!pip install tabula-pyimport tabula
import pickle
# module 'tabula' has no attribute 'read_pdf' 에러 발생하면, 아래 코드 주석 해제 후 실행
from tabula.io import read_pdf
# Tabula로 PDF 읽기 -> DataFrame List
ingredients_list = tabula.read_pdf('./datas/별첨1. 표준화명칭목록_220530.pdf', pages='all', lattice=True)
# DataFrame List를 Pickle로 저장
with open('./datas/ingredients_list.pkl', 'wb') as f:
pickle.dump(ingredients_list, f)1 번 문제
문제 1-1) 성분사전 DataFrame 만들기(10점)
- Pickle을 이용해 Load한 ingredients_list_pkl를 하나의 DataFrame으로 합치세요.
- 조건1: 데이터는 index 기준으로 합치세요.
- 조건2: join없이 단순히 합치세요.
- hint1: 20375개의 행이 만들어져야 합니다.
- hint2: ingredients_list_pkl는 여러 DataFrame들이 Element로 들어있는 List입니다.
- 완료 후 결과 dataframe 변수를 check_01_01 함수에 입력하여 채점하세요.
#(1) pickle 로드
import pickle
with open('./datas/ingredients_list.pkl', 'rb') as f:
ingredients_list_pkl = pickle.load(f)📌 정답
# 1-1
import pandas as pd
# pd. concat : 리스트에 있는 여러 DataFrame을 하나의 DataFrame으로 합침
ingredients_df = pd.concat(ingredients_list_pkl, ignore_index=False)
#ignore_index=False: 이 옵션은 합치는 과정에서 원래의 index를 유지할 것인지를 결정합니다.
#False로 설정된 경우, 원래 DataFrame들의 index가 그대로 유지됩니다. 만약 True로 설정한다면, index는 리셋되어 0부터 다시 시작됩니다.
check_01_01(ingredients_df)
ingredients_df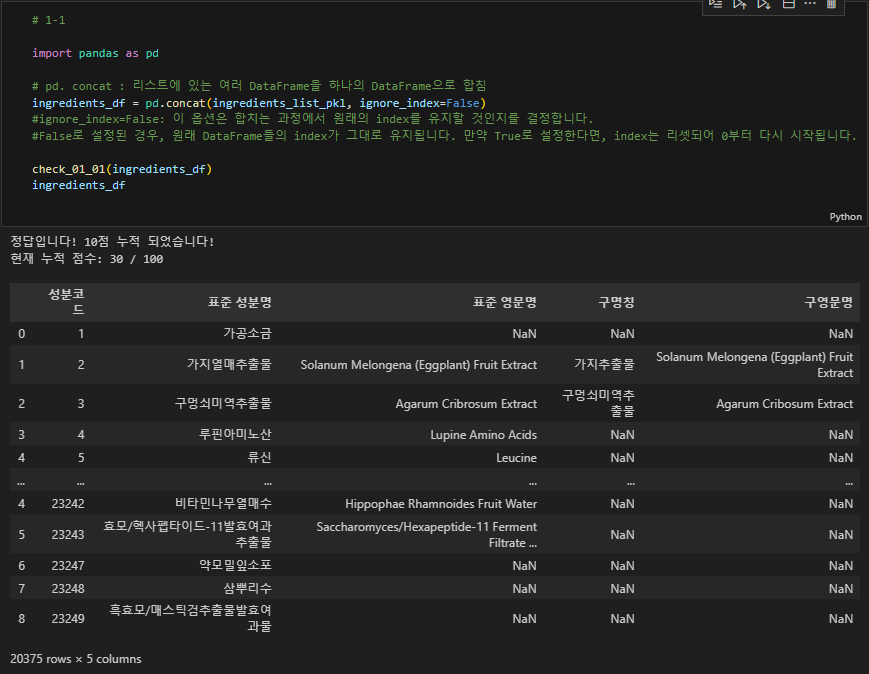
문제 1-2) 성분사전 DataFrame 내의 Data 수정하기 - 1(15점)
- 이 성분 사전 DataFrame에는 원본에는 없는 '\r' 이 아래와 같이 data 사이에 끼어 있습니다. 이 '\r'을 삭제하세요
- hint1: '\r'를 대체 할 때 한글('표준 성분명', '구명칭')의 경우 띄어쓰기가 없고, 영어('표준 영문명', '구영문명)의 경우 띄어쓰기를 해야 합니다.
- hint2: 모든 영문명의 경우 대문자로 시작합니다.
- 완료 후 결과 dataframe 변수를 check_01_02 함수에 입력하여 채점하세요.
📌 \r 이 얼마나, 어떻게 있는지 확인
# 전체 데이터 프레임 검색 방법 [참고] : https://blog.naver.com/boaconic859315/222643571465
rowR = ingredients_df[ingredients_df.apply(lambda row: row.astype(str).str.contains('\r').any(), axis=1)]
rowR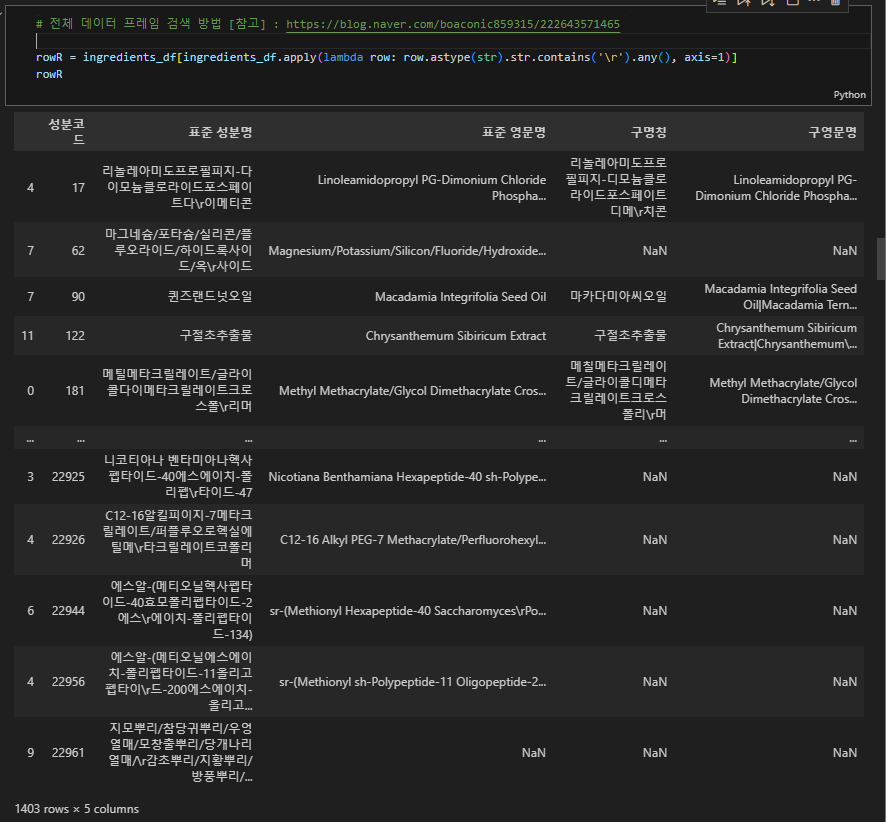
📌 정답
# 1-2
# .str.replace('\s+', ' ', regex=True) 메서드 [참고] : https://blog.naver.com/ugdotnet/223077503589
ingredients_df['표준 성분명'] = ingredients_df['표준 성분명'].replace('\r', "", regex = True)
ingredients_df['구명칭'] = ingredients_df['구명칭'].replace('\r', "", regex = True)
ingredients_df['표준 영문명'] = ingredients_df['표준 영문명'].replace('\r', " ", regex = True)
ingredients_df['구영문명'] = ingredients_df['구영문명'].replace('\r', " ", regex = True)
ingR = ingredients_df[ingredients_df.apply(lambda row: row.astype(str).str.contains('\r').any(), axis=1)]
ingR
check_01_02(ingredients_df)
ingredients_df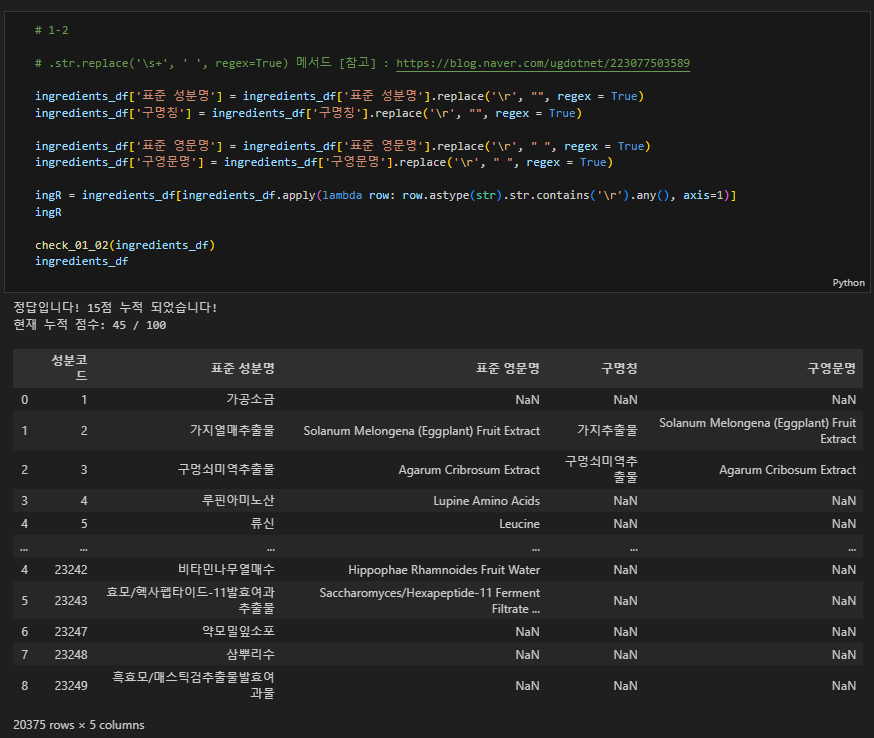
문제 1-3) 성분사전 DataFrame 내의 Data 수정하기 - 2(15점)
- pdf를 dataframe으로 전환하면서 일부 누락된 데이터가 있습니다. 아래 cell의 replace_dict는 현재값(key):변경할값(value)의 쌍으로 이루어져 있습니다. 이 replace_dict를 이용하여 성분사전 dataframe '표준 영문명' column의 값을 변경하세요.
- 참고: replace_dict의 내용만 변경하면 됩니다. 다른 누락사항을 확인하여 변경할 필요는 없습니다.
- 완료 후 결과 dataframe 변수를 check_01_03 함수에 입력하여 채점하세요.
replace_dict = {
'Acetobacter/Lycium Chinense Fruit/Rehmannia Glutinosa Root/Cuscuta Chinensis Fruit/Cistanche Deserticola/Zanthoxylum Piperitumit/Chrysanthemum Morifolium Fruit/Poria Cocos/ Cinnamomum Cassia': 'Acetobacter/Lycium Chinense Fruit/Rehmannia Glutinosa Root/Cuscuta Chinensis Fruit/Cistanche Deserticola/Zanthoxylum Piperitumit/Chrysanthemum Morifolium Fruit/Poria Cocos/ Cinnamomum Cassia Ferment',
'Saccharomyces/Licorice Root/Rehmannia Glutinosa Root/Angelica Gigas Root/Ophiopogon Japonicus Root/Atractylodes Macrocephala Root/Paeonia Lactiflora Root/Anemarrhena Asphodeloides Root/Fraxinus Excelsior Bark/Asparagus Cochinchinensis/Phellodendron Amurense': 'Saccharomyces/Licorice Root/Rehmannia Glutinosa Root/Angelica Gigas Root/Ophiopogon Japonicus Root/Atractylodes Macrocephala Root/Paeonia Lactiflora Root/Anemarrhena Asphodeloides Root/Fraxinus Excelsior Bark/Asparagus Cochinchinensis/Phellodendron Amurense Bark Ferment Extract',
'Bacillus/Lycium Chinense Fruit/Rehmannia Glutinosa Root/Cuscuta Chinensis Fruit/Cistanche Deserticola/Zanthoxylum Piperitum Fruit/Chrysanthemum Morifolium Fruit/Poria Cocos/ Cinnamomum Cassia': 'Bacillus/Lycium Chinense Fruit/Rehmannia Glutinosa Root/Cuscuta Chinensis Fruit/Cistanche Deserticola/Zanthoxylum Piperitum Fruit/Chrysanthemum Morifolium Fruit/Poria Cocos/ Cinnamomum Cassia Ferment',
'Bifida/Angelica Gigas/Angelica Tenuissima Root/Antler Velvet/Rehmannia Glutinosa Root/Atractylodes Japonica Rhizome/Cnidium Officinale Root/Cordyceps Sinensis/Ledebouriella Seseloides Root/Licorice Root/Paeonia Lactiflora Root/Panax Ginseng': 'Bifida/Angelica Gigas/Angelica Tenuissima Root/Antler Velvet/Rehmannia Glutinosa Root/Atractylodes Japonica Rhizome/Cnidium Officinale Root/Cordyceps Sinensis/Ledebouriella Seseloides Root/Licorice Root/Paeonia Lactiflora Root/Panax Ginseng Root/Phellinus Linteus/Scutellaria Baicalensis Root Ferment',
'Leuconostoc/Lycium Chinense Fruit/Rehmannia Glutinosa Root/Cuscuta Chinensis Fruit/Cistanche Deserticola/Zanthoxylum Piperitum Fruit/Chrysanthemum Morifolium Fruit/Poria Cocos/ Cinnamomum Cassia': 'Leuconostoc/Lycium Chinense Fruit/Rehmannia Glutinosa Root/Cuscuta Chinensis Fruit/Cistanche Deserticola/Zanthoxylum Piperitum Fruit/Chrysanthemum Morifolium Fruit/Poria Cocos/ Cinnamomum Cassia Ferment',
'Saccharomyces/Anemarrhena Asphodeloides Root/Angelica Gigas Root/Asparagus Cochinchinensis/Atractylodes Macrocephala Root/Fraxinus Excelsior Bark/Licorice Root/Ophiopogon Japonicus Root/Paeonia Lactiflora Root/Phellodendron Amurense': 'Saccharomyces/Anemarrhena Asphodeloides Root/Angelica Gigas Root/Asparagus Cochinchinensis/Atractylodes Macrocephala Root/Fraxinus Excelsior Bark/Licorice Root/Ophiopogon Japonicus Root/Paeonia Lactiflora Root/Phellodendron Amurense Bark Ferment Extract',
'Saccharomyces/Camellia Japonica Flower/Castanea Crenata Shell/Diospyros Kaki Leaf/Paeonia Suffruticosa Root/Rhus Javanica/Sanguisorba Officinalis Root Extract': 'Saccharomyces/Camellia Japonica Flower/Castanea Crenata Shell/Diospyros Kaki Leaf/Paeonia Suffruticosa Root/Rhus Javanica/Sanguisorba Officinalis Root Extract Ferment Filtrate',
'Lactobacillus/Honeysuckle Flower/Licorice Root/Morus Alba Root/Pueraria Lobata Root/Schisandra Chinensis Fruit/Scutellaria Baicalensis Root/Sophora Japonica Flower': 'Lactobacillus/Honeysuckle Flower/Licorice Root/Morus Alba Root/Pueraria Lobata Root/Schizandra Chinensis Fruit/Scutellaria Baicalensis Root/Sophora Japonica Flower Extract Ferment Filtrate',
'Lactobacillus/Lycium Chinense Fruit/Rehmannia Glutinosa Root/Cuscuta Chinensis Fruit/Cistanche Deserticola/Zanthoxylum Piperitum Fruit/Chrysanthemum Morifolium Fruit/Poria Cocos/Cinnamomum Cassia': 'Lactobacillus/Lycium Chinense Fruit/Rehmannia Glutinosa Root/Cuscuta Chinensis Fruit/Cistanche Deserticola/Zanthoxylum Piperitum Fruit/Chrysanthemum Morifolium Fruit/Poria Cocos/Cinnamomum Cassia Ramulus Bark Ferment Filtrate',
'Saccharomyces/Lycium Chinense Fruit/Rehmannia Glutinosa Root/Cuscuta Chinensis Fruit/Cistanche Deserticola/Zanthoxylum Piperitum Fruit/Chrysanthemum Morifolium Fruit/Poria Cocos/ Cinnamomum Cassia': 'Saccharomyces/Lycium Chinense Fruit/Rehmannia Glutinosa Root/Cuscuta Chinensis Fruit/Cistanche Deserticola/Zanthoxylum Piperitum Fruit/Chrysanthemum Morifolium Fruit/Poria Cocos/ Cinnamomum Cassia Ferment',
}📌 정답
# 1-3
for key, value in replace_dict.items():
ingredients_df['표준 영문명'] = ingredients_df['표준 영문명'].replace(key, value)
check_01_03(ingredients_df)
ingredients_df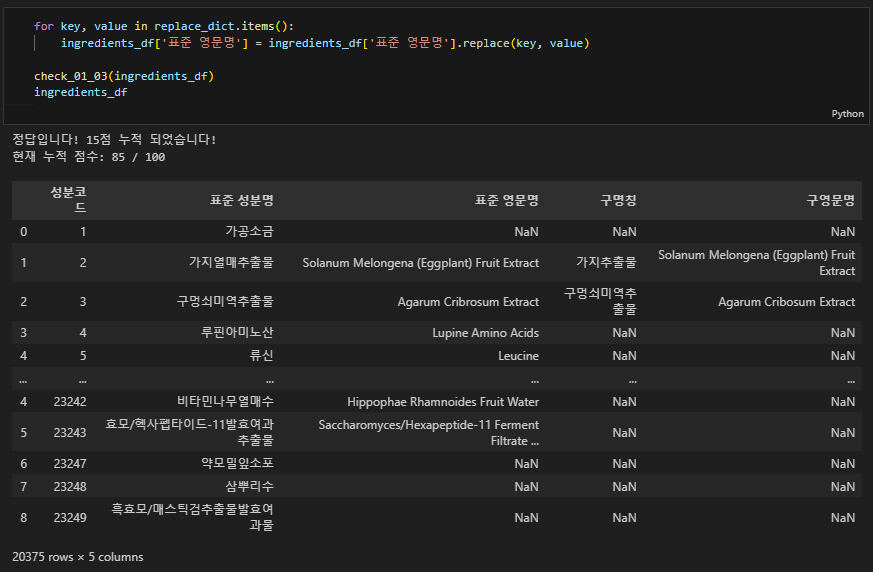
2번 문제
문제 2-1) Target DataFrame 중 Ingredients Column 내의 Data 수정하기(20점)
- Kaggle에서 가져오는 데이터는 수정을 필요로 하는 경우가 있습니다. 제시된 Target DataFrame 또한 성분사전과 다른 표현을 쓰는 경우가 있어 해당 내용에 대해 수정을 하고자 합니다. 다음 조건에 맞게 Ingredients Column의 데이터를 수정하세요.
- 조건1: 맨 끝에 마침표('.')가 있다면 마지막 마침표만 제거하세요
- ex) 'Algae (Seaweed) Extract. Sea Salt.' -> 'Algae (Seaweed) Extract. Sea Salt'
- 조건2: '. May Contain'를 포함하고 있다면, '. May Contain' 이후의 데이터를 제거하세요
- ex) 'Algae (Seaweed) Extract. May Contain: Sea Salt, Fragrance' -> 'Algae (Seaweed) Extract'
- 조건3: 아래의 replace_str_dict는 현재값(key):변경할값(value)의 쌍으로 이루어져 있습니다. 이 replace_str_dict를 이용하여 데이터를 변경하세요
- 참고: replace_str_dict의 내용만 변경하면 됩니다. 다른 누락사항을 확인하여 변경할 필요는 없습니다.
- 완료 후 결과 dataframe 변수를 check_02_01 함수에 입력하여 채점하세요.
#원본
df_target = pd.read_csv('./datas/cosmetics.csv', encoding='utf-8')
df_target = df_target.iloc[:5]
df_target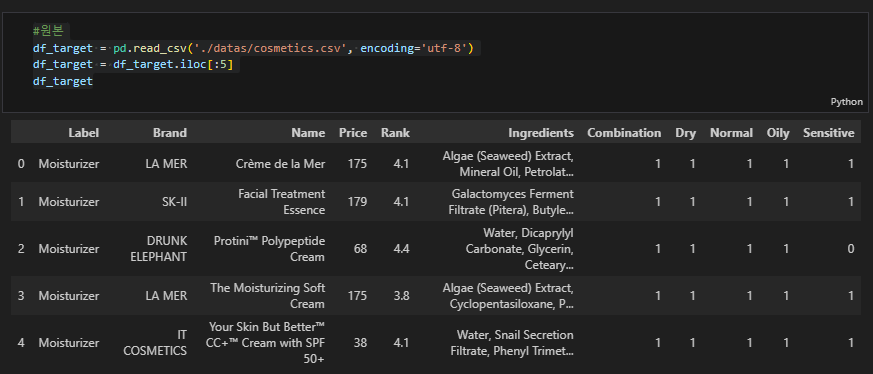
💡 개념
- loc 함수 :
- iloc 함수 :
- DataFrame :
- iterrows() :
replace_str_dict = {
'Algae (Seaweed) Extract': 'Algae Extract',
'Citrus Aurantifolia (Lime) Extract': 'Citrus Aurantifolia (Lime) Fruit Extract',
'Eucalyptus Globulus (Eucalyptus) Leaf Oil': 'Eucalyptus Globulus Leaf Oil',
'Galactomyces Ferment Filtrate (Pitera)': 'Galactomyces Ferment Filtrate',
'Bacillus/Soybean/ Folic Acid Ferment Extract': 'Bacillus/Folic Acid/Soybean Ferment Extract',
'Butyrospermum Parkii (Shea Butter)': 'Butyrospermum Parkii (Shea) Butter',
'Sea Salt/Maris Sal/Sel Marin': 'Sea Salt',
'Parfum/Fragrance': 'Fragrance|Perfume|Parfum',
', Fragrance': ', Fragrance|Perfume|Parfum',
}# . 제거
for idx, row in df_target.iterrows():
if df_target.loc[idx,'Ingredients'][-1:] == '.':
df_target.loc[idx, 'Ingredients'] = df_target.loc[idx, 'Ingredients']
df_target
# . May Contain 제거
# '. May Contain' 기준으로 앞뒤 나누기
text = '. May Contain'
split_text = df_target['Ingredients'].str.split(text)
# '. May Contain' 이후 데이터 삭제 반복
for idx, row in df_target.iterrows():
df_target.loc[idx, 'Ingredients'] = split_text[idx][0]
# replace_str_dict는 현재값(key):변경할값(value)
# 데이터 변경
for key, value in replace_str_dict.items():
for idx, row in df_target.iterrows():
re_place = df_target.loc[idx, "Ingredients"].replace(key, value)
df_target.loc[idx, "Ingredients"] = re_place
df_target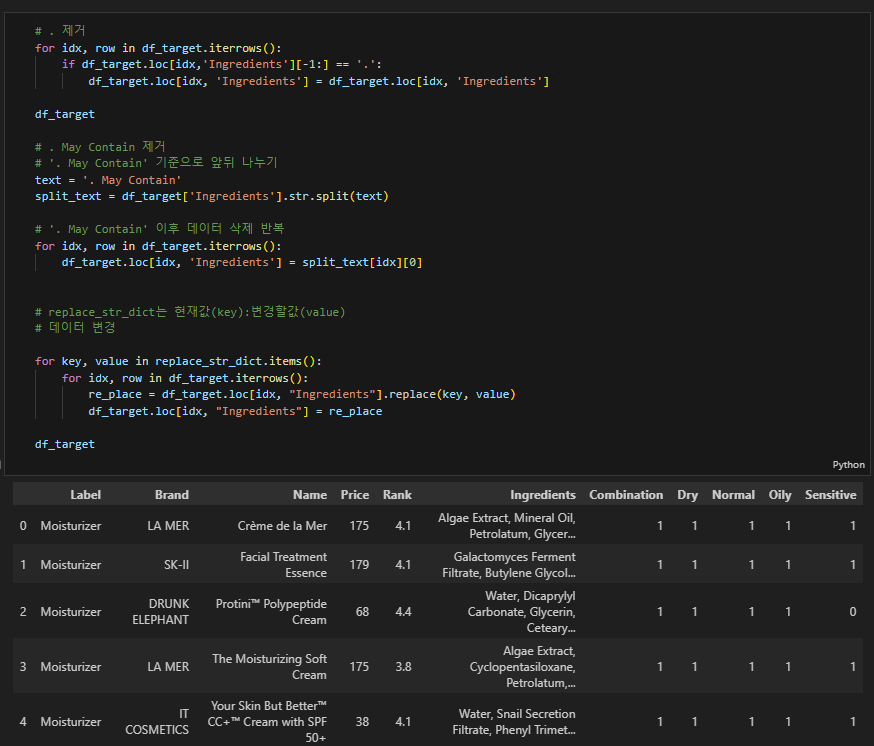
📌 정답
# 2-1
def new_df_target(text):
# 맨 끝에 마침표 제거
if text.endswith('.'):
text = text[:-1]
# MayContain 이후의 데이터를 제거
if '. May Contain' in text:
text = text.split('. May Contain')[0]
# replace_str_dict 변경
# [.replace(old, new) 참고] : https://blog.naver.com/purplecow7/223001801905
for old, new in replace_str_dict.items():
text = text.replace(old, new)
return text
# [.apply 참고] : https://blog.naver.com/nackji80/223071958160, https://kibua20.tistory.com/194
df_target['Ingredients'] = df_target['Ingredients'].apply(new_df_target)
check_02_01(df_target)
df_target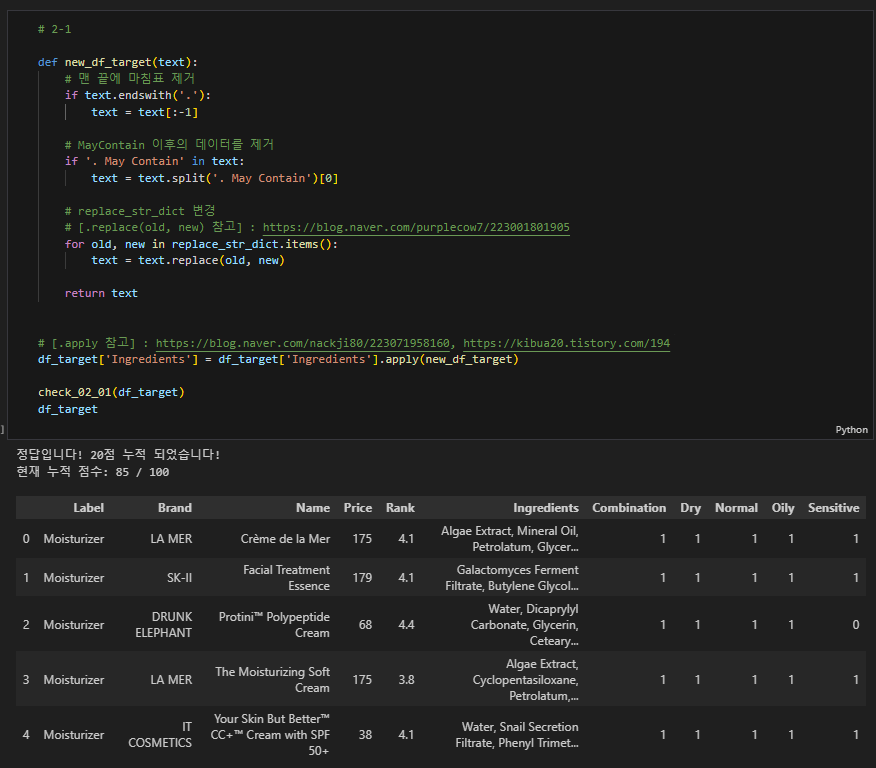
문제 2-2) Target DataFrame 중 'Ingredients' Column Data 변환하기(10점)
- 다음 조건에 맞게 앞서 수정한 'Ingredients' Column의 데이터를 변환하여 'Ingredients List' Column에 입력하세요.
- 조건1: 'Ingredients' Column의 각 데이터를 ', '(쉼표+띄어쓰기)로 분리하여 List로 변환하세요
- ex) ' Algae (Seaweed) Extract, Sea Salt ' -> [' Algae (Seaweed) Extract', ' Sea Salt ']
- 조건2: 조건1에서 변경한 list의 각 Element 앞뒤의 공백이 있다면 공백을 삭제하세요
- ex) [' Algae (Seaweed) Extract', ' Sea Salt '] -> ['Algae (Seaweed) Extract', 'Sea Salt']
- 조건3: 'Ingredients List' Column을 새로 생성하여 조건1과 조건2에서 만든 list를 각 행에 맞게 입력하세요
- 완료 후 결과 dataframe 변수를 check_02_02 함수에 입력하여 채점하세요.
📌 정답
# 2-2
# # 조건 2
# # 변경한 리스트 : df_target['Ingredients List']
# # .str.strip() [참고] : https://blog.naver.com/superxt/223055431746
# df_target['Ingredients List'] = df_target['Ingredients'].str.strip()
# # 조건 1
# # split() : 띄어쓰기로 나눠져 있는 걸, list형태의 객체로 바꿔줌
# # 'Series' object has no attribute 'split' 에러 발생 → .str.split(',') 로 해결
# df_target['Ingredients List'] = df_target['Ingredients'].str.split(',')
# 위 풀이가 오답으로 떠서 아래 풀이로 변경
set_list = df_target['Ingredients'].str.split(", ")
for i in range(len(set_list)):
for j in range(len(set_list[i])):
set_list[i][j] = set_list[i][j].strip()
df_target['Ingredients List'] = set_list
check_02_02(df_target)
df_target
3번 문제
문제 3-1) Target DataFrame 의 'Ingredients List' Column를 Mapping하여 'Code List' Column 만들기(15점)
- (아래 예시를 참고)성분사전(Ingredients Dictionary)를 이용하여 Target DataFrame의 'Ingredients List'를 각 성분에 Mapping되는 'Code List'로 만들고, 'Code List' Column을 만들어 Code List를 각 행에 맞게 입력하세요.
- 조건1: Ingredients List에 대응하는 Code List의 순서는 같아야 합니다.
- hint1: '표준 영문명'에서 찾지 못한다면 '구영문명'으로도 찾아보세요
- hint2: 대문자-소문자 차이가 있을 수 있습니다.
- 참고: 'Code'는 성분사전(Ingredients Dictionary)의 '성분코드'를 의미합니다.(Index가 아닙니다)
- 완료 후 결과 dataframe 변수를 check_03_01 함수에 입력하여 채점하세요.
📌 정답
def map_ingredients_to_codes(ingredients_list):
code_list = []
for ingredient in ingredients_list:
# 성분사전에서 '표준 영문명' 또는 '구영문명'에 해당하는 성분코드를 찾기
# | 의미 : 두 피연산자가 set 유형이면 '|' 연산자는 두 집합의 합집합을 반환
# 합집합 기호 | [참고] : https://f7project.tistory.com/390
code = ingredients_df[(ingredients_df['표준 영문명'].str.lower() == ingredient.lower()) | (ingredients_df['구영문명'].str.lower() == ingredient.lower())]['성분코드'].values
# 성분코드가 존재한다면, code_list에 추가
if len(code) > 0:
code_list.append(code[0])
else:
code_list.append(None) # 성분사전에서 찾지 못한 경우 None을 추가
return code_list
# .strip() : 주어진 문자가 원래 문자열의 시작 또는 끝과 일치하지 않는 경우 문자열을 있는 그대로 반환
# [참고] : https://www.entity.co.kr/entry/Python-String-strip-%ED%95%A8%EC%88%98-strip-%ED%95%A8%EC%88%98%EC%9D%98-%EC%A0%95%EC%9D%98
# lambda & apply [참고] : https://blog.naver.com/sophi_happy/222585611788
df_target['Code List'] = df_target['Ingredients List'].apply(lambda x: map_ingredients_to_codes([ingredient.strip() for ingredient in x]))
문제 3-2) 다음 조건을 만족하는 code들을 찾아 그 code들에 해당하는 DataFrame을 구하세요(15점)
- (아래 예시를 참고) Target DataFrame의 Code List를 각 행 내에서 중복 없이 모두 합쳐 두 번 나온 수를 오름차순으로 정렬하고, 첫번째부터 다섯번째까지의 수들을 찾아 성분사전(Ingredients Dictionary)를 이용하여 해당 Code들의 DataFrame을 구하세요.
- 이 DataFrame에서 나타난 Code 중 각 행 내에서 중복 없이 두 번 나온 Code는 [3, 9, 23, 34, 57, 234] 이고, 이 중 오름차순으로 첫번째부터 다섯번째까지의 수는 [3, 9, 23, 34, 57] 입니다.
- 참고
- '3'의 경우 2번 행과 3번 행에서 나왔습니다.
- 0번 행의 '12'의 경우 중복하여 나왔으므로, 한 번 나온 것으로 count 합니다.
- 성분사전(Ingredients Dictionary)에서 해당 code들의 DataFrame은 아래와 같습니다.
- 조건1: 중복 code는 없어야 합니다.
- 조건2: '두' 번 나온 수, 오름차순, 첫번째부터 다섯번째까지 다시 한번 확인하세요.
- hint1: sorted(list, key=lambda x: func(x))
- hint2: set()
- hint3: list.count()
- 참고: 'Code'는 성분사전(Ingredients Dictionary)의 '성분코드'를 의미합니다.(Index가 아닙니다)
- 완료 후 결과 dataframe 변수를 check_03_02 함수에 입력하여 채점하세요.
🥲못 풀었다😭
- 노력의 흔적들...
💡 개념
- 깊은 복사
- [참고] : https://blog.naver.com/hjy5405/222581849287<import copy
copy_codelist = copy.deepcopy(df_target['Code List'])💡itertools.chain(*iterables)
def chain(*iterables):
# chain('ABC', 'DEF') --> A B C D E F
for it in iterables:
for element in it:
yield element
[참고] https://docs.python.org/ko/3/library/itertools.html<# 계속 리스트라서 안된다고 오류가 나서, 리스트를 풀어봄
import itertools
code_list = list(itertools.chain(*copy_codelist.to_list()))
copy_codelist# set() : 중복 제거
# [참고] https://blog.naver.com/jiwons0803/222670062938
def codelist(nums):
return set(nums)
def main():
print(copy_codelist)
if __name__ == '__main__':
main()💡다중 조건 정렬
- lambda :
- [참고] : https://pearlluck.tistory.com/462
- 오름차순 정렬 : sorted(a, key=lambda x : x[0])
- 내림차순 정렬 : sorted(a, key=lambda x : -x[0])<# values 값으로 오름차순 정렬
val = sorted(copy_codelist, key=lambda x : x[0])# 3-2
# set() : 집합으로 만드는 명령어
# list.count() : 리스트변수.count(value)
result_df =
check_03_02(result_df)
result_df
비전공자의 데이터 공부법