-
Numpy란? (library는 대표적으로 pandas, numpy, matplotlib 등이 있음)
- Numerical Python의 약자로 Python에서 대규모 다차원 배열을 다룰 수 있게 도와주는 라이브러리
- 대부분의 데이터는 숫자의 배열이기 때문에 numpy로 이를 분석
- 반복문 없이 배열 처리 가능 > 반복문을 사용하는 파이썬의 리스트와 달리 빠른 연산을 지원하고, 메모리를 효율적으로 사용할 수 있다.
-
Numpy 사용하기
- import numpy as np #별칭 np로 부르며 사용하겠다는 의미
- ndarray : n차원의 배열 ex) np_arr = np.array(range(5) #[0 1 2 3 4]로 출력 / list는 ,로 구분하지만 ndarray는 공백으로 값을 구분
ex)type(ndarray) : class 'numpy.ndarray'로 출력.
-
배열의 기초
- list와 달리 array는 같은 데이터 타입(단일 데이터)만 저장 가능하다.
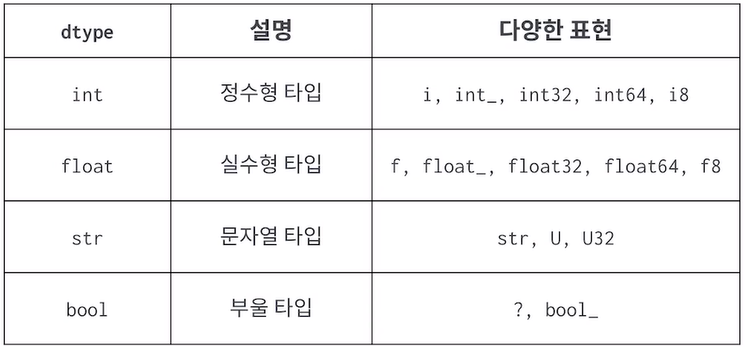
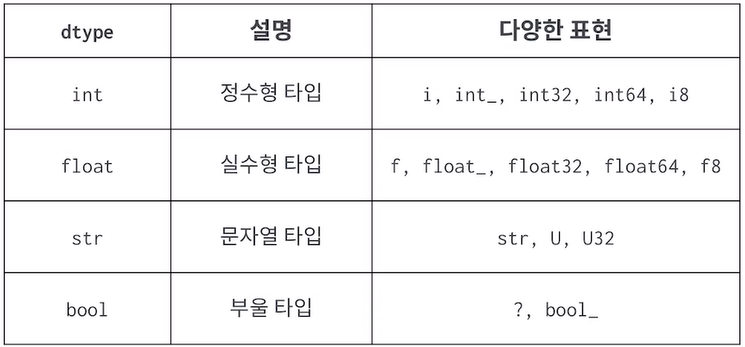
ex) arr = np.array([0,1,2,3,4], dtype=float)
print(arr) #[0. 1. 2. 3. 4.]으로 출력, .0일 때 0은 생략, data type모두 float으로 통일됨 - data type
- ndarray의 차원과 관련된 속성 : ndim & shape #n-dimension으로 차원을 구하는 함수
ex) list = [0,1,2,3]
arr = np.array(list) #list로 변환
print(arr.ndim) #1
print(arr.shape) #(4,) 4개의 행이 0개의 열, 이 때 0은 생략 - 배열의 길이는 행의 개수를 의미한다. <-> 행의 요소의 개수와 헷갈리기 쉬움.
- type(array) : array의 type으로 class 'numpy.ndarray'가 출력
array.dtype : array 내부의 원소의 data type으로 int64,int,float 등이 출력
- list와 달리 array는 같은 데이터 타입(단일 데이터)만 저장 가능하다.
-
indexing & slicing : 원하는 요소를 지정하기 위해 적절히 조합하여 사용
-
indexing : 데이터를 찾아내는 것
ex1) x = np.arrange(7)
print(x) #[0 1 2 3 4 5 6]
print(x[3]) #3
x[0] = 10
print(x) #[10 1 2 3 4 5 6]
ex2) x = np.arrange(1,13,1) #1부터 13까지 1간격의 array
x.shape = 3,4 #3열 4행을 의미
print(x) #[[1 2 3 4][5 6 7 8]
[9 10 11 12]] -
slicing : index값으로 배열의 일부분을 가져옴
ex) x = np.arrange(7)
print(x)
print(x[1:4]) #[1 2 3], 1이상 4미만을 의미한다
print(x[:3]) #[0 1 2], :은 처음부터 or 마지막까지를 의미한다. -
Boolean indexing : 배열의 각 요소의 선택 여부를 Boolean mask를 이용하여 지정하는 방식
- 조건에 맞는 데이터를 가져오고, 참/거짓 여부를 판별한다.
ex) x = np.arrange(7)
print(x<3) #[True True True False False False False] -
Fancy indexing : 배열의 각 요소 선택을 Index 배열을 전달하여 지정하는 방식
-

Department of Artificial Intelligence, EWHA