자료구조 B+Tree
쿼리 성능을 최적화하기 위해서는 B+Tree 자료구조를 이해하는 것이 시작입니다.
(a, b, c) 컬럼으로 구성된 인덱스가 있을 때 a, b 정렬은 인덱스를 타고 a, c 정렬은 못타고...
이런식으로 외우는건 큰 도움이 되지 않습니다.
mysql(innodb)의 테이블과 인덱스 데이터는 모두 트리 구조로 저장됩니다.
하나의 테이블은 하나의 트리로, 하나의 인덱스도 하나의 트리로 저장됩니다.
(파티셔닝 된 테이블은 각 파티션별로 나눠집니다.)
어떤 테이블에 (a, b, c) 컬럼으로 구성된 인덱스 idx1이 있습니다.
아래는 idx1 인덱스의 트리 구조 예시입니다.
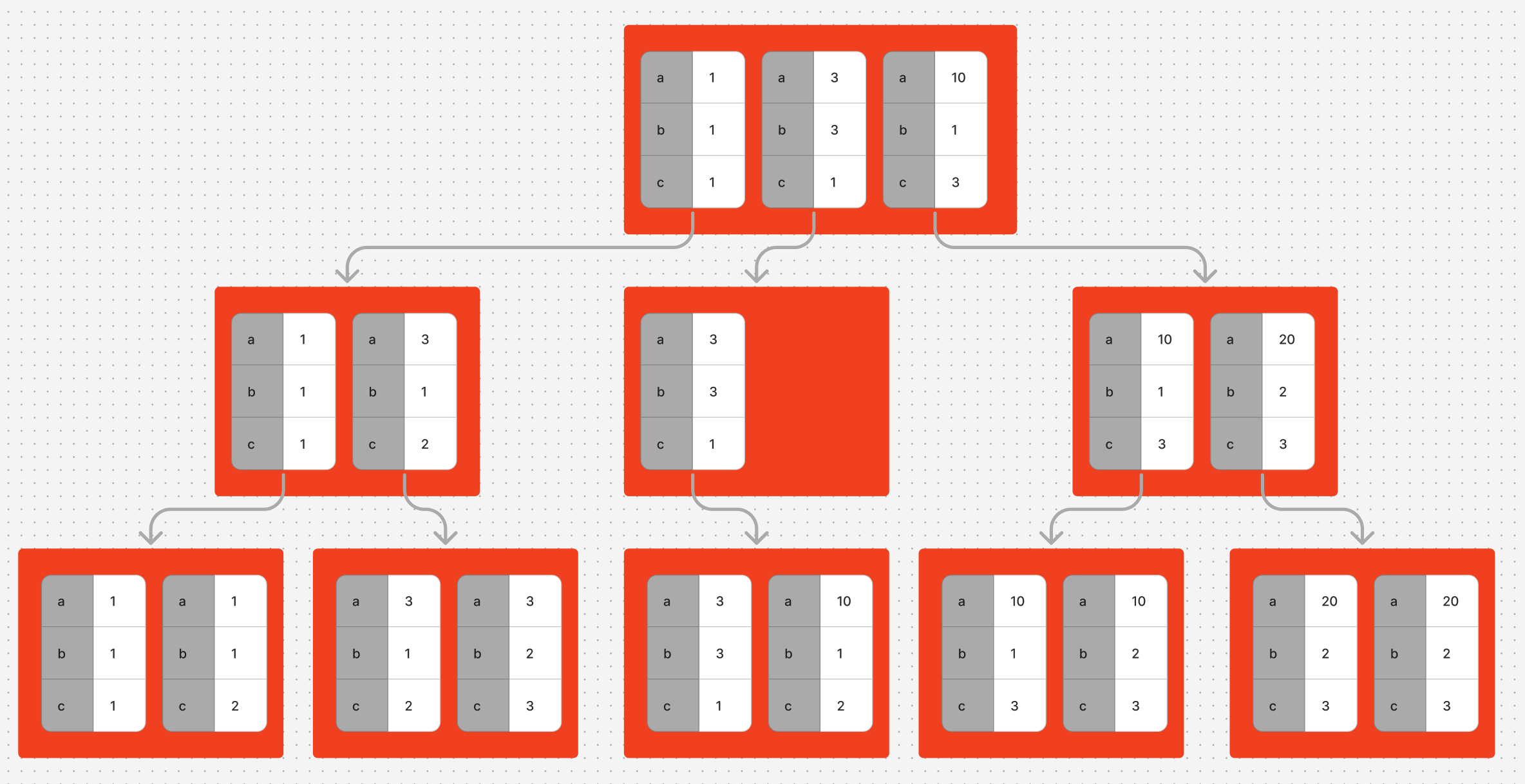
빨간 사각형이 하나의 노드 입니다.
하나의 노드에 여러개의 값이 들어있습니다.(실제론 더 많습니다)
리프노드는 현재 테이블에 저장된 모든 행의 a,b,c 의 값을 정렬된 채로 갖고 있습니다.
위 이미지는 행이 10개 저장된 테이블의 인덱스 입니다.
자식노드가 있는 루트노드와 중간노드는 자식이 갖고있는 최소값과 자식노드의 위치정보를 갖고 있습니다.
중간 노드 중 가장 왼쪽에 있는 노드는 자식 노드가 두개이며 두 자식 노드의 (a,b,c)의 최소값이 (1,1,1)과 (3,1,2) 입니다.
수직탐색과 수평탐색
인덱스 트리에서 (a,b,c)가 (10, 1, 2)인 행을 찾는 과정을 보겠습니다.
루트노드에서 시작해서 자식노드 3개 중에 (a, b, c)가 (10, 1, 2)보다 작은 값 중 최대값을 갖는 노드를 찾습니다.
(1,1,1), (3,3,1) (10,1,3) 중 위 조건에 맞는 값은 (3,3,1) 입니다.
해당 노드에서도 마찬가지로 (10, 1, 2)보다 작은 값 중 최대값인 노드를 찾습니다.
(3, 3, 1) 노드로 이동했더니 해당 노드에 찾는 결과가 있습니다.
B+Tree의 특징은 각 노드가 바로 이전과 다음 노드로 갈 수 있도록 위치정보를 갖고 있습니다.
(10, 1, 2)를 찾은 후 오른쪽 노드로 가서 최소값을 봤더니 (10, 1, 3) 입니다.
조건에 맞는 값이 아니므로 검색을 종료합니다.
위 예시에서 루트노드로부터 내려오며 찾는 과정을 수직탐색.
오른쪽(또는 왼쪽)으로 이동하며 다음값을 찾는 과정을 수평탐색 이라고 합니다.
인덱스의 pk
인덱스로 값을 조회해서 어떻게 테이블의 모든 데이터를 가져올 수 있는지 보겠습니다.
위 이미지에 누락됬지만 mysql의 모든 인덱스는 pk가 자동으로 뒤에 추가되어 생성됩니다.
(a, b, c) 컬럼으로 인덱스를 만든다면 실제로는 (a, b, c, pk) 인덱스가 생성됩니다.
pk가 복합키라면 (a, b, c, pk1, pk2 ...)로 생성됩니다.
인덱스에 이미 pk가 포함되도록 (a, pk1, b, c) 로 구성했다면 누락된 pk만 뒤에 추가됩니다
(a, pk1, b, c, pk2 ...)
모든 인덱스에 pk가 포함된다고 했으니 인덱스로 값을 찾으면 찾은 행의 pk를 알 수 있습니다.
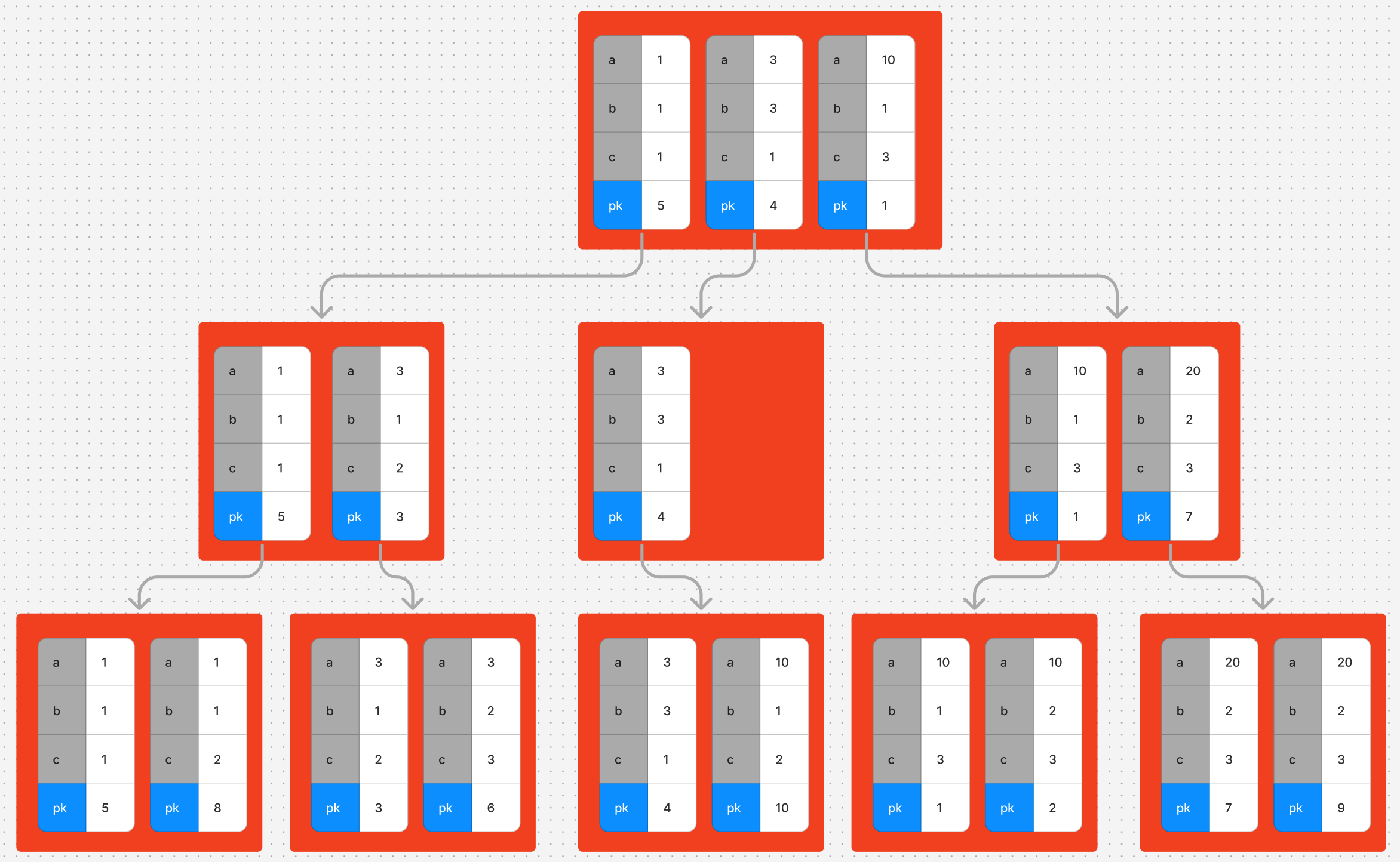
자동으로 추가된 pk를 포함한 인덱스 구조입니다.
리프노드 중 가장 오른쪽 노드에서처럼 a,b,c 의 값이 모두 같다면 pk를 기준으로 정렬됩니다.
위 예시에서 (10, 1, 2)를 가진 행의 pk는 10인 것을 찾았습니다.
테이블 트리
mysql의 innodb는 클러스터링 테이블로써 테이블도 하나의 트리로 구성됩니다.
테이블에 해당하는 트리는 인덱스와 조금 다릅니다.
리프노드엔 테이블의 모든 데이터가 들어있지만 그 위 노드들에는 pk만 존재합니다.
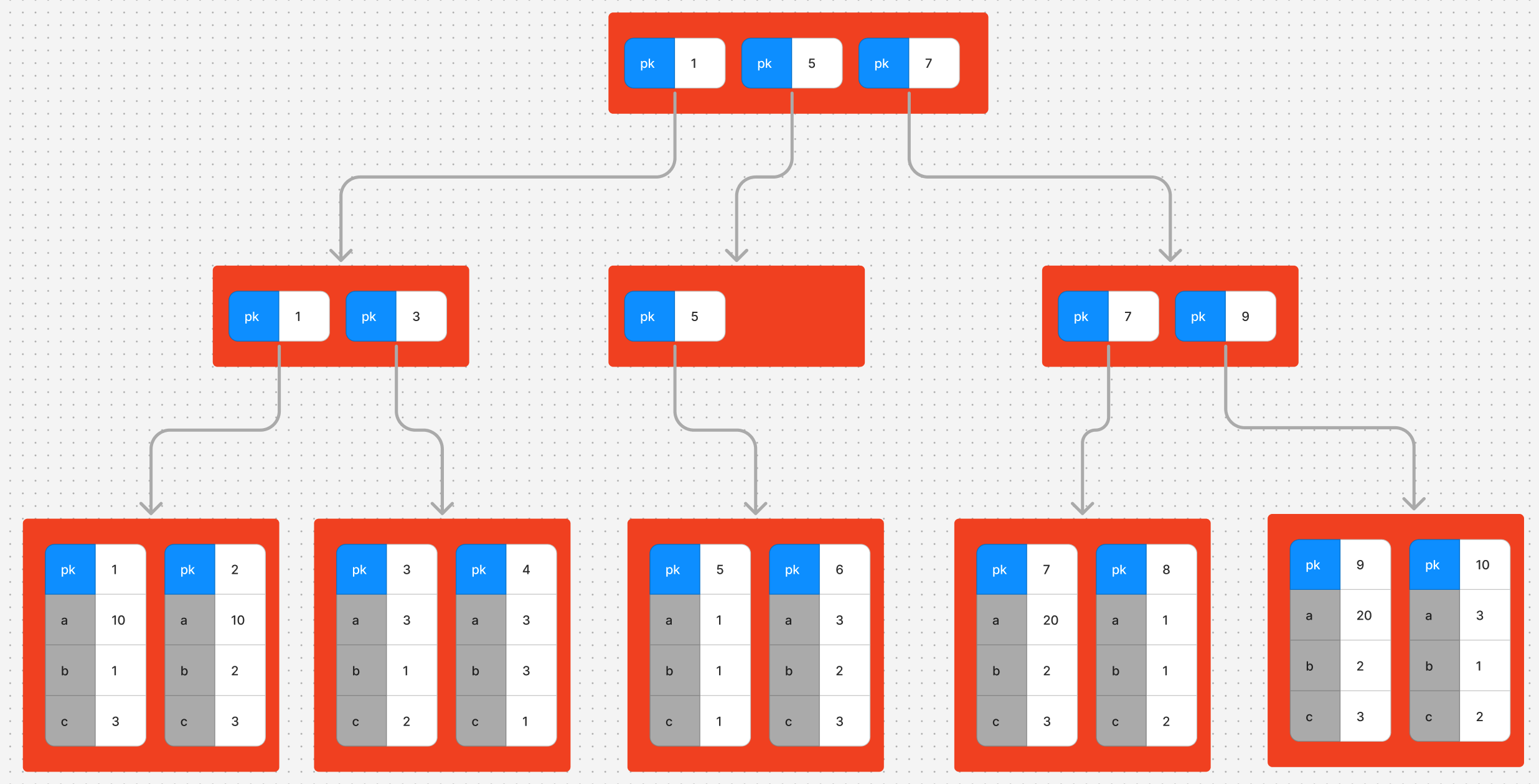
pk는 중복되지 않으므로 pk로만 정렬해도 중복되는 값이 없습니다.
pk가 10인 값을 찾는 과정은 인덱스와 동일합니다.
10보다 작은값 중 최대값을 가진 자식노드로 이동하는 것을 반복합니다.
루트노드의 자식노드가 pk를 1, 5, 7 갖고있으므로 7로 이동합니다.
자식노드가 7과 9를 갖고있으므로 9로 이동하면 pk가 10인 행이 존재합니다.
정리
SELECT *
FROM my_table t
WHERE t.a = 10
AND t.b = 1
AND t.c = 2이제 위 쿼리가 어떤식으로 인덱스를 이용해 값을 가져오는지 알 수 있습니다.
인덱스 idx1을 통해 (a, b, c)가 (10, 1, 2)인 인덱스 값을 수직탐색을 통해 찾습니다.
인덱스 데이터에서 pk가 10인 것을 확인하여 테이블 트리에서 수직탐색하여 데이터를 가져옵니다.
인덱스 트리에서 수평탐색을 통해 다음값으로 이동 후 (10, 1, 2)가 맞는지 확인합니다.
찾으려는 (10, 1, 2)가 아니므로 종료합니다.
다음 글로 이어집니다.
