
pandas의 unstack()함수는 pandas의 DataFrame이나 Series에서 사용되며, 데이터를 재구조화하여 더 읽기 쉽고 분석하기 편리한 형태로 변환하는 데 사용된다.
이 함수는 멀티인덱스(multi-index)를 가진 데이터에서 특정 레벨의 인덱스를 컬럼으로 옮겨 데이터를 재구성한다.
기본 개념
unstack() 은 주로 데이터를 피봇팅할 때 사용되며, '긴 형식'(long format)의 데이터를 '넓은 형식'(wide format)으로 변경한다. 이를 통해 데이터의 특정 측면을 더 잘 강조하거나, 특정 분석을 위해 데이터의 구조를 변경할 수 있다.
*긴 형식'(long format) 과 '넓은 형식'(wide format)
- '긴 형식' 은 데이터가 수직적으로 길게 나열되는 형태로,
각 행이 하나의 관측치를 대표하고 일반적으로 'tidy data'의 원칙을 따른다.
이 형식에는 데이터에 중복이 적고, 데이터를 다루는 많은 라이브러리나 소프트웨어에서 요구하는 표준 형태이다.
- 각 행은 하나의 관측치를 대표한다.
- 같은 변수의 데이터가 여러 행에 걸쳐 나타난다.
- 데이터를 추가하려면 행을 추가하면 된다.- '넓은 형식' 은 데이터가 수평적으로 넓게 퍼져 있는 형태로,
각 변수가 하나의 열을 차지하고, 각 행이 여러 관측치를 포함할 수 있다.
이 형식은 보다 직관적이고 시각적으로 이해하기 쉬울 수 있지만, 데이터 처리나 변환 작업이 복잡해질 수 있다.
- 각 행이 하나 이상의 관측치를 대표할 수 있다.
- 변수의 수가 많아질수록 열의 수가 늘어난다.
- 하나의 관측치가 여러 열에 걸쳐 표현된다.
사용 방법
unstack() 함수는 DataFrame의 Series 객체에 호출될 수 있으며, 선택하지 하지 않으면 기본적으로 가장 마지막 레벨의 인덱스가 컬럼으로 변환된다.
# 사용 예
result = df.groupby(['col1', 'col2']).size() #
result.unstack()파라미터
level : 어떤 인덱스 레벨을 컬럼으로 바꿀지 결정한다. 기본값은 -1로, 가장 마지막 레벨이 선택된다. 인덱스 레벨 번호 또는 이름을 지정할 수 있다.
fill_value : unstacking 과정에서 생성되는 결측치를 대체할 값이다. 예를 들어, 데이터 셋에서 모든 가능한 조합이 존재하지 않는 경우 결측치가 발생할 수 있는데, 이 값을 통해 특정 값으로 채울 수 있다.
import pandas as pd
# create DataFrame
df = pd.DataFrame(
{ 'values' = range(6),
'A' : ['foo', 'foo', 'foo', 'bar', 'bar', 'bar'],
'B' : ['one', 'two', 'three', 'one', 'two', 'three']
}
).set_index(['A','B'])
print(df)
# unstack
unstacked = df.unstack(level='B')
print(unstacked)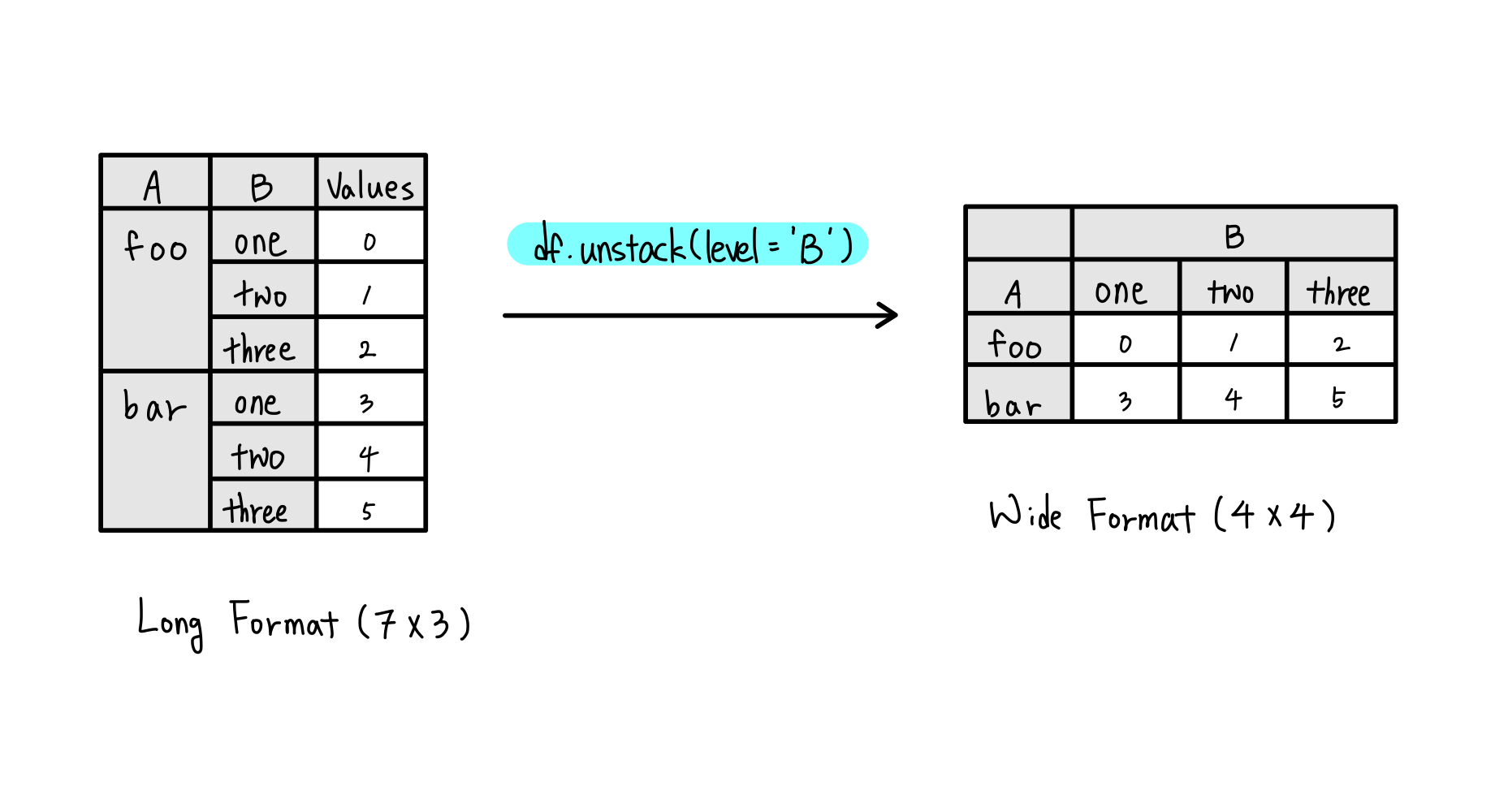
이 예시에서는 A와 B를 인덱스로 가지는 DataFrame에 대헤 unstack() 함수를 사용하여 B 인덱스를 컬럼으로 변환한다. 결과적으로 B의 각 값('one', 'two', 'three')이 컬럼으로 재배치되고, A의 각 값에 따라 세분화되어 표시된다.
이러한 unstack() 함수는 특히 시계열 데이터나 계층적 인덱스를 가진 복잡한 데이터에서 매우 유용하게 사용될 수 있으며, 데이터를 분석하기 위한 다양한 형태로 쉽게 변환할 수 있도록 도와준다.
with GPT-4
