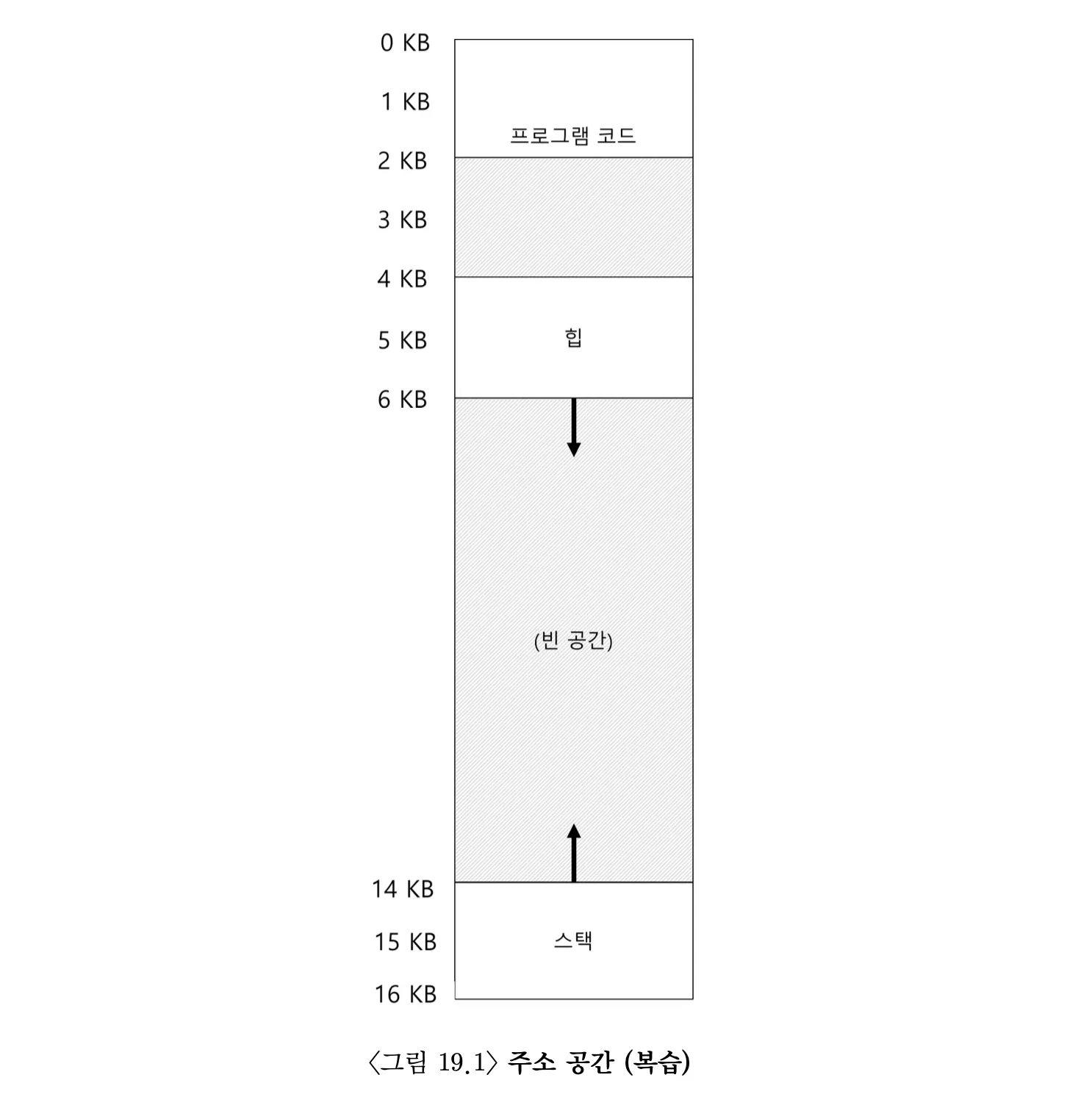
베이스와 바운드 레지스터만을 사용하는 주소공간 개념에서는, 힙과 스택 사이에 사용되지 않는 큰 공간이 존재한다. 사용되지는 않더라도 메모리는 차지하게 되는데, 메모리 낭비가 심하다고 볼 수 있다.
1. 세그멘테이션: base/bound의 일반화
주소 공간의 논리적인 세그먼트마다 base/bound 레지스터가 존재한다. 즉, 코드/스택/힙 세그먼트가 있다. 이를 통해 각 세그먼트를 서로 다른 위치에 배치할 수 있고, 사용되지 않는 물리 메모리 공간 차지를 방지할 수 있다.
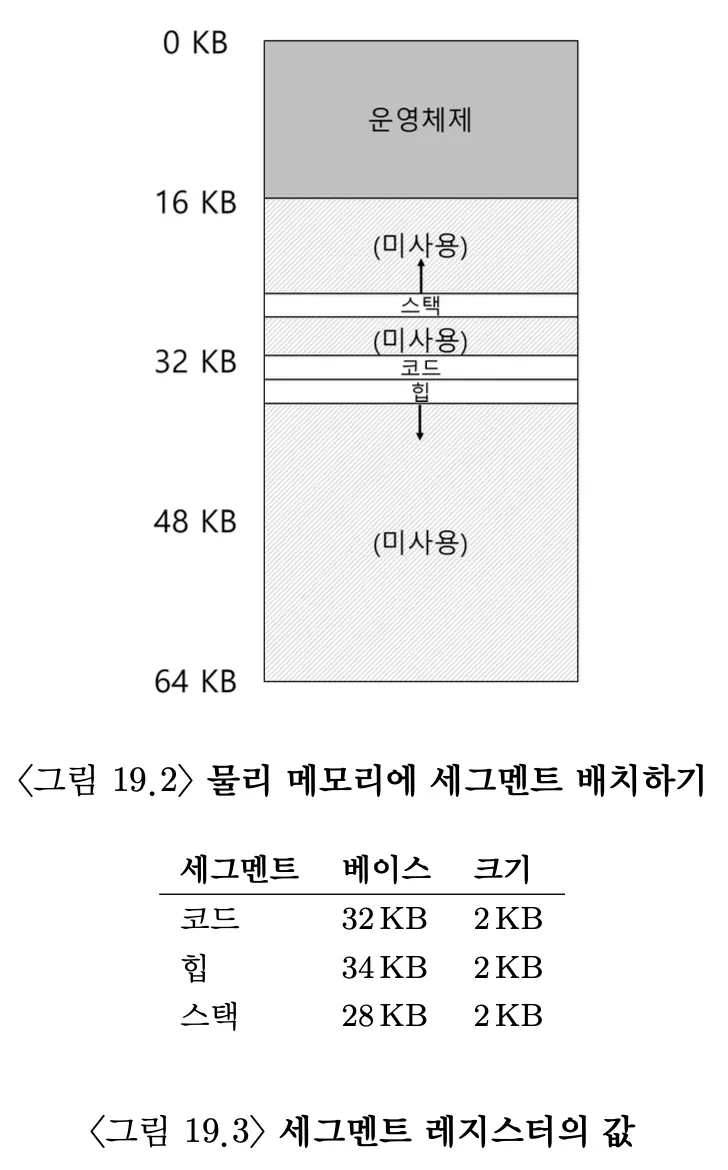
위 그림에서는 3개의 세그먼트가 있으니 3쌍의 베이스/바운드 레지스터 집합이 필요하다.
그림 19.1의 주소공간을 사용하여 주소 변환을 해보자. 가상 주소 100번지를 참조한다고 가정하자.
가상 주소 100번지는 코드 세그먼트에 속할때, 참조가 일어나게 되면 베이스 값(32KB)에 오프셋(100)을 더해 100+32KB인 32868이 된다. 이후 주소가 범위 내에 있는지 (100<2KB) 검사하고, 범위 내에 있을 경우 32868을 읽는다.
가상 주소 4200의 힙을 예시로 들어보자. 위와 같이 생각하면, 34KB + 4200이라고 생각하겠지만, 이는 틀렸다. 19.1에서 힙은 4KB로부터 시작하기 때문에 실제로 오프셋은 4200-4KB인 104이다. 이를 통해 주소 변환을 해보면 34KB+104 즉, 34920의 물리 주소로 변환된다.
힙의 마지막을 벗어난 잘못된 주소를 접근하게 된다면, 운영체제가 이를 감지하여 트랩을 발생시킨다. 이를 Segment fault 또는 Segment violation이라고 한다.
2. 세그먼트 종류의 파악
하드웨어 변환을 위해 세그먼트 레지스터를 사용한다. 하드웨어는 가상 주소가 어느 세그먼트를 참조하는지 그리고 그 세그먼트 안에서 오프셋은 얼마인지를 어떻게 알 수 있는가?
VAX/VAS 시스템에서는 다음과 같은 방법이 사용되었다. 세그먼트를 표시하기 위해 14비트를 사용한다. 최상위 2비트는 세그먼트의 종류를 명시하고, 나머지 12비트는 오프셋을 나타낸다.
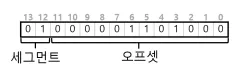
해당 예시를 보자. 세그먼트 비트는 01 이고, 이는 힙 세그먼트를 의미한다. 오프셋은 0000 0110 1000 로 104이다. 이를 기반으로 베이스/바운드 레지스터를 통해 물리 주소로 변환할 수 있다.
세그먼트를 파악하기 위해 하드웨어적 방법을 사용할 수도 있다.
- 만약 주소가 프로그램 카운터에서 생성되었다면(명령어 반입) 코드 세그먼트를 의미한다.
- 주소가 스택 또는 베이스 포인터에 기반을 둔다면 스택 세그먼트이다.
- 그 이외에는 힙 세그먼트.
3. 스택
스택 세그먼트는 다른 세그먼트와 차이가 있는데, 확장 방향이 반대라는 것이다. 이를 위해 확장 방향을 정해주기 위한 하드웨어를 추가로 사용한다. 예를 들어 주소가 커지는 방향으로 커지면 1, 작아지는 방향으로 커지면 0이다.
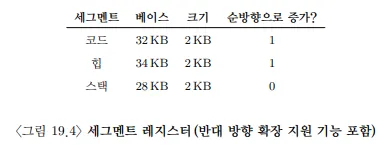
가상 주소 15KB에 접근하려 한다고 가정하자. 가상 주소를 이진 형태로 바꾸면 11 1100 0000 0000이다. 또한 세그먼트의 최대 크기는 4KB라고 가정하자
- 상위 2비트가
11이기 때문에 스택 세그먼트임을 알 수 있다. - 오프셋은
1100 0000 0000은 3KB이다. 올바른 음수 오프셋을 얻기 위해서는 세그먼트의 최대 크기를 빼야한다. 즉 음수 오프셋은 3KB-4KB인-1KB이다. - 스택 세그먼트의 베이스인 28KB에서 오프셋 -1KB를 더해준다. 변환된 물리 주소는
27KB가 된다.
바운드 검사는 오프셋의 절댓값을 이용하여 검사한다.
4. 공유 지원
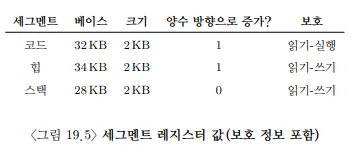
세그멘테이션 기법의 발전에 따라, 메모리 절약을 위해 주소 공간들 간에 특정 메모리 세그먼트를 공유하는 것이 유용하다는 것을 알게되었다. 특히, 코드 공유가 일반적이며, 현재까지도 많은 시스템이 사용중인 방법이다.
공유 지원을 위해, 하드웨어에 protection bit의 추가가 필요하다. 읽기 전용 비트의 경우 공간을 독립성을 유지하면서 여러 프로세스가 주소 공간의 일부를 공유할 수 있다.
5. 소단위 대 대단위 세그멘테이션
지금까지 논의한 것처럼, 코드/스택/힙 세그먼트로 나누는 방식을 대단위 세그멘테이션이라고 부른다. 주소 공간을 비교적 큰 단위로 분할하기 때문이다.
일부 초기 시스템은 주소 공간을 작은 크기의 공간으로 잘게 나눌 수 있었기 때문에, 소단위 세그멘테이션이라고 부른다. 많은 수의 세그먼트들을 관리하기 위해서 세그멘트 테이블 같은 하드웨어 자원을 이용했다.
6. 운영체제의 지원
세그먼트 방식은, 시스템이 각 주소 공간 구성 요소를 세그먼트별 물리 메모리로 재배치하기 때문에 기존에 하나의 베이스/바운드 쌍이 존재하는 방식에 비해 물리 메로리 공간을 엄청 절약할 수 있다. 즉, 스택과 힙 사이의 공간에 물리 메모리를 할당할 필요가 없어졌다는 뜻이다.
이를 위해 두가지 문제를 고민해야한다.
- 문맥 교환 시 세그먼트 레지스터의 저장과 복원
- 미사용 중인 메모리 공간의 관리
일반적으로 생길 수 있는 문제는, 물리 메모리가 빠르게 작은 크기의 빈 공간들로 채워진다는 것이다. 이 작은 빈 공간들에는 새롭게 생겨나는 세그먼트를 할당하기에는 너무 작고, 기존 세그먼트를 확장하기에도 별로다. 이를 외부 단편화라고 한다.
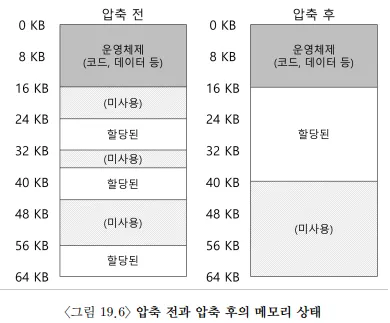
왼쪽 그림에서 24KB의 새로운 세그먼트를 할당하고 싶다고 가정해보자. 미사용 공간의 크기는 24이지만, 8씩 3개로 나뉘어져 있어, 24KB가 들어갈 공간이 없다.
간단한 해결 방법은 압축이다. 세그먼트를 한쪽 방향으로 몰아넣어 여유 공간을 만든다. 세그먼트들은 연속된 공간에 넣기 위해 복사가 일어나는데, 메모리에 부하가 크고 많은 프로세서 시간을 사용하기 때문에 압축의 비용이 많이 든다.
빈 공간 리스트를 관리하는 알고리즘을 사용하는 방법이 있다. 최적/최악/최초 적합, 버디 알고리즘 등 다양한 방법이 존재한다.
