OSTEP
1.OSTEP 5 - Process API
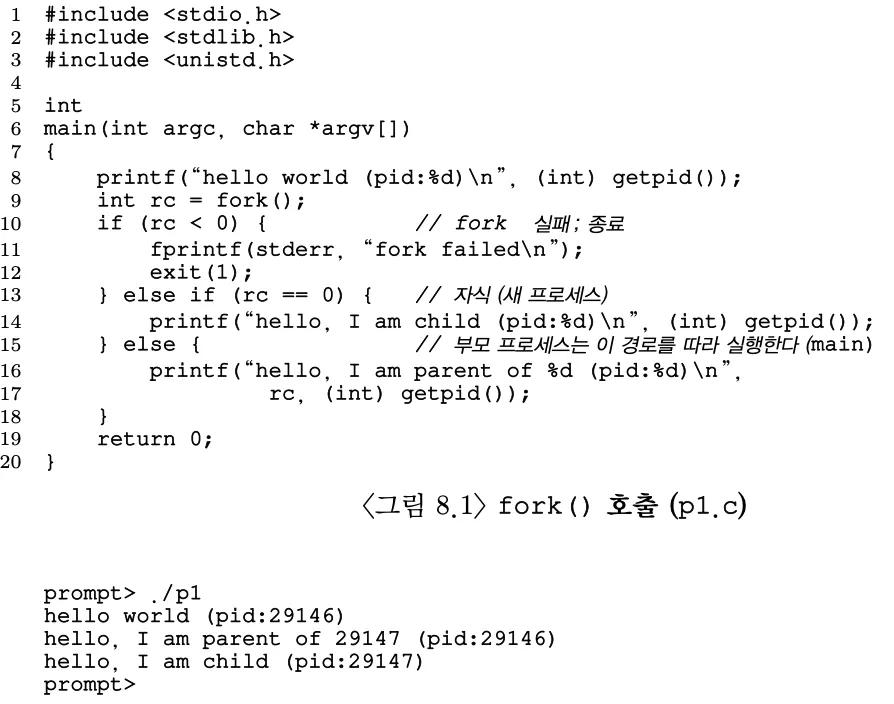
프로세스를 생성할 때 사용된다. 현재 실행중인 프로세스의 복사본을 생성한다. 운영체제가 새로운 프로세스를 생성하고 이 새로운 프로세스는 원본 프로세스의 메모리 공간을 복사하여 가지게 된다. 그러나 완전히 동일하지는 않다. 각각 고유한 주소 공간, 레지스터, PC 값을
2.OSTEP 4 - Process
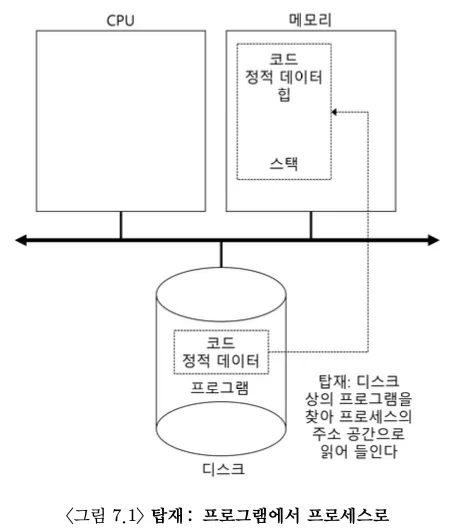
이 장에서는 운영체제가 제공하는 핵심 개념 중 하나인 프로세스(process)에 대해 논의한다. 일반적으로 프로세스는 실행 중인 프로그램으로 정의한다. 프로그램은 디스크 상에 존재하며 실행을 위한 명령어와 정적 데이터의 묶음으로, 이 명령어와 데이터 묶음을 읽고 실행하
3.OSTEP 6 - Direct Execution

운영체제는 여러 작업들이 동시에 실행되는 것처럼 보이도록 물리적인 CPU를 공유한다. 이를 CPU 시간을 나누어 돌아가면서 잠깐 잠깐 실행하는 방식을 통해 CPU 가상화를 구현한다.근데 이러한 가상화 기법을 위해서는 몇가지 문제를 해결해야 한다.성능 저하: 시스템에 과
4.OSTEP 7 - CPU Scheduling
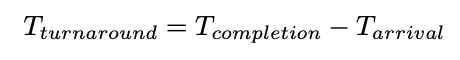
일련의 프로세스들이 실행하는 상황을 워크로드라고 부르기로 하자. 우리는 시스템에서 실행 중인 프로세스 혹은 작업에 대해 다음과 같은 가정을 한다.모든 작업은 같은 시간 동안 실행된다.모든 작업은 동시에 도착한다.각 작업은 시작되면 완료될 때까지 실행된다.모든 작업은 C
5.OSTEP 8 - Multi Level Feedback Queue (MLFQ)
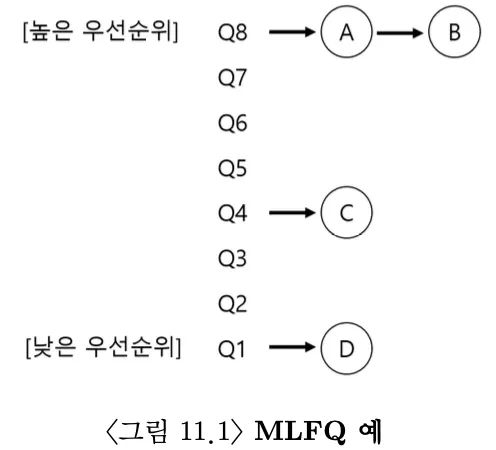
MLFQ가 해결하고자 하는 기본적인 문제는 두가지이다.짧은 작업을 먼저 실행시켜 반환 시간을 최적화한다. 운영체제는 실행시간을 미리 알 수 없다는 점을 고려해야 한다.대화형 사용자에게 응답이 빠른 시스템이라는 느낌을 주고 싶었기에 응답 시간을 최적화한다.프로세스에 대한
6.OSTEP 9 - Lottery Scheduling

이 장에서는 비례 배분(Proportional Share), 공정 배분(fair share)이라고도 하는 유형의 스케줄러에 대해 다룬다. 비례 배분은 스케줄러가 각 작업에게 정해진 비율로 CPU를 배분하는 것을 보장하는 것이 목적이다.비례 배분 스케줄리의 예시인 추첨
7.OSTEP 10 - Multi-CPU Scheduling
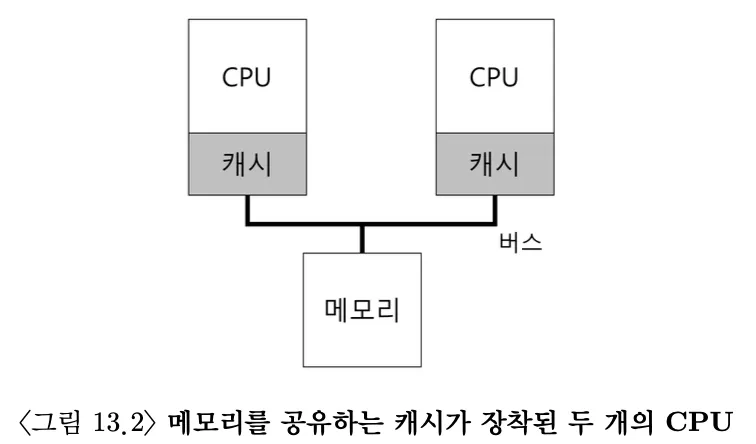
이 장에서는 멀티 프로세스 스케줄링의 기본을 소개한다. 더 자세한 내용은 이후에 병행성(concurrency) 부분에서 다루게 된다. 병행성 부분을 공부하고 다시 본다면 더 이해가 잘될 것이다.현재는 여러개의 CPU 코어가 하나의 칩에 내장된 멀티코어 프로세서가 어디에
8.OSTEP 13 - Address Space
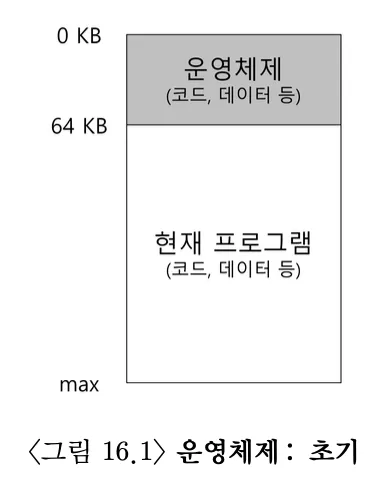
메모리 관점에서 초기 컴퓨터는 많은 개념을 사용자에게 제공하지 않았다.물리 메모리에 하나의 실행 중인 프로그램(프로세스)이 존재하였고. 쓰고 남은 메모리를 사용했다. 가상화는 거의 존재하지 않았다.여러 프로세스가 준비상태에 있고 운영체제는 이를 전환하면서 실행했다. 예
9.OSTEP 14 - Memory API

C 프로그램이 실행되면, 스택과 힙이라는 두가지 유형의 메모리 공간이 할당된다.스택(stack) 메모리메모리의 할당과 반환은 컴파일러에 의해 암묵적으로 이루어져, 자동 메모리라고도 불린다. 함수 안에서 변수를 선언하게 되면, 컴파일러가 함수가 호출될 때 스택에 공간을
10.OSTEP 15 - Address Translation

CPU 가상화 부분에서, 제한적 직접 실행(LDE)에 대해서 배웠다. 중요한 순간에 운영체제가 관여하여 하드웨어를 직접 제어한다. 메모리 가상화에서도 비슷한 전략을 추구한다. 가상화를 제공하는 동시에 효율성과 제어를 모두 추구한다.효율성을 위해 하드웨어의 자원을 사용한
11.OSTEP 16 - Segmentation
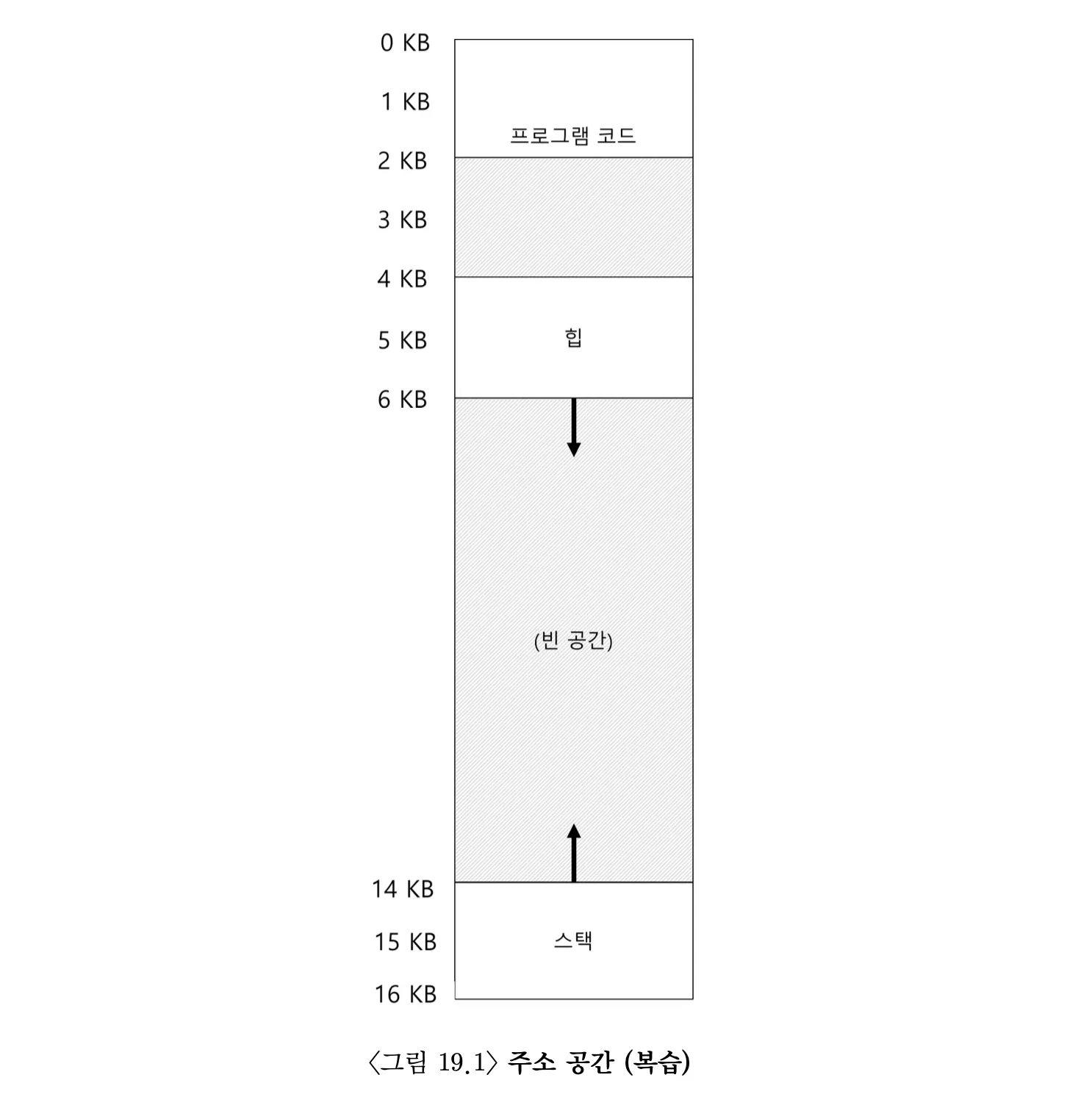
베이스와 바운드 레지스터만을 사용하는 주소공간 개념에서는, 힙과 스택 사이에 사용되지 않는 큰 공간이 존재한다. 사용되지는 않더라도 메모리는 차지하게 되는데, 메모리 낭비가 심하다고 볼 수 있다.주소 공간의 논리적인 세그먼트마다 base/bound 레지스터가 존재한다.
12.OSTEP 17 - Free Space Management

이 장에서는 메모미 가상화 논의에서 약간 우회하여 메모리 관리 시스템의 근본적인 측면을 논의한다. 메모리 관리 시스템이란 malloc()(프로세스 힙 페이지 관리)일 수도 있고, 운영체제(프로세스 주소공간의 일부 관리)일 수도 있다.특히, 빈 공간 관리에 초점을 둘 것
13.OSTEP 18 - Introduction fo Paging

운영체제는 거의 모든 공간 관리 문제를 해결할 때 두가지 중 하나를 사용한다.가변 크기의 조각들로 분할 (세그멘테이션) 그러나 다양한 크기로 분할하면서 공간에 대한 단편화가 많이 발생하고, 할당이 어려워진다. 동일 크기의 조각으로 분할 이번 장에서 배우게 될 Pa
14.OSTEP 19 - Translation Lookaside Buffer

페이징은 상당한 성능 저하를 가져올 수 있다. 페이지 테이블의 저장을 위해 큰 메모리 공간이 요구된다. 주소 변환을 위해 페이지 테이블의 정보를 읽어야하고, 페이지 테이블 접근을 위한 메모리 읽기 작업의 비용은 비용이 크다. 모든 load/store 명령마다 페이지 테
15.OSTEP 21 - Swapping: Mechanism
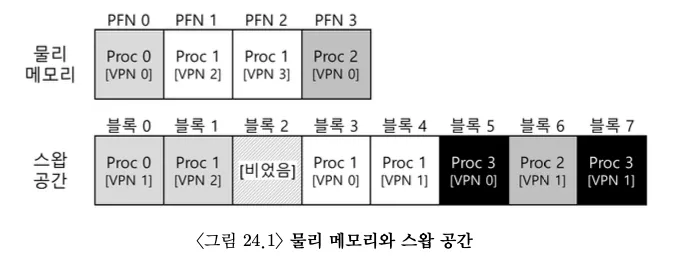
지금까지는 모든 페이지들이 물리 메모리에 존재하는 것을 가정했다. 하지만 큰 주소 공간을 지원하기 위해 OS는 현재는 크게 필요하지 않은 주소공간의 일부를 보관해 둘 공간이 필요하다. 이를 위해 메모리 계층에 레이어의 추가가 필요하다. 현대 시스템에서는 하드 디스크 드
16.OSTEP 27 - Thread API
핵심 질문: 쓰레드를 생성하고 제어하는 방법운영체제가 쓰레드를 생성하고 제어하는데 어떤 인터페이스를 제공해야 할까? 어떻게 이 인터페이스를 설계해야 쉽고 유용하게 사용할 수 있을까?멀티 쓰레드 프로그램 작성시, 가장 먼저할 일은 새로운 쓰레드의 생성이다. POSIX를
17.OSTEP 28 - Locks

프로그래머들은 소스코드의 임계 영역을 락으로 둘러서 그 임계 영역이 하나의 원자 단위 명령어인 것처럼 실행되도록 한다.다음과 같은 임계 영역이 있고, 락을 사용하기 위해 임계 영역을 감쌌다.락은 하나의 변수이기 때문에, 락을 사용하기 위해서는 락 변수를 먼저 선언해야한
18.OSTEP 29 - Locked Data Structures
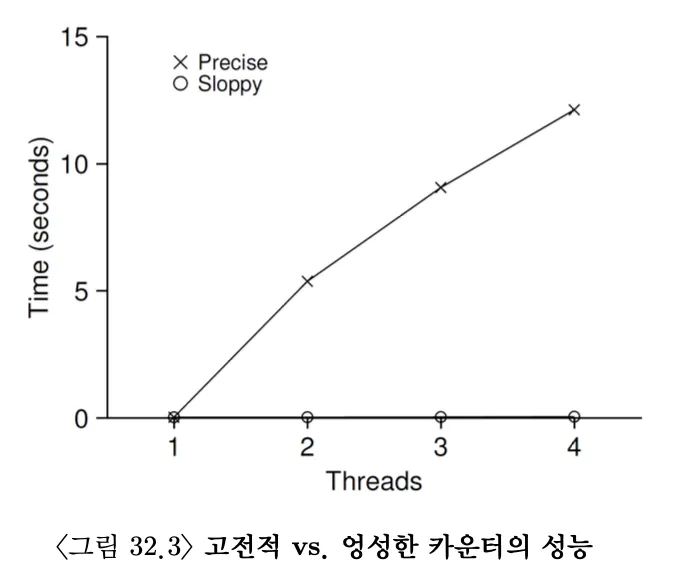
자료 구조에 락을 추가하여 쓰레드가 사용할 수 있도록 만들면, 그 구조는 thread safe하다고 할 수 있다.핵심 질문: 자료 구조에 락을 추가하는 방법어떤 방식으로 락을 추가해야 그 자료 구조가 정확하게 동작하게 만들 수 있을까? 더 나아가, 자료 구조에 락을 추
19.OSTEP 30 - Condition Variables
지금까지 락의 개념을 학습하면서 하드웨어와 운영체제의 적절한 지원을 통해 제대로 된 락을 만드는 법을 살펴보았다. 불행히도“락”만으로는 병행 프로그램을 제대로 작성 수 없다.쓰레드가 계속 진행하기 전에 어떤 조건이 참인지를 검사해야 하는 경우가 많이 있다. 예를 들면
20.OSTEP 31 - Semaphore
세마포어의 값을 1로 사용하는 것과, mutex_lock의 차이는 뭘까? 세마포어로 락을 사용할 수 있다면, mutex는 왜 사용하는걸까?Dijkstra와 그의 동료들은 모든 다양한 동기화 관련 문제를 한 번에 해결할 수 있는 그런 기법을 개발하고자 했다. 그리고 세마
21.OSTEP 32 - Concurrency Bugs
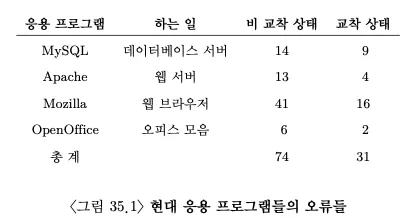
핵심 질문: 일반적인 병행성 관련 오류들을 어떻게 처리하는가병행성 버그는 몇개의 전형적인 패턴을 갖고 있다. 튼튼하고 올바른 병행 코드를 작성하기 위한 가장 첫 단계는 어떤 경우들을 피해야 할지 파악하는 것이다.복잡한 병행 프로그램에서 발생하는 오류들은 어떤 것들이 있