기존 RAG 방식들
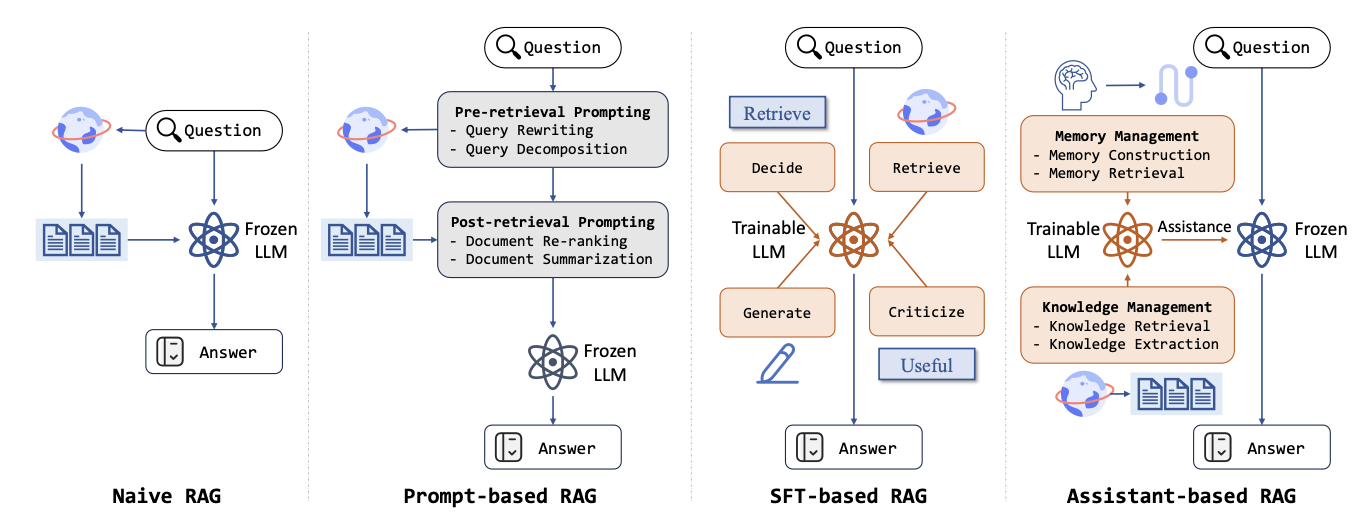
기종 RAG라고 하면, 아래의 세 가지 방식이 가장 널리 활용됩니다.
-
Naive RAG
가장 기본적인 형태의 RAG로, 질문에 대해 외부 데이터베이스로부터 관련 문서를 검색한 후, 해당 문서와 질문을 함께 LLM에 입력하여 답변을 생성하는 방식입니다.
Retrieval과 Generation이 분리되어 있으며, 별도의 추가 학습 없이도 손쉽게 적용할 수 있다는 장점이 있습니다.[질문] → [Retriever로 문서 검색] → [질문 + 문서 → LLM → 답변 생성]
-
Prompt-based RAG
Naive RAG의 구조를 기반으로 하되, LLM의 응답 품질을 향상시키기 위해 정교한 프롬프트 엔지니어링을 적용하는 방식입니다.
질문을 변형하거나, 검색된 문서를 요약·정제하여 LLM이 더 효과적으로 정보를 활용할 수 있도록 프롬프트를 설계합니다.[질문 → Prompt로 변형] → [Retriever] → [정교한 Prompt + 문서 + 질문 → LLM → 답변]
-
SFT-based RAG (Supervised Fine-Tuning 기반 RAG)
이 방식은 Retrieval 과정을 제거하거나 제한적으로 활용하고,
외부 문서와 정답 데이터를 기반으로 LLM 자체를 Supervised Fine-Tuning하여
문서 기반 질의응답 능력을 모델 내부에 내재화하는 방식입니다.
이론적으로 가장 높은 성능을 기대할 수 있으며, 정확도와 일관성이 우수하지만,
• LLM마다 별도의 학습이 필요하고,
• 도메인 변경 시 반복적인 fine-tuning이 요구되며,
• 비용과 시간 측면에서의 부담이 큽니다.[질문 + 문서] → [fine-tuned LLM → 답변 생성]
❗ 공통된 한계점
기존 RAG 방식들은 LLM이 검색된 외부 문서를 기반으로 직접 응답을 생성하도록 설계되어 있기 때문에,
복잡한 질의에 대한 multi-hop reasoning이나 연결 기반 추론(chain reasoning) 수행에 한계가 존재합니다.
또한, 검색된 문서에 핵심 정보가 부재하거나,
혼란을 주는 불필요한 정보가 포함된 경우,
LLM은 이를 효과적으로 필터링하지 못하고 정확도가 저하될 수 있습니다.
정보가 불충분하거나 애매한 경우에는 환각(hallucination) 문제가 발생하여,
LLM이 실제로 존재하지 않는 내용을 “추론”이 아닌 "상상"을 통해 생성하는 경향도 나타납니다.
아울러, 외부 문서를 직접 LLM의 입력 컨텍스트에 포함시키는 구조적 특성상,
입력 토큰 수가 증가하며, 이로 인해 추론 비용이 상승하고,
모델의 컨텍스트 한계에 도달하는 문제가 발생할 수 있습니다.
그래서 등장한 Assistant-Based RAG
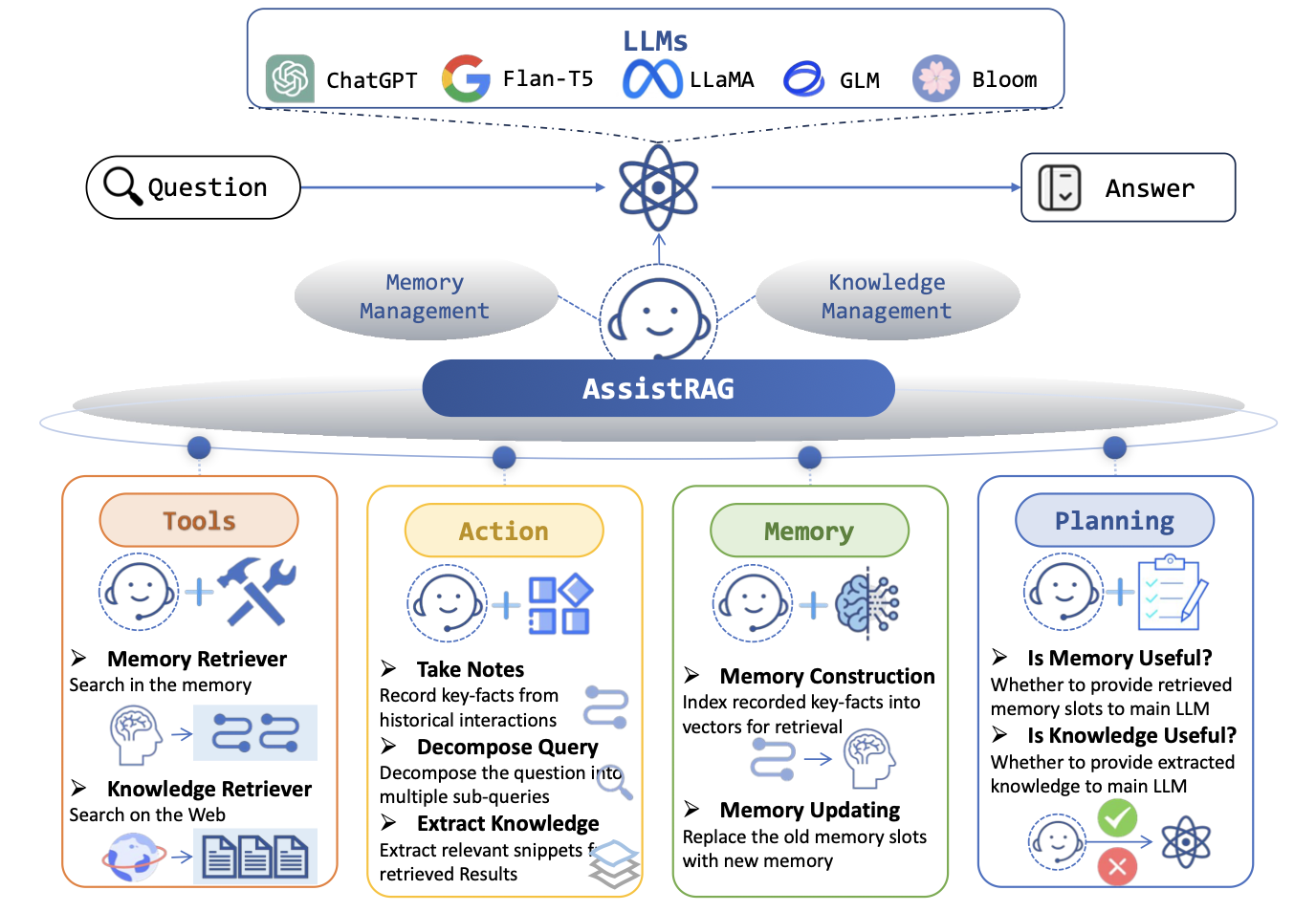
기존 RAG의 한계를 극복하기 위해, 두 개의 LLM(메인 LLM + 보조 LLM)을 분업 구조로 활용하는
Assistant-Based RAG (ASSISTRAG) 프레임워크가 제안되었습니다.
이 구조에서는 보조 LLM이 정보를 검색·정리·선택한 후,
핵심 정보만을 포함한 프롬프트를 메인 LLM에 전달하여 응답을 생성하게 됩니다.
Main LLM: 최종 응답을 생성하는 고정(frozen) 모델 Assistant LLM: 정보를 수집·정제하는 학습 가능한 보조 모델
보조 LLM
보조 LLM은 단순한 검색 기능을 넘어, 다음과 같은 복합적 추론 및 정보 처리 역할을 수행합니다
정보검색 & 질문분해
정보 선택 & 필터링
메모리 구축
계획수립 & 행동실행
-
🔍 정보 검색 & 질의 분해 (Retrieval & Query Decomposition)
• 복잡하거나 다단계로 이루어진 질문을 서브 질문으로 분해
• 각 서브 질문에 대해 외부 문서 또는 툴을 활용해 관련 정보를 검색
• 프롬프트를 활용하여 특정 도메인 지식이 필요한 전문 정보 생성도 가능💡 예시 – 실제 활용 사례:
필자가 심리상담 챗봇을 구축할 때, 감정 소분류나 인지 왜곡 여부와 같은 심리학적 개념을 포함한 프롬프트를 구성하여 보조 LLM이 필요한 정보를 생성하도록 활용
-
🧹 정보 선택 & 필터링 (Selection & Filtering)
• 검색된 문서 중 부적절하거나 부정확한 정보를 제거
• 정보의 신뢰도와 정합성을 높여 메인 LLM의 환각(hallucination) 가능성을 감소시킴 -
🧾 메모리 구축 (Memory Construction)
• 이전에 수집하거나 reasoning한 정보를 구조화된 메모리 형태로 저장
• 이후 유사한 질의나 연속된 대화에서 기억된 정보를 재활용 가능 -
🧭 계획 수립 & 행동 실행 (Planning & Action Execution)
• 질문 해결을 위한 step-by-step 계획 수립
• 각 단계에서 필요한 행동(문서 검색, 정리, 비교 등)을 결정하고 실행[사용자 질문]
↓
(1) 질의 분해 → (2) 외부 정보 검색 → (3) 정보 필터링 및 정리
↓
(4) 필요한 정보만 추출 → (5) 메모리에 기록
↓
(6) 메인 LLM에 최적화된 입력 구성 → 메인 LLM이 최종 응답 생성
📌 예시
질문: “강호동과 유재석 중 누가 나이가 많아?”
• 보조 LLM: 두 사람의 생년월일 정보를 검색하고 나이를 계산한 뒤
• 메인 LLM: 전달받은 나이 정보를 바탕으로 “강호동이 더 나이가 많다”는 응답을 생성📈 성능 평가
3가지 QA 벤치마크(HotpotQA, 2WikiMultiHopQA, Bamboogle)를 기준으로 성능 평가를 진행한 결과
Naive RAG 대비 평균 +27.1%
SFT-RAG 대비 평균 +13.5%
작은 모델에서 더욱 큰효과 발생 최대 +78%
66% 불필요한 문서 제거
🔗 Boosting the Potential of Large Language Models with
an Intelligent Information Assistant
