이미지 처리를 위한 데이터 전 처리
-
기술 예시 : 얼굴 인식 카메라, 화질 개선, 이미지 자동 태깅
-
컴퓨터는 이미지를 각 픽셀 값을 가진 숫자 배열로 인식
-
이미지 전처리
- 모두 같은 크기를 갖는 이미지로 통일
가로 세로 픽셀 사이즈를 표현하는 해상도 통일
색을 표현하는 방식 통일(RGV, HSV, Gray-scale 등)
- 모두 같은 크기를 갖는 이미지로 통일
이미지 처리를 위한 딥러닝 모델
-
기존 다층 퍼셉트론 기반 신경망의 이미지 처리 방식
-
합성곱 신경망(Convolution Neural network)
- 작은 필터를 순환시키는 방식으로 이미지의 패턴이 아닌 특징을 중점으로 인식
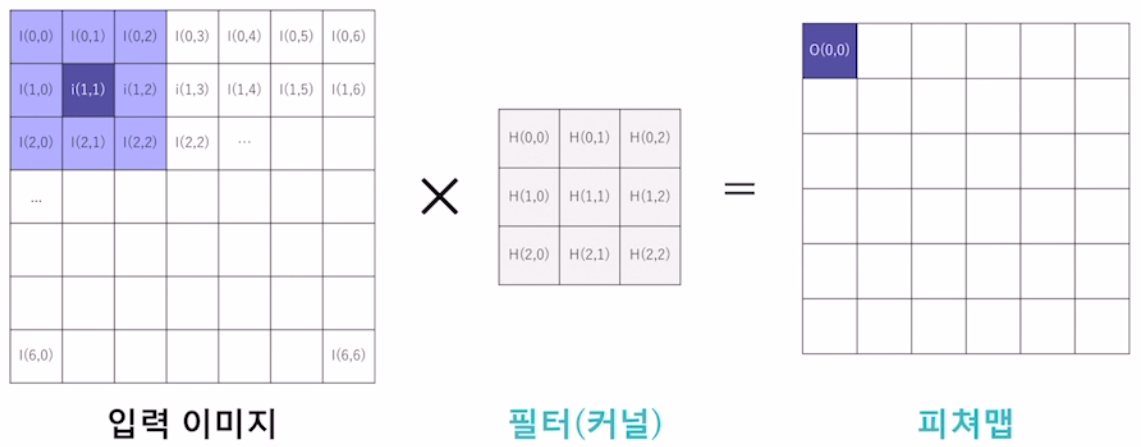 이미지에 어떤 특징이 있는 지 구하는 과정 ( filter가 이동하며 새로운 이미지를 생성 ) >> stride, zero padding 등의 개념이 사용됨.
이미지에 어떤 특징이 있는 지 구하는 과정 ( filter가 이동하며 새로운 이미지를 생성 ) >> stride, zero padding 등의 개념이 사용됨.Stride : 필터를 이동시키는 거리 설정
Padding : 원본 이미지의 상하좌우에 한 줄 씩 추가해서 모서리에 위치한 의미있는 값을 영향력있게 만듦- Pooling Layer : 이미지의 왜곡(노이즈)을 축소하는 과정 + 정보 압축
ex)Max Pooling(가장 많이 사용된다), Min Pooling, Average Pooling... - Softmax(activate function) : 마지막 계층(label수와 같은 node를 갖는)에 Softmax 활성화 함수 사용 > 각각을 확률값(0~1)의 수로 나타낸다.
(CNN + Pooling) + (FC + AF)
Convolution Layer 와 Pooling Layer : 특징을 추출 (Pooling Layer : noise를 줄인다)
Fully-Connected Layer + Activate Function : 분류Pooling Layer를 처리할 때마다 이미지의 크기가 크게 줄어들기 때문에 Layer 수가 많아져도 빠른 학습이 가능하다.
자연어 처리를 위한 데이터 전 처리
-
예시 : 기계 번역 모델 ex)papago..., 음성 인식
-
자연어 처리 과정
1. 자연어 전 처리 2. Word Embedding 3. Modeling -
자연어 전 처리 방법
- Noise Cancelling : 자연어 문장의 스펠링 체크 및 띄어쓰기 오류 교정
- Tokenizing : 문장을 Token(토큰)으로 나눔. 어절, 단어 등 목적에 따라 토큰을 다르게 정의 (모델링에 대입할 수 있도록 자연어로 쉽게 바꾸기 위한 방법)
- StopWord removal : 불필요한 단어를 의미하는 불용어 제거
- 자연어 데이터는 수치형 데이터로의 변환이 필요함 (Bag of Words)
- 토크 시퀀스 : 길이를 통일하기 위해 짧은 문장은 padding을 부여, 길이 차이가 많이 나면 그 데이터는 전 처리 과정에서 삭제.
자연어 처리를 위한 딥러닝 모델
RNN 이전의 딥러닝 모델
-
Word Embedding : Bag of Words에서 부여된 index로 정의된 토큰에 의미를 부여하는 방식, 단어의 특징을 나타내기 위해 사용
-
기존 MLP 모델의 한계 :2차원 data > n*1꼴의 1차원으로 바꾸어서 input. 이 과정에서 vector 내의 특징이 사라지고, 문장들 간의 관계 역시 무너지게 된다. >>RNN모델의 등장
RNN(Recurrent Neural Network) : 순환 신경망
-
퍼셉트론과 비슷하게 작동 (input 데이터를 받아 Y를 출력 ), input data는 embedding data가 벡터 형태로 입력
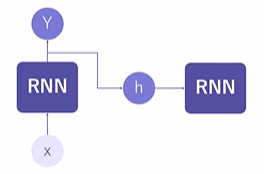
-
출력 값을 두 갈래로 나뉘어 신경망에게 '기억'하는 기능을 부여, 다음 input data 입력시 이전 데이터가 함께 고려되며 학습
- 최종 데이터는 Fully connected layer를 통해 판단
Summary
- Embedding : 자연어 전처리를 통해 정리된 데이터의 특징을 추출
- RNN : 앞서 사용된 토큰에 대한 y값을 다음 training에 함께 고려하여 학습
- Activation function : 최종 데이터 처리 후 label 출력
