 카메라로 찍거나 등등 변수에 의한 노이즈들) 머신러닝은 이러한 노이즈를 감안하고도 인식을 잘 할수 있는 모델을 만드는 것이 목적이다.
MODEL
일반적으로 모델이라고 하면 MLP, CNN, Transformer, LSTM 등 매우 다양하다.
모델이란 어떤 parameter theta 로 정의되는 mapping function 이라고 할 수 있다. (어떠한 input X 를 받아서 output Y 를 출력하는 mapping function)
모델이 아주 복잡해진다는 건 (Complexity 가 높다면) 주어진 데이터 셋을 아주 잘 학습해서 해당 데이터 셋에서는 아주 좋은 성능을 보이게 되지만, 학습되지 않은 데이터를 일반화 하지 못하기 때문에(범용성 급락) 과적합(overfitting)되었다고 할 수 있다.
반대로 모델이 아주 간단하다는건 (Complexity 가 낮다면) 주어진 데이터 조차 제대로 예측하지 못할 것이다.
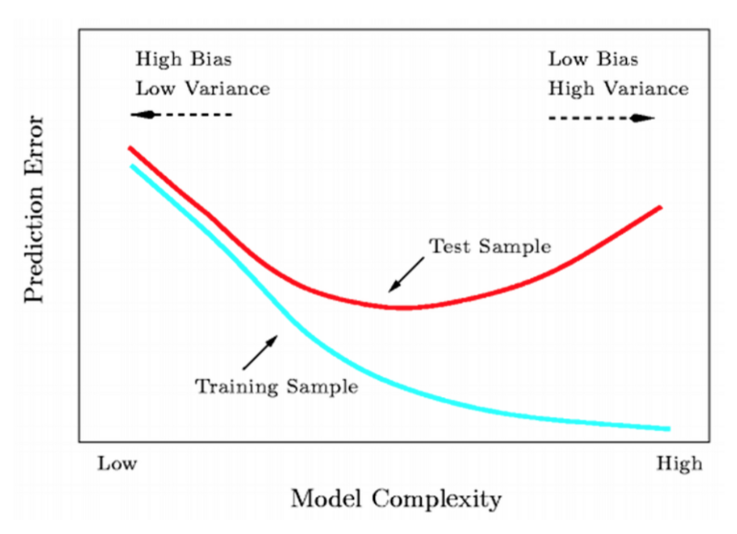
source : https://supermemi.tistory.com/160
