외부모듈.
- 외부 모듈, pip install, 제어 역전, 라이브러리, 프레임워크
- 외부 모듈 : 파이썬이 기본적으로 제공하는 것이 아닌 다른 사람들이 만들어 배포하는 모듈.
- 외부 모듈 중 Beautiful Soup와 Requests를 설치한 후 활용하는 방법.
모듈 설치.
pip install 모듈 이름⇒ 위의 코드를 이용해 외부 모듈을 설치.
Beautiful Soup 모듈.
- 웹 페이지 분석 모듈.
- BeautifulSoup을 이용하여 파이썬에서 HTML 문서를 DOM구조로 쉽게 해석할 수 있음.
Python urllib의 사용.
→ urllib는 파이썬에서 웹과 관련된 데이터를 손쉽게 이용하도록 도와주는 라이브러리. urllib라이브러리는 내부에 총 4개의 모듈이 존재하며 그 중에서 하나는 웹을 열어서 데이터를 읽어오는 역할을 하는 request 모듈.
- 웹 문서 불러오기.
import urllib.request
req = urllib.request
req.urlopen("https://www.naver.com")
⇒ urlopen 함수의 인자는 데이터를 얻고 싶은 웹 페이지의 주소를 주면 됨. urlopen 함수는 웹에서 얻은 데이터에 대한 객체를 반환해줌.
python urllib의 사용.
d = req.urlopen("https://www.naver.com")
status = d.getheaders()
for i in status:
print(i)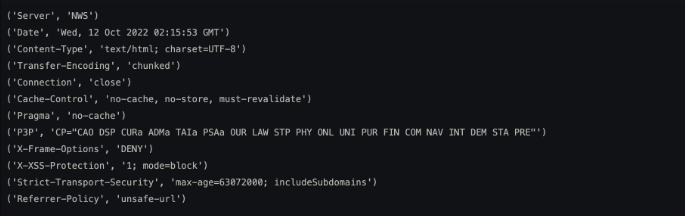
import urllib.request, urllib.parse, urllib.error
fhand = urllib.request.urlopen('http://data/pr4e.org/romeo.txt')
counts = dict()
for line in fhand:
words = line.decode().split()
for word in words:
counts[word] = counts.get(word, 0) + 1
print(counts)구글 검색으로 “python prime module”이라고 치면 파이썬에서 소수 (prime number)를 구하는 모듈을 찾아보세요. prime, primenumbers, pyprimes, pyprimesieve 등 다양한 모듈이 나올 것입니다. 적당한 모듈을 선택해서 100~1000 사이에 있는 소수가 몇 개인지 구해 보세요.
- primePy 모듈 함수를 사용.
from primePy import primes
primes_to_100 = primes.upto(100) # 100까지 소수를 리스트로 돌려줌.
primes_to_1000 = primes.upto(1000) # 1000까지 소수를 리스트로 돌려줌.
primes_to_100_1000 = len(primes_to_1000) - len(primes_to_100)
print(primes_to_100_1000,'개 입니다.')
주제에 대한 자신만의 예제를 만들어 코딩.
→ 2장까지는 엑셀, 텍스트 파일의 형태.
→ 웹에서 데이터를 가지고 온다. (html, css)
→ beautiful soap 모듈 함수를 익힘.
from bs4 import BeautifulSoupimport os
os.chdir('/Users/cho.h.j/Desktop/data') # 디렉토리 변경.(원할 경우.)
page = open('03. test_first.html','r').read() # open 명령으로 html 파일을 읽어 옴. 'r'은 read라는 뜻.
soup = BeautifulSoup(page, 'html.parser') # html 코드를 soup라는 변수에 저장.
print(soup.prettify()) # prettify는 html페이지의 내용을 들여쓰기하여 본다는 옵션.list(soup.children) # soup라는 변수에서 한단계 아래에서 포함된 태그들을 알고 싶으면 children이라는 속성 사용.기초 배우기.
<html 구조 살펴보기>
<html>
<head>
<title> 페이지 제목 </title>
</head>
<body>
<h1> 글 제목 </h1>
<p> 글 본문 </p>
</body>
</HTML>웹 크롤링 준비.
웹 사이트 특정 문장(명언.) 수집하기.
→ Quotes to scrape 라는 사이트 (명언을 모아둔 사이트.)
위의 명언을 모으기 위해서 어떻게 해야할까?
위와 같이, tag를 눌러보자.
→ about이라는 곳이 있다. 해당 말을 한 사람의 정보를 볼 수 있다.
웹 스크래핑을 하기 위한 순서도.
- ‘Quatos to scrape’ 페이지를 불러와서 객체에 저장.
- 브라우저에서 명언이 있는 위치를 확인.
- 각 태그에 맞는 명언을 찾아서 출력.
Beautiful soap 설치.
from bs4 import BeautifulSoup사용할 모듈 함수 import.
import os # os 운영체제 모듈.
import re # 정규식 모듈. import requests # url 주소에 있는 내용을 요청할 때 사용하는 모듈.import urllib.request as urfrom bs4 import BeautifulSoup as bsurl = 'http://quotes.toscrape.com/'ur.urlopen(url)html = ur.urlopen(url)htmlhtml.read()[:100]
# html 에서 엄청나게 많은 정보가 있어서 다 보기에 힘들기 때문에, 100개 까지만 슬라이싱 해서 추출하여 정보를 읽음.Beautiful soap로 자료형 변환.
→ beautiful soap를 활용하여 html 객체에 저장한 자료를 정보를 쉽게 추출할 수 있는 형태, 파싱하여 쉬운 형태로 변환.
- 파싱은, 웹 문서에서 원하는 패턴이나 순서로 자료를 추출해 가공하는 것.
html = ur.urlopen(url)
soup = bs(html.read(), 'html.parser')
soup자료형 비교.
type(html)
type(soup)
→ soup 자료형이 bs4.beautifulsoap로 만들어진 것을 확인 할 수 있다.
한줄로 위와 같은 내용을 만들기.
soup = bs(ur.urlopen(url).read(), 'html.parser')특정 태그에서 텍스트 추출.
→ 현재 페이지에 있는 텍스트만 아주 간단하게 모을 수 있는 작업.
html 구조 다시 한번 보기.
soup<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8"/>
<title>Quotes to Scrape</title>
<link href="/static/bootstrap.min.css" rel="stylesheet"/>
<link href="/static/main.css" rel="stylesheet"/>
</head>
<body>
<div class="container">
<div class="row header-box">
<div class="col-md-8">
<h1>
<a href="/" style="text-decoration: none">Quotes to Scrape</a>
</h1>
</div>
<div class="col-md-4">
<p>
<a href="/login">Login</a>
</p>
</div>
</div>
<div class="row">
<div class="col-md-8">
<div class="quote" itemscope="" itemtype="[http://schema.org/CreativeWork](http://schema.org/CreativeWork)">
<span class="text" itemprop="text">“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”</span>
<span>by <small class="author" itemprop="author">Albert Einstein</small>
<a href="/author/Albert-Einstein">(about)</a>
</span>
<div class="tags">
Tags:
<meta class="keywords" content="change,deep-thoughts,thinking,world" itemprop="keywords"/>
<a class="tag" href="/tag/change/page/1/">change</a>
<a class="tag" href="/tag/deep-thoughts/page/1/">deep-thoughts</a>
<a class="tag" href="/tag/thinking/page/1/">thinking</a>
<a class="tag" href="/tag/world/page/1/">world</a>
</div>
</div>
<div class="quote" itemscope="" itemtype="[http://schema.org/CreativeWork](http://schema.org/CreativeWork)">
<span class="text" itemprop="text">“It is our choices, Harry, that show what we truly are, far more than our abilities.”</span>
<span>by <small class="author" itemprop="author">J.K. Rowling</small>
<a href="/author/J-K-Rowling">(about)</a>
</span>
<div class="tags">
Tags:
<meta class="keywords" content="abilities,choices" itemprop="keywords"/>
<a class="tag" href="/tag/abilities/page/1/">abilities</a>
<a class="tag" href="/tag/choices/page/1/">choices</a>
</div>
</div>
<div class="quote" itemscope="" itemtype="[http://schema.org/CreativeWork](http://schema.org/CreativeWork)">
<span class="text" itemprop="text">“There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.”</span>
<span>by <small class="author" itemprop="author">Albert Einstein</small>
<a href="/author/Albert-Einstein">(about)</a>
</span>
<div class="tags">
Tags:
<meta class="keywords" content="inspirational,life,live,miracle,miracles" itemprop="keywords"/>
<a class="tag" href="/tag/inspirational/page/1/">inspirational</a>
<a class="tag" href="/tag/life/page/1/">life</a>
<a class="tag" href="/tag/live/page/1/">live</a>
<a class="tag" href="/tag/miracle/page/1/">miracle</a>
<a class="tag" href="/tag/miracles/page/1/">miracles</a>
</div>
</div>
<div class="quote" itemscope="" itemtype="[http://schema.org/CreativeWork](http://schema.org/CreativeWork)">
<span class="text" itemprop="text">“The person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.”</span>
<span>by <small class="author" itemprop="author">Jane Austen</small>
<a href="/author/Jane-Austen">(about)</a>
</span>
<div class="tags">
Tags:
<meta class="keywords" content="aliteracy,books,classic,humor" itemprop="keywords"/>
<a class="tag" href="/tag/aliteracy/page/1/">aliteracy</a>
<a class="tag" href="/tag/books/page/1/">books</a>
<a class="tag" href="/tag/classic/page/1/">classic</a>
<a class="tag" href="/tag/humor/page/1/">humor</a>
</div>
</div>
<div class="quote" itemscope="" itemtype="[http://schema.org/CreativeWork](http://schema.org/CreativeWork)">
<span class="text" itemprop="text">“Imperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.”</span>
<span>by <small class="author" itemprop="author">Marilyn Monroe</small>
<a href="/author/Marilyn-Monroe">(about)</a>
</span>
<div class="tags">
Tags:
<meta class="keywords" content="be-yourself,inspirational" itemprop="keywords"/>
<a class="tag" href="/tag/be-yourself/page/1/">be-yourself</a>
<a class="tag" href="/tag/inspirational/page/1/">inspirational</a>
</div>
</div>
<div class="quote" itemscope="" itemtype="[http://schema.org/CreativeWork](http://schema.org/CreativeWork)">
<span class="text" itemprop="text">“Try not to become a man of success. Rather become a man of value.”</span>
<span>by <small class="author" itemprop="author">Albert Einstein</small>
<a href="/author/Albert-Einstein">(about)</a>
</span>
<div class="tags">
Tags:
<meta class="keywords" content="adulthood,success,value" itemprop="keywords"/>
<a class="tag" href="/tag/adulthood/page/1/">adulthood</a>
<a class="tag" href="/tag/success/page/1/">success</a>
<a class="tag" href="/tag/value/page/1/">value</a>
</div>
</div>
<div class="quote" itemscope="" itemtype="[http://schema.org/CreativeWork](http://schema.org/CreativeWork)">
<span class="text" itemprop="text">“It is better to be hated for what you are than to be loved for what you are not.”</span>
<span>by <small class="author" itemprop="author">André Gide</small>
<a href="/author/Andre-Gide">(about)</a>
</span>
<div class="tags">
Tags:
<meta class="keywords" content="life,love" itemprop="keywords"/>
<a class="tag" href="/tag/life/page/1/">life</a>
<a class="tag" href="/tag/love/page/1/">love</a>
</div>
</div>
<div class="quote" itemscope="" itemtype="[http://schema.org/CreativeWork](http://schema.org/CreativeWork)">
<span class="text" itemprop="text">“I have not failed. I've just found 10,000 ways that won't work.”</span>
<span>by <small class="author" itemprop="author">Thomas A. Edison</small>
<a href="/author/Thomas-A-Edison">(about)</a>
</span>
<div class="tags">
Tags:
<meta class="keywords" content="edison,failure,inspirational,paraphrased" itemprop="keywords"/>
<a class="tag" href="/tag/edison/page/1/">edison</a>
<a class="tag" href="/tag/failure/page/1/">failure</a>
<a class="tag" href="/tag/inspirational/page/1/">inspirational</a>
<a class="tag" href="/tag/paraphrased/page/1/">paraphrased</a>
</div>
</div>
<div class="quote" itemscope="" itemtype="[http://schema.org/CreativeWork](http://schema.org/CreativeWork)">
<span class="text" itemprop="text">“A woman is like a tea bag; you never know how strong it is until it's in hot water.”</span>
<span>by <small class="author" itemprop="author">Eleanor Roosevelt</small>
<a href="/author/Eleanor-Roosevelt">(about)</a>
</span>
<div class="tags">
Tags:
<meta class="keywords" content="misattributed-eleanor-roosevelt" itemprop="keywords"/>
<a class="tag" href="/tag/misattributed-eleanor-roosevelt/page/1/">misattributed-eleanor-roosevelt</a>
</div>
</div>
<div class="quote" itemscope="" itemtype="[http://schema.org/CreativeWork](http://schema.org/CreativeWork)">
<span class="text" itemprop="text">“A day without sunshine is like, you know, night.”</span>
<span>by <small class="author" itemprop="author">Steve Martin</small>
<a href="/author/Steve-Martin">(about)</a>
</span>
<div class="tags">
Tags:
<meta class="keywords" content="humor,obvious,simile" itemprop="keywords"/>
<a class="tag" href="/tag/humor/page/1/">humor</a>
<a class="tag" href="/tag/obvious/page/1/">obvious</a>
<a class="tag" href="/tag/simile/page/1/">simile</a>
</div>
</div>
<nav>
<ul class="pager">
<li class="next">
<a href="/page/2/">Next <span aria-hidden="true">→</span></a>
</li>
</ul>
</nav>
</div>
<div class="col-md-4 tags-box">
<h2>Top Ten tags</h2>
<span class="tag-item">
<a class="tag" href="/tag/love/" style="font-size: 28px">love</a>
</span>
<span class="tag-item">
<a class="tag" href="/tag/inspirational/" style="font-size: 26px">inspirational</a>
</span>
<span class="tag-item">
<a class="tag" href="/tag/life/" style="font-size: 26px">life</a>
</span>
<span class="tag-item">
<a class="tag" href="/tag/humor/" style="font-size: 24px">humor</a>
</span>
<span class="tag-item">
<a class="tag" href="/tag/books/" style="font-size: 22px">books</a>
</span>
<span class="tag-item">
<a class="tag" href="/tag/reading/" style="font-size: 14px">reading</a>
</span>
<span class="tag-item">
<a class="tag" href="/tag/friendship/" style="font-size: 10px">friendship</a>
</span>
<span class="tag-item">
<a class="tag" href="/tag/friends/" style="font-size: 8px">friends</a>
</span>
<span class="tag-item">
<a class="tag" href="/tag/truth/" style="font-size: 8px">truth</a>
</span>
<span class="tag-item">
<a class="tag" href="/tag/simile/" style="font-size: 6px">simile</a>
</span>
</div>
</div>
</div>
<footer class="footer">
<div class="container">
<p class="text-muted">
Quotes by: <a href="[https://www.goodreads.com/quotes](https://www.goodreads.com/quotes)">GoodReads.com</a>
</p>
<p class="copyright">
Made with <span class="sh-red">❤</span> by <a href="[https://scrapinghub.com](https://scrapinghub.com/)">Scrapinghub</a>
</p>
</div>
</footer>
</body>
</html>soup.find_all(찾아낼 태그)→ find_all은 텍스트를 추출하는 것.
class 속성과 속성 값.
태그의 시작 태그를 보면 라고 작성되어 있음.
이때, class를 이 태그의 속성 이라하고, “text”는 속성값 이라고 합니다.
여기에서 속성이란 HTML 요소에 좀 더 구체적인 기능을 추가하기 위해 시작 태그 안에 지정하는 것을 말함.
즉, 태그는 class라는 속성을 가지고 있고, class = “text이므로 class 속성의 속성값은 “text” 임.
태그에서 텍스트만 출력하기.
quote = soup.find_all('span')
quote[0]quote[0].textfor i in quote:
i.text
print(i.text)웹 브라우저에서 특정 태그 찾아 명언 출력.
- 정보의 위치 확인하기.
→ 브라우저를 열어서 Quotes to scrape 웹사이트에 들어간 다음, ‘it is our choice’로 시작하는 명언 제목의 위치를 찾아보겠다.
- 콘솔 창에서 HTML 구조 파악.
→ 웹사이트에 접속한 다음, F12키를 누르면 개발자 도구 또는 콘솔 창이라고 부르는 창이 하나 나온다. 이 창에서 해당 웹 사이트의 HTML 구조를 바로 살펴볼 수 있다.
- 명언 일부를 입력해 위치 찾기.
→ Harry라는 단어를 이용해 콘솔 창에서 명언이 어떻게 입력되어 있는지 확인하기.
콘솔 창에서 Ctrl + F 키를 눌러 검색 창을 열고 harry라는 단어를 검색.
- 태그 안에 정의된 특정 클래스를 찾아가는 방법.
→ class 속성값이 quote인
soup.find_all('div', {"class" : "quote"})soup.find_all('div', {"class" : "quote"})[0]soup.find_all('div', {"class" : "quote"})[0].textprint(soup.find_all('div',{'class':'quote'})[0].text)반복문을 이용해 해당 페이지의 명언 추출.
for i in soup.find_all('div',{"class":'quote'}):
print(i.text)포털 사이트 머리기사 정보 모으기.
- 필요한 모듈 함수 import.
import os
import re
import urllib.request as ur
from bs4 import BeautifulSoup as bs- 파일을 저장할 워킹 디렉토리 변경.(선택.)
os.chdir('/Users/cho.h.j/Desktop/data')- 데이터를 모을 사이트를 변수에 저장.
news = 'https://news.daum.net/'- 위와 마찬가지로 BeautifulSoup를 이용해서 파싱 시킴.
soup = bs(ur.urlopen(news).read(),'html.parser')soup- div 부분의 class : item_issue 부분만 추출.
soup.find_all('div', {"class" : "item_issue"})for i in soup.find_all('div', {"class" : "item_issue"}):
print(i.text)→ 뽑아온 데이터를 통해 제목만 따로 추출하기.
하이퍼링크 주소 추출하기.
지금까지 find_all ,
그만큼 중요한 태그가 바로 <a> 이다. HTML에서 <a> 태그는 하이퍼링크를 만들 때 사용하는 태그.
<a> 태그 사용법 알아보기.
<a href = "링크할 URL 주소"> 하이퍼링크 텍스트 </a>예를 들어, ‘하이퍼링크 텍스트로 ‘네이버 바로가기' 라고 입력하고 HTML을 짰다면, ‘네이버 바로가기’ 클릭하면 하이퍼링크로 지정한 주소의 웹 문서(www.naver.com)로 연결.
<HTML>
<body>
<A href = "http://www.naver.com"> 네이버 바로가기 </A>
</body>
</HTML><a> 태그 사용법을 알아둬야 하는 이유는 링크된 URL, 즉 <a> 태그로 묶인 내용 중에서도 href 속성값을 얻어내는 방법 알기 위해.
soup.find_all('a')→ find_all을 이용하여 <a> 태그만 추출.
soup.find_all('a')[:5]→ 출력된 <a> 태그 중 href = htp://entertain.daum.net이고 ‘연예'라는 문자열이 들어 있는 <a> 태그.
즉, 브라우저에서 <연예>를 누르면 https://entertain.daum.net로 이동하도록 하이퍼링크가 설계되어 있다.
href 속성값 추출.
<a> 태그에서 하이퍼링크의 주솟값이 저장된 href 속성값을 가져오면 됩니다. 어떤 태그를 저장한 객체 a가 있을 때 그안의 특정한 속성값을 찾아내려면 get을 사용.
a.get('속성')- for문을 이용해서 추출해보자.
for i in soup.find_all('a')[:5]:
i.get('href')원하는 영역에서 하이퍼링크 모두 추출.
- 머리 기사가 위치한
<div>태그로 가서 href 속성값만 추출하는 코드를 작성.
href 속성값만 추출하는 이유는 추출된 주소로 자동으로 다시 접속하기 위해.
news = 'https://news.daum.net/'
soup = bs(ur.urlopen(news).read(), 'html.parser')find_all로 <a> 태그 추출.
for i in soup.find_all('div', {"class" : "item_issue"}):
i.find_all('a')get으로 href 속성값 구하기.
for i in soup.find_all('div', {"class" : "item_issue"}):
i.find_all('a')[0]- 주의 : BeautifulSoup로 만든 객체가 아니라면 get함수가 작동하지 않음.
for i in soup.find_all('div', {"class" : "item_issue"}):
i.find_all('a')[0].get('href')chapter 3.
파일을 이용해서 연습.
import os
os.chdir('/Users/cho.h.j/Desktop/data')from bs4 import BeautifulSouppage = open("test_first.html",'r').read()
soup = BeautifulSoup(page, 'html.parser') # 파싱을 시키는 것.
print(soup.prettify()) # prettify() 들여쓰기가 되어지는 것.list(soup.children) # soup 라는 변수에서 한단계 아래에서 포함된 태그.원하는 태그 찾기.
→ 크롬 개발자 도구를 이용해서 해당되는 태그를 찾아봄.
from urllib.request import urlopenurl = "http://finance.naver.com/marketindex/"
page = urlopen(url)
soup = BeautifulSoup(page, "html.parser")
print(soup.prettify())soup.find_all('span', 'value')[0].string셀프 주유소는 정말 저렴?
셀프 주유소 사이트 오피넷에 가면 beautifulsoup로는 정보를 가져올 수 없는 정보들이 있다.
그래서, Selenium 사용한다.
selenium은 아나콘다의 모듈이 아니기 때문에 별도로 설치해야 함.
!pip install seleniumfrom selenium import webdriverdriver = webdriver.Chrome('../data/chromedriver')→ google에서 chromedriver 버전에 맞게 설치.
그 다음, 운영체제의 맞게 ..(오류가 나면)
xattr -d com.apple.quarantine /Users/cho.h.j/Desktop/data/chromedriver
#mac driver.save_screenshot('../desktop/001.jpg')서울시 구별 주유소 가격 정보 얻기.
from selenium import webdriver
from selenium.webdriver.common.by import By
# from selenium.webdriver.support import expected_conditions as EC
# from selenium.webdriver.support.ui import WebDriverWait as waitdriver = webdriver.Chrome('../Users/cho.h.j/Desktop/data/chromedriver')driver.get('https://www.opinet.co.kr/searRgSelect.do')xpath1 = '//*[@id="SIGUNGU_NM0"]'
gu_list_raw = driver.find_element(By.XPATH,xpath1)
print(gu_list_raw)gu_list = gu_list_raw.find_elements(By.TAG_NAME,'option')gu_names = [option.get_attribute("value") for option in gu_list]gu_names.remove('')gu_nameselement = driver.find_element(By.ID,"SIGUNGU_NM0")
element.send_keys(gu_names[0])→ 구 이름이 있는 태그에 저장한 gu_names에서 첫 번째 것을 입력.
element_sel_gu = driver.find_element(By.XPATH,'//*[@id="searRgSelect"]').click()→ 조회버튼의 관련한 xpath.
element_get_excel = driver.find_element(By.XPATH,'//*[@id="glopopd_excel"]').click()→ excel 저장 버튼 관련한 xpath.
import time
from tqdm import tqdm_notebook
for gu in tqdm_notebook(gu_names):
element = driver.find_element(By.ID, "SIGUNGU_NM0")
element.send_keys(gu)
time.sleep(2)
xpath1 = '//*[@id="searRgSelect"]'
element_sel_gu = driver.find_element(By.XPATH,xpath1).click()
time.sleep(1)
xpath2 = '//*[@id="glopopd_excel"]'
element_get_excel = driver.find_element(By.XPATH,xpath2).click()
time.sleep(1)→ 반복문을 통해서 서울시의 구별로 주유소의 데이터를 모음.
구별 주유 가격에 대한 데이터의 정리.
import pandas as pd
from glob import glob→ glob 이란, 파일 경로 등을 쉽게 접근 할 수 있게 해주는 모듈.
glob('../data/지역*.xls')station_files = glob('../data/지역*.xls')
station_filestmp_raw = []
for file_name in stations_files:
tmp = pd.read_excel(file_name,header = 2)
tmp_raw.append(tmp)
station_raw = pd.concat(tmp_raw)station_raw.info()→ info 함수로 station_raw의 정보를 확인.
station_raw.head()stations = pd.DataFrame({'Oil_store' : station_raw['상호'],
'주소' : station_raw['주소'],
'가격' : station_raw['휘발유'],
'셀프' : station_raw['셀프여부'],
'상표' : station_raw['상표']})
station.head()stations['구'] = [eachAddress.split()[1] for eachAddress in stations['주소']]
stations.head()→ 주소 컬럼의 주소를 봤을 때 빈칸을 기준으로 분리 시키고 두 번째 단어를 선택하면 구 이름이 될 것.
stations['구'].unique()stations[stations['구'] == '서울특별시'].
# 구 가 서울특별시에 해당하는 내용을 추출.stations.loc[stations['구'] == '서울특별시',' 구'] = '성동구'
stations['구'].unique()stations[stations['구'] == '특별시']stations.loc[stations['구']=='특별시', '구'] = '도봉구'
stations['구'].unique()stations[stations['가격']=='-']→ 주유소들에 대해 우리가 가격을 일일이 확인할 수는 없어서 가격 정보가 기입하지 않은 주유소 대상에서 제외.
stations = stations[stations['가격'] != '-']
stations.head()stations['가격'] = [float(value) for value in stations['가격']]
#stations.reset_index(inplace = True)
#del stations['index']stations.info()셀프 주유소는 정말 저렴한지 boxplot 확인.
→ 그래프에 한글을 넣기 위해 작성.
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
import platform
path = "c:/Windows/Fonts/malgun.ttf"
from matplotlib import font_manager, rc
if platform.system() == 'Darwin':
rc('font', famliy='AppleGothic')
elif platform.system() == 'Windows':
font_name = font_manager.FontProperties(fname=path).get_name()
rc('font', family=font_name)
else:
print('unknown..')#stations.boxplot(column='가격', by = '셀프', figsize = (12,8))→ boxplot 그리기.
plt.figure(fgsize = (12,8))
sns.boxplot(x = '상표', y = '가격', hue='셀프', data = stations, palette = "Set3")plt.figure(figsize = (12,8))
sns.boxplot(x="상표", y="가격", data = stations, palette='Set3')
sns.swarmplot(x='상표',y='가격',data = stations, color=".6")
plt.show()→ swarmplot 그려보면 좀 더 확실한 분포를 볼 수 있다.
import json
import folium
import googlemaps
import warnings
warnings.simplefilter(action = "ignore", category = FutureWarning)stations.sort_values(by='가격',ascendng = False).head(10)
stations.sort_values(by='가격',ascending = True).head(10)import numpy as np
gu_data = pd.pivot_table(stations, index = ['구'], value=['가격'],
aggfunc = np.mean)
gu_data.head()stations.sort_values(by='가격', ascending=False).head(10)
stations.sort_values(by='가격', ascending = True).head(10)import numpy as np
gu_data = pd.pivot_table(stations, index=['구'], value=['가격'],
aggfunc=np.mean)
gu_data.head()geo_path = 'skorea_municipalities_geo_simple.json'
geo_data = json.load(open(geo_path, encoding = 'utf-8')
map = folium.Map(location=[37.5502, 126.982], zoom_start = 10.5,
tiles = 'stamen Toner')
map.choropleth(geo_str = geo_str,
data = gu_data,
columns = [gu_data.index,'가격'],
fill_color = 'PuRd',
key_on='feature.id')
map