앙상블(Ensemble)이란?
- 여러 개의 모델을 조합하여 결과를 도출하는 방법입니다.
- 단일 강력한 모델보다 여러 개의 약한 모델을 조합해 정확도를 높이는 기법입니다.
- Bagging과 Boosting으로 나뉩니다.
- 아래와 같이 VotingClassifier을 이용해서 여러 개의 모델을 조합하는 방식도 앙상블(Ensemble)입니다. (Stacking, Blending도 포함)
ensemble_model = VotingClassifier(estimators=[
('random_forest', random_forest),
('decision_tree', decision_tree),
('xgboost', xgboost)
], voting='soft')Bagging : RandomForest
Boosting : XGBoost
Bagging
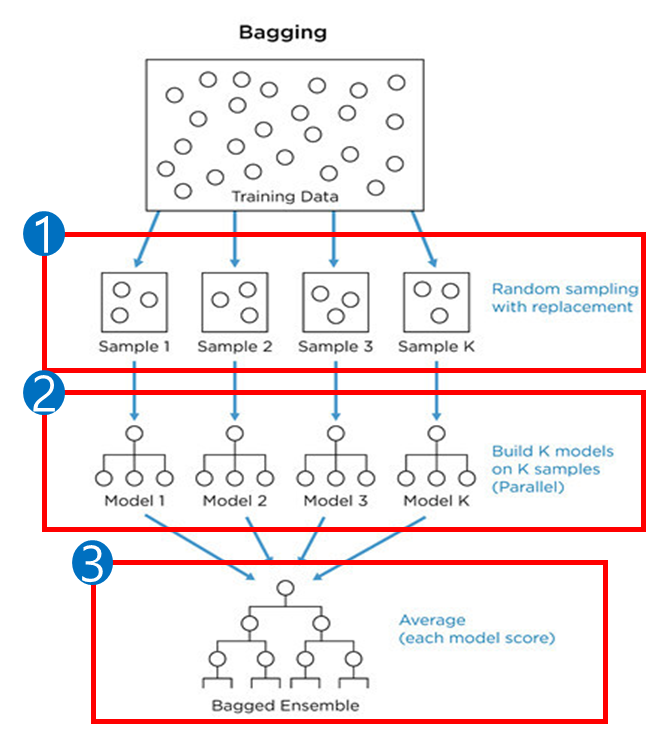
-
① 부트스트랩(복원 추출)을 사용하여 Train Data에서 무작위로 N개 데이터 선택합니다. 이때, 데이터 추출 비율(복원 추출 비율)은
max_samples(default = None, None이면 1.0을 의미)로 조정할 수 있습니다. -
② 병렬 처리를 통해 독립적인 여러 모델이 생성되며, 모델의 개수는
n_estimators(default = 100)로 결정합니다. -
③ 모든 모델이 생성된 후, 하드 보팅 또는 소프트 보팅을 통해 최종값이 산출됩니다.
-
하드 보팅의 경우
model.predict()를 사용해서 클래스 결괏값을 구하고,
소프트 보팅의 경우model.predict_proba()를 사용하여 클래스 확률값을 구합니다.
⭐ 하드 보팅(Hard Voting) : 과반수 투표를 통한 결과 도출.
⭐ 소프트 보팅(Soft Voting) : 모델의 평균을 계산하여 결과 도출.
- 위와 같은 배깅(Bagging) 기반 방식은 다수의 모델을 결합해 결괏값을 산출하는 방식으로, 과적합을 줄일 수 있습니다.
Boosting
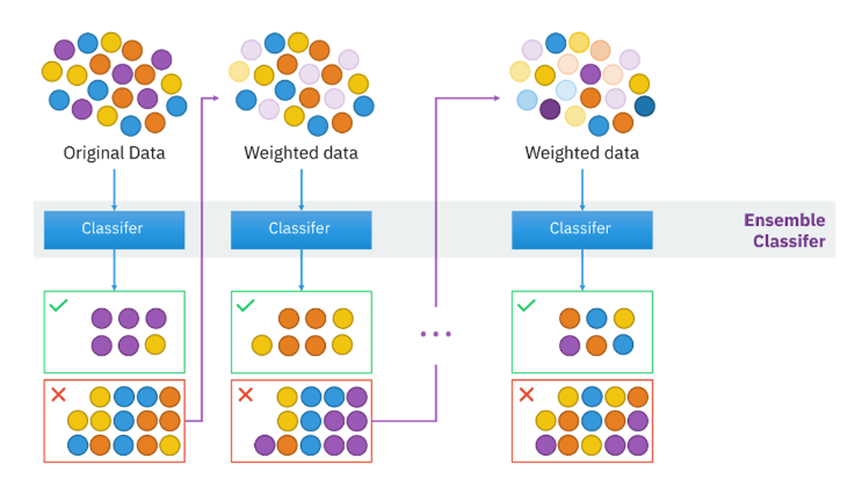
-
순차적으로 약한 모델을 추가하여 최종 모델을 생성합니다.
-
직전 모델의 잔차와 학습률을 결합하여 다음 모델에 가중치를 부여합니다.
-
잘못 분류된 데이터에 큰 가중치, 알맞게 분류된 데이터에 작은 가중치 부여하여 다음 모델이 더 잘 학습하도록 유도합니다.
-
훈련 데이터셋 기준으로 잔차 최소화를 목표로 학습하므로 모델의 성능이 향상될 수 있지만, 과적합이 발생할 수도 있습니다.
-
과적합 방지를 위한 파라미터들이 있습니다.
- XGBoost 기준
L1(Lasso), L2(Ridge)규제를 활용하여 가중치의 과도한 증가를 방지합니다.learning_rate(default = 0.3, [0, 1.0])를 조정하여 과적합을 방지할 수 있습니다.
L1(Lasso) : 가중치를 0으로 만들거나 최대한 0에 가깝게 만듭니다.
L2(Ridge) : 가중치를 0으로 만들지 않고 최대한 0에 가깝게 만듭니다.
⭐ 일부 특성이 중요하다면 Lasso 그렇지 않다면 Ridge
