1
Beautiful Soup에서 soup이라는 변수에 어떤 사이트를 읽은 정보가 담겨있을 때, 특정 id를 이용해서 찾는 방법은?
soup.find_all(id=‘some_id’)2
다음 중 ppp.com 이라는 웹페이지를 열기 위한 명령어
BeautifulSoup("ppp.com", "html.parser")- [참고]
url = 'https://finance.naver.com/marketindex/'
page = urlopen(url)
# 종류 : page, response, res
soup = BeautifulSoup(page, 'html.parser') # 엔진 넣어주고
print(soup.prettify())3
Beautiful Soup에서 soup이라는 변수에 어떤 사이트를 읽은 정보가 담겨있을 때, 특정 class를 이용해서 찾는 방법
soup.find_all(class_="readable")4
태그를 찾은 결과에서 태그내의 글자를 가져오는 방법
- soup.find_all("tag1", "class1")[0].get_text()
- soup.find("tag2").get_text()
- soup.find("tag1", "class1").get_text()5
Beautiful Soup 특정 태그 찾기



6
urllib의 quote함수 란?
주소에 한글이 포함된 경우에 인코딩을 맞춰준다7
pandas의 unique() 함수
-해당컬럼에서 한 번 이상 등장한 데이터를 한 번만 표현한다
-해당함수를 사용해서 이상한 데이터를 확인해 볼 수 있다
-unique() 검사의 결과는 array로 반환된다[참고]
8
urllib.parse.urljoin()
urljoin 명령
- 상대 주소와 절대 주소에 대해 잘 대응해준다
- 상대 주소를 절대 주소로 변환해 준다
- 절대주소를 지정해 주어야 한다[참고]
9
regularexpression 에서 000-0000-0000의 패턴을 지정
-> 정규표현식 을 묻는 문제
\d+\s-\s\d+\s-\s\d+10
pandas 상관계수 함수
corr
11
영화 제목 태그를 가져오기 위한 코드
- soup.find_all("div", "tit5")[0].a.string
- soup.select(".tit5")[0].find("a").text
- soup.select(".title5")[0].select_one("a").get_text()12
seaborn 에서 데이터를 선형의 모델로 표현해주는 기능을 가진 그래프
lmplot13
matplotlib 에서 x축 데이터 표기의 축을 변환하는 코드
plt.xticks(rotation="vertical")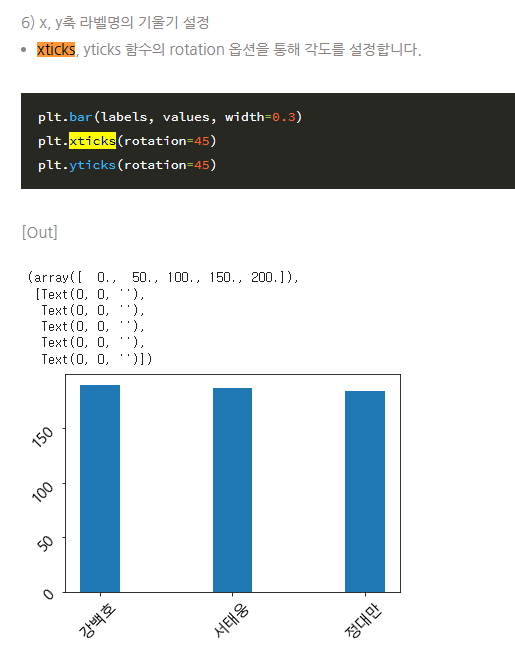
14
BeautifulSoup(이하 bs)에 대한 설명
- bs는 웹 주소를 정확히 알고 있어야 한다
- bs에서는 동적 페이지에 접근하기 위해 selenium을 호출 할 수 있다
-
bs를 이용하면 웹페이지내에서 원하는 태그에 담겨있는 정보를 얻을 수있다15
파이썬에서 쌍따옴표(")와 따옴표(')와 세 개 연달아 사용하는 따옴표(''')에 대한 설명
- 쌍따옴표 안의 문자열에 따옴표가 있을 수 있다
- 셋 연달아 사용하는 따옴표는 그 안에 쌍따옴표나 따옴표가 다 올 수 있다
- 셋 연달아 사용하는 따옴표는 줄 바꿈도 포함될 수 있다16
셀레니움에서 driver 라는 변수에 지정된 웹페이지의 소스코드를 가져오는 명령
driver.page_source17
pandas 에서 형식이 동일하고 연달아 붙이기만 하면 될 때 데이터 프레임을 병합하는 명령어
concat★ 헷갈리지 말것
두 데이터 프레임을 합치는 명령어
merge18
urllib 라이브러리 기능 중 url 주소에 대한 분석 기능이 있는 것을 골라주세요.
19
데이터 전처리를 위해 사용한 pandas 기능
pivot_table
비전공자의 데이터 공부법