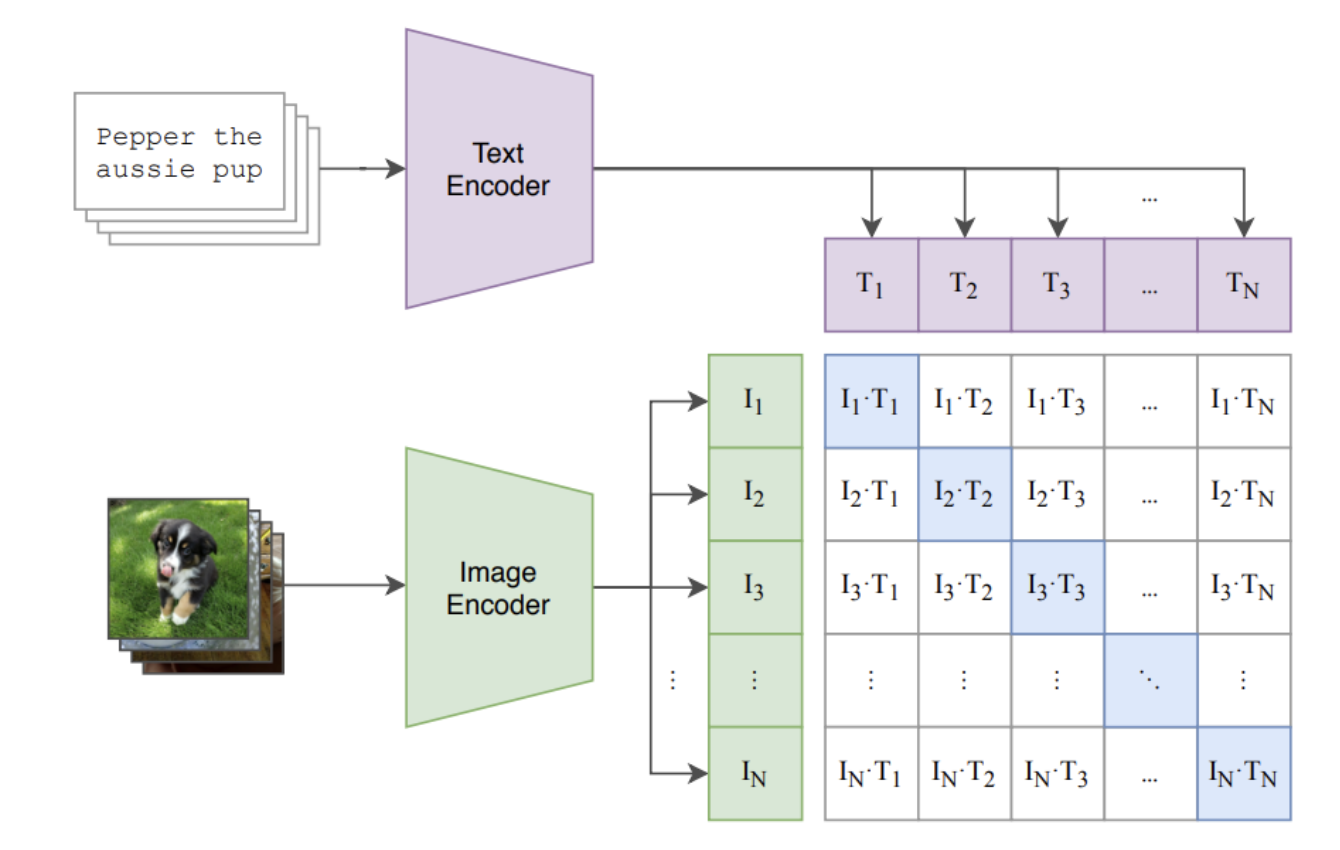
CLIP
CLIP은 비전 분야에서 라벨링 데이터 부족의 한계를 극복하기 위해 제안된 모델이다.
비전 분야는 대규모 데이터를 확보하기 위해 반드시 라벨링 작업이 필요했는데, 이는 비용과 시간이 많이 드는 과정이었다.
반면, 자연어 분야는 웹에 존재하는 방대한 텍스트 데이터를 기반으로, 별도의 라벨링 없이 단어 간 관계를 학습시킬 수 있었다.
이 때문에 자연어 분야는 대규모 언어 모델(LLM)의 등장을 계기로 폭발적인 성장을 보일 수 있었지만,
비전 분야는 대규모 라벨링 데이터셋 구축의 어려움으로 성장 속도가 더뎠다.
CLIP은 이런 한계를 극복하기 위해, 이미지와 자연어 문장을 짝지어 학습하는 방식을 도입했다.
즉, 이미지에 달린 캡션이나 alt-text 같은 웹상의 자연어 텍스트를 라벨 대체(supervision) 로 사용한 것이다.
Text Supervise
앞서 말했듯이 대규모 이미지–텍스트 쌍을 모으는 것이 핵심이다.
웹에는 수많은 이미지가 이미 존재하지만, 대부분 라벨이 붙어 있지 않다.
CLIP은 이를 해결하기 위해 이미지와 함께 존재하는 캡션, alt-text, 설명 글 등을 활용했다.
즉, 자연어 문장을 라벨처럼 취급하여 대규모 이미지–텍스트 쌍 데이터셋을 구축한 것이다.
다만 이 데이터에는 한계도 있다:
- 텍스트의 정확도가 불균일하고 (잘못된 설명 포함)
- 문장 길이가 들쭉날쭉하며
- 고정된 클래스가 아닌 자유로운 자연어 문장이라는 점이다.


Contrastive Pre-training
문장의 형식과 길이가 일정하지 않기 때문에, 기존 분류 모델처럼 Softmax 출력층을 고정 클래스에 적용하는 방식은 적합하지 않다.
CLIP은 대신 대조 학습(Contrastive Learning) 을 사용했다.
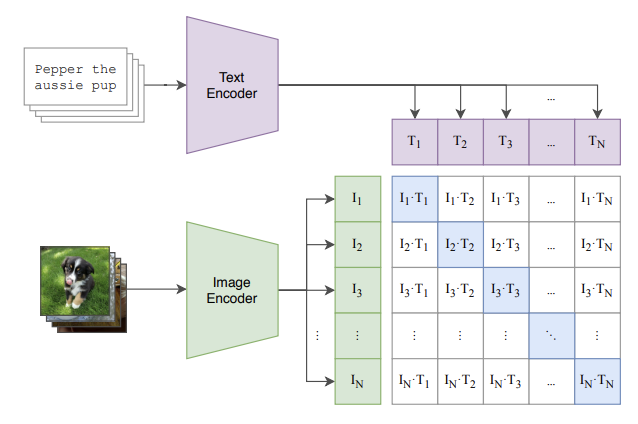
Contrastive Learning은 지도학습의 한 형태로,
- 관련 있는 쌍(positive pair) 은 임베딩 공간에서 가깝게,
- 관련 없는 쌍(negative pair) 은 멀리 떨어지도록 학습하는 방식이다.
예를 들어, [pretty dog]과 [smiling dog]은 문장은 다르지만 의미적으로 유사하므로 feature space에서 가깝게 인코딩된다.
즉, 고정된 클래스 라벨이 아니라 문장의 의미에 따라 임베딩이 구성되는 것이다.
CLIP에서는 이미지 인코더와 텍스트 인코더를 각각 두고,
- 이미지 → 임베딩 벡터 (I)
- 텍스트 → 임베딩 벡터 (T)
를 생성한다.
이후 모든 이미지–텍스트 쌍에 대해 코사인 유사도를 계산한다.
배치 크기를 (N)이라 하면, (N\times N) 개의 유사도가 계산되고,
그중 대각선의 (N)개가 정답 쌍이다.
CLIP은 정답 쌍의 유사도를 높이고, 나머지 (N^2 - N)개의 잘못된 쌍의 유사도를 낮추도록 학습한다.
- Image Encoder: ResNet-50, Vision Transformer (ViT)
- Text Encoder: Transformer
Zero-Shot Prediction
이 학습 방식의 가장 큰 장점은 Zero-Shot Prediction이다.
즉, 학습 데이터에 등장하지 않았던 새로운 클래스도 텍스트 프롬프트만 제공하면 분류가 가능하다.
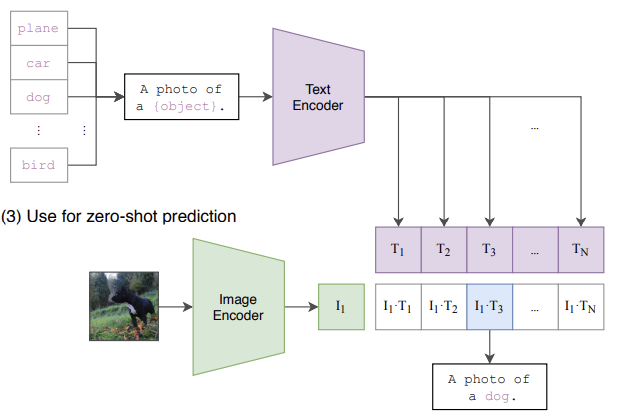
예를 들어, CLIP이 dog 이미지를 직접 학습한 적이 없더라도,
텍스트 후보군에 "a photo of a dog" 문장을 넣어두면,
이미지 임베딩과 텍스트 임베딩을 비교했을 때 dog가 가장 유사도가 높게 나와 → dog로 분류된다.
즉, CLIP은 이미지를 보고 새로운 클래스를 생성해내는 건 아니지만,
학습 시 본 적 없는 클래스라 해도, 해당 단어를 프롬프트로 추가하기만 하면 분류가 가능하다.
