자료의 집합
리스트는 여러 개 값을 집합적으로 저장.
요소.
- 리스트에 소속되는 각각의 값
- 리스트에는 주로 같은 타입 요소를 모음.
score = [88, 95, 70, 100, 99]
name = ['최상미', '이한승', '김기남']score = [88, 95, 70, 100, 99]
sum = 0
for s in score:
sum += s
print('총점 : ', sum)
print('평균 : ', sum /len(score))
리스트의 요소.
- 개별요소 읽기 : 대괄호 안에 읽고자 하는 요소의 순서값 적음.
**score = [88, 95, 70, 100, 99]
print(socre[0])
print(socre[2])
print(score[-1])**
- 요소 분리 : 범위 지정.
nums = [0,1,2,3,4,5,6,7,8,9]
print(nums[2:5])
print(nums[:4])
print(nums[6:])
print([1:7:2])
score = [88,95,70, 100, 99]
print(score[2])
score[2] = 55
print(score[2])
nums = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
nums[2:5] = [20, 30, 40]
print(nums)
nums[6:8] = [90, 91, 92, 93, 94]
print(nums)
이중 리스트.
- 리스트의 요소로 리스트 넣어 중첩할 수 있음.
lol = [[1,2,3],[4,5],[6,7,8,9]]
print(lol[0])
print(lol[2][1])
for sub in lol:
for item in sub:
print(item, end = '')
print()
리스트 컴프리헨션.
- [수식 for 변수 in 리스트 if 조건]
nums = [n * 2 for n in range(1, 11)]
for i in nums:
print(i, end = ',')
삽입.
- append : 인수로 전달한 요소를 리스트 끝에 추가.
- insert : 삽입할 위치와 요소값을 전달 받아 리스트 주간에 삽입.
nums = [1,2,3,4]
nums.append(5)
nums.insert(2, 99)
print(nums)
리스트 관리.
- 범위에 리스트 대입하여 여러 요소 한꺼번에 삽입 가능.
nums = [1,2,3,4]
nums[2:2] = [90, 91, 92]
print(nums)
nums = [1,2,3,4]
nums[2] = [90, 91, 92]
print(nums)
삭제.
- 대상 선택 방법에 따라 다른 메서드 사용.
score = [88, 95, 70, 100, 99, 80, 78, 50]
score.remove(100)
print(score)
del(score[2])
print(score)
score[1:4] = []
print(score)
- remove : 인수로 전달받은 요소값 찾아 삭제.
- del : 순서값 지정하여 삭제.
- clear : 리스트 모든 요소 삭제.
- 빈 리스트 대입 : 일정 범위 요소 다수 삭제.
검색.
- index : 특정 요소 위치 찾음.
- count : 특정 요소값의 개수 조사.
score = [88, 95, 70, 100, 99, 80, 78, 50]
perfect = score.index(100)
print('만점 받은 학생은 '+str(perfect)+'번입니다.')
pernum = score.count(100)
print('만점자 수는' + str(pernum) + '명입니다.')
- min / max : 리스트 요소 중 최소값 / 최댓값 찾음.
- in / not in : 특정 요소 유무 여부 검사.
정렬.
- 요소를 크기순으로 재배열.
- sort : 리스트 정렬하며 요소 순서 조정. 리스트 자체 수정.
- reverse : 요소 순서 반대로.
score = [88, 95, 70, 100, 99]
score.sort()
print(score)
score.reverse()
print(score)
- sorted : 리스트 그대로 두고 정렬된 새로운 리스트 만들어 리턴.
리스트 연습.
import random
alpha = 'abcdefghij'
score = []
for i in range(10):
one = [random.randint(50, 100), random.randint(50, 100), random.randint(50, 100)]
score.append(one)
sums = []
for x in score:
sums.append(sum(x))
ziplist = list(zip(alpha, score, sums))
ziplist.sort()
for x in ziplist:
print(x)data = [1,3,11, 15, 23, 28, 37, 52, 82, 100]
result = [i for i in data if not(i & 1)]
print(result)
2.
def fibo(x):
if x == 1 or x == 2:
return 1
return fibo(x - 1) + fibo (x-2)
result = [fibo(i) for i in range(1, 11)]
print(result)
3.
data_list = [i*i for i in range(1, 21) if i%3 or i % 5]
print(data_list)
튜플.
불변 자료 집합.
- 튜플은 초기화한 후 편집 할 수 없다는 점에서 리스트와 차이.
- 소괄호 사용하여 정의.
score = (88, 95, 70, 100, 99)
sum = 0
for s in score:
sum += s
print('총점 : ', sum)
print('평균 : ', sum / len(score))
- print : 튜플 출력 시 소괄호 함꼐 출력하여 리스트 아님을 나타냄.
- 정의 할 때에는 소괄호 없이 값만 나열해도 무관함.
- 요소 하나밖에 없는 경우에는 값 다음에 콤마 찍어 튜플임을 표시.
튜플로 가능한 일.
- / * 연산자 사용하여 연결 및 반복.
tu = 1,2,3,4,5
print(tu[3])
print(tu[1:4])
print(tu + (6, 7))
print(tu * 2)
tu[1] = 100
del tu[1]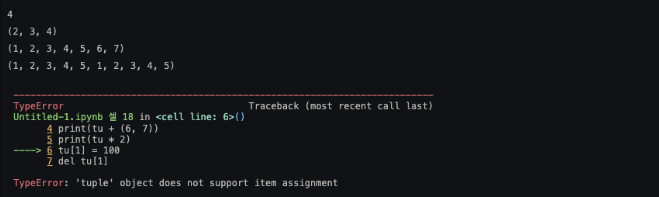
- 여러 개의 변수에 값을 한꺼번에 대입.
- 좌변에 변수 목록, 우변에 튜플을 대입.
tu = '이순신','김유신','강감찬'
lee, kim, kang = tu
print(lee)
print(kim)
print(kang)
- 두 개 이상 값을 반환.
- 내부에 요소 포함하는 튜플 사용.
import time
def gettime():
now = time.localtime()
return now.tm_hour, now.tm_min
result = gettime()
print('지금은 %d시 %d분입니다.' % (result[0], result[1]))
- import : 모듈 기능 사용 명령.
- divmod : 나눗셈의 몫과 나머지를 튜플로 묶어 리턴.
패킹.
여러 타입의 데이터를 하나의 튜플이나 리스트로 묶어 선언.
언패킹.
튜플이나 리스트의 요소들을 여러 개의 변수에 나누어 대입.
딕셔너리.
사전.
- 키와 값의 쌍을 저장하는 대용량 자료구조.
- 맵 / 연관배열
- 중괄호 안에 키 : 값 형태로 콤마로 구분하여 나열.
dic = {'boy' : '소년', 'school' : '학교', 'book':'책'}
print(dic)
dic = {'boy' : '소년', 'school' : '학교', 'book':'책'}
print(dic['boy'])
print(dic['book'])
- 찾는 키가 없을 경우 예외 발생.
- 예외 처리 구문.
- get 메소드.
dic = {'boy' : '소년', 'school' : '학교', 'book':'책'}
print(dic.get('student'))
print(dic.get('student','사전에 없는 단어입니다.'))
- 특정 키 검색 시에는 in 구문 사용.
- 순서가 없기 때문에 인덱스, 슬라이싱 사용불가.
- in, not in 을 사용하여 키가 있는지 확인 가능.
- 값을 확인하기 위해서는 values 함수와 in을 함께 사용.
사전관리.
- 실행 중 삽입, 삭제, 수정 등 편집 가능.

del
- 해당 키를 찾아 값과 함께 삭제.
keys / values.
- 사전의 키 / 값 목록 얻음.
dict_*객체.
- 리스트처럼 순회하여 값 순서대로 읽음.
update.
- 두 개 사전을 병합.
dict 함수.
- 빈 사전 만들거나 다른 자료형을 사전으로 변환.
⇒ get(키, 디폴트값) - 키의 값 리턴. 없으면 디폴트값 리턴 (디폴트값이 없으면 무시)
- d[키] 방식은 데이터가 없으면 오류를 발생시킨다.
⇒ pop(키)-특정키의값을 리턴하고 삭제 (키값이없으면오류)
- popitem() - 임의의 데이터(키와 값)을 리턴하고 삭제 (데이터가 없으면 오류)
- clear() - 사전 모든 요소(데이터)를 삭제
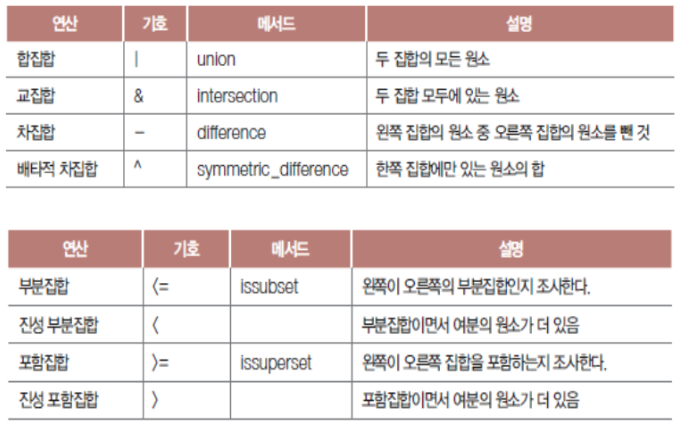
집합.
- 여러 가지 값의 모임.
aisa = {'korea','china','japan','korea'}
print(aisa)
- 순서가 없고, 집합 안에서는 unique 한 값을 갖는 mutable 객체. 중괄호를 사용하는 것은 dictionary와 비슷하지만, key가 없음.
set() - 빈 집합 만들거나 다른 컬렉션을 집합형으로 변환.
⇒ 인수 없이 set() 함수 호출.
- 공집합 만들기.
⇒ add 메소드.
- 집합에 원소 추가.
⇒ update 메소드.
- 집합끼리 결합하여 합집합 만들기.
- 중복 허용되지 않음에 유의
집합 연산.

Data Science. DevOps.