⬇️ Main Note
https://docs.google.com/document/d/1-eH_yBUhPpvdizNdblevmtFpXr5XpStC3KgcGywECfU/edit
✨ [History of Log-in]
-
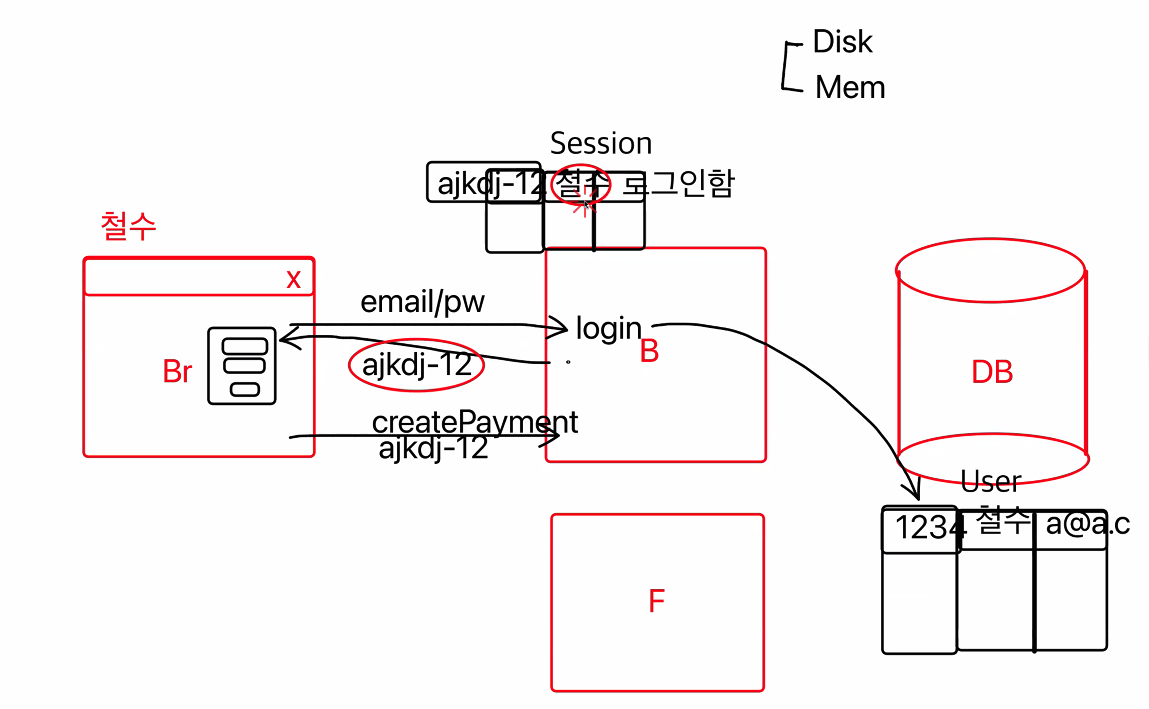
Email and password data are sent from browser to backend with the request of login-API.
-
Inside the data base, there is a data table that contains the user log in data. Then it finds out the corresponding data.
--> (ex) Josh 123#1 a@b.com) -
When the log in data is found, backend memory saves the user log in data into a variable called "Session". Session is a type of memory-based-data.
-
Since the user is logged in, every single requests the user sends is requested with session number.
--> For example for payment, the computer should know who(which id/user) is trying to pay the money.
-
When the traffic gets higher, meaning that when lots of people start to join in, backend cannot handle all the requests at once. Backend responds one at a time.
-
CPU helps backend computer to solve all the requests in a short time.
--> It's a memory that saves left waiting users or sending data, etc.
--> Scale-up => Increasing CPU -
Even iof there are bunch of backend computer, the number of API is the same. So it is possible to expand backend computer.
--> Scale-out => Expanding by copy and pasting.
[Problems]
1
-
It is still hard to divide those copied backend computers.
-
What if Josh went to different browser because the previous browser was full? ( people 10/10)
--> The new browser isn't the one where Josh logged in, so scale-out is impossible. -
Stateful => Each backend computer having its own state!
-
To solve this problem, Login Session should be saved inside the data base.
--> Literally the log-in data are saved inside the data base.
--> For data base, it doesn't matter how large the database are expanded.
--> Stateless
2
Then What's the difference between expanding backend copmuter and expanding data base?
- When 3 backend, 3 database is needed.
--> This is hard: If million data are saved in data base, all those millions of data should be also contained inside the rest of data base. (유지보수 up)
Q. How to solve these problems?
➡️ 🧩 Data Partitioning
✨ [Data Paritioning]
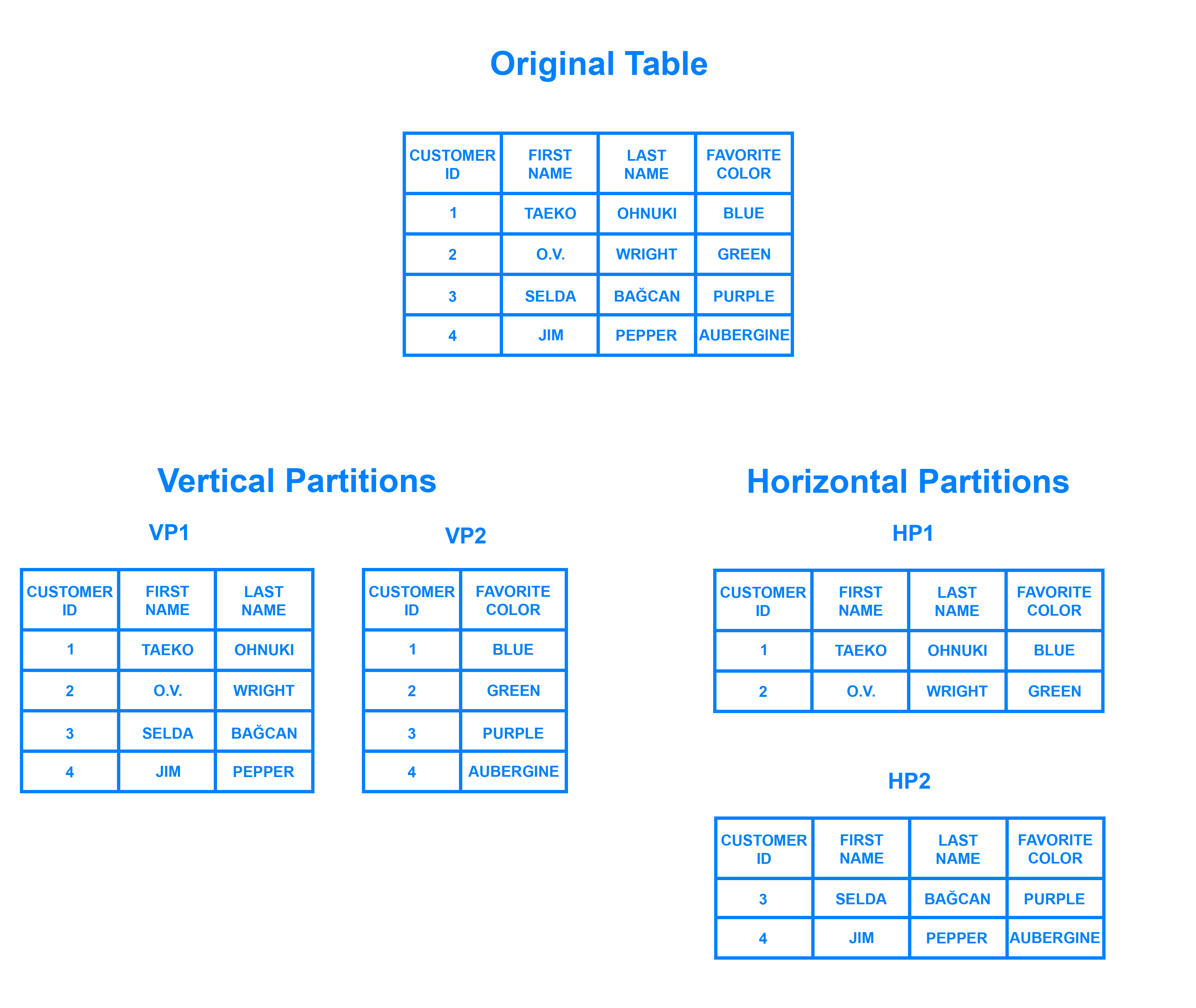
Just think as dividing the table into pieces.
Vertical Partitioning
- Literally dividing the table into two pieces vertically.
--> ex) Divided table 1 contains name, main, and password. Divided table 2 contains money and bankaccount.
Horizontal Partitioning
- Literally dividing horizontally.
--> ex) Divided table 1 contains 1 to 100 people's data. Divided table 2 contains 101 to 200 people's data.
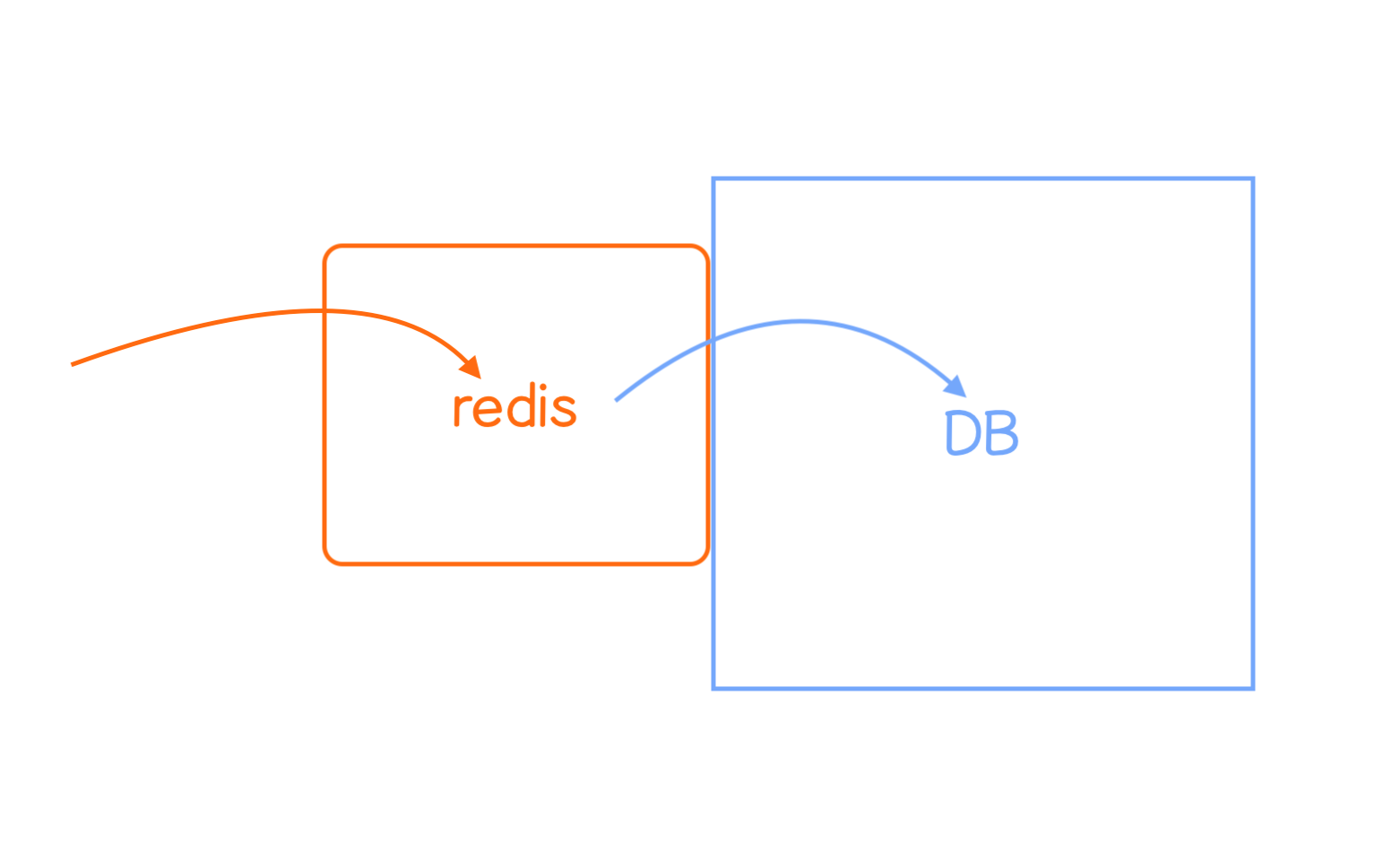
//DB를 긁는다 = 디스크에서 DB로부터 데이터를 꺼내온다
- But this takes too long so 🧩 redis is used.
- Redis is put before data base and it gets the data faster than data base. (memory)
✨ [JWT]
- When Josh logs in, a token is created === id is created.
--> id = token - Then that token is re-given to Josh in a form of state or cookie.
--> So when requesting for createPayment API, token is given at the same time.
--> Telling that "A person called Josh is trying to do a payment!"
- Token is saved in Data base and used with data base.
- Anyway it needs to be saved in data base and get the saved data, so redis is like pre-saving one.
--> Using JWT token here.<JSON Web Token>
✨ [Encryption]
✨ [Saving the Password]
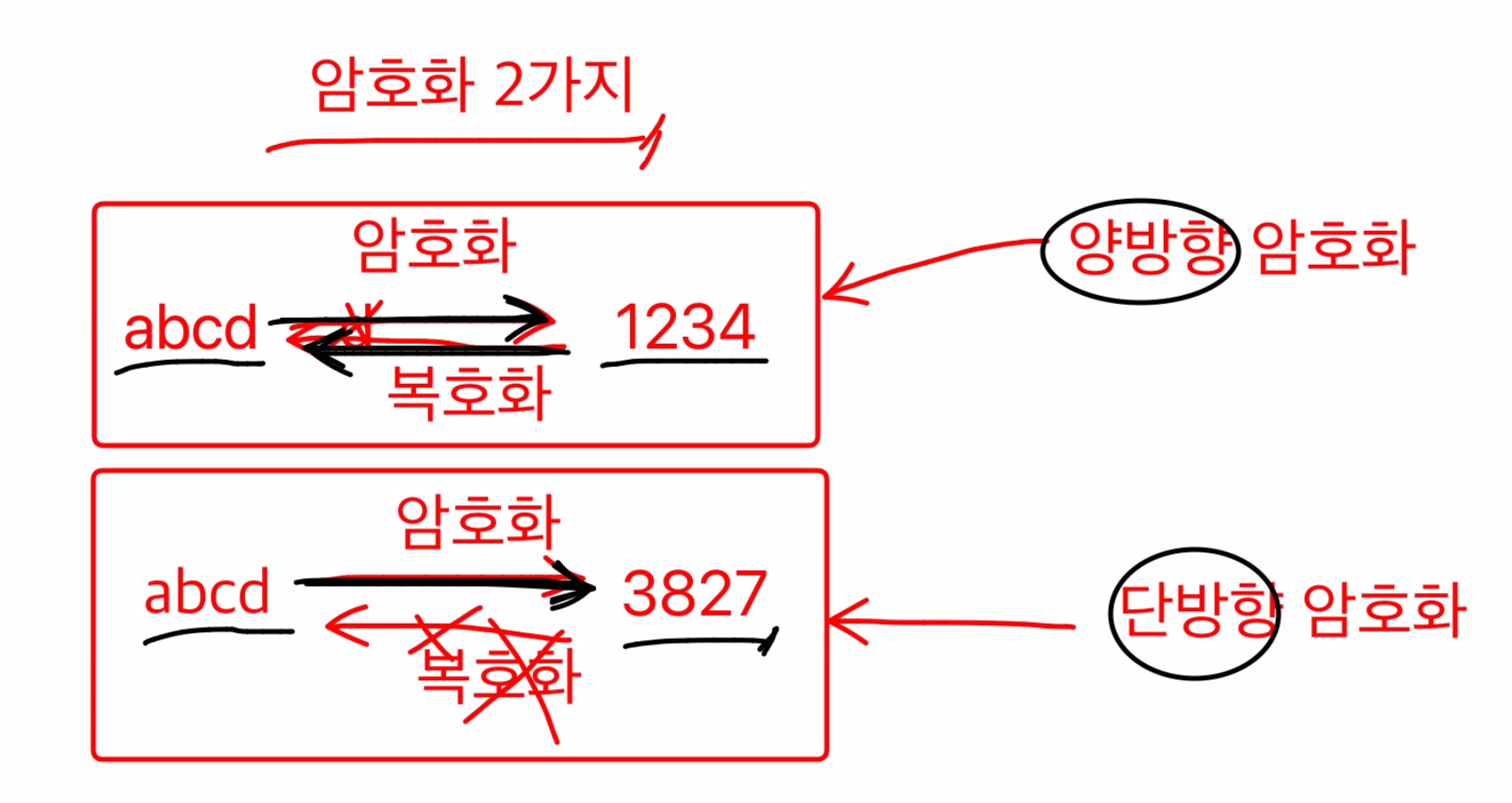
2 Ways to encode =>
1. Bidirectional Encryption
abcd -> 1234
- Able to encode and decode.
2. One Way Encryption
273719 -> 7 7 9
- Unable to know how 7 7 9 came out
- Actually, it is division by 10 and it's remainder.
27 % 10 = 7, 37 % 10 = 7, 19 % 10 = 9
-->7 7 9
✨ [Authentication/ Authorization]
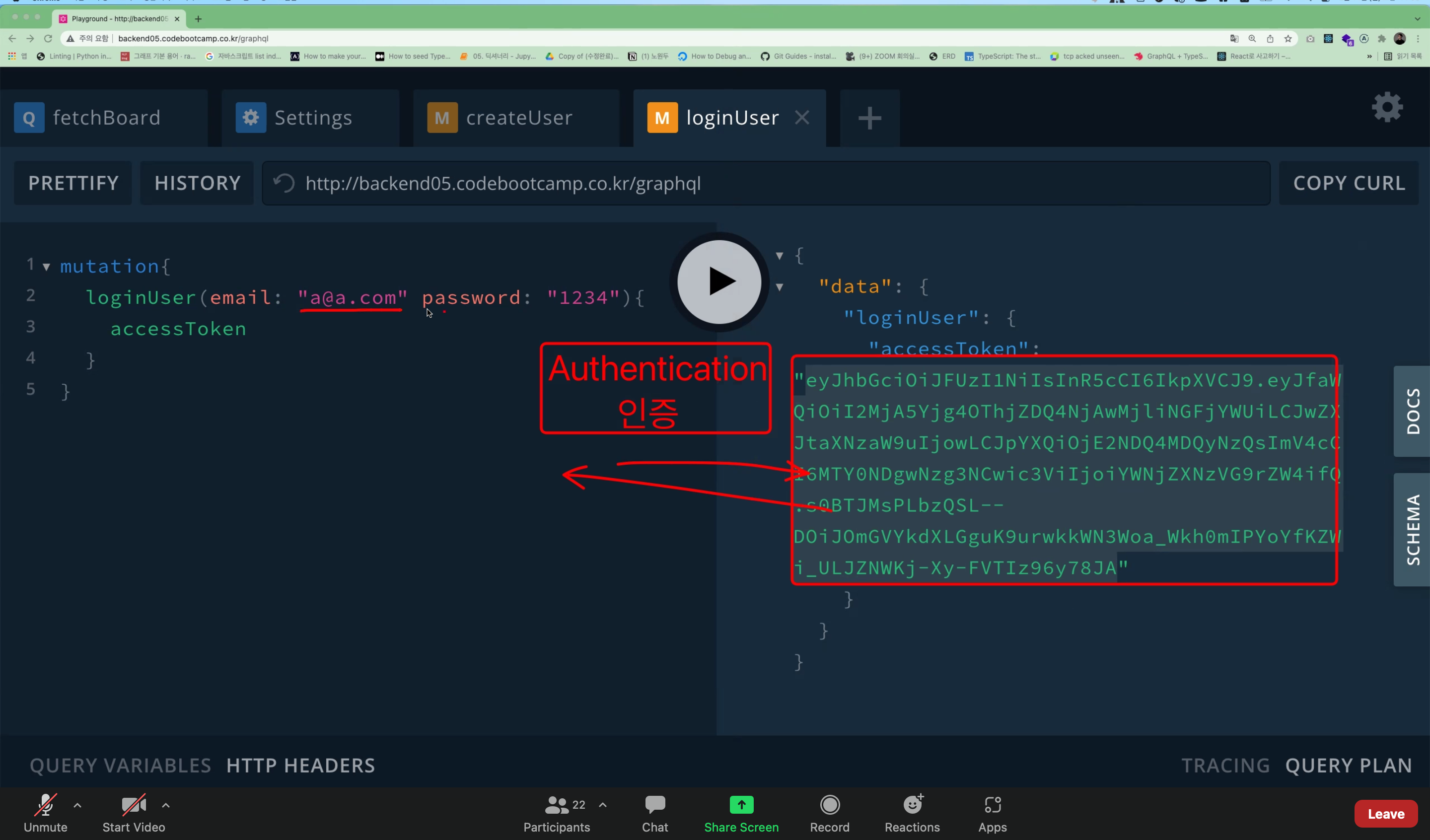
- Authentication (인증): Using accessToken to get the loginUser data.
--> Just the process of getting the token. - Authorization (인가): Giving the permission to access to the browser.
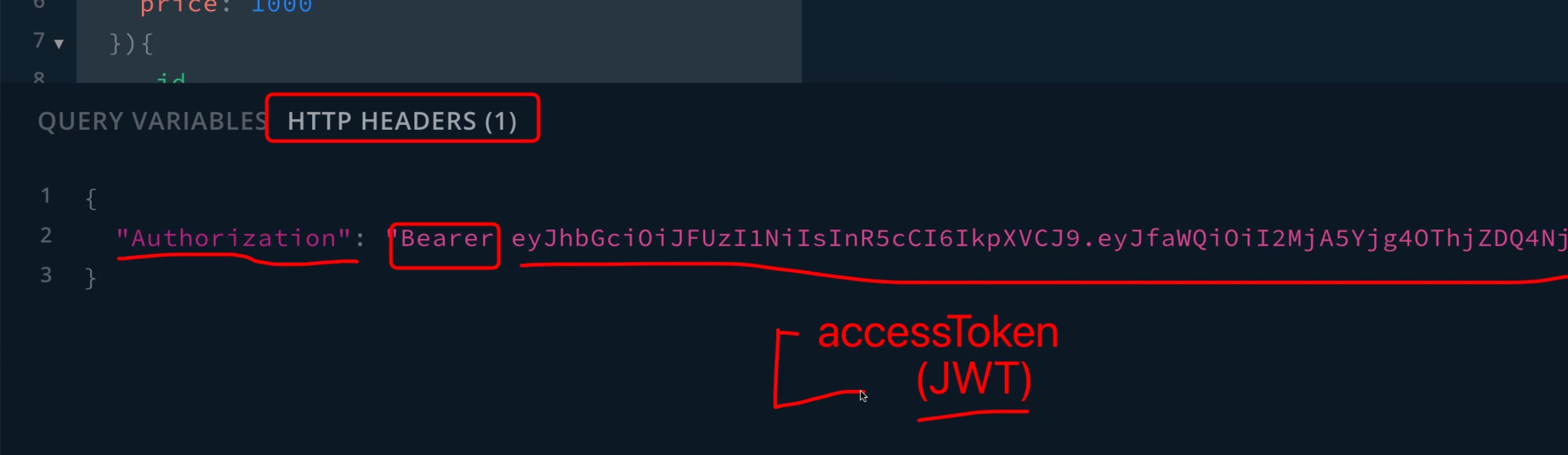
- Typing the accessToken in the header so that the computer can know who is paying or who is creating the board or else.
- Through http, the data is delivered between two computers. Here at this point, it is able to save token in header.
- No token, no response is possible to request.
