
Flask-Ngrok API 연동
- 구글 코랩을 통해 KoBERT 모델링을 학습하는 데에는 성공
- 주어진 파이토치 모델을 CoreML 모델로 컨버팅할 때 BERT의 특징인 '미리 훈련된' 토크나이저를 사용할 수 없다는 점을 간과 → 주어진 입력 텍스트를 모델이 인식하기에 적절한 벡터로 '전처리'해야하지만 CoreML 단에서 불가능하다는 판단
- 백엔드 단의 간단한 API 함수를 통해 iOS 앱에서 텍스트 입력 및 출력을 하는 POST 구현
구현 목표
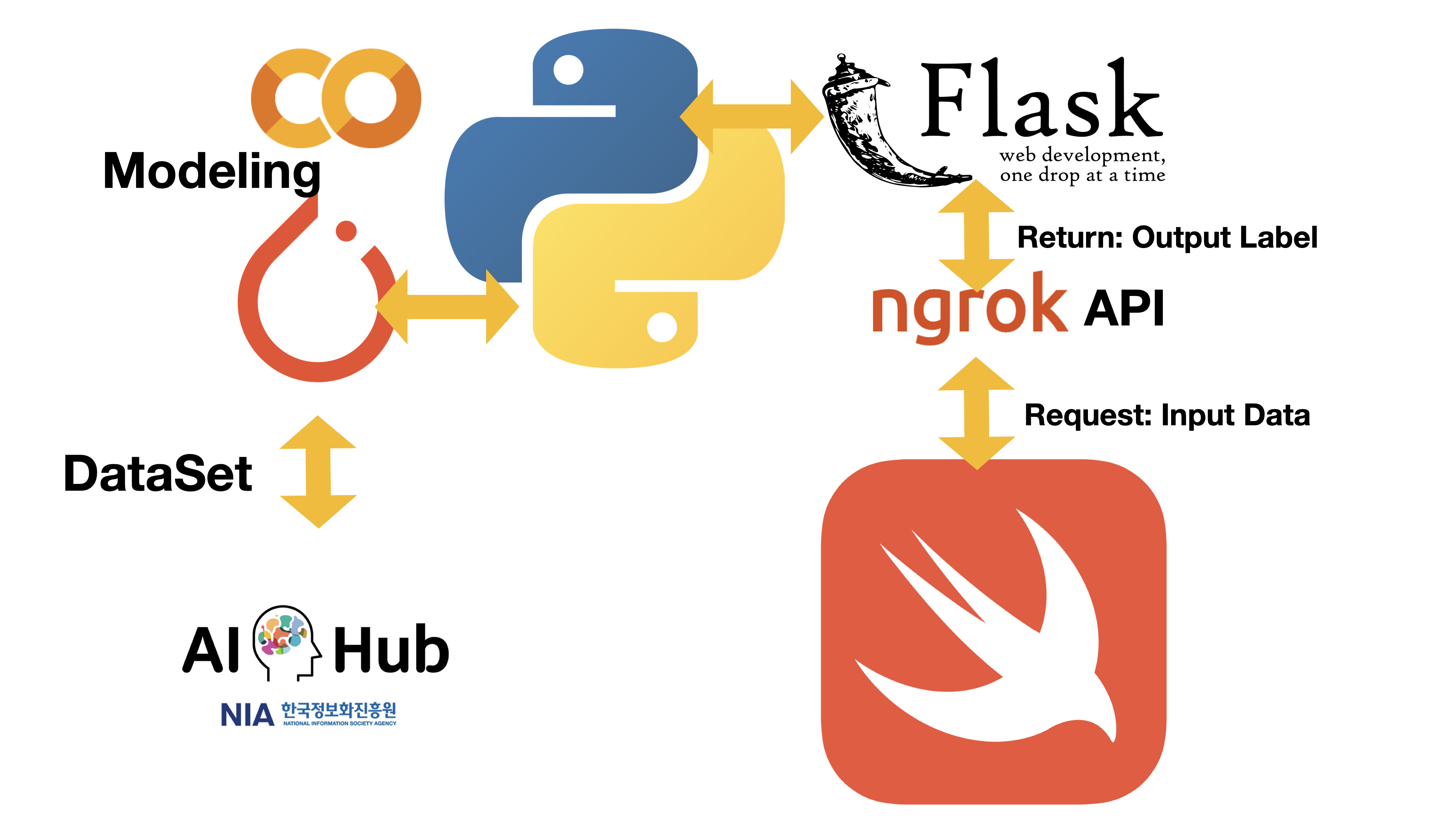
- NLP 분석 자체를 파이토치 모델이 전적으로 담당, 텍스트 입력 및 출력을 프론트 단인 iOS 앱에서 하기로 결정
- GPU를 사용하는 가상 머신 코랩에서 로컬 호스트로 서버 올리기 → 해당 서버를 외부(iOS 시뮬레이터 등)에서 접근하기 위한 네트워크 확보 필요
- API 구현 이후 해당 URL 주소를 사용하는 iOS의 데이터 서비스 담당 클래스 구현
구현 과정
Flask + Ngrok
model = torch.load(f'/content/drive/MyDrive/Colab Notebooks/SentimentAnalysisKOBert.pt')
model.eval()- 저장된 학습 완료 모델을 로드
!pip install flask-ngrok
!pip install flask==0.12.2
!pip install pyngrok==4.1.1
!ngrok authtoken '2E0itmXyrnKa7DoJmLdkZxE4Hk3_2hreUgB64mTNMJs6RjKfZ'
!wget https://bin.equinox.io/c/4VmDzA7iaHb/ngrok-stable-linux-amd64.tgz
!tar -xvf /content/ngrok-stable-linux-amd64.tgz
from flask import Flask, jsonify, request
from flask_ngrok import run_with_ngrok
import requests- 파이썬 위에서 로컬 호스트 서버를 올리는 flask
- 코랩이 가상머신을 사용하고 있기 때문에 해당 flask의 로컬 호스트로는 외부 환경에서 접근 불가능 → 네트워크를 밖으로 열어주는 ngrok 사용
app = Flask(__name__)
app.config['JSONIFY_PRETTYPRINT_REGULAR'] = False
run_with_ngrok(app) # Start ngrok when app is run
@app.route('/analysis', methods=['POST'])
def analysis():
content = request.get_json()
print(content)
text = content['content']
label = predict(text)
return jsonify({"label":str(label)})
if __name__ == '__main__':
app.run() # If address is in use, may need to terminate other sessions:
# Runtime > Manage Sessions > Terminate Other Sessions
import threading
threading.Thread(target=app.run, kwargs={'host':'0.0.0.0','port':80}).start() analysis주소를 통해POST메소드 리퀘스트 시 입력받은 텍스트를 파라미터로 넣고 예측 완료된 데이터의 라벨을 리턴하는 API 함수- JSON 타입을 사용하기 때문에
jsonify로 리턴
CustomDataService Class
import Foundation
import Combine
class CustomDataService: DataService {
var sentimentAnalysisPublisher: Published<SentimentModel?>.Publisher {
$sentimentAnalysis
}
@Published var sentimentAnalysis: SentimentModel? = nil
var cancellabes = Set<AnyCancellable>()
func fetchSentimentAnalysis(_ text: String) {
guard let urlRequest = getURLRequest(text) else { return }
URLSession.shared.dataTaskPublisher(for: urlRequest)
.subscribe(on: DispatchQueue.global(qos: .background))
.receive(on: DispatchQueue.main)
.tryMap(handleOutput)
.decode(type: SentimentModel.self, decoder: JSONDecoder())
.sink { completion in
switch completion {
case .finished:
print("SUCCESS")
break
case .failure(let error):
print(error.localizedDescription)
}
} receiveValue: { [weak self] returnedData in
guard let self = self else { return }
self.sentimentAnalysis = returnedData
}
.store(in: &cancellabes)
}
private func getURL() -> URL? {
let urlString = CustomAPI.sentiment.urlString
guard let url = URL(string: urlString) else { return nil }
return url
}
private func getURLRequest(_ body: String) -> URLRequest? {
guard let url = getURL(), let body = try? JSONSerialization.data(withJSONObject: ["content" : body]) else { return nil }
var urlRequest = URLRequest(url: url)
urlRequest.httpMethod = "POST"
urlRequest.setValue(CustomAPI.sentiment.clientContent, forHTTPHeaderField: CustomAPI.sentiment.clientHeaderContentType)
urlRequest.httpBody = body
return urlRequest
}
private func handleOutput(output: URLSession.DataTaskPublisher.Output) throws -> Data {
guard
let response = output.response as? HTTPURLResponse,
response.statusCode == 200 else { throw URLError(.badServerResponse) }
return output.data
}
}- 기존의 네이버 클로바 API를 담당하는 데이터 클래스와 동일한 구조
enum CustomAPI {
case sentiment
var clientHeaderContentType: String {
switch self {
case .sentiment: return "Content-Type"
}
}
var clientContent: String {
switch self {
case .sentiment: return "application/json"
}
}
var urlString: String {
switch self {
case .sentiment: [YOUR RETURNED NGROK URL]
}
}
}- ngrok 무료 사용 버전은 로컬 호스트를 원격으로 열 때마다 다른 url 주소를 제공하고 있기 때문에 계속해서
urlString을 변경해주어야 함
SentimentModel
struct SentimentModel: Codable {
let label: String?
let document: Document?
let sentences: [Sentence]?
var labelString: String {
guard let label = label else { return "" }
switch label {
case "0": return "기쁨"
case "1": return "불안"
case "2": return "당황"
case "3": return "슬픔"
case "4": return "분노"
case "5": return "상처"
default: return ""
}
}
var labelImageString: String {
guard let label = label else { return "" }
switch label {
case "0": return "funny"
case "1": return "anxious"
case "2": return "nervous"
case "3": return "sad"
case "4": return "anger"
case "5": return "hurt"
default: return ""
}
}
}- 네이버 클로바 API에서 사용했던 데이터 모델을 재활용
label프로퍼티 추가 → 기존의document,sentences등 클로바 API에서 필요한 데이터는 옵셔널 선언을 통한 JSON 디코딩 시 자동으로 널값으로 채우기labelString,labelImageString등 리턴받은 라벨 데이터를 사용하는 연산 프로퍼티 → 주어진 라벨이 어떤 감정인지, 감정 정보 및 이모티콘 정보 리턴

TextInput
if let sentimentAnalysis = viewModel.sentimentAnalysis {
if let document = sentimentAnalysis.document {
Text(document.sentiment)
.font(.headline)
.fontWeight(.semibold)
.withDefaultViewModifier()
}
Image(sentimentAnalysis.labelImageString)
.resizable()
.scaledToFit()
.frame(width: 200, height: 200)
Text(sentimentAnalysis.labelString)
.font(.headline)
.fontWeight(.semibold)
}- 텍스트 입력 뷰에서 리턴받은 데이터를 뷰에서 보여주는 코드를 다시 작성
- 클로바를 사용할 때에는
document를, 커스텀 모델을 사용할 때에는label연관 데이터를 뷰에 보여주기
구현 화면


생각보다 KoBERT가 주어진 문장을 잘 분석하는 것 같다. 지도 학습에 있어서 커스텀 모델의 장점은, 원하는 개수/종류의 라벨을 줄 수 있어서인 것 같다. 또한 BERT 모델을 특히 한국어를 분석할 때 사용할 수 있어서 의미 깊었다.
TODO
- 로컬 호스트 API 변경
- 코랩의 가상 머신 위에 올린 플라스크 서버를 임시로 사용하고 있기 때문에, 임의의 시점마다 API를 사용할 수 없다. 모델을 시험한다는 점에서는 현재와 같이 로컬 호스트를 사용할 수 있겠지만, 본격적인 앱을 구현할 때에는 상시적인 API를 쓸 수 있어야 한다.
- AWS 람다를 통해 비교적 간단한 API를 구현할 수 있을 것 같다. 하지만 AWS 람다에 올릴 수 있는 모델 크기 제한 때문에, 먼저 스토리지 크기가 큰 S3 버킷에 주어진 파이토치 모델을 올린 뒤(대략 500 MB 정도) API Gateway를 연결, POST 리퀘스트가 왔을 때 AWS 람다에서 S3 버킷의 모델을 로딩/예측 함수 사용/결과값 리턴하는 API 모델을 설계할 수 있다.
- 감성 분석의 정확도
- 첫 번째 고민은 모델 자체를 '어떻게 굴러가게 할지'에 관한 고민이었다면, 보다 직접적인 모델 관련 고민
- 800자 전후의 텍스트를 분석해야 하는 본 감정 분석 앱의 논리 상 위 테스트의 경우와 같이 '단문장' 감성 분석으로는 정확도가 떨어지는 이슈
- (1). BERT 모델 학습 시에 '여러 문장'을 학습하는 방법 (2). 주어진 여러 문장을 효과적인 '한 문장'으로 요약, 이후 이 '한 문장'의 감정을 예측하는 방법 등 여러 가지가 있을 것 같다.
- 문장의 개수라는 이슈뿐만 아니라 BERT 모델 자체의 학습량을 늘리는 것 역시 중요한 과제. 하지만 기쁨/분노 등 상세한 감정 라벨이 붙어 있는 한국어 데이터셋을 찾기 힘들다는 부차적인 문제
- 네이버 클로바 API 등 보다 (정확도가 높다고 생각되는) API 데이터를 바탕으로 감정 역추론도 할 수 있을 것 같다는 생각. 하지만 긍정/중립/부정 등 실수값으로 전달되는 클로바 감정 분석 데이터를 어떻게 원하는 기쁨/분노 등 상세한 감정으로 라벨링할 것인지 기준을 설계해야 한다는 어려움 존재

JUST DO IT