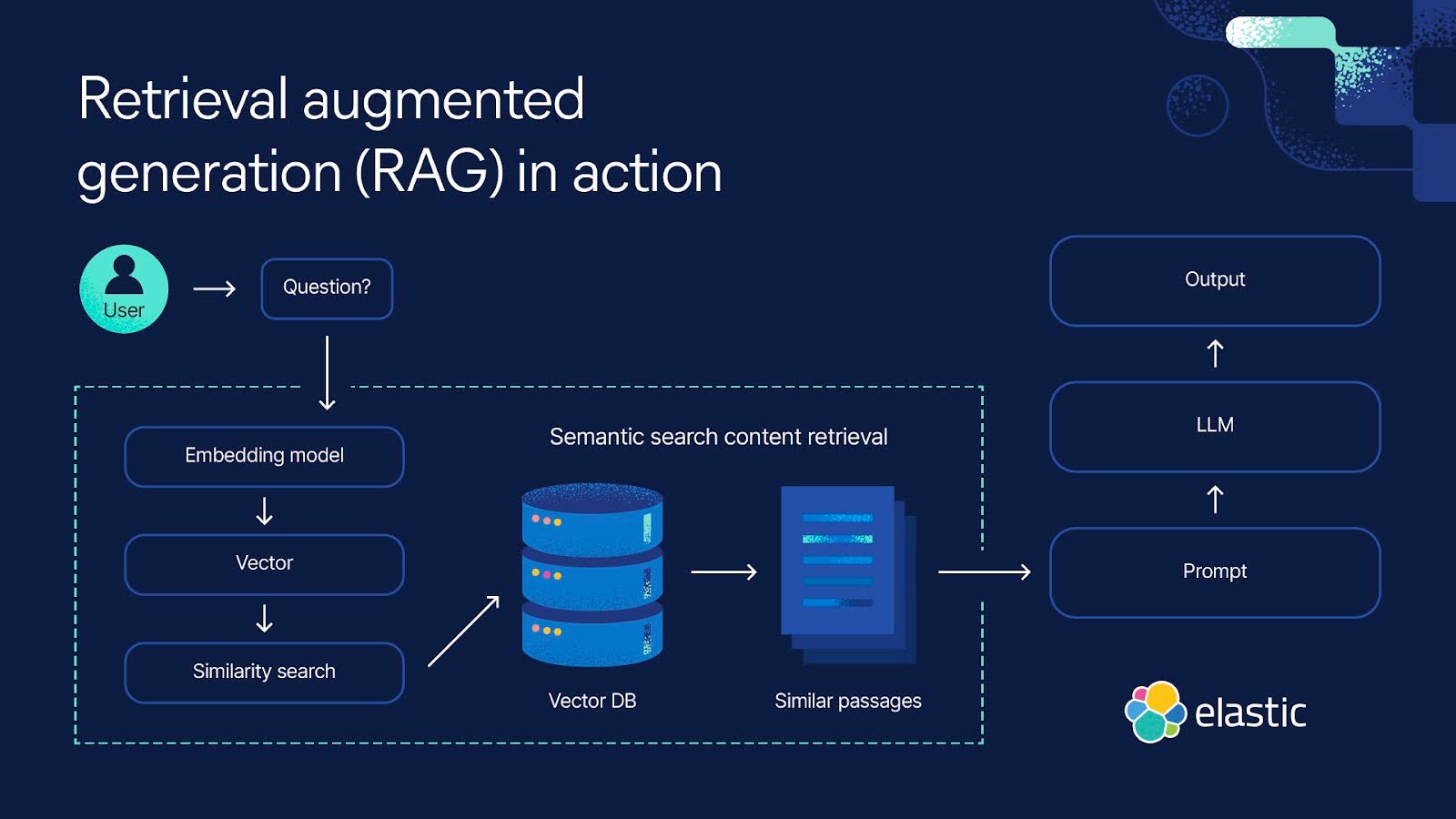
RAG란?
RAG(Retrieval-Augmented Generation)는 검색 증강 생성 방식으로, 기존 LLM의 한계를 극복하기 위해 외부 데이터를 검색하고 이를 바탕으로 답변을 생성하는 방법입니다.
기존 LLM은 사전 학습된 데이터만을 바탕으로 답변을 생성하는 한계가 있지만, RAG는 실시간 검색 기능을 통해 최신 정보를 반영할 수 있습니다.
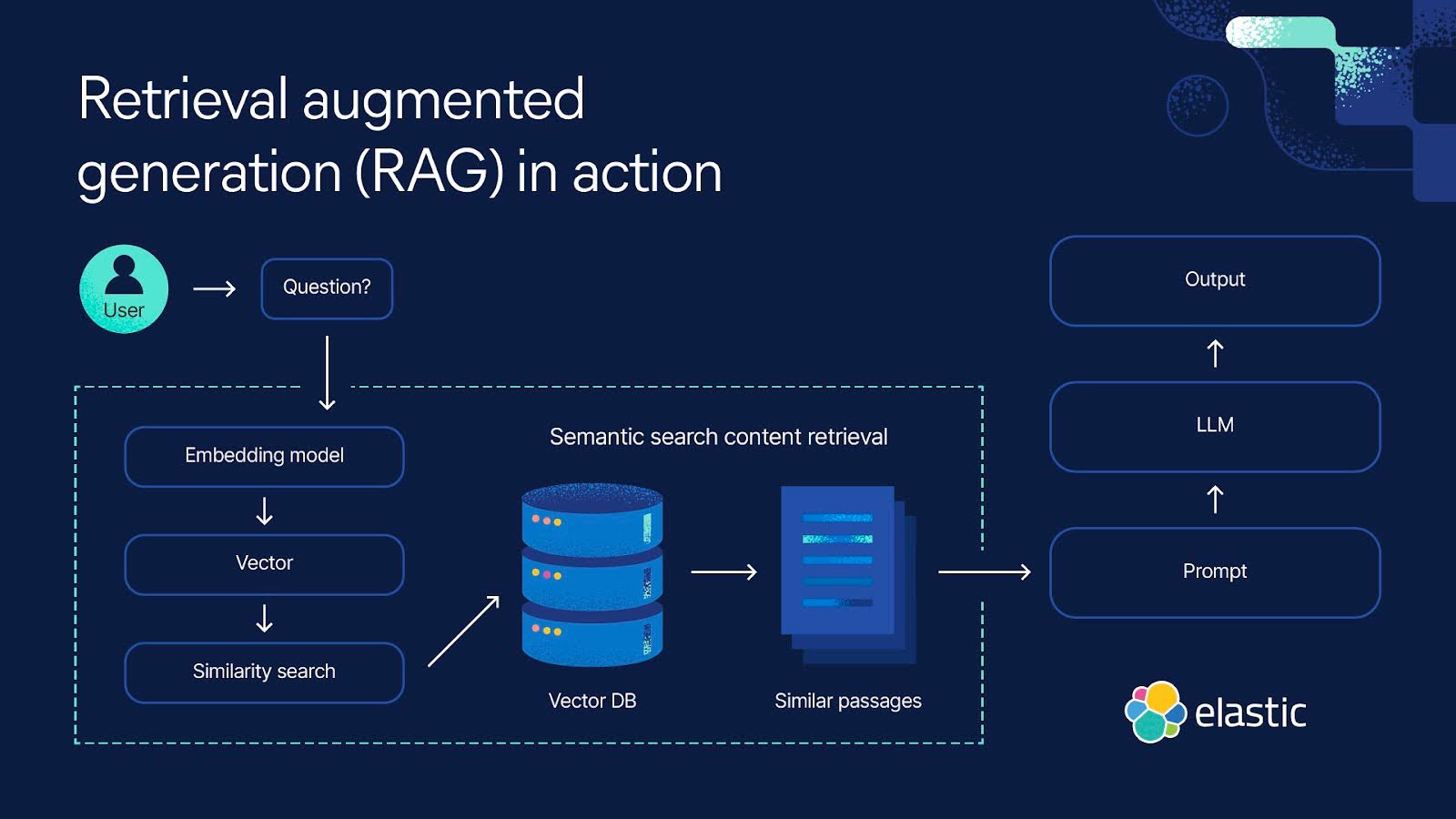
RAG의 핵심 절차
RAG는 검색(Retrieval)과 생성(Generation)의 두 단계로 작동합니다.
1️⃣ Retrieval (검색 단계)
• 사용자의 입력(질문, 컨텍스트)에 따라 외부 데이터베이스에서 관련 정보를 검색
• 벡터 검색(Vector Search)을 활용하여 의미적으로 유사한 데이터를 찾음
2️⃣ Generation (생성 단계)
• 검색된 데이터를 LLM의 입력으로 제공하여 답변을 생성
• 기존 모델보다 더 정확하고 신뢰할 수 있는 정보를 제공
LLM의 한계와 RAG
🚫 기존의 LLM모델에는 여러가지 한계가 존재했다.
최신 정보 반영 불가
환각 현상 (Hallucination)
특정 도메인에 대한 부족한 지식
환각현상 예시)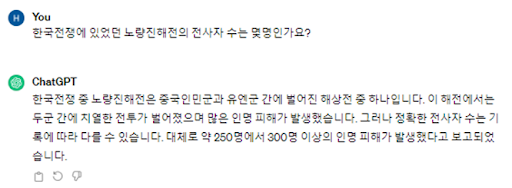
💡 LLM의 이러한 현상을 외부의 데이터베이스로부터 답변을 도출하는 RAG 방식으로 해결할 수 있다.
RAG기법은 기존 모델에 검색기능을 추가하여 컨텍스트에대해 더욱 풍부하고 최신의 정보를 바탕으로 답변을 생성하게 해준다.
RAG 파이프라인
RAG의 전체 과정은 “검색 ➡️ 생성”으로 요약할 수 있지만, 세부적으로는 다음과 같은 단계로 구성됩니다.
데이터 로드 ➡️ 텍스트 분할 ➡️ 인덱싱 ➡️ 검색 ➡️ 생성
1️⃣ 데이터 로드 (Data Loading)
• 검색에 사용할 데이터베이스 구축
• 데이터 소스: 웹페이지, 논문, 사내 문서, 데이터베이스 등
2️⃣ 텍스트 분할 (Text Chunking)
• 문서가 너무 길면 검색 성능이 떨어질 수 있으므로 작은 단위(Chunk)로 분할
• 문장 단위, 패러그래프 단위 등으로 분할
3️⃣ 인덱싱 및 벡터화 (Indexing & Embedding)
• 각 텍스트 조각을 벡터로 변환하여 저장
• 벡터 검색(Vector Search)이 가능하도록 FAISS, ChromaDB, Pinecone 같은 벡터DB 사용
4️⃣ 검색 (Retrieval)
• 사용자의 질문을 벡터로 변환 후 가장 유사한 데이터를 검색
• 검색 결과에서 가장 관련성이 높은 문서를 선택
5️⃣ 생성 (Generation)
• 검색된 문서와 함께 LLM에 입력하여 더 정확한 답변을 생성
• 사용자의 질문에 맞는 최신 정보와 컨텍스트를 반영
