🎇 데이터 조회
✨ SQL 작성 형식
- SQL문 끝에는 항상 세미콜론을 써줘야 한다.
- SQL문 안에는 공백이나 개행 등을 자유롭게 넣을 수 있다.
- SQL문의 예약어는 대문자로 작성한다.
- 데이터를 조회할 때 데이터베이스 이름을 테이블과 같이 써 주는 것을 권고한다. 예) test.member
-> 다른 데이터베이스에도 같은 테이블명이 있을 가능성이 높으므로
✨ 조건 표현식
- (NOT) BETWEEN A AND B : A와 B 사이의 값
SELECT * FROM test.member WHERE age BETWEEN 15 AND 30;
// 나이가 15에서 30 사이인 member- !=, <> : 같지 않음
SELECT * FROM test.member WHERE gender != 'm';
SELECT * FROM test.member WHERE gender <> 'm';
// gender가 m이 아닌 member- IN : 이 중에 있는~(특정 값을 추출)
SELECT * FROM test.member WHERE age IN (20, 30);
// age가 20가 30인 member✨ 데이터(Date) 타입 관련 함수
- 연도, 월, 일 추출하기
YEAR(컬럼) : 연도 추출
MONTH(컬럼) : 월 추출
DAYOFMONTH(컬럼) : 날짜 추출
SELECT * FROM test.member WHERE MONTH(join_day) IN(3,4);
// 3월, 4월에 가입한 member- DATEDIFF(날짜 A, 날짜 B) : 날짜 간의 차이 구하기
SELECT DATEDIFF(’2018-01-05’, ’2018-01-03’) FROM test.member;
// 2
CURDATE() // 오늘 날짜
SELECT DATEDIFF(’2019-01-05’, CURDATE()) FROM test.member;
// 오늘날짜(2020-06-02) 기준 -514- 날짜 더하기 빼기
DATE_ADD() : 더하기
DATE_SUB() : 빼기
SELECT DATE_ADD(join_day, INTERVAL 300 DAY) FROM test.member;
// 가입한 날로부터 300일 뒤
SELECT DATE_SUB(join_day, INTERVAL 250 DAY) FROM test.member;
// 가입한 날로부터 250일 전- UNIX_TIMESTAMP : 1970년 1월 1일을 기준으로 몇 초가 지났는지 나타낸 값
SELECT UNIX_TIMESTAMP('2019-01-05') FROM test.member;
// 1546614000 -> 1970년 1월 1일로 부터 1546614000초가 지났다.- FROM_UNIXTIME() : UNIXTIME을 날짜형태로 되돌리는 함수
SELECT FROM_UNIXTIME(UNIX_TIMESTAMP('2019-01-05')) FROM test.member;
// 2019-01-05 00:00:00📒 참고 링크
- 날짜, 시간 관련 데이터 타입 : https://dev.mysql.com/doc/refman/8.0/en/date-and-time-types.html
- 날짜, 시간 관련 함수 : https://dev.mysql.com/doc/refman/8.0/en/date-and-time-functions.html
✨ 문자열 패턴 매칭
-
LIKE A : 문자열 패턴 매칭 조건을 걸기 위해 사용되는 키워드
% : 임의의 길의를 가진 문자열(0자도 포함)
예) '%떡' -> 망개떡, 꿀떡, 무지개떡, 떡_ : 존재하는 문자수 표현(한자라 문자)
예) '__떡' -> 망개떡\ : % , _ , ' , " 를 표현할 때 사용
예)'%쌀함량\%' -> 맵쌀함량%, 찹쌀함량% -
BINARY : 대소문자 구분
: mysql 기본 설정으로 인해 대소문자가 구분이 되지 않고 문자 추출이 되는 경우가 있다.
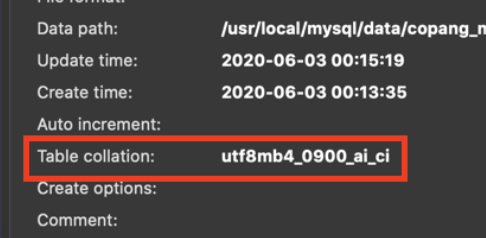
여기 나와있는 ci는 case-insensitive의 약자로 문자열이 동일한지 확인할 때, 대소문자를 구별하지 않겠다는 뜻이다.따라서, 설정을 변경해 주거나 예약어를 통해 구분해 주어야 한다. 대부분 데이터베이스 관리자가 아니면 설정은 건드릴 수 없기에 예약어를 통해 많이 구분해준다.
SELCET * FROM test.member WHERE sentence LIKE BINARY '%g%'
// good afternoon! -> 소문자 g가 포함된 문자열을 출력한다.
SELCET * FROM test.member WHERE sentence LIKE BINARY '%G%'
// good bye -> 대문자 G가 포함된 문자열을 출력한다.✨ 여러 조건 걸기
SELECT * FROM member
WHERE (gender = 'm' AND height >= 180)
(OR gender = 'f' AND height >= 170);
// 남자이면서 키가 180 이상인 member 또는 여자이면서 키가 170이상인 member- AND는 OR보다 우선순위가 높으므로 주의해서 사용해야한다.
- 괄호를 사용하여 우선순위를 정해 사용하는 것이 좋다.
숫자형 : 19 > 27 > 120 > 230
문자형 : 120 > 19 > 230 > 27 - 숫자형은 숫자 크기로 비교하지만, 문자형의 경우 앞자리부터 하나하나 크기를 비교하여 정렬한다.
✨ 데이터 정렬
- ORDER BY 컬럼 ASC(DESC): 오름(내림)차순으로 정렬
- 데이터 타입에 따라 정렬방식이 달라지니 숫자의 데이터 타입이 숫자형인지 문자형인지 잘 확인해야 한다.
💡 TIP 숫자의 자료형이 문자형으로 되어있을 경우
- CAST(컬럼 AS sined) : 컬럼의 데이터 타입을 정수 형태로 변환
👧 singed : 양수와음수를 포함한 모든 정수를 나타내는 타입
✨ 데이터 추려보기
- LIMIT n (,m) : 추출한 데이터중 제한된 갯수만 보이기
SELECT * FROM member
WHERE (gender = 'm' AND height >= 180)
(OR gender = 'f' AND height >= 170)
LIMIT 5;
// 5개의 행만 보인다. -> 1,2,3,4,5
SELECT * FROM member
WHERE (gender = 'm' AND height >= 180)
(OR gender = 'f' AND height >= 170)
LIMIT 4, 3;
// 4번째 인덱스부터 3개의 행이 보인다. (인덱스는 0부터 시작한다. -> 5,6,7행이 보인다.🎇 데이터 분석
✨ 집계 함수와 산술 함수
집계 함수(Aggregate Function)
- COUNT() : 개수
- MAX() : 최댓값
- MIN() : 최솟값
- AVG() : 평균값
- SUM() : 합계
- STD() : 표준편차
산술 함수(Mathematical Function)
- ABS() : 절대값
- SQRT() : 제곱근
- CEIL() : 올림
- FLOOR() : 내림
- ROUND() : 반올림
✨ NULL
- IS (NOT) NULL : null 값인 것(아닌 것)
- null 값은 어떤 (곱하기,나누기...)연산을 해도 null이다.
- COALESCE() : null 값 바꾸기
SELECT COALESCE(height, '####') FROM test.member
// height의 null 값이 ####으로 바뀌어서 출력✨ 컬럼 값 변환
- AS 컬럼명 : 컬럼명 변환
- CASE WHEN 조건 THEN 결과 (ELSE-그외) END
SELECT name, price, price/cost,
(CASE
WHEN price/cost BETWEEN 1 AND 1.5 THEN 'C. 저효율 메뉴'
WHEN price/cost BETWEEN 1.5 AND 1.7 THEN 'B. 중효율 메뉴'
WHEN price/cost >= 1.7 THEN 'A. 고효율 메뉴'
ELSE '알 수 없음'
END) AS efficiency // 컬럼명 'efficiency'로 변경
FROM pizza_price_cost
ORDER BY efficiency DESC, price ASC
LIMIT 6;- CONCAT() : 값 연결하기
SELECT CONCAT(name, '는', price, '원 이다.') AS '메뉴와 가격', price/cost
FROM pizza_price_cost
// 컬럼명 : 메뉴와 가격 , 내용 : 피자는 3000원 이다.✨ 고유값
- DISTINCT(컬럼) : 컬럼 내의 고유한 값만 보기
SELECT DISTINCT(gender) FROM test.member
/// f , m ✨ 문자열 관련 함수
- SUBSTIRING(컬럼, n, m) : 문자열 일부를 추출하는 함수
SELECT SUBSTRING(name 1, 1) FROM test.member;
// 이름의 성만 추출(첫번째 문자열에서 시작해서 하나만 추출)- LENGTH() : 문자열 길이
- UPPER(),LOWER() : 대문자, 소문자로 변환
- LPAD(), RPAD() : 왼쪽 또는 오른쪽을 특정 문자열로 채워주는 함수
SELECT LPAD(age, 10, '0') FROM test.member;
// 0000000032 ->왼쪽부터 0을 채워 10자리수를 만든다.- TRIM(), LTRIM(), RTRIM() : (왼쪽,오른쪽)공백 삭제
SELECT RTRIM(word) FROM copang_main.trim_test;
// 오른쪽 공백 삭제
SELECT LTRIM(word) FROM copang_main.trim_test;
// 왼쪽 공백 삭제
SELECT TRIM(word) FROM copang_main.trim_test;
// 오른쪽,왼쪽 공백 삭제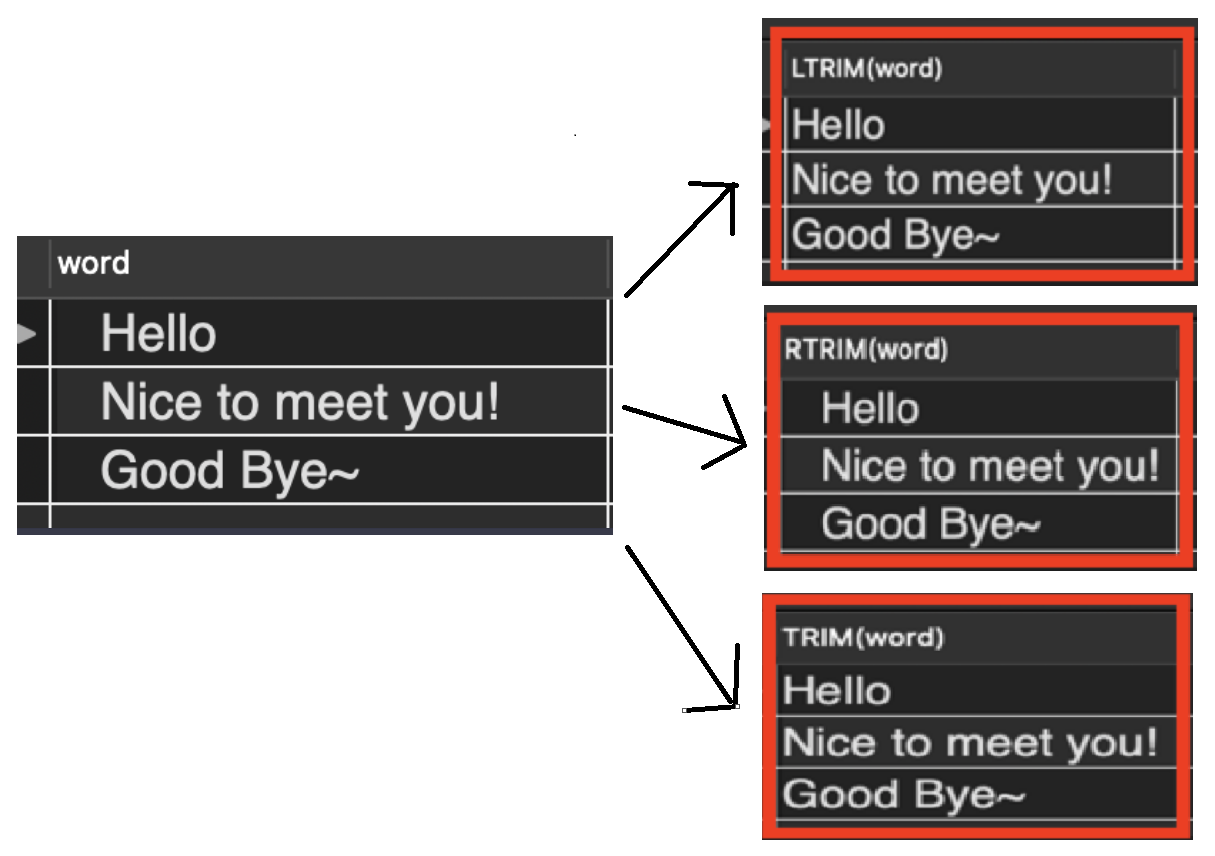
✨ 그루핑(Grouping)
-
GROUP BY 컬럼 HAVING : 그룹화하여 나눔
-
집계함수와 많이 사용된다.
-
조건을 나타낼 때는 WHERE 말고 HAVING을 사용한다.
SELECT 절에는
- GROUP BY 뒤에서 사용한 컬럼 또는
- COUNT(), MAX() 등과 같은 집계 함수만
사용 가능하다.
GROUP BY 뒤에 쓰지 않은 컬럼이름은 SELECT 문에 쓸 수 없다. 왜냐하면, GROUP BY를 사용하면 하나의 행이 아니라 여러 행이 묶인 형태로 표현 되기 때문에 어떠한 값을 가져올 지 알 수 없게 된다. 따라서 집계함수로만 사용할 수 있다.
SELECT category,
main_month, COUNT(*) AS '영화 수',
SUM(view_count) AS '총 관객 수'
FROM 2020_movie_report
GROUP BY category, main_month
HAVING main_month = 5
AND SUM(view_count) >= 3000000 ;- WITH ROLLUP : 부분 총계를 낼 때 사용
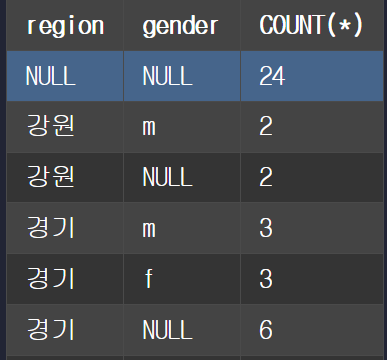
SELECT SUBSTRING(address, 1, 2) as region,
gender,
COUNT(*)
FROM member
GROUP BY SUBSTRING(address, 1, 2), gender WITH ROLLUP
HAVING region IS NOT NULL
ORDER BY region ASC, gender DESC;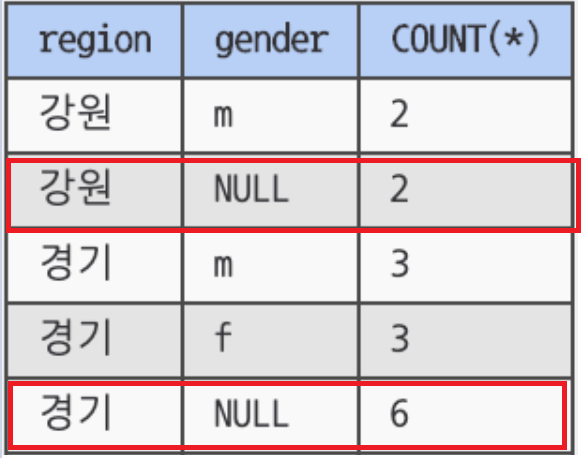
- GROUPING() : 빈 값 null값과 부분총계 null값을 구분하기 위해 사용
전체 총계는 보고 싶은데 IS NOT NULL로 표시한 부분으로 1번의 총계가 표시되지 않을 때, GROUPING() 을 사용하여 해결 할 수 있다.
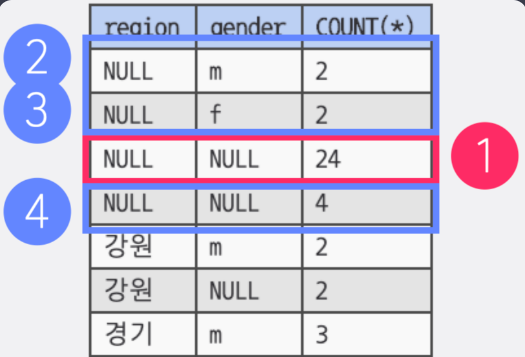
- 실제로 NULL을 나타내기 위해 쓰인 NULL인 경우에는 0,
- 부분 총계를 나타내기 위해 표시된 NULL은 1
을 리턴해서 둘을 구분하게 해주는 함수이다.
WITH ROLLUP을 썼을 때, 이 NULL이
- 실제로 NULL을 나타내기 위해서 쓰인 건지,
- 부분 총계를 나타내기 위해 쓰인 건지
구분하고 싶다면 GROUPING() 함수를 사용할 수 있다.
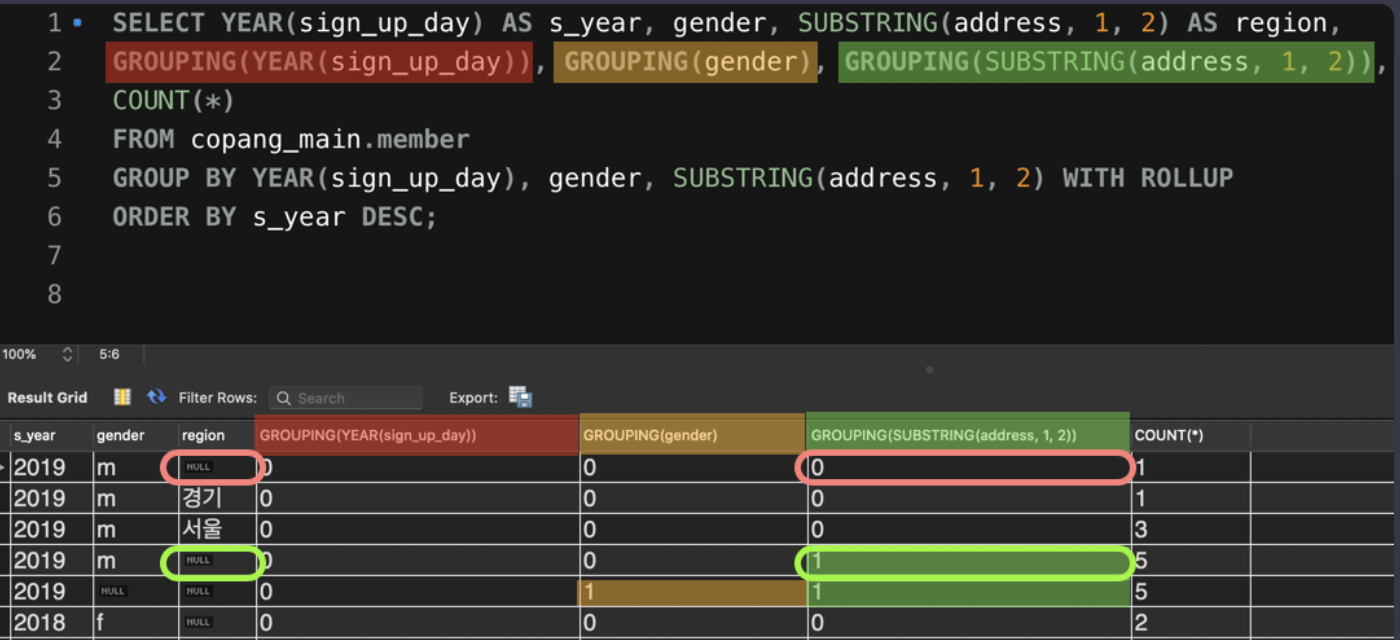
SELECT SUBSTRING(address, 1, 2) as region,
gender,
COUNT(*)
FROM member
GROUP BY SUBSTRING(address, 1, 2), gender WITH ROLLUP
HAVING (GROUPING(region) = 1) OR (region IS NOT NULL)
ORDER BY region ASC, gender DESC;