
결측값, 중복값 처리
1. 결측값(NaN)
- isnull() : 결측값이 존재하는 곳 확인
- isnull().sum() : 각 컬럼별로 결측치의 개수 확인
- dropna() : 결측값이 존재하는 행을 지움
- dropna(axis=1) : 결측값이 존재하는 열을 지움
- fillna(값) : 결측값 대체
결측값이 존재하는 데이터(아래)에서 값을 처리하겠음.
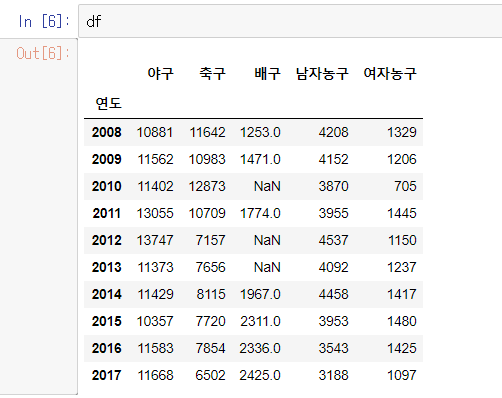
# isnull() : 결측값이 존재하는 곳 확인(boolean 값으로 결과 표시)
df.isnull()
# isnull().sum() : 각 컬럼별로 결측치의 개수 확인
df.isnull().sum()
# dropna() : 결측값이 존재하는 행을 지움
df.dropna()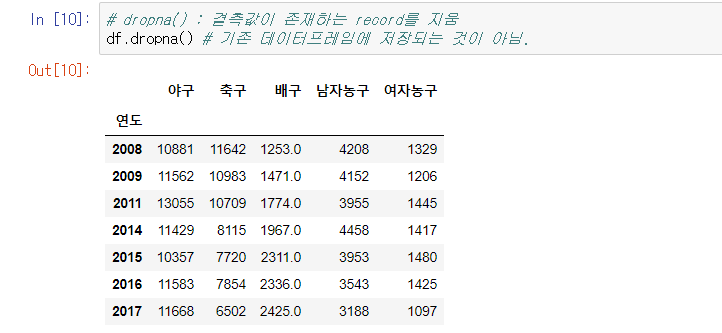
# dropna(axis=1) : 결측값이 존재하는 열을 지움
df.dropna(axis='columns')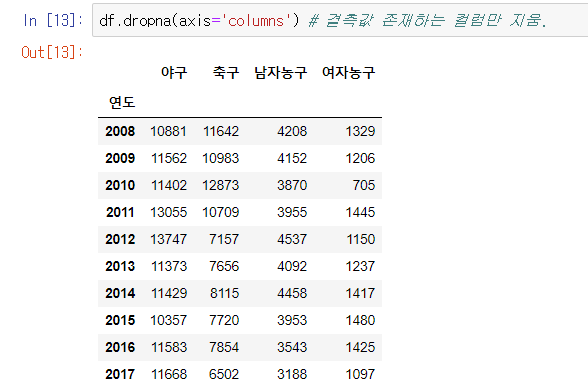
# fillna(값) : 결측값 대체
df.fillna()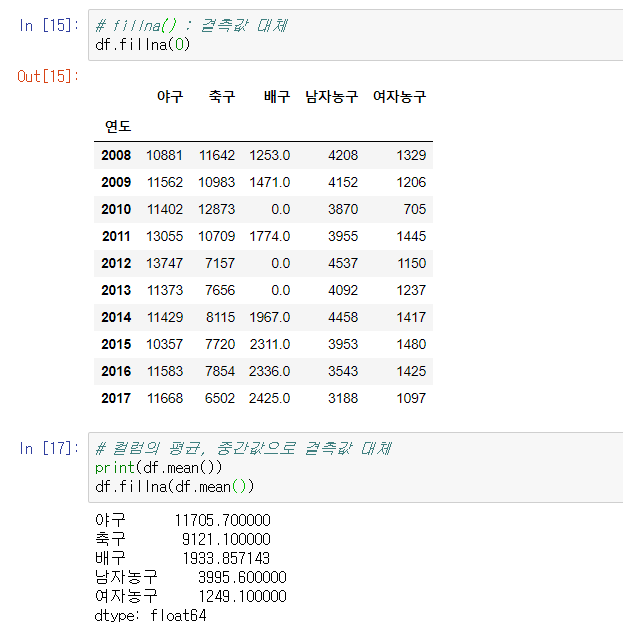
2. 중복값
- drop_duplicates() : 중복되는 행 삭제(값, 이름 중복 모두)
중복 값이 행/열 모두에 존재하는 데이터에서 이를 처리하는 과정이 아래에 나와있음. (아래는 처리한 데이터)
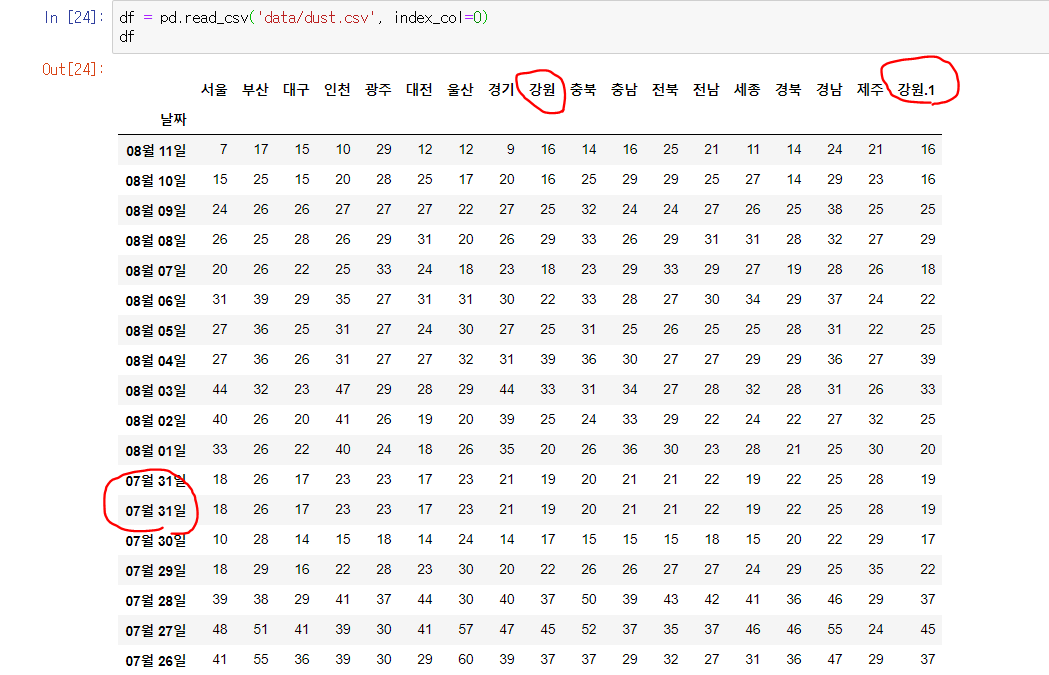
# 행이 중복되는 경우
df.index # index 값 확인을 통해 중복 값 찾음
df.index.value_counts() # 중복되는 값의 수를 출력함
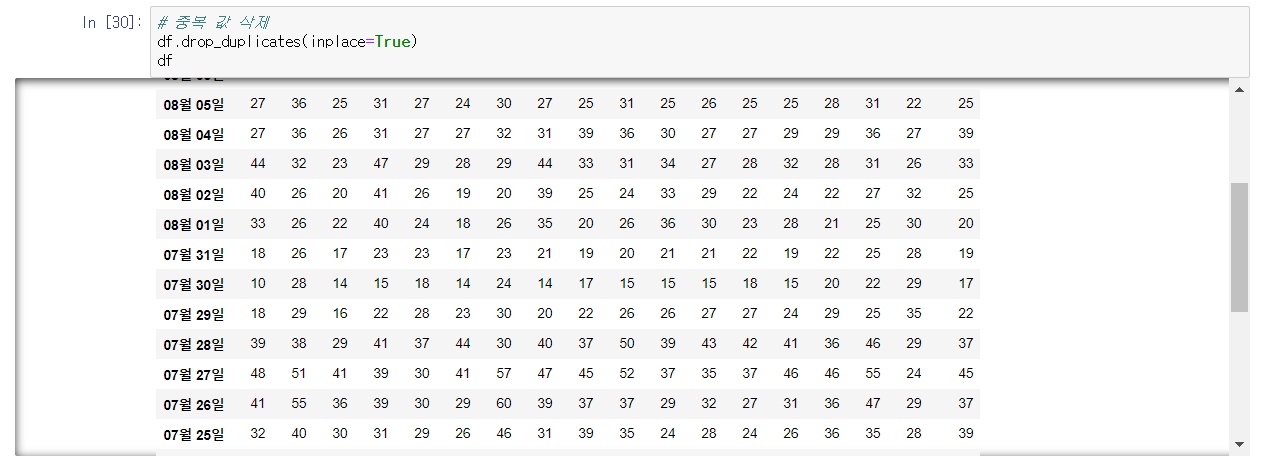
df.drop_duplicates(inplace=True) # 중복 행 제거, inplace=값 변경 저장 여부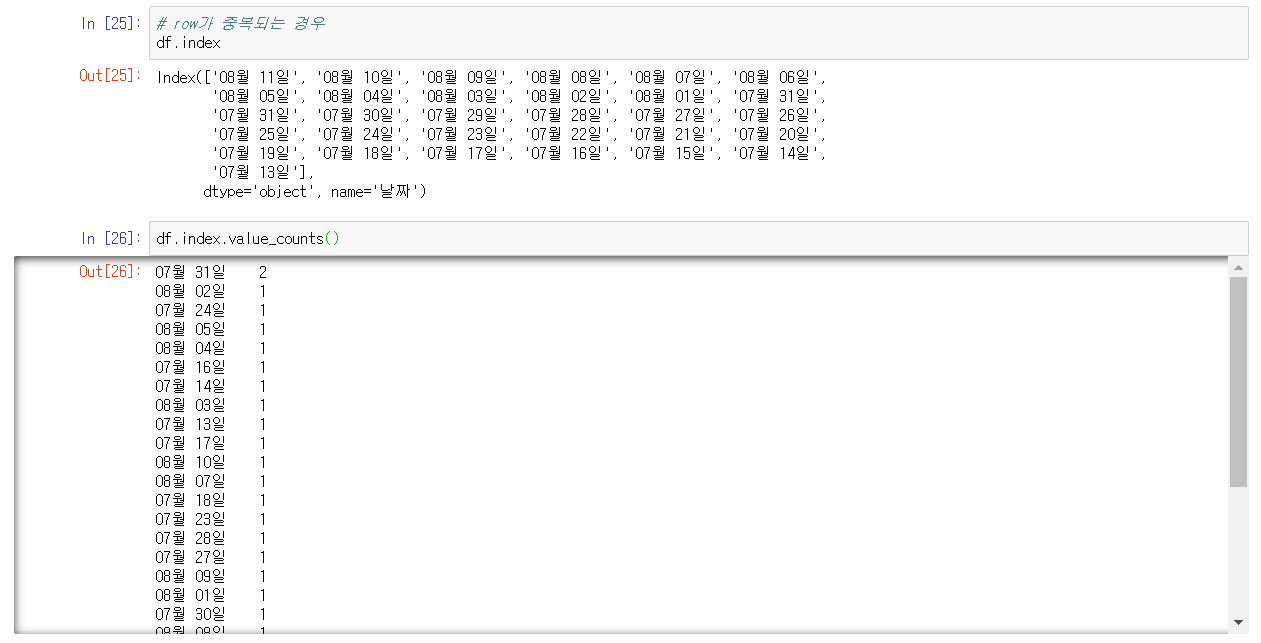
# 열이 중복되는 경우
df.T # .T : row, column을 바꿈.
df = df.T.drop_duplicates().T # row의 내용이 동일하면 중복값으로 인식하고 삭제됨. 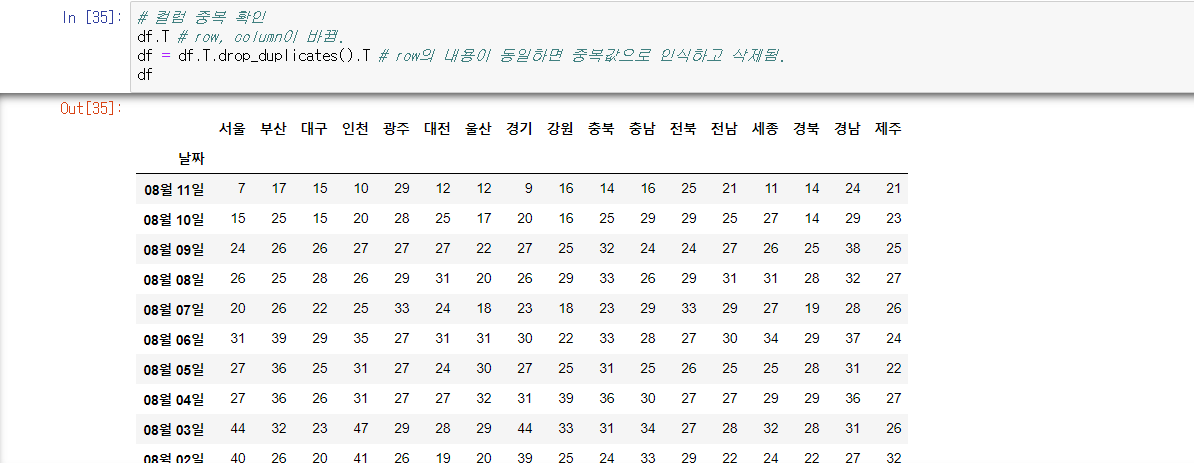

박학다식 대학원생이 되기 위해..