Open AI의 GPT-3출시와 함께 공개된 논문이다.
GPT-4.5가 공개된 현재 시점에서는 다소 오래된 연구이지만, 중요한 접근법을 포함하고 있어 기록해두고자 한다.
Few-Shot Learning
few shot learning은 GPt-3의 가장 중요한 개선방향이다.
이는 Fine-Tuning 없이 [예제 + 질문]만으로 적절한 답변을 생성하는 학습 방식이다.
부모님 - 1
선생님 - 1
할아버지 - 1
사장님 - 1
친구 - 0
막내 동생 - 0
학교 후배 - 0
직장동료 - ??
인간이라면 직장 동료의 값이 0이라는 것을 쉽게 유추할 수 있다.
이전 GPT 모델들은 방대한 데이터를 학습한 이후에야 이를 추론할 수 있었지만, 인간이 즉각적으로 판단할 수 있는 이유는 주어진 예시(k개)를 기반으로 일반화했기 때문이다.
이러한 학습 방법을 Few shot learning이라고 한다.
이전 모델들의 학습방식
이전의 NLP 모델들은 각 태스크에 대해 지도학습 방식으로 대량의 데이터를 Fine-Tuning하여 학습했다.
이 방식이 성능이 낮다는 것은 아니다.
실제로 특정 태스크만을 고려했을 때, Fine-Tuning된 모델의 성능이 높은 경우가 많다.
그러나, 특정 태스크를 위해 수천~수만 개의 데이터를 학습시키다 보면 모델이 특정 데이터 분포에 과적합될 위험이 있다.
이는 해당 모델이 새로운 태스크나 데이터 분포에 대해 일반화되지 않는 문제를 초래한다.
이 문제를 해결하기 위해 GPT-2에서는 In-Context Learning을 도입했다.
이는 [태스크 설명 + 질문] 형식으로 입력을 구성하여 모델이 적절한 컨텍스트 안에서 답변을 생성하도록 유도하는 방식이다.
그러나 이 방식만으로는 일부 태스크에서 충분한 성능을 발휘하지 못했다.
이 문제를 해결하는 가장 단순한 방법은 모델 크기를 키우는 것이다.
모델 자체의 크기를 확장하면 추론 능력이 향상되며, 이는 성능 개선으로 이어진다.
따라서, GPT-3에서는 모델 크기 확장과 Few-Shot Learning을 활용하여 성능을 대폭 향상시켰다.
GPT-3의 성능
GPT-3에는 1,750억 개의 파라미터가 포함되어 있다.
이는 GPT-2(14억 개)와 비교했을 때 100배 이상 증가한 규모다.
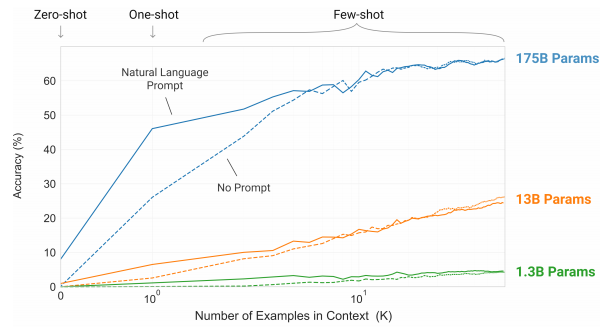
Few shot Learning은 모델의 크기가 커질수록 더욱 효과적이다.
위 그래프에서 K=1과 K=10의 성능 차이가 커지는 것을 확인할 수 있다.
GPT-3모델의 다양한 NLP 태스크 성능을 측정해 보았더니
특정 태스크에서는 Fine-Tuning SOTA모델보다 좋은 성능을 보였다.
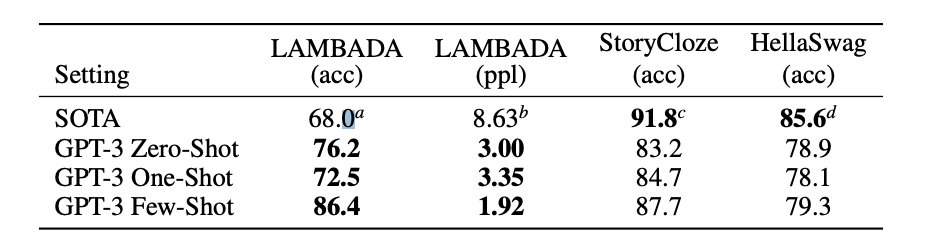
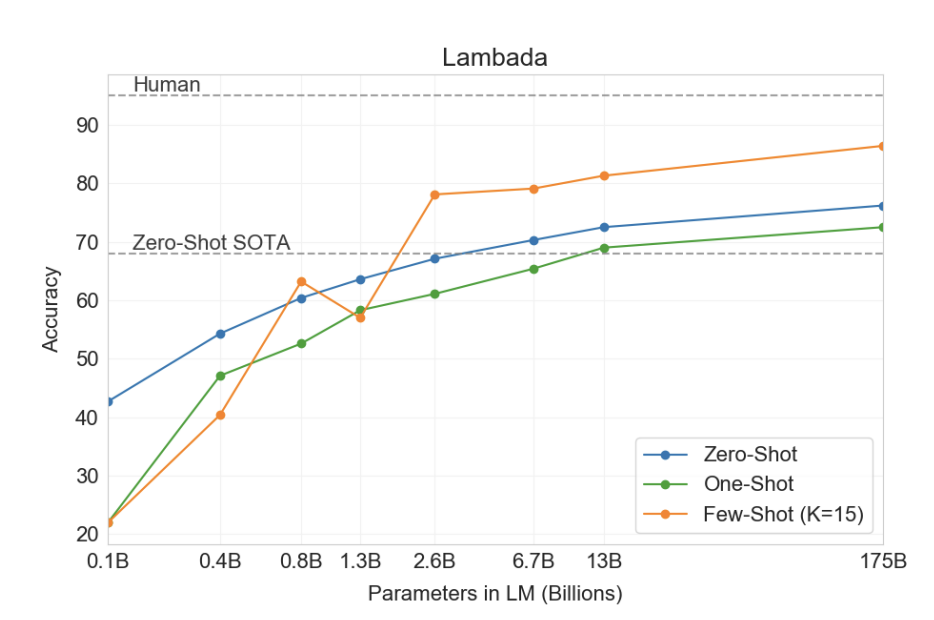
LAMBADA(문장 완성)태스크에서 86.4%의 정확도를 보이면서 이전 SOTA 모델에비해 큰 성능향상을 이뤘다.
한계
Few-Shot Learning의 한 가지 한계점은,
모델이 추론 과정에서 새로운 태스크를 학습하는 것인지,
아니면 사전 학습 중 이미 학습된 태스크를 수행하는 것인지 정확히 판단하기 어렵다는 점이다.
이는 모델이 정말로 새로운 지식을 일반화하는지 또는
단순히 사전 학습된 데이터에서 유사한 패턴을 찾아내는지를 구분하는 것이 쉽지 않다는 의미다.
자원의 한계
모델을 개발하는 과정에서 큰 모델, 많은 데이터를 학습하는 것이 이상적이지만,
자원의 한계로인해 효율적인 학습방식이 필요할 때가 많다.
이러한 상황에서 Few Shot Learning방식이 해답이 될 수 있다.
