1. Cost Function
📌 에러를 표현하는 도구
- 최소값 지점 찾기
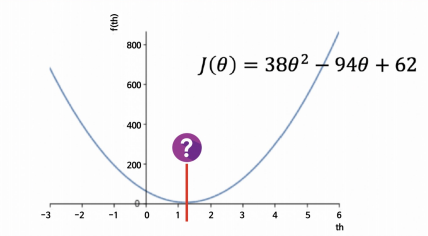
import sympy as sym
# Symbol : 기호로 인식됨
theta = sym.Symbol('theta')
# diff : 미분하세요
diff_th = sym.diff(38*theta**2 - 94*theta + 62, theta)
diff_th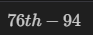
94/76- 1.236842105263158 지점
-
데이터 = 모델
- 에러는 '0'
-
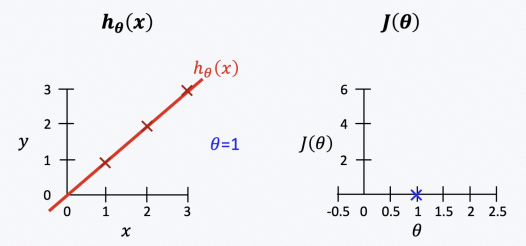
데이터 != 모델
- 에러가 '증가'
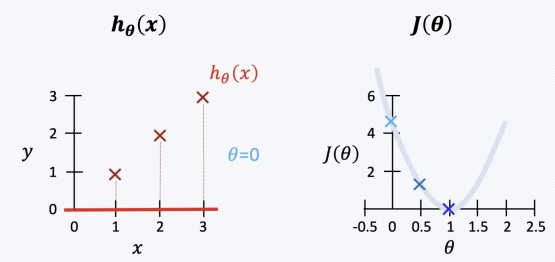
2. Gradient Descent
- 개념 설명
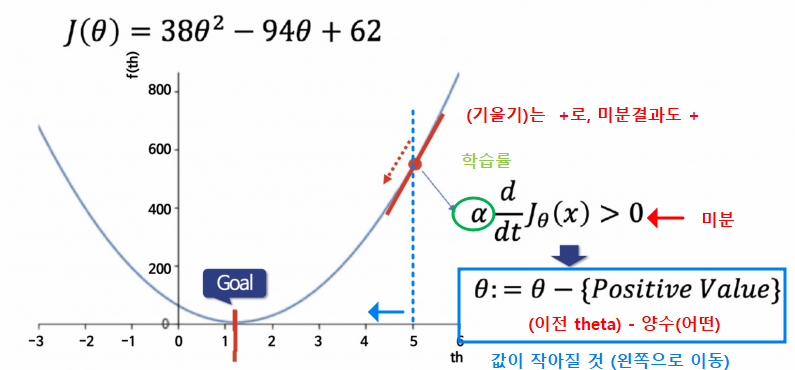
- 즉 !
Gradient Descent 는 미분을 해서 어디로(오/왼) 가야할지 정하는 것
3. 다변수 데이터에 대한 회귀
- feature : 여러개의 특성
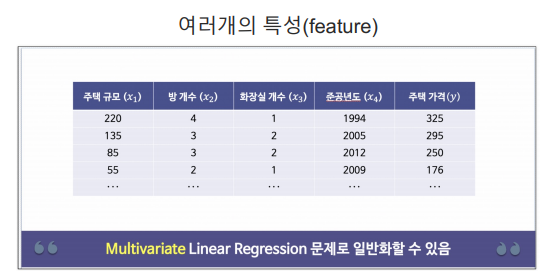
보스턴 집값 예측
the boston house-price data of Harrison, D. and Rubinfeld, D.L. 'Hedonic prices and the demand for clean air'
강의 시 제공해준 seaborn이 제대로 실행되지 않아, csv 파일로 진행
- 데이터 읽기
import pandas as pd
boston_url = 'https://raw.githubusercontent.com/blackdew/tensorflow1/master/csv/boston.csv'
boston = pd.read_csv(boston_url)- key값 확인
boston.keys- 컬럼 확인
boston.columnsIndex(['crim', 'zn', 'indus', 'chas', 'nox', 'rm', 'age', 'dis', 'rad', 'tax',
'ptratio', 'b', 'lstat', 'medv'],
dtype='object')
- 컬럼 예쁘게 확인
[each for each in boston.columns]['crim',
'zn',
'indus',
'chas',
'nox',
'rm',
'age',
'dis',
'rad',
'tax',
'ptratio',
'b',
'lstat',
'medv']
- 전체 데이터 확인
boston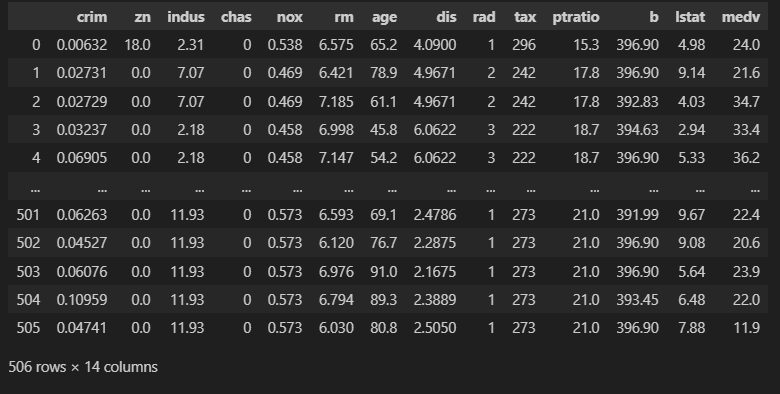
- 데이터 파악을 위해 pandas로 정리
- csv 파일을 불러와서 이미 df 임, 생략
- ['medv'] -> ['price']
강의 자료와 동일시 하기 위해 컬럼명 변경
# 데이터 파악을 위해 pandas로 정리 (csv로 이미 되어 있어서 생략)
# 컬럼명 변경
boston.columns.values[13] = 'price'
boston.head(2)
- 상관계수 확인
#모듈
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
# 상관계수 변수 = df.상관계수 함수().소수점 첫쨰자리
corr_mat = boston.corr().round(1)
# 사이즈 설정
sns.set(rc={'figure.figsize':(18,8)})
# 히트맵 (상관계수 변수, 숫자를 기록해주세요, 컬러)
sns.heatmap(data=corr_mat, annot=True, cmap='bwr')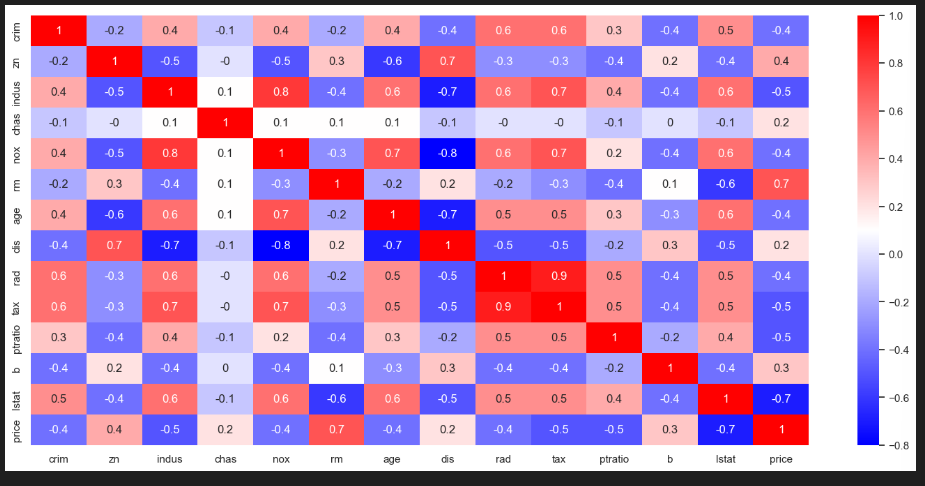
- RM과 LSTAT와 PRICE의 관계 보기
sns.set_style('darkgrid')
sns.set(rc={'figure.figsize':(18,8)})
# 컬럼의 개수는 2개(그래프 2개 그릴 것임)
fig, ax = plt.subplots(ncols=2)
# 위에서 medv -> price 컬럼명을 바꿨지만, 그래프가 생성되지 않아, 그대로 [medv] 사용
# regplot(방수, 가격, 왼쪽)
sns.regplot(x='rm', y='medv', data=boston, ax=ax[0])
# regplot(하위계층, 가격, 왼쪽)
sns.regplot(x='lstat', y='medv', data=boston, ax=ax[1])
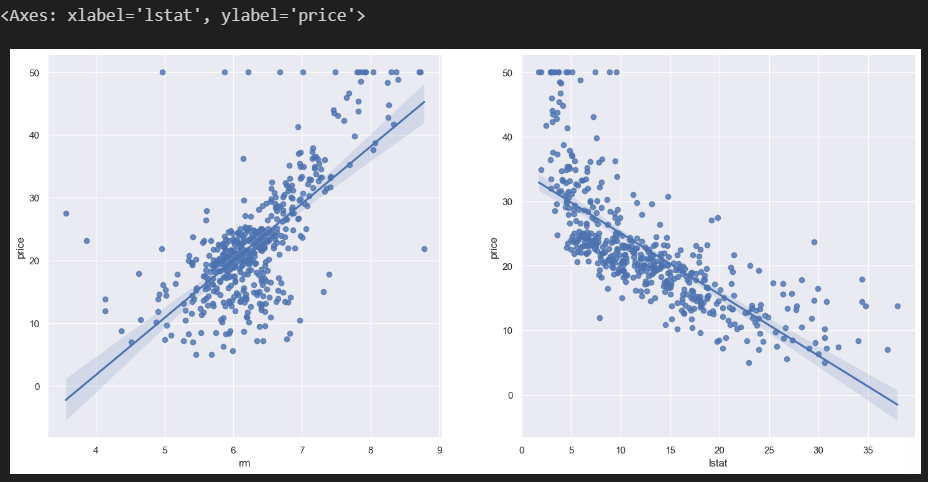
- 데이터 나누기
from sklearn.model_selection import train_test_split
X = boston.drop('medv', axis=1)
y = boston['medv']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)- LinearRegression (학습)
from sklearn.linear_model import LinearRegression
reg = LinearRegression()
reg.fit(X_train, y_train)- RMS (평가)
import numpy as np
from sklearn.metrics import mean_squared_error
# predict
pred_tr = reg.predict(X_train)
pred_test = reg.predict(X_test)
# mean_squared_error (선형 회귀 에서 주로 사용)
# 루트(np.sqrt)(mean_squared_error(참값, pred_tr-예측값))
rmse_tr = (np.sqrt(mean_squared_error(y_train, pred_tr)))
rmse_test = (np.sqrt(mean_squared_error(y_test, pred_test)))
print('RMSE of Train Data : ', rmse_tr)
print('RMSE of Test Data : ', rmse_test)RMSE of Train Data : 4.642806069019824
RMSE of Test Data : 4.9313525841467145
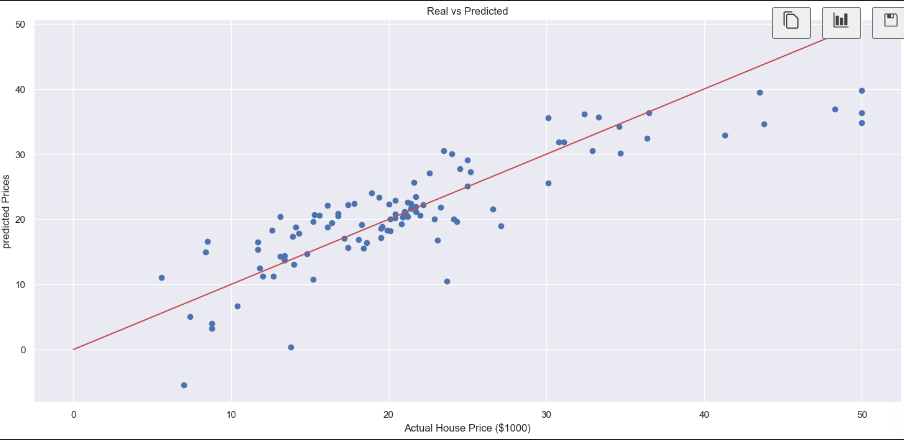
- 성능 확인 (그래프로 확인)
import matplotlib.pyplot as plt
# plt.scatter(x=참값, y=예측값)
plt.scatter(y_test, pred_test)
plt.plot([0,48], [0,48], 'r')
plt.xlabel("Actual House Price ($1000)")
plt.ylabel("predicted Prices")
plt.title("Real vs Predicted")
plt.show()

비전공자의 데이터 공부법