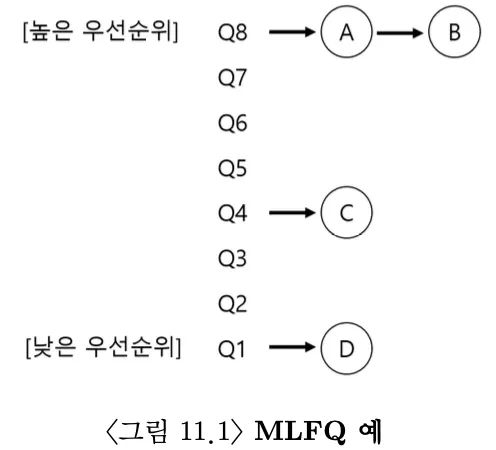
MLFQ가 해결하고자 하는 기본적인 문제는 두가지이다.
- 짧은 작업을 먼저 실행시켜 반환 시간을 최적화한다. 운영체제는 실행시간을 미리 알 수 없다는 점을 고려해야 한다.
- 대화형 사용자에게 응답이 빠른 시스템이라는 느낌을 주고 싶었기에 응답 시간을 최적화한다.
프로세스에 대한 정보가 없다면 어떡할까? 실행 중인 작업의 특성을 알아내고 이를 이용해 더 나은 스케줄링 결정을 위한 방법은 무엇일까?
1. MLFQ: 기본 규칙
MLFQ는 여러개의 큐로 구성되며 각각 다른 우선순위(priortiy)를 가진다. 실행 준비가 된 프로세스는 여러 큐 중 하나에 존재한다. MLFQ는 우선순위가 높은 작업을 먼저 스케줄한다. 같은 우선 순위를 가질 경우 RR 방식을 이용한다.
규칙 1: Priority(A) > Priority(B) 이면, A가 실행된다 (B는 실행되지 않는다).
규칙 2: Priority(A) = Priority(B) 이면, A와 B는 RR 방식으로 실행된다.
2. 시도 1: 우선 순위의 변경
MLFQ는 각 작업의 특성에 따라 우선순위를 동적으로 부여한다. 작업이 키보드 입력을 기다리며 반복적으로 CPU를 양보하면 MLFQ는 해당 작업의 우선순위를 높게 유지한다. 반면에 작업이 긴 시간 동안 CPU를 집중적으로 사용하면 MLFQ는 해당 작업의 우선순위를 낮춘다.
규칙 3: 작업이 시스템에 진입하면, 가장 높은 우선순위, 즉 맨 위의 큐에 놓여진다.
규칙 4a: 주어진 타임 슬라이스를 모두 사용하면 우선순위는 낮아진다. 즉, 한 단계 아래 큐로 이동한다.
규칙 4b: 타임 슬라이스를 소진하기 전에 CPU를 양도하면 같은 우선순위를 유지한다.
예 1: 한개의 긴 실행 시간을 가진 작업
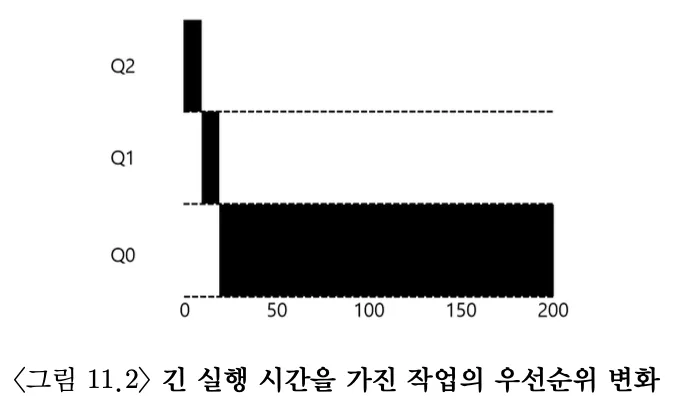
긴 실행 시간을 가진 작업이 도착했을 때, 처음에는 최고 우선 순위로 진입한다. 타임 슬라이스가 지날 때마다 우선 순위가 한 단계씩 낮아지게 된다.
예 2: 짧은 작업과 함께
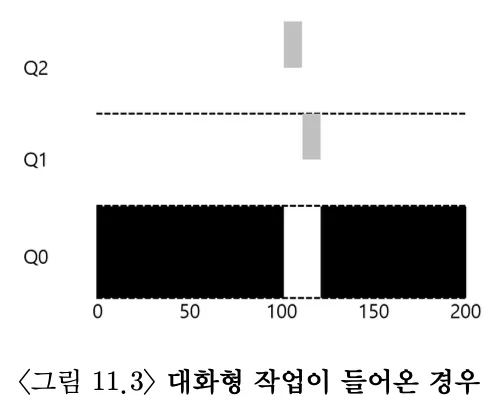
A는 오래 실행되는 CPU 위주의 작업이고, B는 짧은 대화형 작업이다. B는 Q0에 도달하기 전에 높은 우선 순위를 가지기 때문에 빠르게 종료된다. 이러한 방식으로 MLFQ는 SJF에 근접할 수 있다.
예 3: 입출력 작업에 대해서는 어떻게?
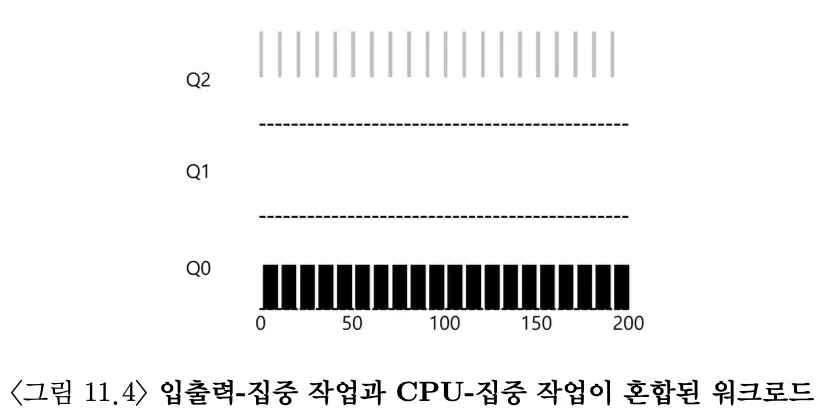
입출력 작업에서 프로세스가 타임 슬라이스를 소진하기 전에 프로세서를 양도하면 같은 우선순위를 유지하게 한다.
대화형 작업이 키보드나 마우스의 입력에 대한 입출력을 수행할 때, 타임 슬라이스가 종료되기 전에 CPU를 반납하기 때문에 계속해서 높은 우선순위를 가지게 된다. 이를 통해 B가 대화형 작업이라면 MLFQ이 대화형 작업을 더 빨리 실행시킨다는 목표에 근접할 수 있다.
현재 MLFQ의 문제점
-
기아 상태
시스템에 너무 많은 대화형 작업이 존재할 경우 긴 실행 시간을 가진 작업은 CPU를 할당 받지 못할 것이다.
-
스케줄러가 자신에게 유리하게 동작하도록 프로그램을 다시 작성할 수 있다.
스케줄러를 속여 지정된 몫보다 많은 시간을 할당하도록 한다. 예를 들어 타임 슬라이스 직전에 의도적으로CPU를 양도시키는 방식이 있다.
-
프로그램은 시간에 흐름에 따라 특성이 변할 수 있다.
CPU 위주의 작업이 대화형 작업으로 바뀔 수도 있다.
3. 시도 2: 우선 순위의 상향 조정
기아 문제를 방지하기 위해 CPU 위주의 작업의 진행을 조금이라도 보장할 수 있는 방법을 생각해보자. 주기적으로 모든 작업의 우선순위를 상향 조정(boost)하는 방식이 있다.
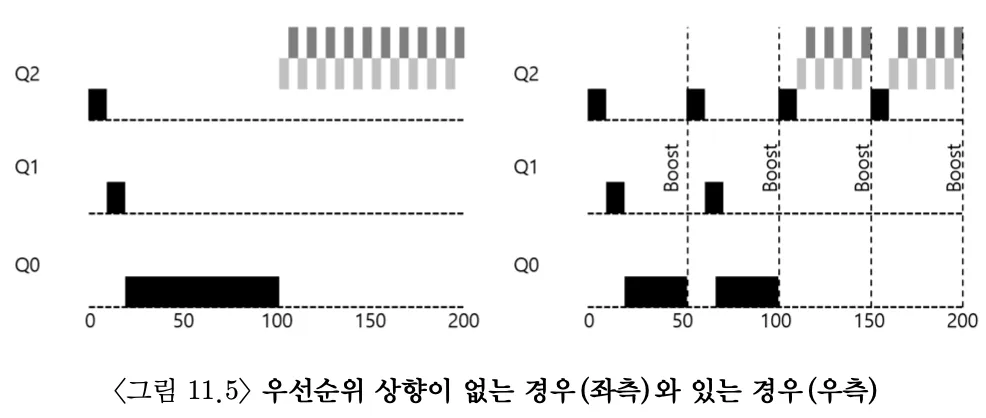
규칙 5: 일정 시간 S가 지나면, 시스템의 모든 작업을 최상위 큐로 이동시킨다.
새 규칙은 두가지 문제를 한번에 해결한다.
- 기아 현상 해결. 일정 시간 마다 최상위 큐에서 RR방식으로 수행된다.
- CPU위주 작업이 대화형 작업으로 전환될 경우, 변경된 특성이 스케줄링에 고려될 수 있다.
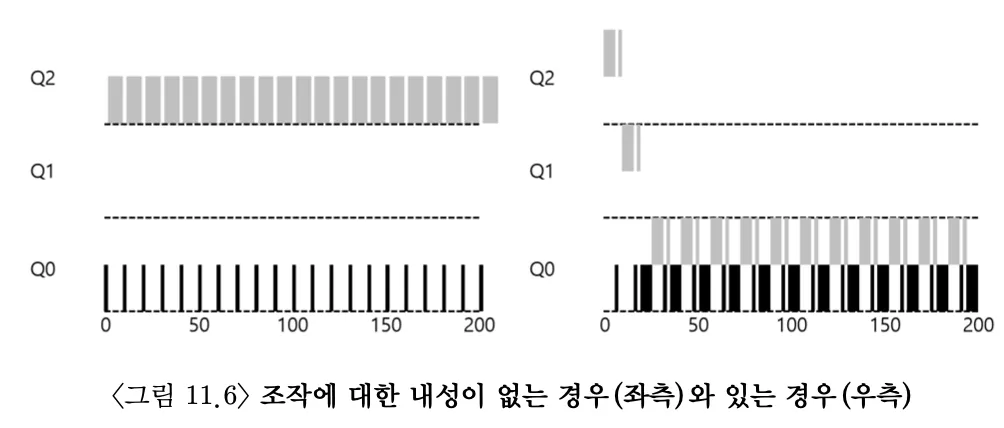
4. 시도 3: 더 나은 시간 측정
스케줄러를 자신에게 유리하게 동작시키는 것은 어떻게 막을 수 있을까?
MLFQ의 각 단계에서 CPU 총 사용 시간을 측정하는 방식을 통해 해결할 수 있다. 규칙 4a와 4b를 합쳐 재정의 해보자.
규칙 4: 주어진 단계에서 시간 할당량을 소진하면(CPU를 몇 번 양도하였는지 상관없이), 우선순위는 낮아진다. (즉, 아래 단계의 큐로 이동한다.)
5. MLFQ 조정과 다른 쟁점들
- 필요한 변수들을 스케줄러가 어떻게 설정 해야할까
- 몇 개의 큐가 존재해야 하는가?
- 기아를 피하고 변화된 행동을 반영하기 위해 우선순위 상향이 얼마나 자주 발생해야 하는가?
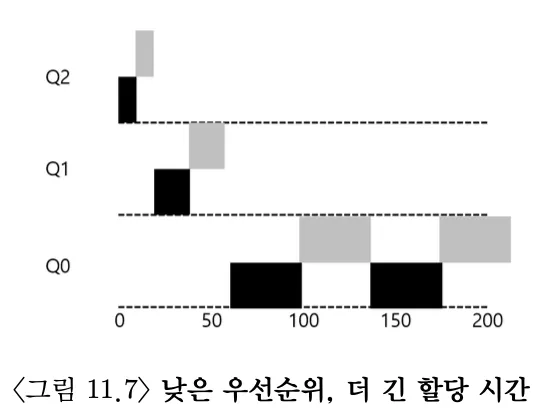
- 큐당 타임 슬라이스 크기는 얼마로 해야하는가? - 대부분의 MLFQ 기법들은 큐 별로 타임 슬라이스를 설정할 수 있다. 일반적으로 우선순위가 높을수록 적은 타임 슬라이스를 가진다.
Solaris의 MLFQ 구현 테이블 - 기본 큐의 개수는 60, 타임 슬라이스의 크기는 우선순위가 가장 높은 큐가 20ms부터 시작하여 수백 ms까지 증가, 우선순위 상향 조정은 약 1초마다 발생한다.
6.요약
- 규칙 1 : 우선순위(A)> 우선순위(B) 일 경우, A가 실행, B는 실행되지 는다.
- 규칙 2 : 우선순위(A) = 우선순위(B), A와 B는 RR 방식으로 실행된다.
- 규칙 3 : 작업이 시스템에 들어가면 최상위 큐에 배치된다.
- 규칙 4 : 작이 지정된 단계에서 배정받은 시간을 소진하면(CPU를 포기한 횟수와 상관없이), 작업의 우선순위는 감소한다(즉, 한 단계 아래 큐로 이동한다).
- 규칙 5 : 일정 주기 S가 지난 후, 시스템의 모든 작업을 최상위 큐로 이동시킨다.
