딥러닝 모델의 학습 방법
-
딥러닝 모델 : 다수의 Hidden Layer가 있는 모델을 의미
-
예측값과 실측값 간의 오차(Loss function)를 최소화하는 알고리즘을 적용
Loss function을 줄이면서 최적화를 진행 > Gradient descent(경사하강법)이용
Gradient 값은 각 가중치마다 정해지며, Back propogation을 통하여 구할 수 있다.
-
Forward propagation : 입력값을 바탕으로 출력값(예측값)을 계산하는 과정
Back propogation: Weight value를 바탕으로 Gradient를 계산하는 과정 -
Activate function ( 비선형 함수 )
Sigmoid, Relu 등이 있다.
-
딥러닝 모델의 학습 순서
1. 학습용 feature 데이터를 입력하여 예측값 구하기(Forward propagation)- 예측값과 실제값 사이의 오차 구하기(by using Loss function)
- Loss를 줄일 수 있는 가중치 업데이트(Back propogation)
- 1~3을 반복하며 Loss를 최소로 하는 가중치 구하기.
텐서플로우로 딥러닝 구현하기 - 데이터 전처리
-
텐서플로우

-
유연하고, 효율적이며, 확장성 있는 딥러닝 프레임워크, 다양한 디바이스에서 동작 가능 > Keras는 tensorflow에서 제공하는 고성능 라이브러리
-
Tensorflow 딥러닝 모델은 Tensor 형태의 데이터를 입력 받는다
Tensor : 다차원 배열로서 tensorflow에서 사용하는 독립적인 객체
데이터를 Tensor형태로 변환해준 후에 사용
import tensorflow as tf
import pandas as pd
import dataframe as df
# pandas를 사용하여 데이터 불러오기
df = pd.read_csv('data.csv')
feature = df.drop(columns = ['label']
label = df['label']
# tensor 형태로 변환
dataset = tf.data.Dataset.from_tensor_slices((feature.values, label.values))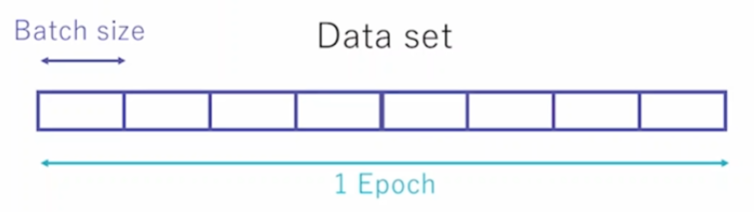
- Epoch : 한 번의 epoch는 전체 데이터 셋에 대해 한 번 학습을 완료한 상태
Batch : 나눠진 데이터 셋 각각을 의미 (보통 mini-batch라고 표현)
iteration : epoch을 나누어서 실행하는 횟수를 의미
ex) 총 데이터가 1000개, Batch size = 100
1 iteration = 100개 데이터에 대해서 학습
1 epoch = 100/Batch size = 10iteration
텐서플로우로 딥러닝 구현하기 - 모델 구현
-
Keras

: 텐서플로우의 패키지로 제공되는 고수준 API -
모델 클래스 객체 생성
tf.keras.models.Sequential()
모델의 각 Layer 구성
tf.keras.layer.Dense(units,activation)
#units : 해당 layer의 unit/node의 수, activation : 사용할 activation function
-
Input Layer의 입력 형태에 대한 정보가 필요
input_shape/ input_dim으로 설정 가능 -
compile mathode
모델 학습 방식을 설정하기 위한 함수
[model].compile(optimizer,loss)
#optimizer : 모델 학습 최적화 방법 ex)adam,sgd... / loss : 손실함수 설정
모델 학습을 위한 함수
[model].fit(dataset, epochs = 100) -
Evaluate & Predict
모델을 평가하기 위한 methode
[model].evaluate(x,y)
#x : 테스트 데이터, y : 테스트 데이터의 label
[model].predict(x)
#x : 예측하고자 하는 데이터
