
제로베이스 첫번째 EDA 로, 서울시 지역별 인구현황과 CCTV 보유 개수의 Line Chart 를 그려볼 것이다.
전반적으로 어떻게 이 경향성이 잘 드러나게 효과적으로 시각화할 것인지 기본기를 다져보는 것이 목표다.
데이터 확보
서울시 열린 광장 사이트에서 open API 를 통해 두가지 데이터를 받아왔다.
# csv 파일 읽어오기
CCTV_seoul = pd.read_csv('../data/01. Seoul_CCTV.csv', encoding='utf-8')✅ encoding = ‘utf-8’ ✅
✅ encoding = ‘cp949’ ✅
오류가 발생하거나, 잘 안불러와진다면 위의 encoding 방식을 시도해보자.
# excel 파일 읽어오기
pop_seoul = pd.read_excel(
'../data/01. Seoul_Population.xls',**header=2**, **usecols=**'B, D, G, J, N'
)✅ header ✅
몇 번째 행을 header 로 읽어올 것인지 선택할 수 있다.
✅ usecols ✅
어떤 칼럼을 사용할 것인지 선택할 수 있다.
필드 이름 정리해주기
# cctv 데이터의 '기관명' 필드 이름을 '구별' 로 바꿔주자.
CCTV_seoul.rename(
columns={'기관명':'구별'}, inplace=True
)
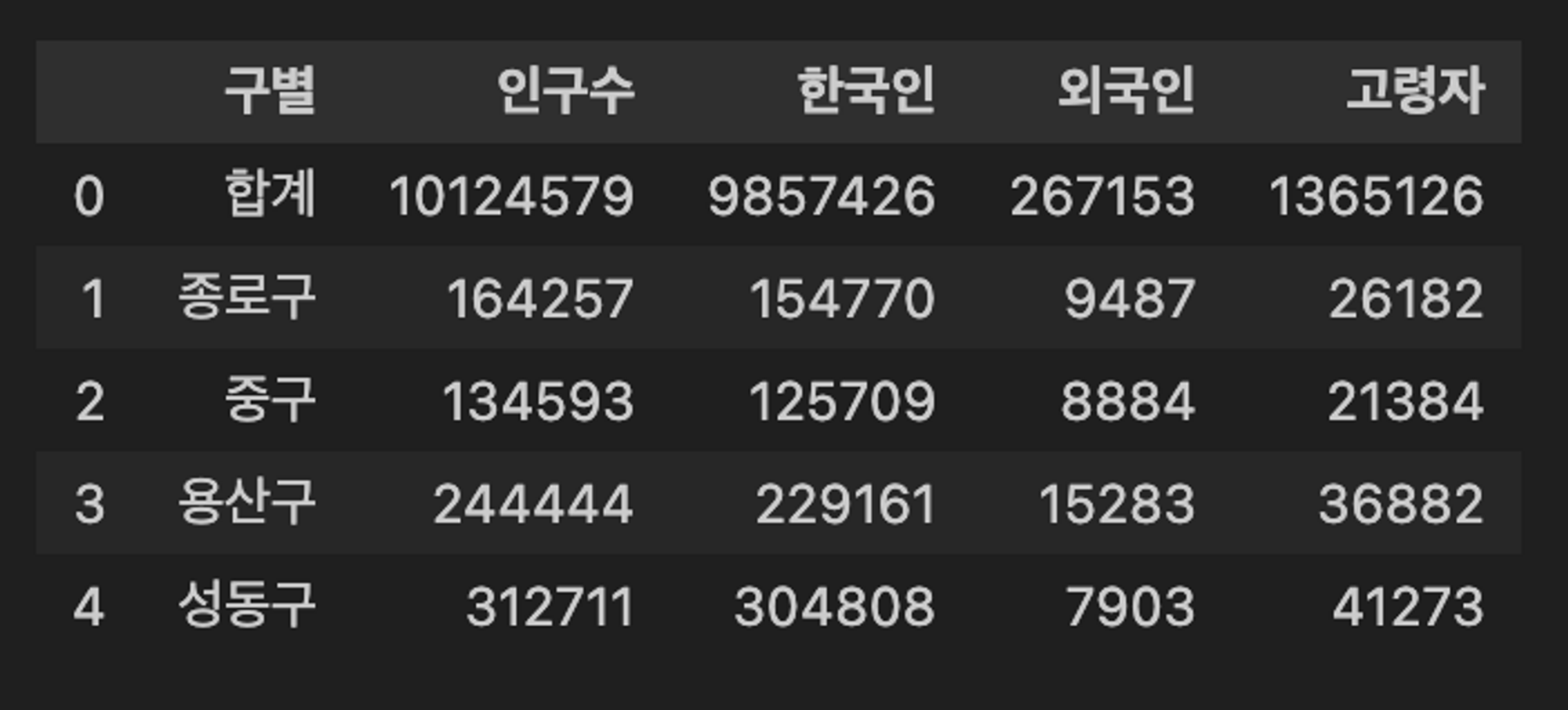
# 인구 데이터의 모든 필드 이름을 바꿔주자.
pop_seoul.rename(columns={
pop_seoul.columns[0] : "구별",
pop_seoul.columns[1] : "인구수",
pop_seoul.columns[2] : "한국인",
pop_seoul.columns[3] : "외국인",
pop_seoul.columns[4] : "고령자",
}, inplace = True
)
데이터 정리
CCTV 데이터 정리
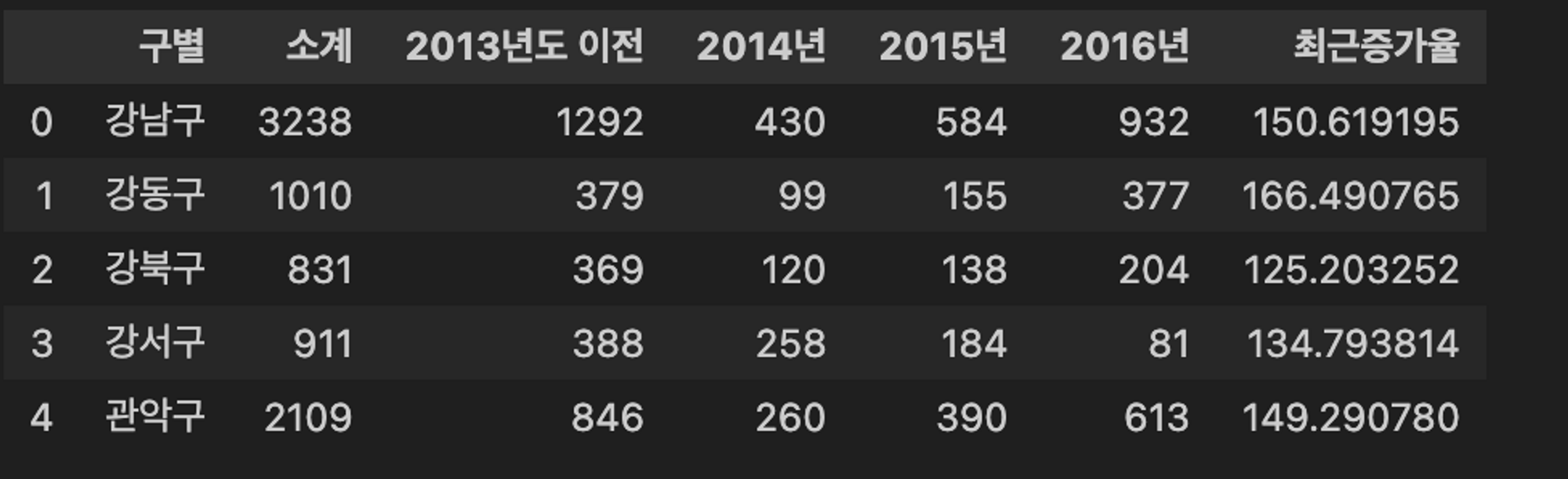
- 최근 3년간(2014 ~ 2016)의 CCTV 대수가 이전 대수에 비해 얼마만큼 증가했는지 증가율 변수 생성
CCTV_seoul['최근증가율'] = (
(CCTV_seoul['2014년'] + CCTV_seoul['2015년'] + CCTV_seoul['2016년']) / CCTV_seoul['2013년도 이전'] * 100
)
인구 데이터 정리
# 맨 처음 합계 행 데이터를 삭제한다.
pop_seoul.drop([0], inplace=True)
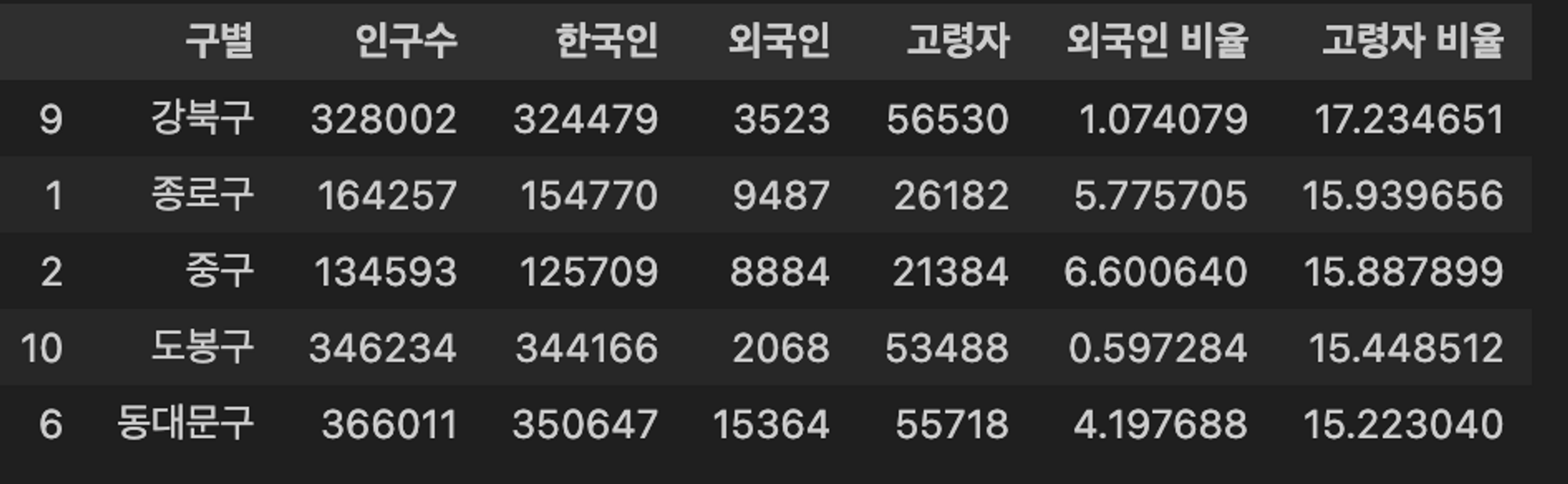
# 외국인 비율, 고령자 비율 필드를 만든다.
pop_seoul['외국인 비율'] = pop_seoul['외국인'] / pop_seoul['인구수'] * 100
pop_seoul['고령자 비율'] = pop_seoul['고령자'] / pop_seoul['인구수'] * 100
데이터 결합
- pd.merge 두 데이터프레임의 칼럼이나 인덱스를 기준으로 병합한다. 기준이 되는 인덱스나 컬럼을 ‘키’ 라고 부른다. 당연히 해당 키는 두 데이터프레임에 모두 있어야 한다. (이름이 동일해야 됨) default : inner join 이다. → how 인자 값을 ‘left’, ‘right’ ,’outer’ 등으로 설정할 수 있다.
# 두 데이터를 inner join 하자. '구별' 을 공동 칼럼으로 한다.
data_result = pd.merge(CCTV_seoul, pop_seoul, on='구별')
# 연도 컬럼을 삭제하자.
data_result.drop(['2013년도 이전','2014년','2015년','2016년'], axis=1, inplace=True)# '구별' 필드를 행 인덱스로 설정하자.
data_result.set_index('구별', inplace=True)
# 인구수 대비 CCTV 비율 필드를 만들자.
data_result['CCTV비율'] = data_result['소계'] / data_result['인구수'] * 100
# CCTV 비율을 기준으로 내림차순 정렬하자.
data_result.sort_values('CCTV비율').head()시각화
matplotlib 기초
import matplotlib.pyplot as plt
from matplotlib import rc
rc('font', family='AppleGothic') # 한글 폰트 설정
plt.rcParams['axes.unicode_minus'] = False # 마이너스 부호때문에 한글이 깨질 수가 있어 주는 설정
%matplotlib inline인구수를 구별로 막대 그래프 시각화하기
data_result['인구수']**.plot**(**kind='barh'**, figsize=(10,10))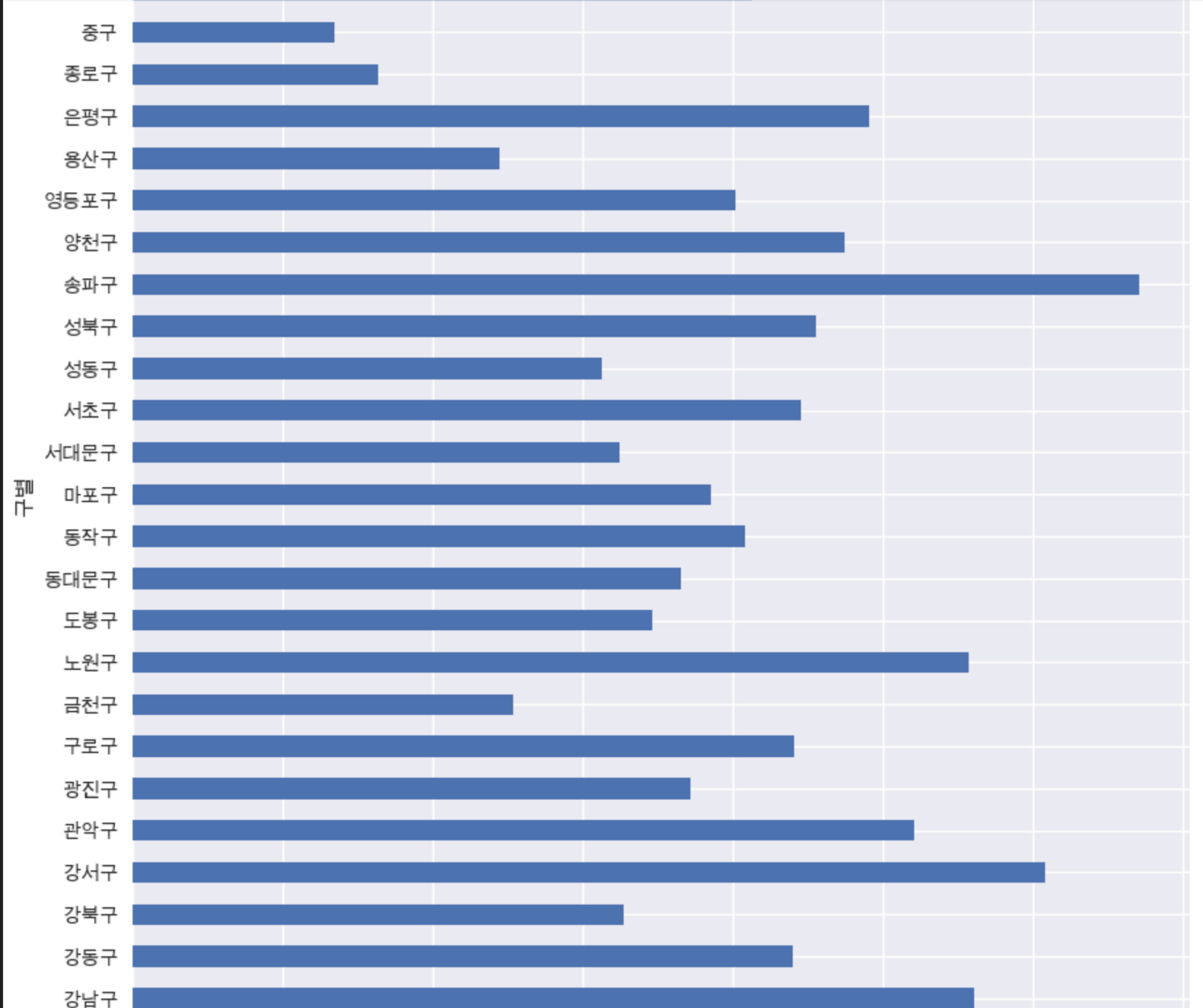
cctv 보유대수를 구별로 막대 그래프 그리기
data_result['소계'].plot(kind='barh', grid=True, figsize=(10,10));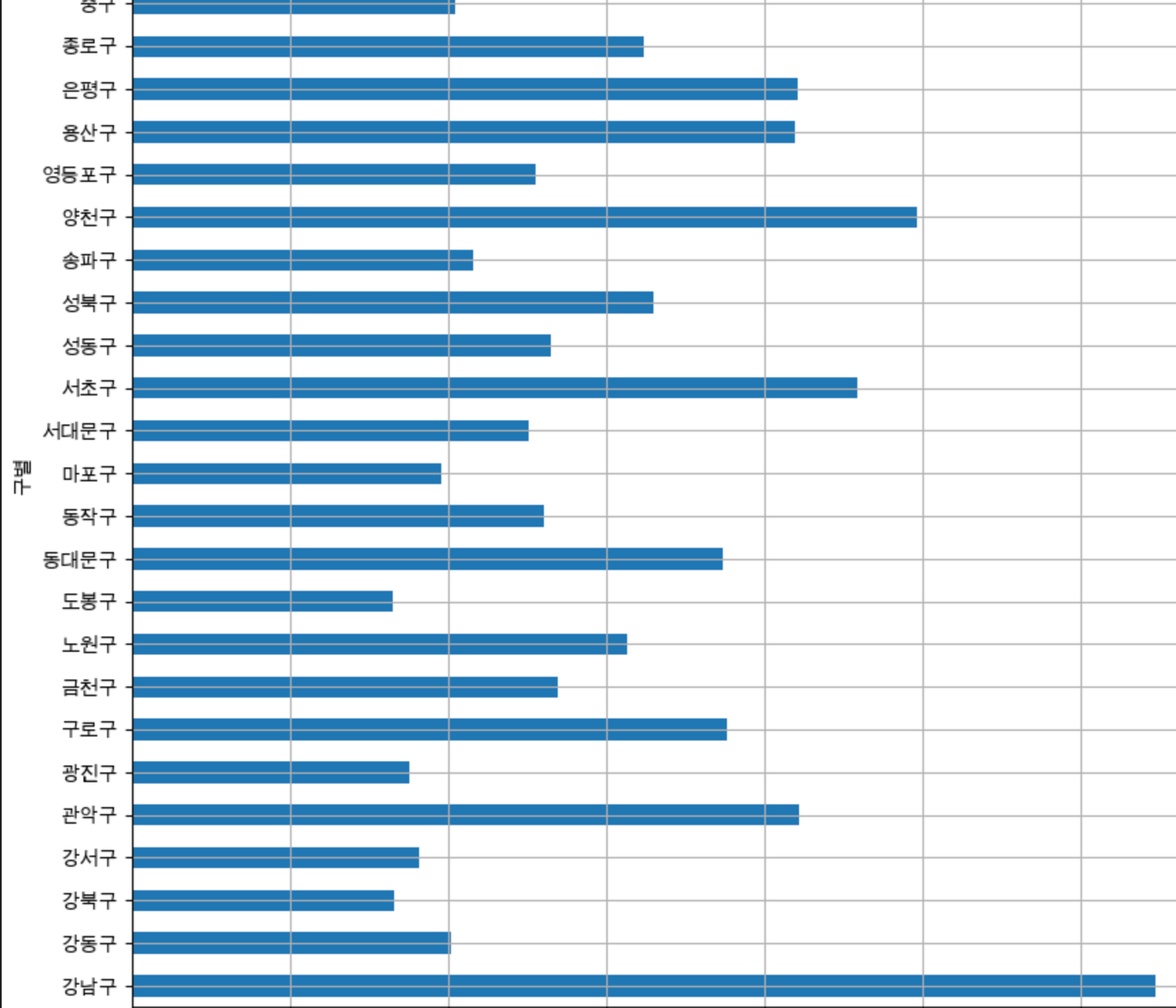
# CCTV 보유대수 막대 그래프
def drawGraph():
**plt.style.use('seaborn') # seaborn 스타일 이용하기**
plt.rcParams['font.family'] = 'AppleGothic' # 한글 폰트 설정
data_result['소계'].sort_values().plot(
kind='barh', grid=True, title='가장 CCTV가 많은 구', figsize=(10,10));
drawGraph()
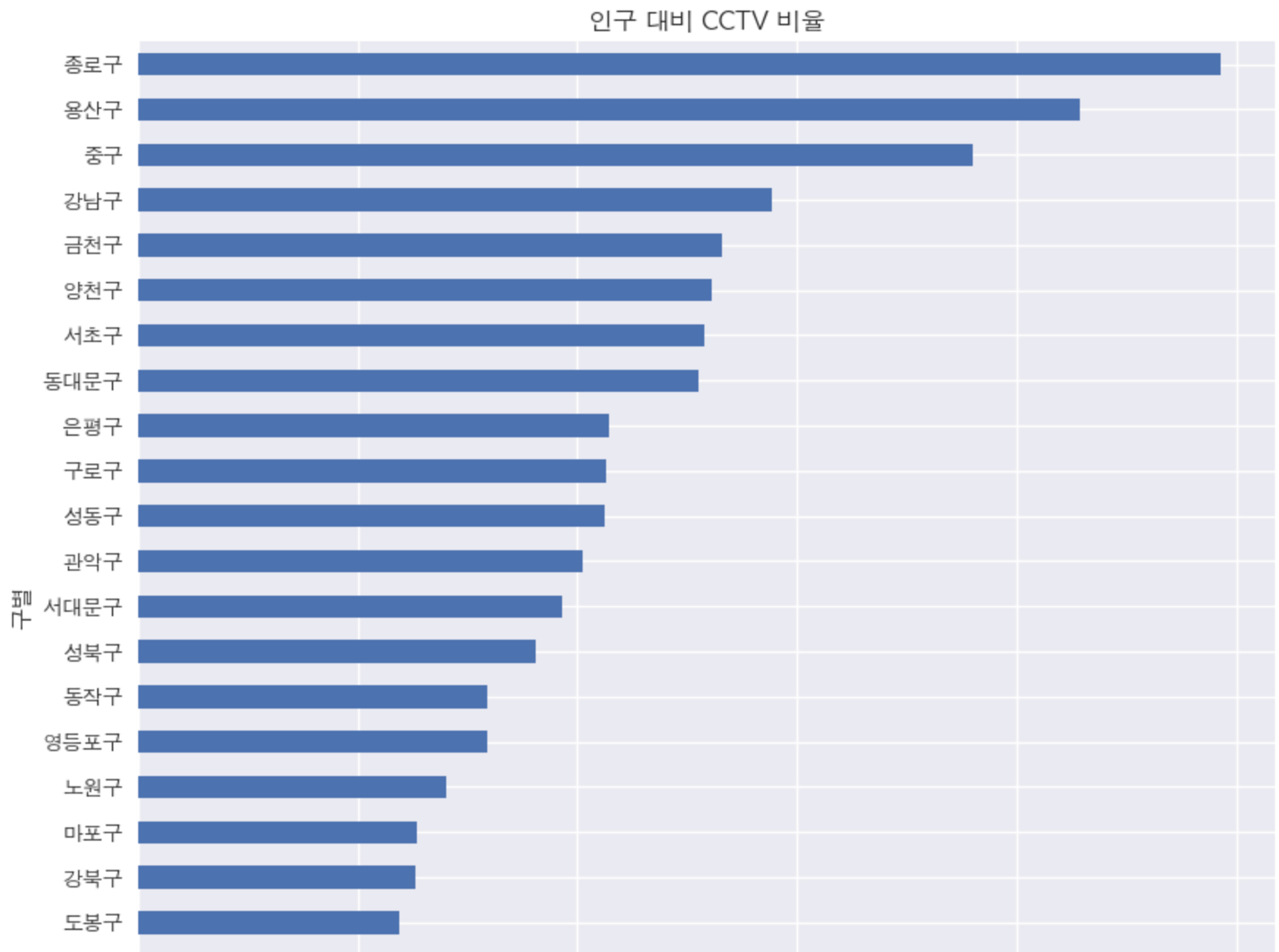
# CCTV 비율 막대 그래프
def drawGraph():
plt.style.use('seaborn')
plt.rcParams['font.family'] = 'AppleGothic'
data_result['CCTV비율'].sort_values().plot(
kind='barh', grid=True, title='인구 대비 CCTV 비율', figsize=(10,10));
drawGraph()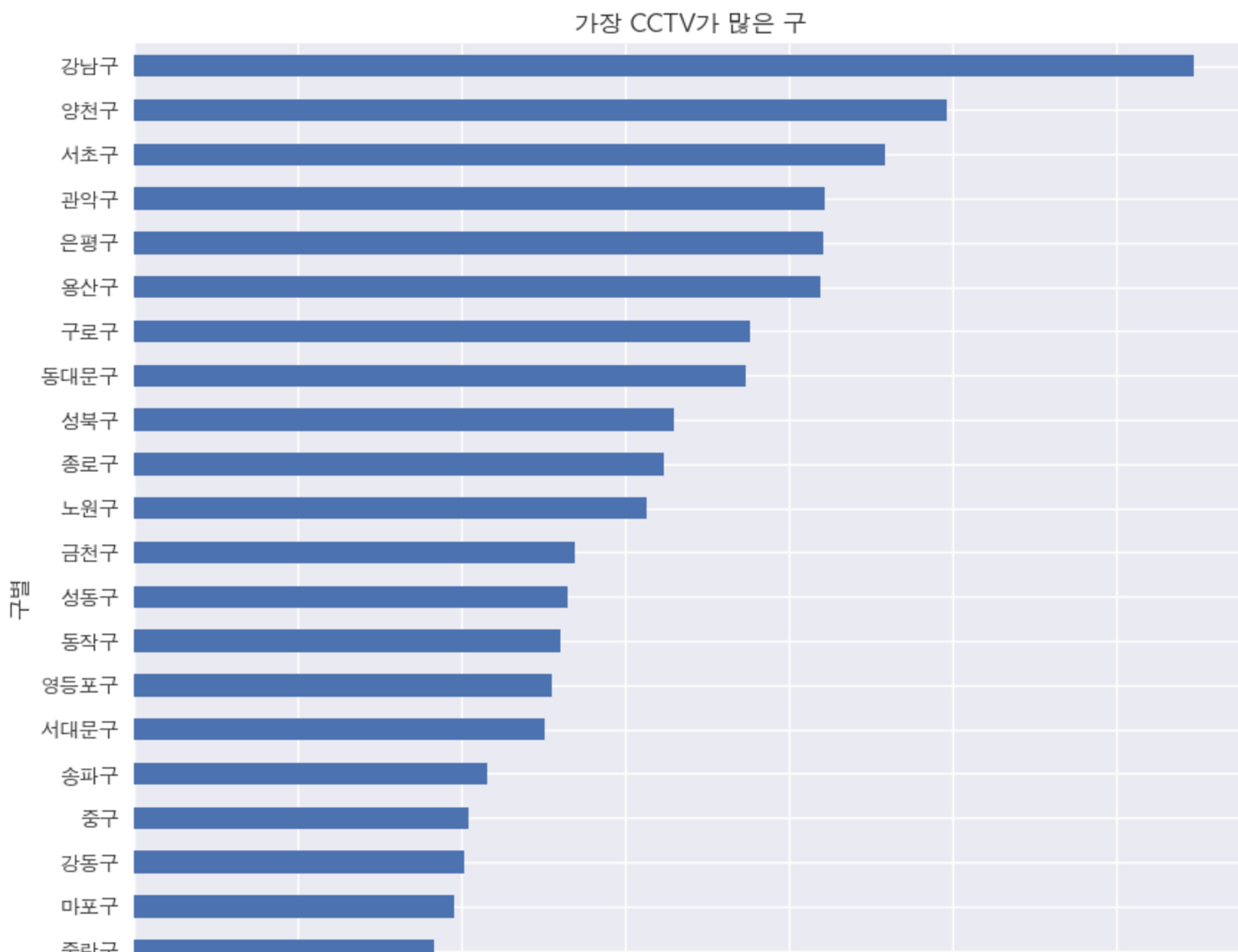
인구수와 CCTV 보유대수 간의 산점도 그리기
def drawGraph():
plt.figure(figsize=(14,10))
plt**.scatter**(data_result['인구수'],data_result['소계'], s=50)
plt.xlabel('인구수')
plt.ylabel('CCTV')
plt.grid(True)
plt.show()
drawGraph()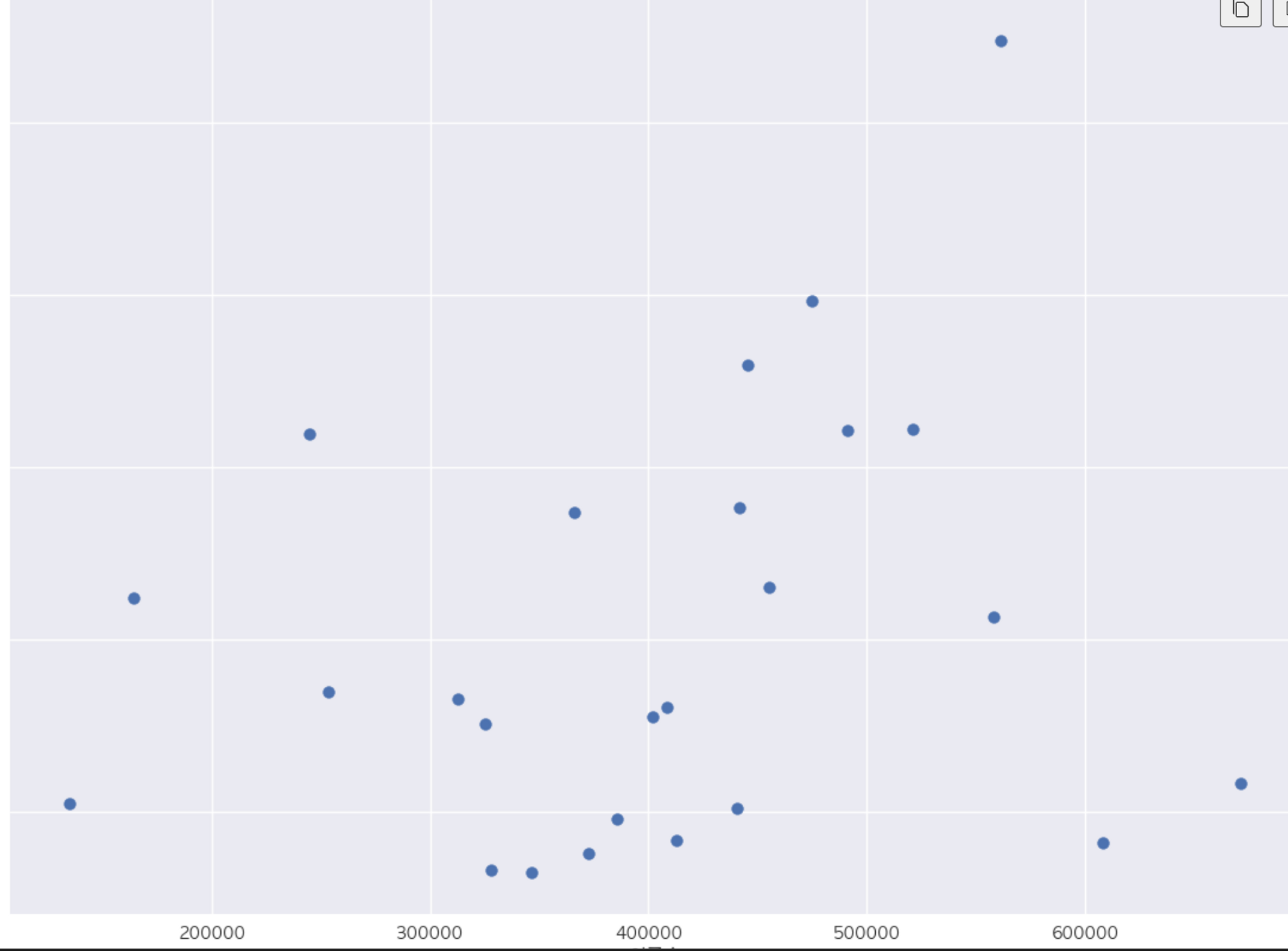
경향 파악하기
Numpy 를 이용해서 회귀선 만들어주기
- np.polyfit(x, y, d)
- x : 설명변수
- y : 종속변수
- d : 구할 차수
import numpy as np
fp1 = **np.polyfit**(data_result['인구수'],data_result['소계']**,1**)
f1 = **np.poly1d**(fp1)# 회귀선을 그려주기 위해 임의로 100개의 x데이터를 지정된 범위 내에서 생성
fx = **np.linspace**(100000,700000,100) # 10만 ~ 70만 사이에서 100개의 데이터를 등간격으로 추출
def drawGraph():
plt.figure(figsize=(14,10))
plt.scatter(data_result['인구수'],data_result['소계'], s=50)
# 선형 회귀 직선 추가
plt**.plot**(**fx**, **f1(fx)**, ls='--', lw=3, color='g')
plt.xlabel('인구수')
plt.ylabel('CCTV')
plt.grid(True)
plt.show()
drawGraph()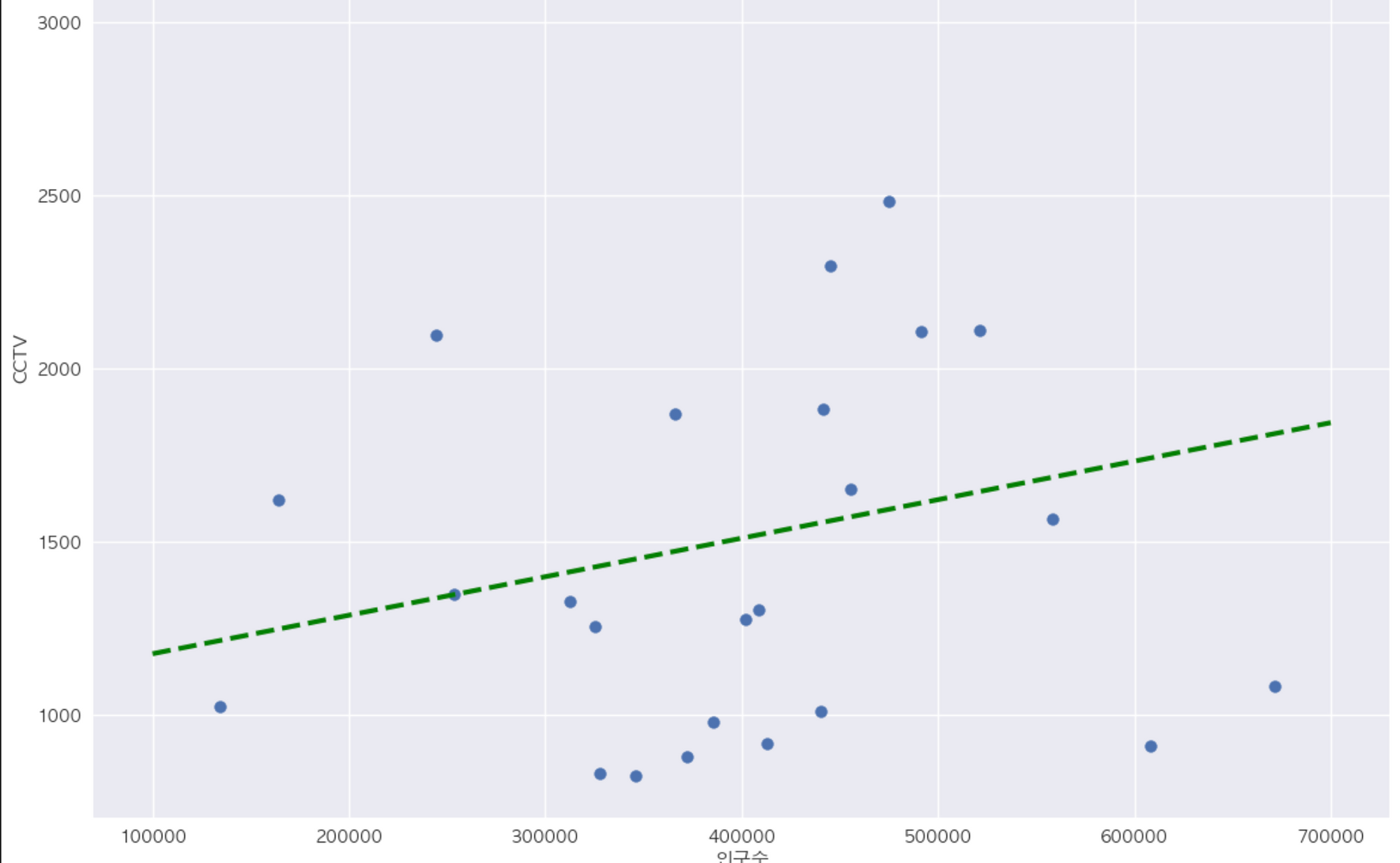
오차 값 생성하기
위의 과정으로 회귀선(경향선)을 그렸다면, 실제값과의 차이(오차)를 구할 수 있다.
경향값은 만든 f1함수에 해당하는 인구수를 넣었을 때의 값이다. → f1(data_result[’인구수’])
data_result['오차'] = data_result['소계'] - f1(data_result['인구수'])
# 오차를 기준으로 내림차순
data_sort_f = data_result.sort_values('오차', ascending=False) # 내림차순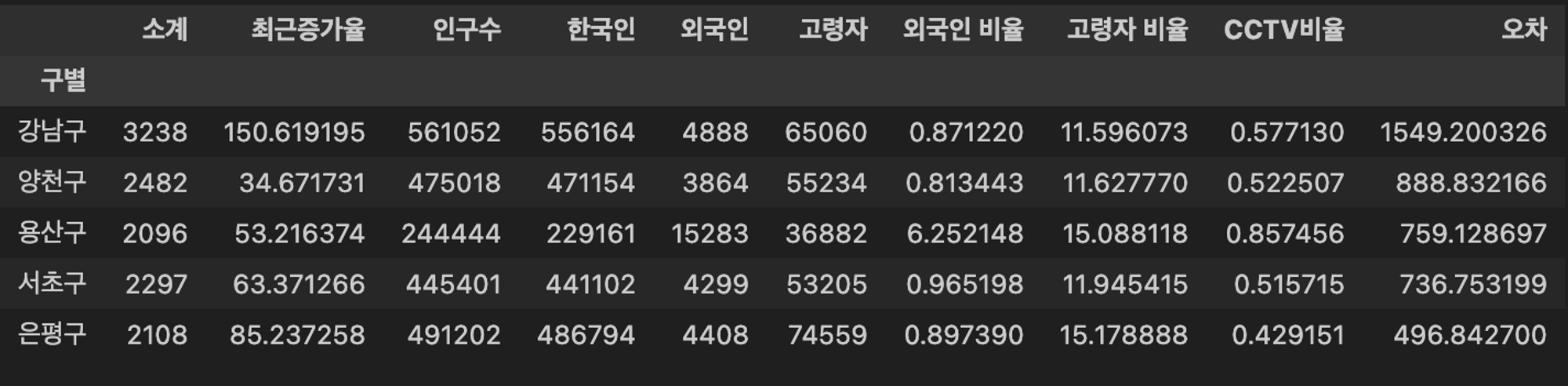
즉, 경향 대비 훨씬 많은 CCTV 를 보유하고 있는 지역을 알아볼 수 있다. (강남구 > 양천구 > 용산구 >…)
# 반대로, 경향 대비 CCTV 보유대수가 훨씬 적은 하위 지역을 살펴보면,
data_sort_t = data_result.sort_values('오차') # 오름차순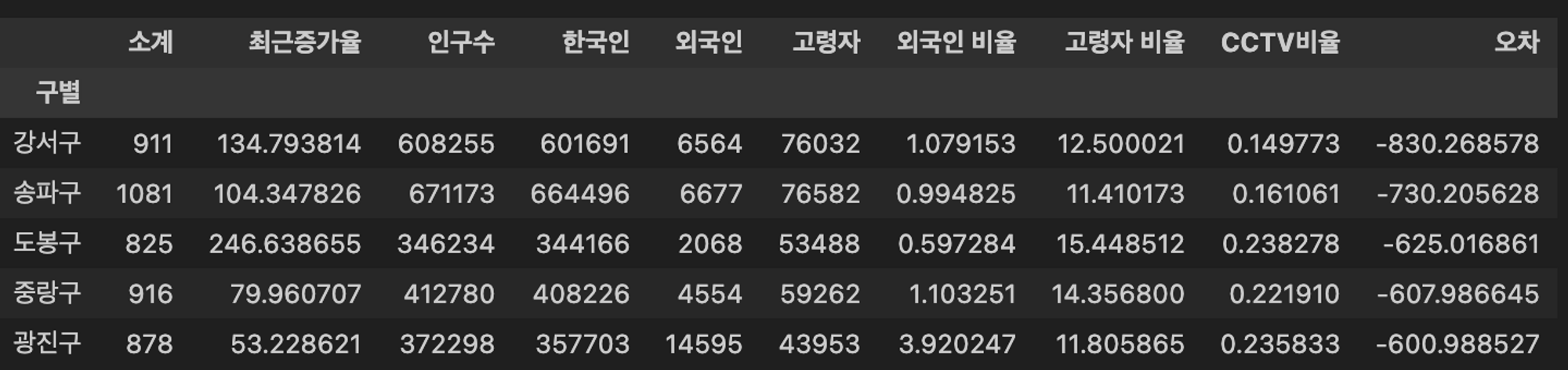
강서구 > 송파구 > 도봉구 > … 순으로 인구수 대비 CCTV 보유대수가 경향보다도 훨씬 적은 것을 파악할 수 있다.
Line Plot 강화하기
좀 더 한눈에 확 파악할 수 있도록 해보자.
from **matplotlib.colors** import **ListedColormap**
# colormap 을 사용자 정의로 세팅
**color_step** = ['#e74c3c','#2ecc71','#95a9a6','#2ecc71','#3498db','#3498db']
my_cmap = **ListedColormap(color_step**)
def drawGraph():
plt.figure(figsize=(14,10))
# 오차 필드 값의 크기에 따라 색깔을 위의 지정한 my_cmap 으로 표현하자
plt**.scatter(**data_result['인구수'],data_result['소계'], s=50, **c = data_result['오차']**, **cmap = my_cmap**)
# 선형 회귀 직선 추가
plt**.plot(fx**, **f1(fx)**, ls='--', lw=3, color='g')
for n in range(5):
# 상위 5개 **데이터 labeling** 해주기
**plt.text(**data_sort_f['인구수'][n] * 1.02, data_sort_f['소계'][n] * 0.98 , data_sort_f**.index[n]**, fontsize=15)
# 하위 5개 데이터 labeling 해주기
**plt.text(**data_sort_t['인구수'][n] * 1.02, data_sort_t['소계'][n] * 0.98 , data_sort_t.index[n], fontsize=15)
plt.xlabel('인구수')
plt.ylabel('CCTV')
plt.grid(True)
**plt.colorbar()**
plt.show()
drawGraph()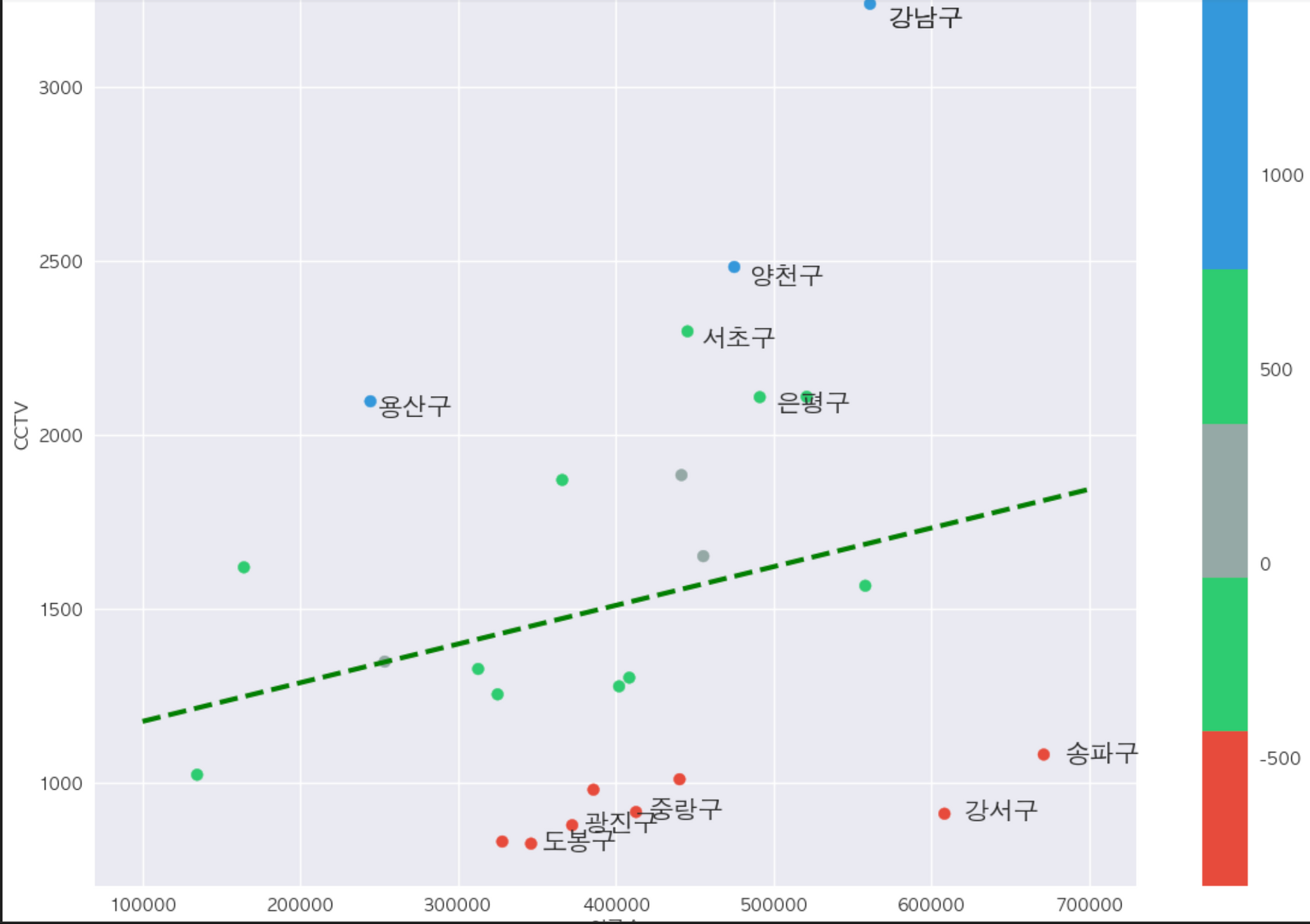

공부한 내용들에 대해 끄적이는 공간입니다💎