1. 개요
1) 강의 소개 및 목표
- 본 강의는 트랜스포머(Transformers)와 머신러닝, 그리고 AI가 우리 삶에서 얼마나 중요한 부분이 되었는지 예측하고 시작되었으며, 현재 거대 언어 모델(LLMs)과 AI가 세상을 주도하고 있음을 확인했습니다.
- 예시로는 ChatGPT나 이미지/비디오 생성 모델인 Sora 등이 있습니다.
- 강의 목표는 수강생들이 트랜스포머의 작동 원리를 배우고, 업계 및 학계 전문가들의 최첨단 연구를 접하여 AI 기술 발전에 기여하도록 돕는 것입니다.
- 강의 구성은 보통 매주 업계 또는 학계의 선도적인 연구자를 초빙하여 트랜스포머 관련 최신 주제에 대해 강연하는 방식으로 진행됩니다.
- 이번 첫 강의는 트랜스포머의 기본을 다루며, 사전 학습(Pre-training) 및 데이터 전략, 후속 학습(Post-training), 그리고 응용 분야 및 남아있는 과제/약점에 초점을 맞추어 구성되었습니다.
2) 트랜스포머 기본 구조 및 작동 원리
- 트랜스포머와 LLM의 근본적인 아키텍처를 이해하는 것이 주요 학습 내용 중 하나입니다.
(1) 단어 임베딩 (Word Embeddings)
- 단어는 숫자가 아니기 때문에 모델에 그대로 입력할 수 없으므로, 첫 단계는 단어를 고차원 공간의 밀집 벡터(dense vectors)로 변환하는 것입니다.
- 임베딩의 목표는 의미론적 유사성(semantic similarity)을 포착하는 것입니다. 예를 들어, '고양이(cat)'와 '개(dog)'는 '고양이'와 '자동차(car)'보다 의미적으로 더 유사하게 표현됩니다.
- 이를 통해 시각화, 트랜스포머 모델을 사용한 학습, 또는 산술 연산(예: King - Man + Woman Queen)이 가능해집니다.
- 고전적인 방법으로는 Word2Vec, FastText 등이 있습니다.
- 정적 임베딩(Static embeddings)은 문맥과 상관없이 단어에 동일한 의미를 부여하는 한계가 있습니다 (예: '은행(bank)'이 '강둑'과 '금융 기관'에서 모두 같은 벡터를 가짐).
- 현재 표준은 단어가 문장 내에서 처한 문맥(context)을 고려하는 문맥적 임베딩(contextual embeddings)을 사용하는 것입니다.

(2) Self-Attention 메커니즘
- 자기 주의는 주어진 토큰에 대해 무엇에 집중해야 하는지 학습하는 데 적용됩니다.
- 이를 위해 세 가지 행렬인 쿼리(Query, Q), 키(Key, K), 값(Value, V)을 학습하며, 이들이 주의(Attention) 과정을 구성합니다.
- 도서관 비유:
- 찾고자 하는 주제(질문)는 쿼리(Query)입니다.
- 각 책에 붙어 있는 요약(주제)은 키(Key)입니다.
- 쿼리와 키를 일치시켜 원하는 책에 접근할 수 있으며, 책 안에 있는 정보가 값(Value)입니다.
- 주의 메커니즘에서는 값(Value)들에 대한 소프트 매치(soft match)를 수행하여 (여러 책으로부터) 정보를 얻게 됩니다.
- 언어에 적용할 때, 모델의 레이어를 거치며 서로 다른 단어들이 문장 내 다른 단어들과 연결되는 것을 볼 수 있습니다.
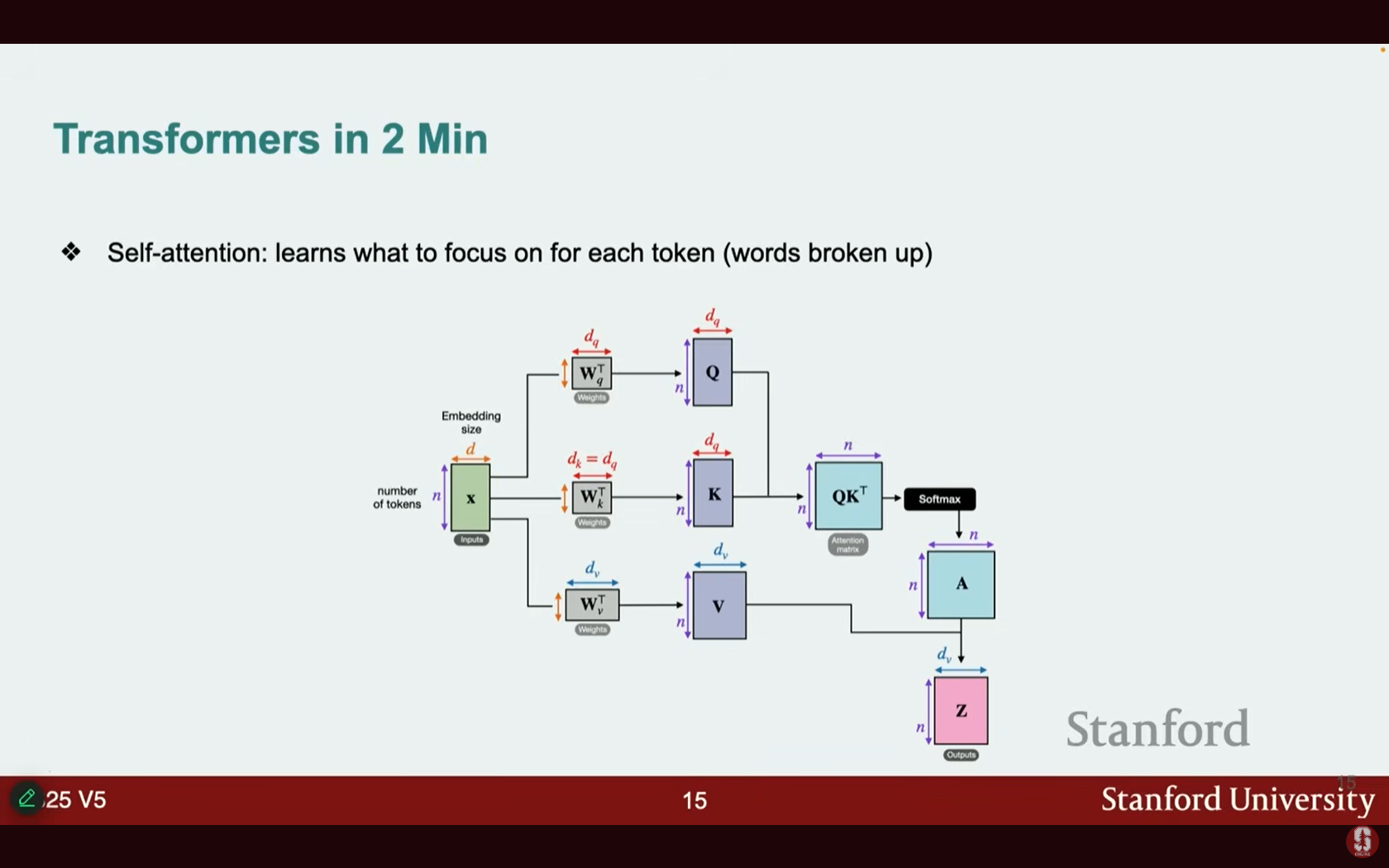

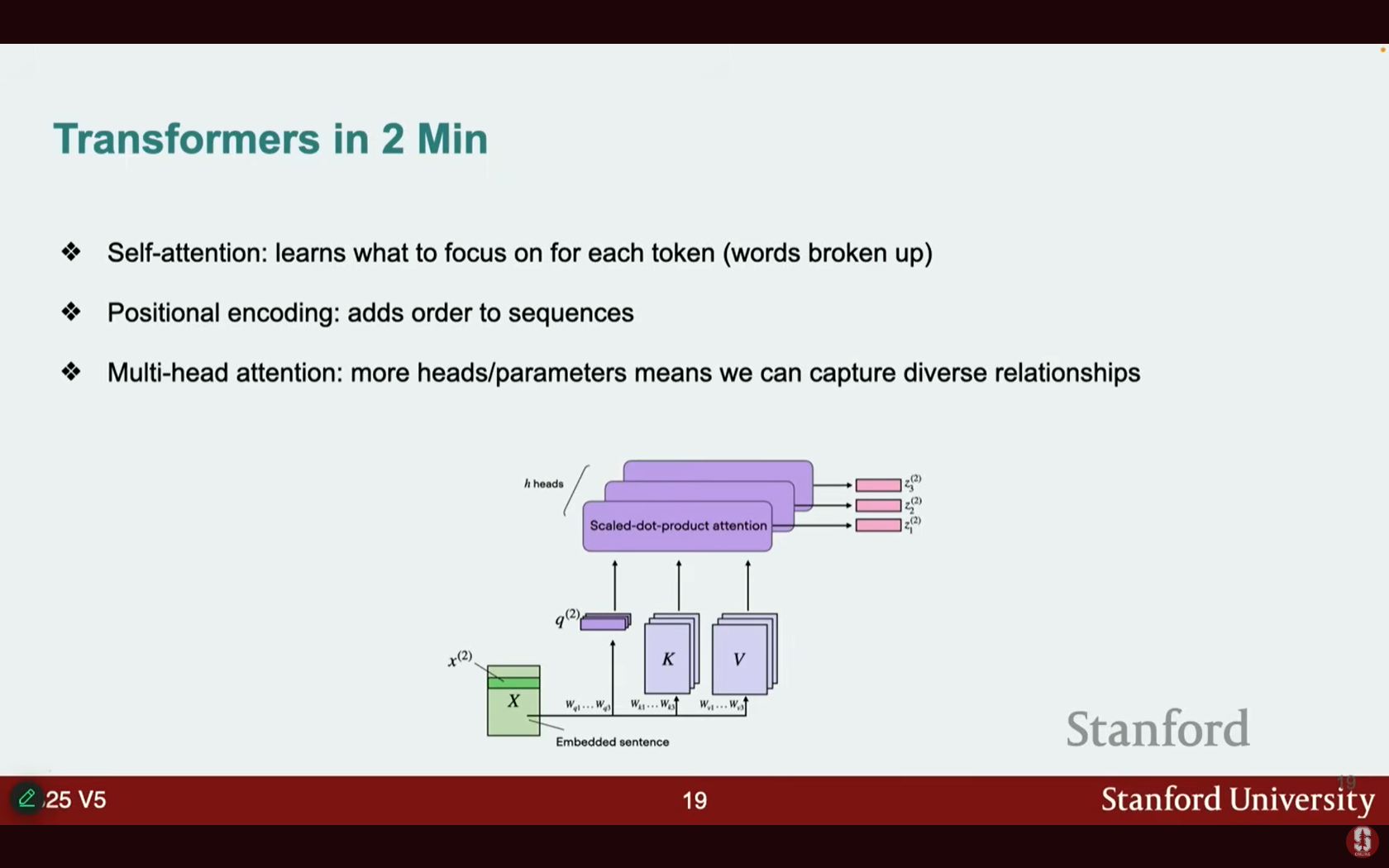
(3) 위치 인코딩 및 멀티 헤드 주의 (Positional Encodings and Multi-Head Attention)
- 위치 인코딩/임베딩 (Positional Encodings/Embeddings)은 시퀀스에 순서 정보를 추가합니다.
- 이 기능이 없으면, 모델은 단순히 선형 곱셈만을 수행하기 때문에 문장의 첫 단어와 마지막 단어를 구분할 수 없습니다.
- 위치 인코딩은 사인파(sinusoids)를 사용하거나, 가장 간단하게는 첫 단어에 0, 두 번째 단어에 1을 부여하는 방식으로 순서 개념을 추가합니다.
- 멀티 헤드 주의 (Multi-head attention)는 여러 개의 '헤드'를 사용하여 문장의 다른 부분에 주의를 기울이게 합니다.
- 헤드가 많고 파라미터가 많을수록 시퀀스로부터 더 다양한 관계(diverse relationships)를 포착할 수 있으며, 이로써 최종 트랜스포머가 구성됩니다.
(4) LLMs와 트랜스포머의 응용
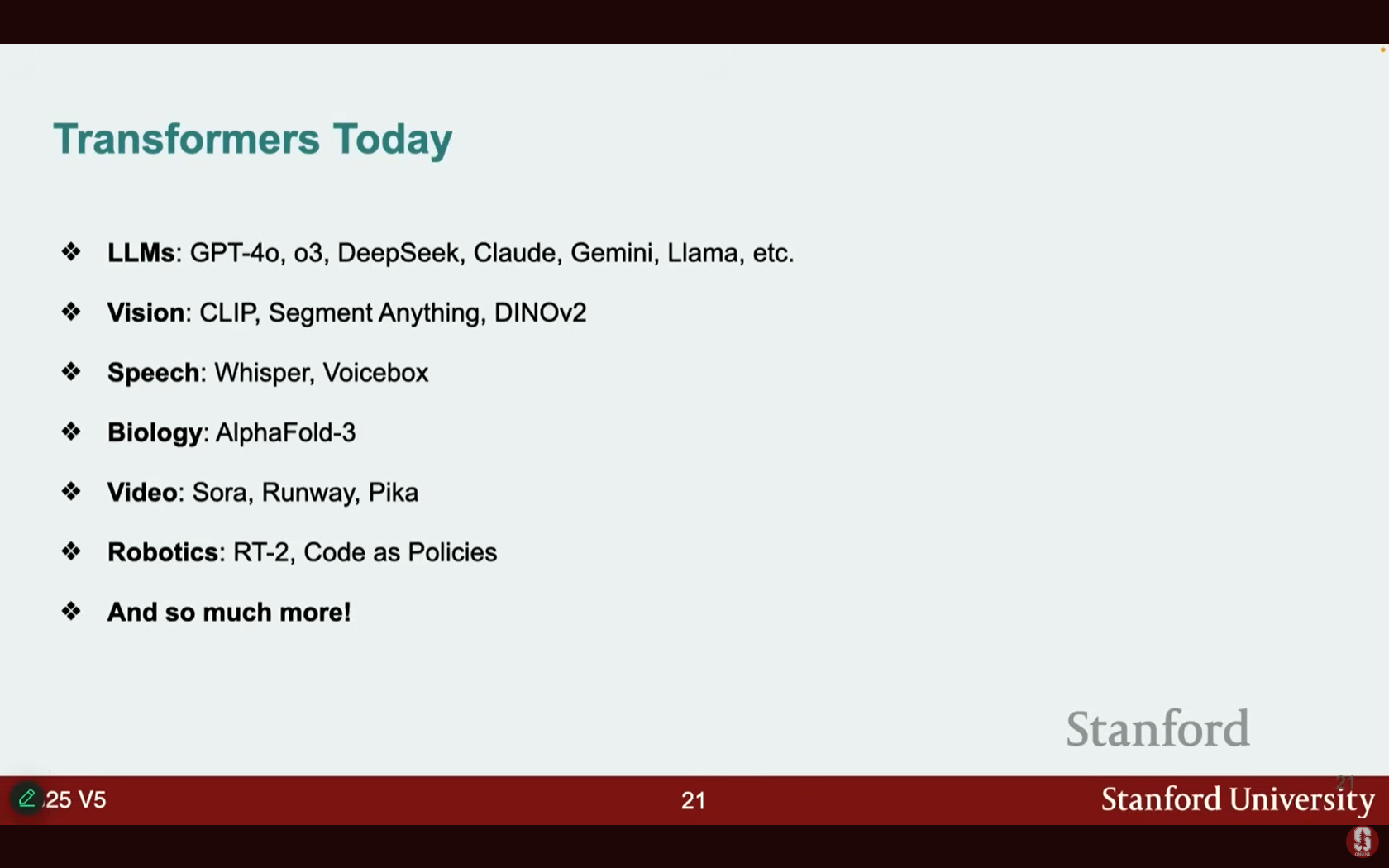
- 오늘날 트랜스포머는 거의 모든 분야를 장악했습니다.
- LLMs (Large Language Models): GPT-4o, DeepSeek 등이 있으며, 이들은 본질적으로 주의(Attention) 및 트랜스포머 아키텍처의 확장된 버전(scaled up versions)입니다.
- LLM 작동 방식: 웹에서 가져온 일반 텍스트 데이터와 같은 방대한 양의 데이터를 모델에 투입하며, 다음 토큰 예측(next token prediction) 목표를 통해 언어를 매우 잘 모델링하도록 학습합니다.

- 심화 내용: 규모의 효과 및 한계
- 발현적 능력 (Emergent Abilities): 모델 규모가 특정 수준에 도달하면, 이전에는 수행할 수 없었던 특정 작업을 갑자기 수행할 수 있는 능력이 나타납니다.
- 단점: 이러한 모델은 높은 계산 비용이 필요하며, 이는 기후 및 탄소 배출 관련 우려를 낳습니다.
- 더 큰 모델은 많은 능력과 작업에 걸쳐 일반화(generalizing) 능력이 뛰어나며, 제로샷 학습(zero-shot learning)을 통해 '플러그 앤 플레이' 방식처럼 사용할 수 있습니다.
- 응용 분야: 언어 외에도 비전(Vision) (세분화 모델), 음성(Speech), 생물학(Biology), 비디오(Video), 로보틱스(Robotics) 등 다양한 분야에서 활용됩니다.
2. 사전 학습(Pre-training) 및 데이터 전략
- LLM의 학습은 크게 두 단계로 나뉩니다: 사전 학습(Pre-training)과 후속 학습(Post-training).
1) 사전 학습의 중요성
- 사전 학습 단계에서는 신경망을 무작위로 초기화된 가중치부터 훈련시켜 보다 일반적인 능력(general capabilities)을 얻게 됩니다.
- 데이터는 모델이 학습하는 근본적인 연료입니다.
- 사전 학습의 목표는 방대한 양의 데이터로 훈련하여 일반적인 수준의 능력, 지식, 또는 지능을 얻는 것입니다.
- LLM은 이전 토큰을 기반으로 다음 토큰을 예측하는 통계적 분포를 학습하기 때문에 효과적인 학습을 위해서는 대규모의 데이터가 필요합니다.

2) 작은 규모 모델과 아동 지향 데이터 (Small Scale & Childlike Data)

- 연구 동기: 인간은 LLM보다 수백 배 적은 언어 데이터로도 효율적으로 언어를 학습합니다. 왜 인간은 그렇게 효율적으로 학습할 수 있을까에 대한 의문을 제기합니다.
- 인간 학습과의 차이점:
- 연속적 학습 (Continuous Learning): 인간은 지속적으로 학습하지만, 현재 모델들은 대부분 한 번의 패스로 끝나는 사전 학습(single pass pre-training) 모델입니다.
- 목표 기반 상호작용 (Goal-based Interaction): 인간은 환경과의 상호작용을 통해 목표 기반으로 학습하지만, 모델은 단순히 다음 토큰 예측으로 사전 학습합니다.
- 연속적 멀티모달/다감각 데이터 (Multimodal/Multisensory Data): 인간은 텍스트뿐 아니라 수많은 감각에 무의식적으로 노출됩니다.
- 구조적/계층적 학습 (Structured/Hierarchical Learning): 인간의 뇌는 단순히 다음 토큰 예측이 아닌 구성성(compositionality)과 같은 구조화된 방식으로 학습할 수 있습니다.

- 작은 모델 학습의 이점:
- LLM 훈련 및 사용의 효율성을 크게 향상시킵니다 (예: 휴대폰에서 로컬 실행 가능).
- 해석 가능성(Interpretability) 및 제어/정렬(Control or Align)이 용이해집니다 (예: 안전성, 편향 감소).
- 오픈 소스 가용성(Open Source Availability)을 높여 컴퓨팅 자원이 적은 사람들도 연구 및 사용이 가능해집니다.

- 가설: 인간의 효율적인 언어 학습은 노출되는 데이터의 종류, 뇌의 학습 알고리즘, 또는 데이터 수신 방식/구조(커리큘럼) 때문일 수 있습니다.

아동 지향 데이터 실험 (Is Child-Directed Speech Effective?)
- 실험 데이터셋:
- Child: 아동과 보호자 간의 자연스러운 대화 데이터 (자연스러운 잡음이 많음).
- Tiny Dialogues: GPT-4를 사용하여 수집한 합성(synthetic) 데이터셋으로, 제한된 아동 언어 어휘를 사용하고 문법적이며 커리큘럼화되어 있습니다.
- Baby LM: Reddit, Wikipedia 등이 혼합된 이질적인 혼합 데이터(heterogeneous mixture)로, 일반적인 LLM 사전 학습 데이터와 유사합니다.
- Wikipedia, Open Subtitles (영화/TV 자막)
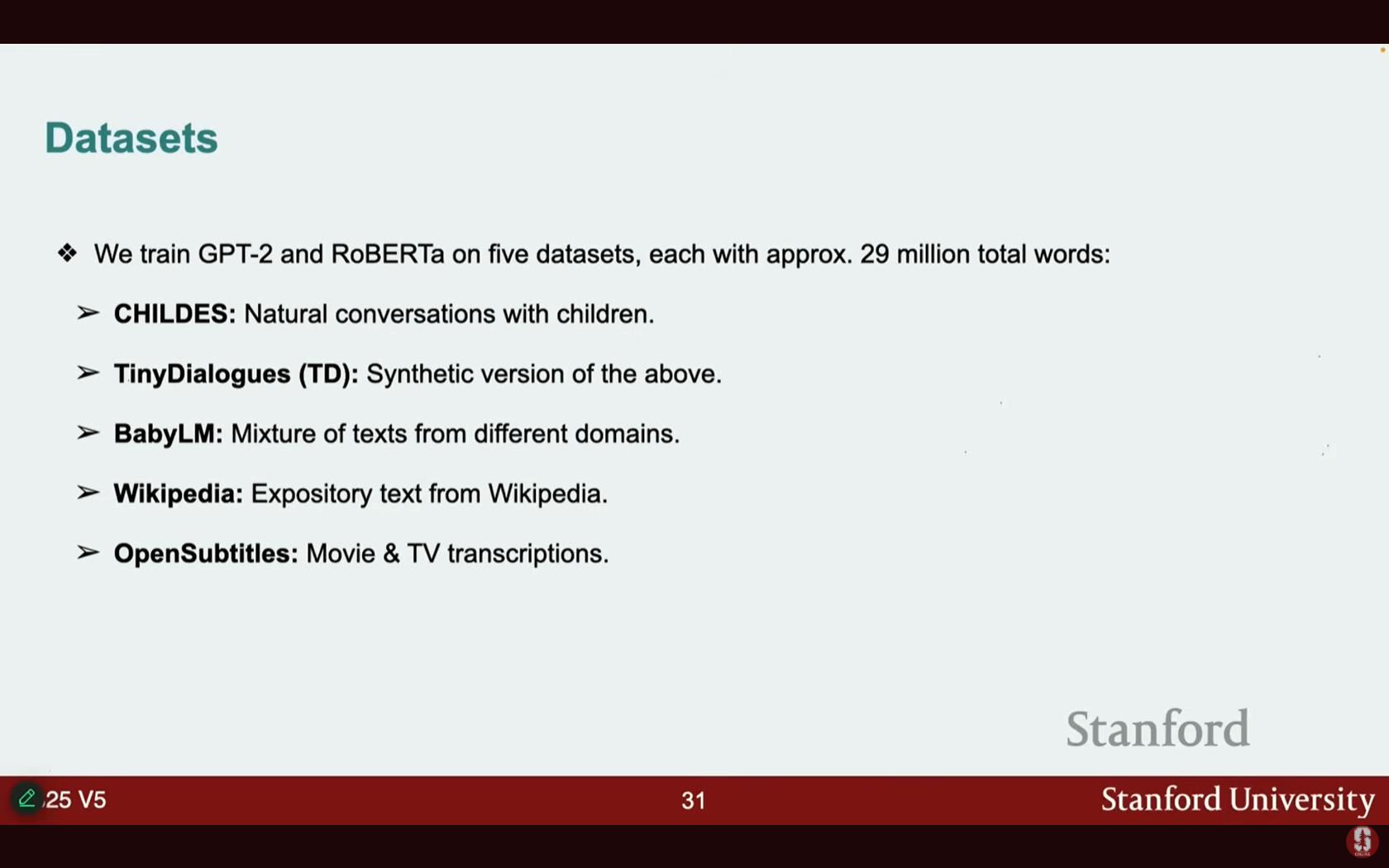


- 커리큘럼 실험: 데이터 예시를 오름차순 연령 순서(ascending age order), 내림차순 순서, 또는 무작위 섞음(randomly shuffling)으로 모델에 제공하여 학습 순서의 영향을 테스트했습니다.

- 결과:
- 데이터 종류: 순수한 아동 지향 데이터(Child)로 훈련하는 것이 BabyLM과 같은 이질적인 인터넷 데이터 혼합보다 성능이 나빴습니다.
- Tiny Dialogues는 자연스러운 Child 데이터셋보다 성능이 눈에 띄게 좋았는데, 이는 합성 데이터셋이 노이즈가 적기(less noisy) 때문일 가능성이 높습니다.
- 커리큘럼 학습: 데이터 예시를 제공하는 순서(글로벌 발달 순서)는 성능에 무시할 수 있는 영향(negligible impact)을 미쳤습니다. 인간은 단순한 것에서 복잡한 것으로 학습하는 것과 대조적입니다.
- 결론: 아이들의 효율적인 언어 학습은 단순히 노출되는 데이터(텍스트)뿐 아니라, 멀티모달 정보 학습이나 인간의 뇌가 근본적으로 다른 학습 알고리즘을 가지고 있기 때문일 수 있습니다.


3) 대규모 모델과 2단계 사전 학습 (Two-Phase Pre-training)
- 연구 목표: 대규모 사전 학습에서 데이터 선택 및 훈련 전략을 최적화하고, 데이터 혼합 비율과 순서에 대한 더 많은 통찰력을 제공하는 것입니다.

- 개념: 2단계 사전 학습 (Two-Phase Pre-training) 방식은 사전 학습을 두 단계로 분리하는 것입니다.
- 1단계: 더 일반적이고 다양한(general and diverse) 데이터로 훈련하여 광범위하게 학습합니다.
- 2단계: 고품질의 도메인 특화(high quality domain specific) 데이터 (예: 수학)로 전환합니다.

- 중요성: 두 단계 모두에서 품질과 다양성 사이의 균형을 맞추는 것이 중요합니다. 특정 데이터셋의 비중을 너무 높이면 과적합(overfitting)으로 이어질 수 있습니다.

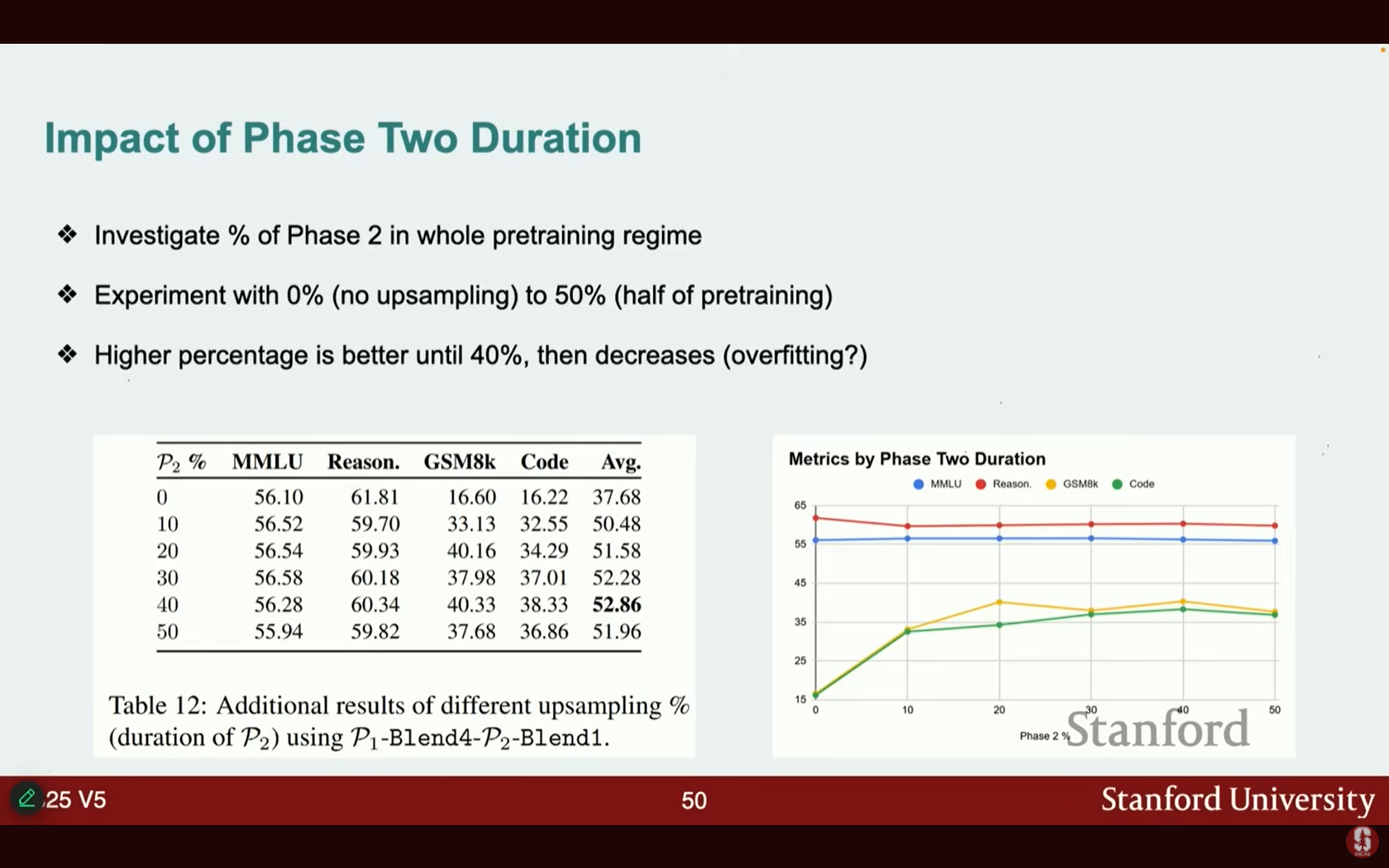
- 결과:
- 효과: 2단계 사전 학습 실험은 단일 단계로 지속적으로 훈련하는 기본 모델보다 눈에 띄게 우수했습니다.
- 규모 확장성: 토큰 수와 모델 크기를 늘려도 2단계 접근 방식은 단일 단계보다 성능이 더욱 향상되었습니다. 이는 대규모 확장 전에 작은 데이터 혼합으로 프로토타이핑하는 것이 효과적임을 시사합니다.

- 2단계 기간: 성능은 2단계 기간이 약 40%에 도달할 때까지 향상되다가, 그 이후에는 특화된 데이터의 다양성이 낮아 과적합 위험으로 인해 성능이 저하되기 시작합니다.
- 전반적 결론: LLM 성능 최적화를 위해서는 단순히 데이터의 양이 아니라 데이터의 품질, 순서, 구조를 활용하는 스마트한 데이터 조직화 및 관리가 필수적입니다.

3. 후속 학습(Post-training) 기술
- 사전 학습된 모델을 특정 작업이나 도메인에 맞게 조정하는 단계입니다.
- 주요 전략에는 미세 조정(Fine-tuning)(예: RLHF), 프롬프트 기반 방법(Prompt based methods), 검색 기반 방법(Retrieval-based methods, RAG 아키텍처) 등이 있습니다.

1) 문제 분해 및 프롬프트 기반 방법
(1) 추론 사슬 (Chain of Thought, CoT)
- 개념: "단계별로 생각하라"는 프롬프트 기법으로, 모델이 중간 단계를 보여주도록 합니다.
- 효과: 인간이 문제를 후속 단계로 분해하여 이해하는 방식과 유사하며, 정답률을 높입니다.
- 장점: 모델의 행동에 대한 해석 가능한 창(interpretable window)을 제공하며, 단순히 응답을 요구하는 것보다 모델 가중치에 더 많은 지식이 내재되어 있음을 시사합니다.


(2) 추론 트리의 확장 (Extensions of CoT)
- 사고의 나무 (Tree of Thought, ToT): CoT가 단일 추론 경로를 생성하는 것과 달리, 여러 개의 추론 궤적(reasoning trajectories)을 고려한 다음, 자체 평가(self-evaluation) 과정(예: 다수결 투표)을 사용하여 최종 출력을 결정합니다.

- 사고의 프로그램 (Program of Thought): 중간 추론 단계로 코드를 생성합니다.
- 언어를 프로그램으로 정형화하여 코드 인터프리터에게 문제 해결을 맡기며, 더 정확한(precise) 답을 얻습니다.

- 언어를 프로그램으로 정형화하여 코드 인터프리터에게 문제 해결을 맡기며, 더 정확한(precise) 답을 얻습니다.
- 소크라테스식 질문 (Socratic Questioning): 자체 질문 모듈을 사용하여 원래 질문과 관련된 하위 문제를 제안하고 이를 재귀적(recursive) 방식으로 해결합니다.
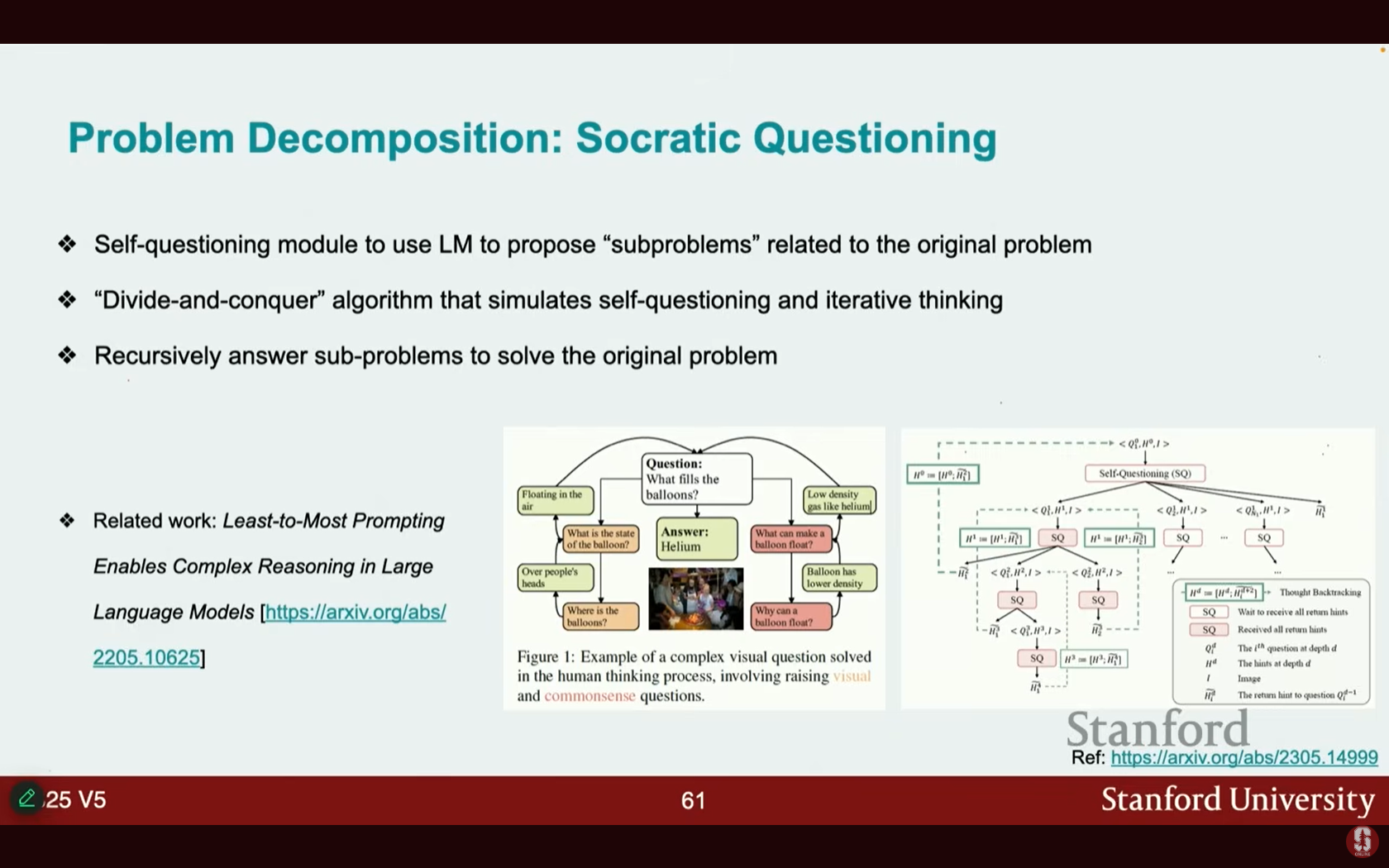
- 계산 그래프 (Computational Graphs): 구성적 작업(compositional tasks)을 계산 그래프로 공식화하고, 추론을 하위 절차와 노드로 분해하여 해결합니다.

2) 강화 학습 및 피드백 메커니즘
- 이는 주로 사전 학습된 모델을 추가로 미세 조정하는 데 사용됩니다.
(1) 인간 피드백 기반 강화 학습 (RLHF)
- Reinforcement Learning with Human Feedback (RLHF): 인간의 피드백으로부터 보상 모델(reward model)을 직접 훈련시키는 방식입니다.
- 사전 학습된 모델이 여러 응답을 생성하면, 인간이 응답 쌍을 선호도에 따라 평가하고, 이를 기반으로 PPO와 같은 강화 학습 최적화 알고리즘을 사용하여 보상 모델을 훈련합니다.
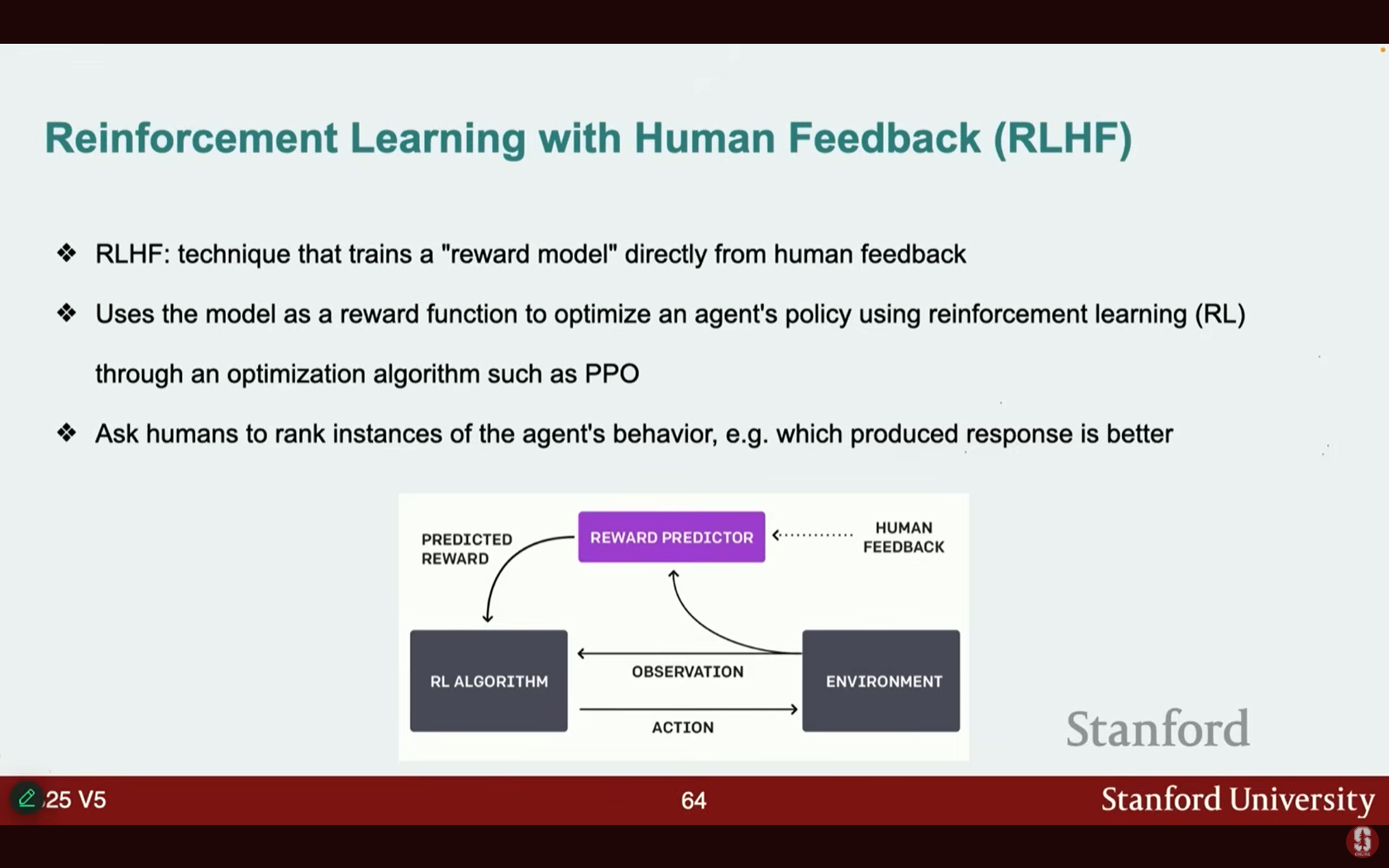
- 사전 학습된 모델이 여러 응답을 생성하면, 인간이 응답 쌍을 선호도에 따라 평가하고, 이를 기반으로 PPO와 같은 강화 학습 최적화 알고리즘을 사용하여 보상 모델을 훈련합니다.
(2) RLHF의 발전된 형태
- 직접 선호도 최적화 (Direct Preference Optimization, DPO): 보상 모델을 별도로 사용하지 않고, 인간이 선호하는 응답을 생성할 가능성을 최대화하고 선호하지 않는 응답을 최소화하도록 모델을 더 직접적으로 훈련시킵니다.
- 이는 보상을 손실 함수 자체에 더 가깝게 연결하여 훨씬 효율적입니다.

- 이는 보상을 손실 함수 자체에 더 가깝게 연결하여 훨씬 효율적입니다.
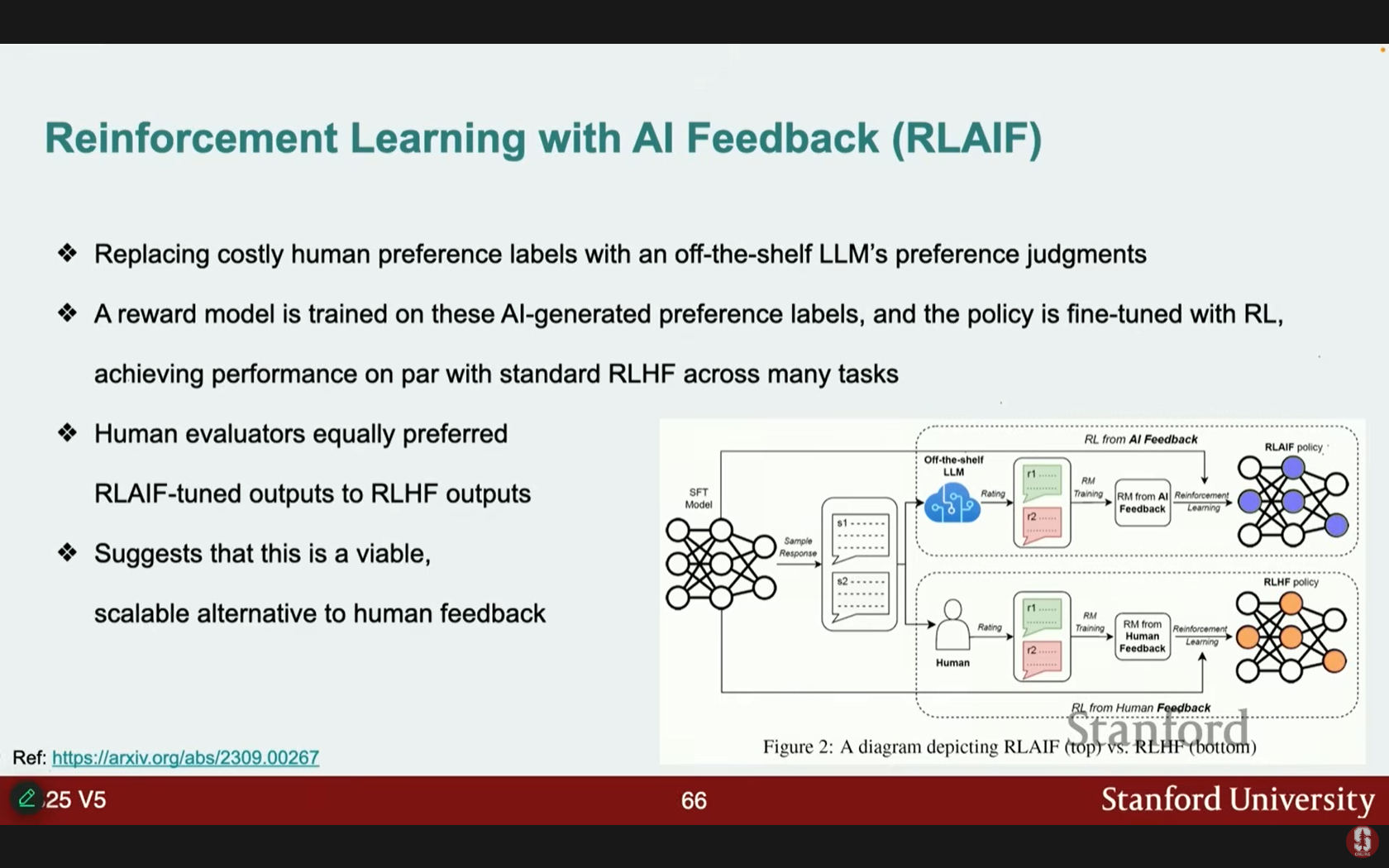
- AI 피드백 기반 강화 학습 (RLAIF): 인간을 AI로 대체하여 선호도 판단을 제공합니다.
- 비용이 적게 들고 확장 가능하며, 훈련된 RLAIF 출력은 RLHF와 유사한 평가를 받았습니다.
- 한계점: 보상 판단을 내리는 LLM의 능력과 정확도에 크게 의존합니다.
- 그룹 상대적 정책 최적화 (Group Relative Policy Optimization, GRPO): PPO 알고리즘의 변형으로, 응답 쌍이 아닌 응답 그룹을 순위 매깁니다.
- 이는 더 풍부하고 세분화된 피드백을 제공하며, 훈련을 안정화하고 특히 수학과 같은 작업에서 LLM 추론 능력을 향상시킵니다 (DeepSeek 모델에서 사용됨).
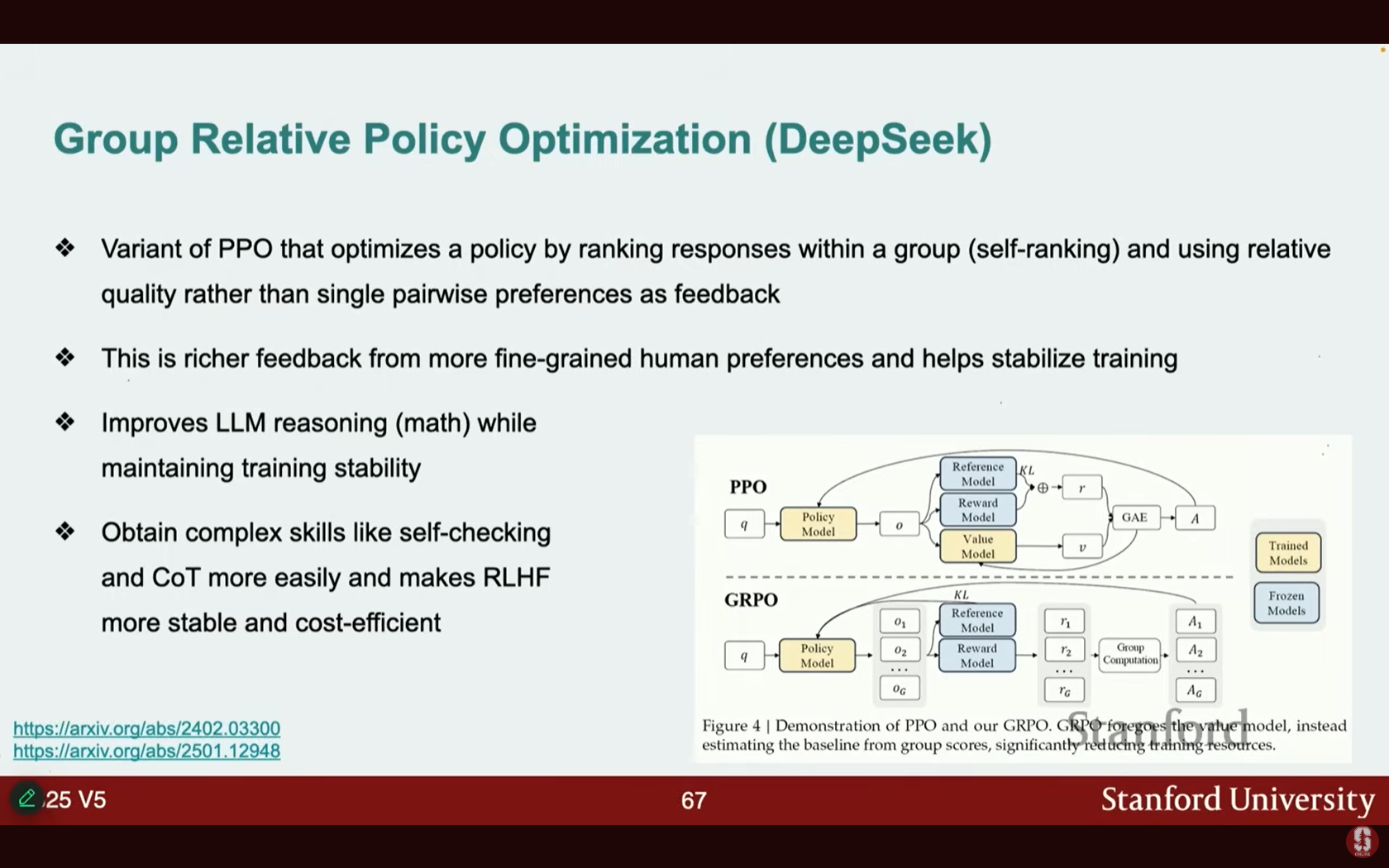
- 이는 더 풍부하고 세분화된 피드백을 제공하며, 훈련을 안정화하고 특히 수학과 같은 작업에서 LLM 추론 능력을 향상시킵니다 (DeepSeek 모델에서 사용됨).
- 손실 회피 기반 최적화 (KTO, Konmani Optimization): 인간의 편향(예: 손실 회피, loss aversion)을 반영하기 위해 표준 손실 함수를 수정합니다.
- 인간은 긍정적인 결과를 얻는 것보다 재앙적인/부정적인 결과를 최소화하는 데 더 신경 쓰는 경향이 있음을 반영하여, AI가 부정적인 결과를 피하도록 장려합니다.

- 인간은 긍정적인 결과를 얻는 것보다 재앙적인/부정적인 결과를 최소화하는 데 더 신경 쓰는 경향이 있음을 반영하여, AI가 부정적인 결과를 피하도록 장려합니다.
- 개인화된 RLHF (Variational Preference Learning): 일반적인 RLHF가 선호도를 평균화하는 것과 달리, 사용자 선호도 프로필(예: 아동, 성인 등 인구통계학적 그룹)마다 잠재 변수를 도입하고, 이 변수에 조건화된 보상 모델을 훈련합니다.
- 이는 다원적 정렬(pluralistic alignment)로 이어져, 단일 모델이 다양한 선호도 프로필에 맞게 행동을 조정할 수 있게 합니다.
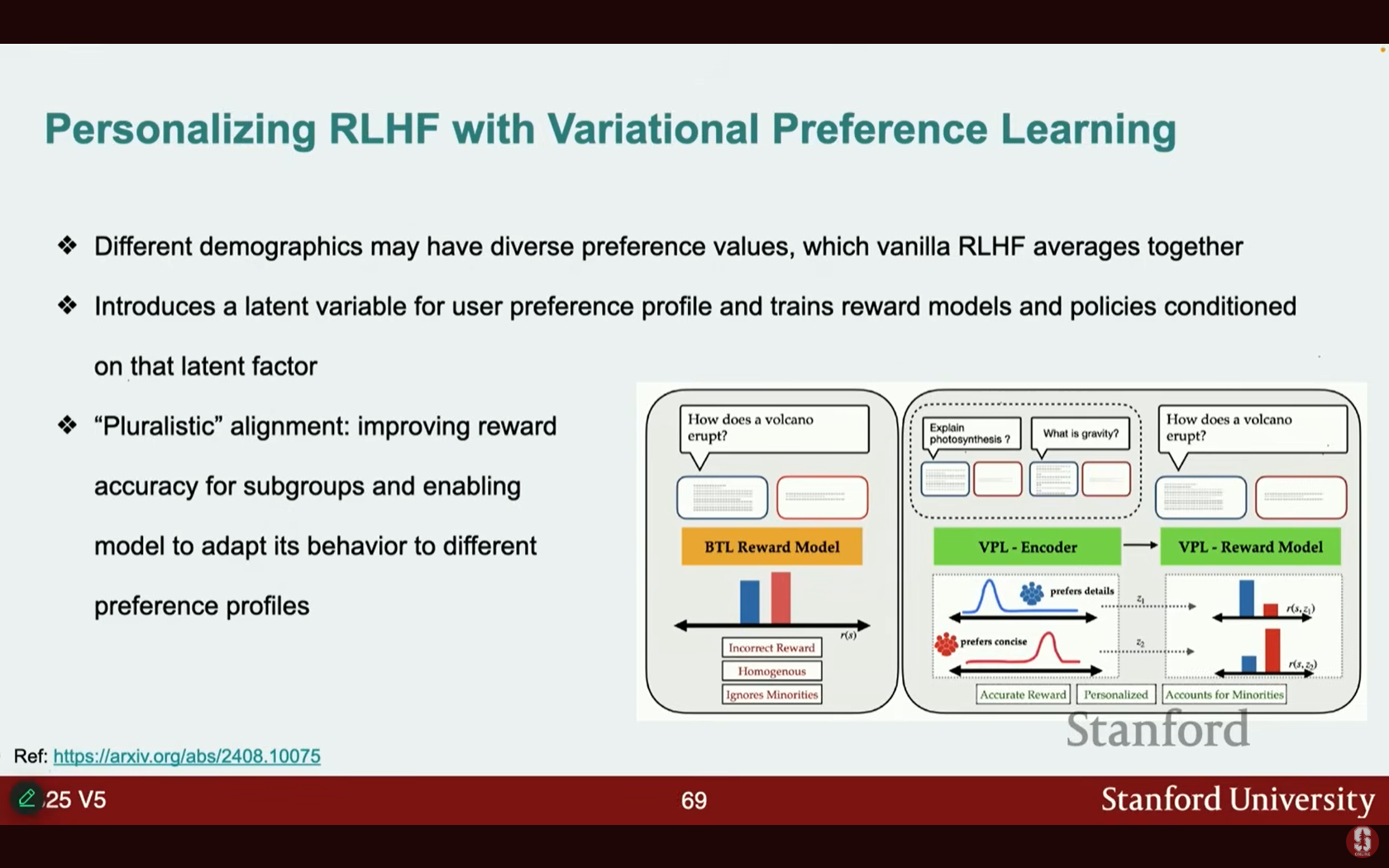
- 이는 다원적 정렬(pluralistic alignment)로 이어져, 단일 모델이 다양한 선호도 프로필에 맞게 행동을 조정할 수 있게 합니다.
3) 자체 개선 AI 에이전트 (Self-Improving AI Agents)
- AI 에이전트 정의: 환경을 인식하고, 결정을 내리며, 특정 목표 달성을 향해 행동을 취하는 시스템입니다 (예: 게임 플레이, 작업 해결, 연구 보조).
- 에이전트 구성 요소:
1. 목표 지향적 (Goal directed)
2. 자체 의사 결정 가능
3. 반복적으로 행동 (Iterative action)
4. 기억/상태 추적 (Memory/state tracking)
5. 도구 사용 (API 호출, 함수 호출)
6. 자체 학습 및 적응 가능

(1) 자체 개선 기법

- 개선 (Refinement): LLM이 자체 출력을 비판하고 개선하는 반복적인 프롬프트 기법입니다.
- 초기 응답을 생성하고, 약점과 불일치를 자체 평가한 다음, 자체 비판을 기반으로 응답을 개선합니다.

- 초기 응답을 생성하고, 약점과 불일치를 자체 평가한 다음, 자체 비판을 기반으로 응답을 개선합니다.
- 자체 반성 (Self-Reflexion): 과거의 실수로부터 학습하고, 장기 기억 구성 요소를 사용하여 과거의 실패를 기반으로 미래의 응답을 조정합니다.
- 여러 반복을 거쳐 정확도와 추론 능력이 향상되어야 합니다.

- 여러 반복을 거쳐 정확도와 추론 능력이 향상되어야 합니다.
- ReAct: 추론(Reasoning)과 외부 행동(Actions)(예: API 호출, 데이터베이스 검색)을 결합합니다.
- 환경과 동적으로 상호작용하며, 여러 행동 시퀀스를 통해 피드백을 받아 이를 출력에 통합합니다.

- 환경과 동적으로 상호작용하며, 여러 행동 시퀀스를 통해 피드백을 받아 이를 출력에 통합합니다.
- 언어 에이전트 트리 탐색 (Language Agent Tree Search, LATS):
- ReAct 프레임워크를 확장하여 다중 계획 경로(multiple planning pathways)를 통합합니다 (CoT 대 ToT와 유사).
- 모든 경로에서 피드백을 수집하여 미래 탐색 과정을 개선하며, 이는 언어적 강화 학습(verbal reinforcement learning)에서 영감을 받은 기법입니다.
- 몬테카를로 트리 탐색 (Monte Carlo Tree Search, MCTS)을 사용하여 계획 궤적을 최적화합니다. 트리 구조에서 각 노드(node)는 상태(state)를, 각 엣지(edge)는 에이전트가 취할 수 있는 행동(action)을 나타냅니다.
- N개의 최적 행동 시퀀스를 생성하고 병렬로 실행하며, 자체 반성 기법으로 점수를 매긴 다음, 최적의 상태에서 탐색을 계속하고 과거 노드의 확률을 업데이트합니다.

4. 언어 외 트랜스포머 응용 분야
1) 비전 트랜스포머 (Vision Transformers, ViT)
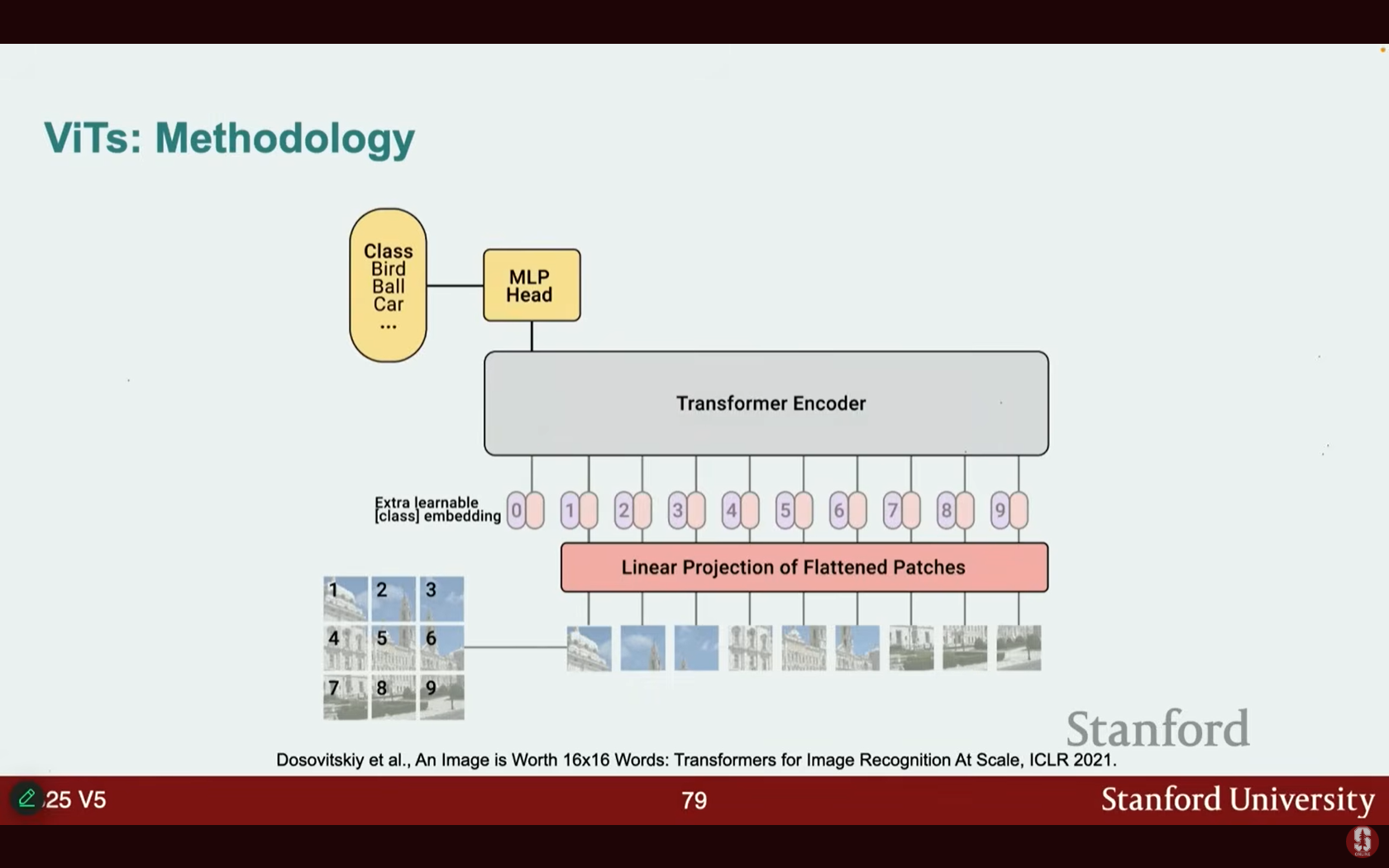
- 원리: 트랜스포머는 시퀀스를 입력받지만, 이미지는 시퀀스가 아닙니다. ViT 연구자들은 이미지를 패치(patches)로 분할한 다음, 이를 임베딩하여 시퀀스를 형성하는 방법을 고안했습니다.
- 이 시퀀스를 단순한 트랜스포머에 통과시키면 분류 등에서 매우 좋은 결과를 얻을 수 있습니다 (MLP 헤드를 끝에 추가).
- CNN과의 비교: ViT를 사용하는 주된 이유는 매우 큰 데이터셋 (수천만 개)을 사용할 때 트랜스포머가 CNN보다 귀납적 편향(inductive biases)이 적기 때문입니다.
- CNN은 국소성(locality, 픽셀이 그룹화됨)을 가정하는 반면, 트랜스포머는 이미지를 시퀀스로 취급하며 데이터가 충분할 때 더 나은 결과를 보입니다.
- CLIP: 이미지 인코더로 ViT를 사용합니다.
- 대조 학습(contrastive learning)을 기반으로 작동하며, 이미지-텍스트 쌍의 데이터셋을 사용하여 이미지와 텍스트의 인코딩된 표현(representations)을 정렬하도록 모델을 훈련합니다.
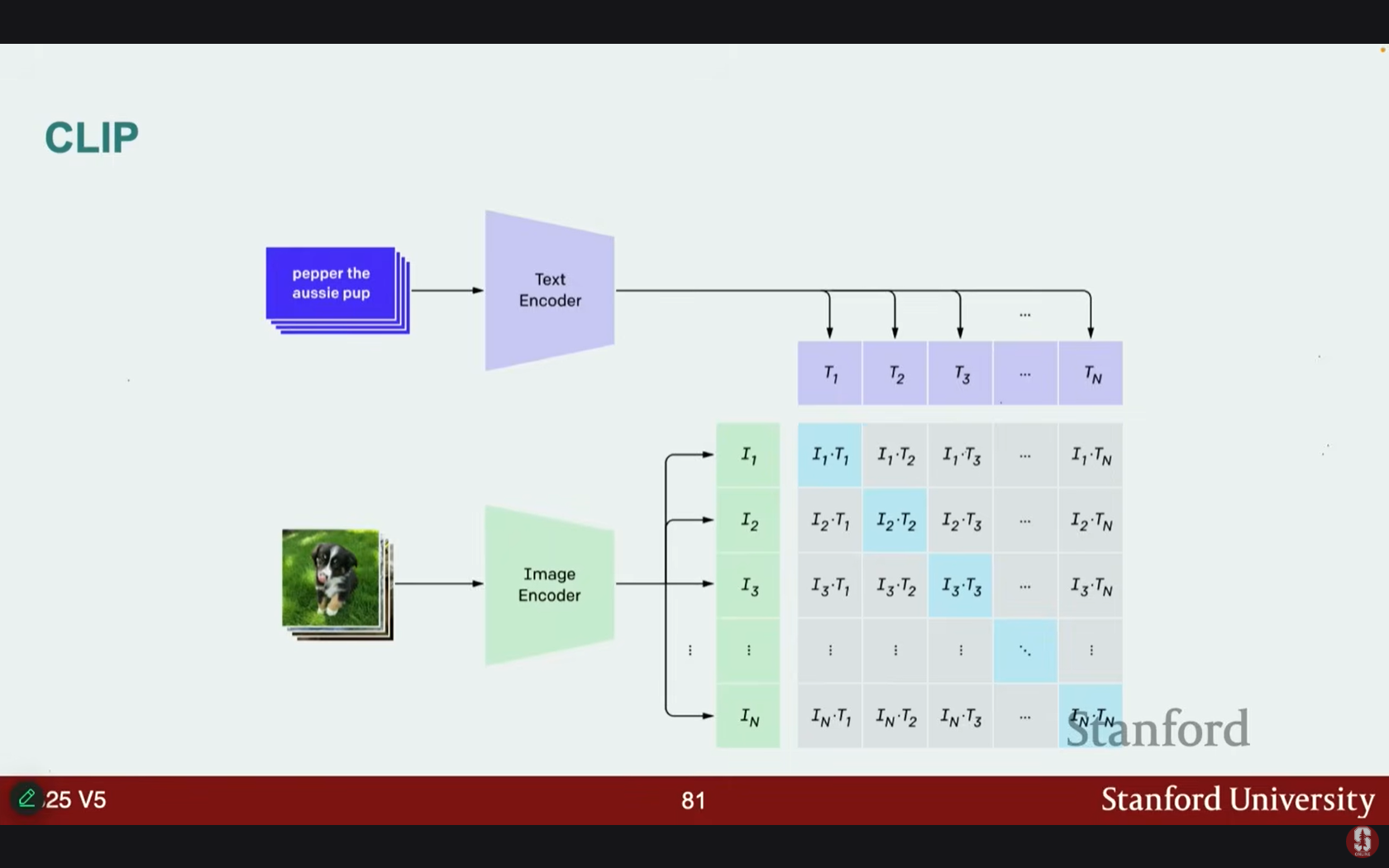
- 대조 학습(contrastive learning)을 기반으로 작동하며, 이미지-텍스트 쌍의 데이터셋을 사용하여 이미지와 텍스트의 인코딩된 표현(representations)을 정렬하도록 모델을 훈련합니다.
- 비전-언어 모델 (Vision-Language Models): GPT-4나 GPT-4o와 같습니다.
- 인코딩된 이미지와 텍스트를 연결(concatenate)하여 훈련하며, 벤치마크 및 작업에서 뛰어난 성능을 보였습니다.
2) 신경과학에서의 응용 (fMRI 및 뇌 활동 예측)
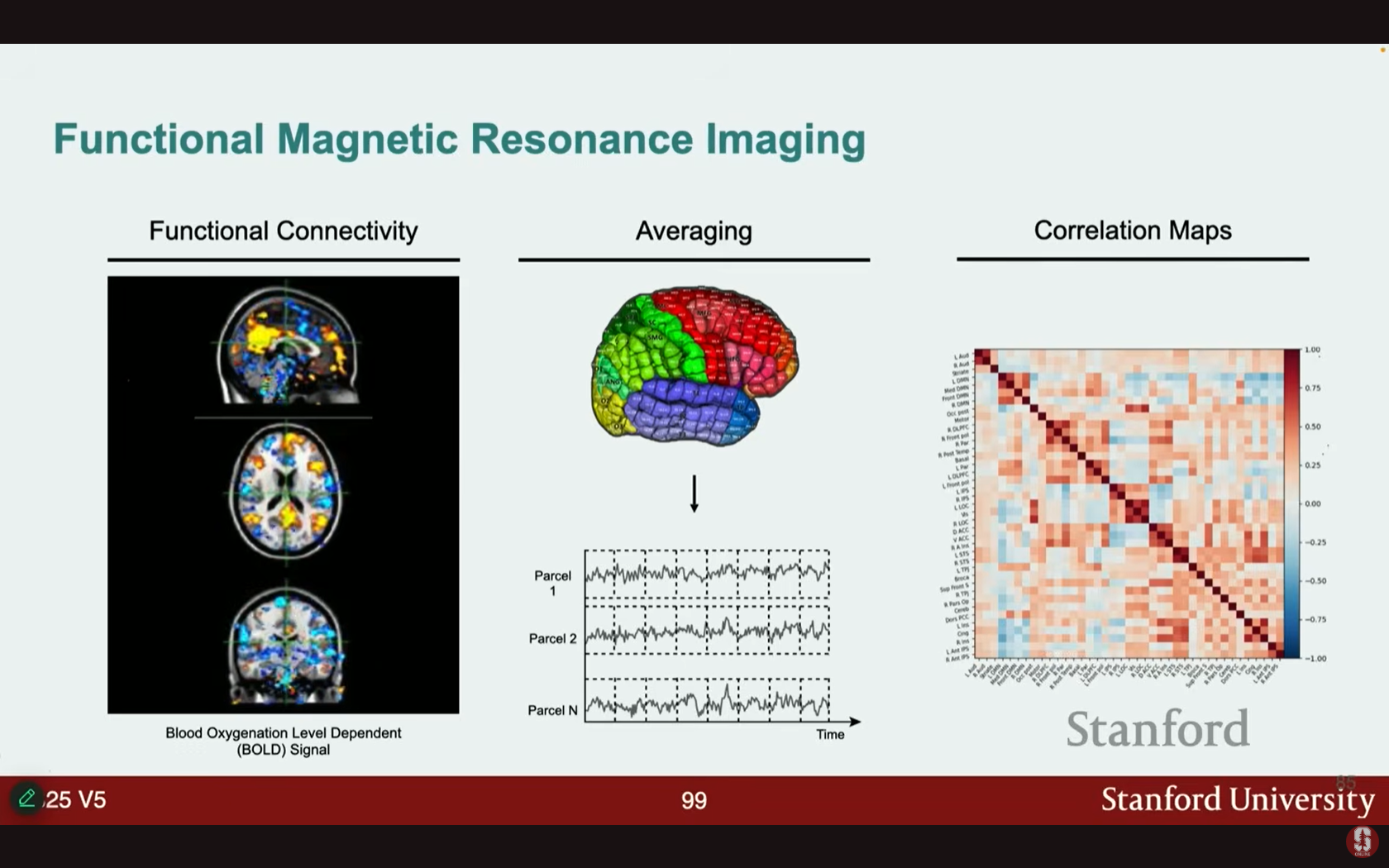
- 기능적 자기공명영상 (fMRI): 뇌의 각 복셀(voxel)이 사용하는 산소량을 포착하며, 뇌 활동에 대한 자세한 대리 지표(proxy)를 제공합니다.
- 질병 진단이나 인지 이해에 사용되지만, 수십만 또는 수백만 개의 복셀을 포함하는 고차원(high-dimensional) 데이터입니다.
- 질병 진단이나 인지 이해에 사용되지만, 수십만 또는 수백만 개의 복셀을 포함하는 고차원(high-dimensional) 데이터입니다.
- 데이터 처리: 트랜스포머 모델에 사용하기 위해 복셀을 잘 알려진 영역이나 그룹으로 평균화하여 파셀(parcels)이라고 불리는 계산적으로 더 다루기 쉬운 수로 만듭니다.
- 전통적 방법의 한계: 초기 ML 모델은 선형 쌍별 상관관계 맵(linear pair-wise correlation maps)을 사용하여 단순한 가정에 기반한 진단을 수행했습니다.
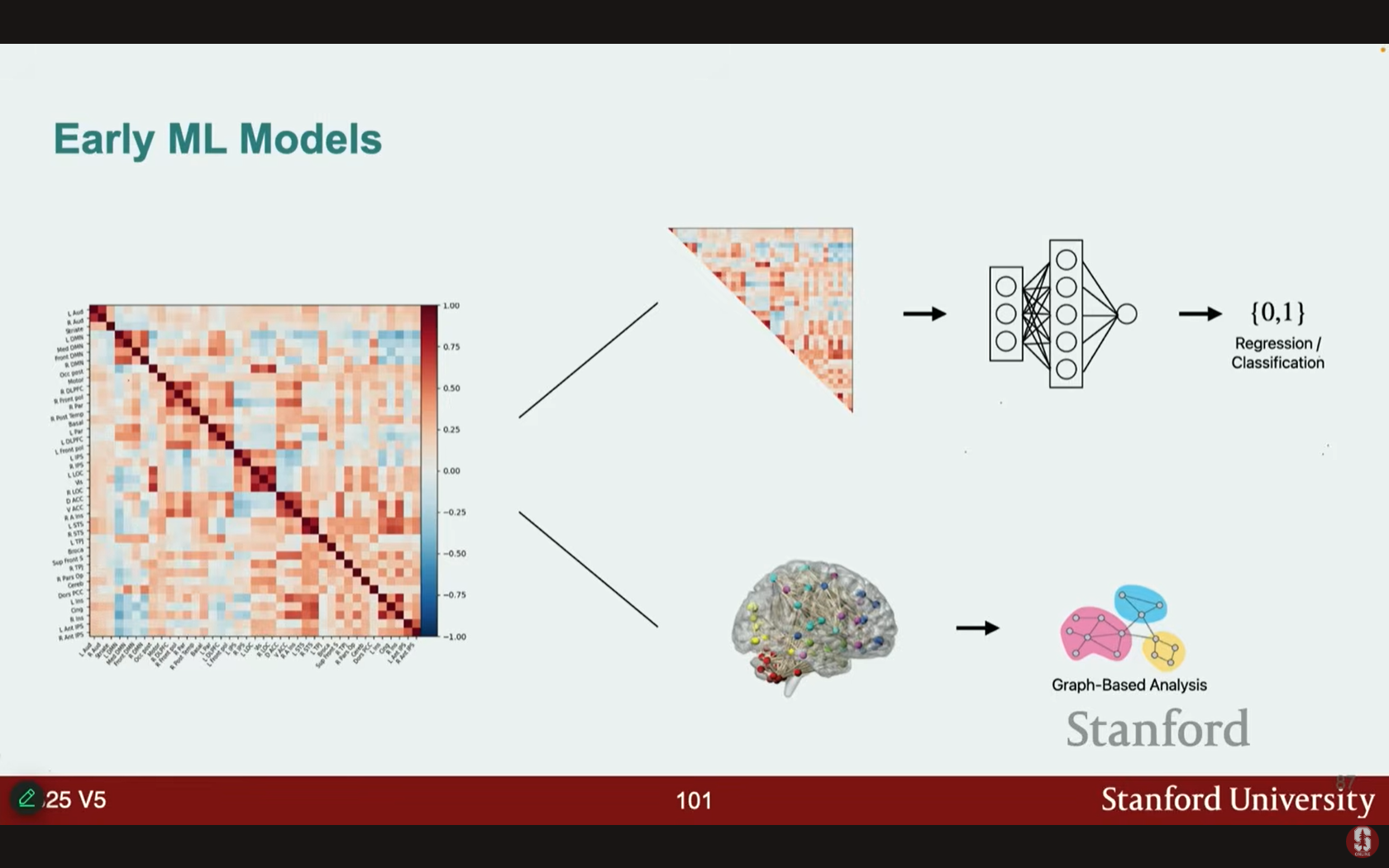
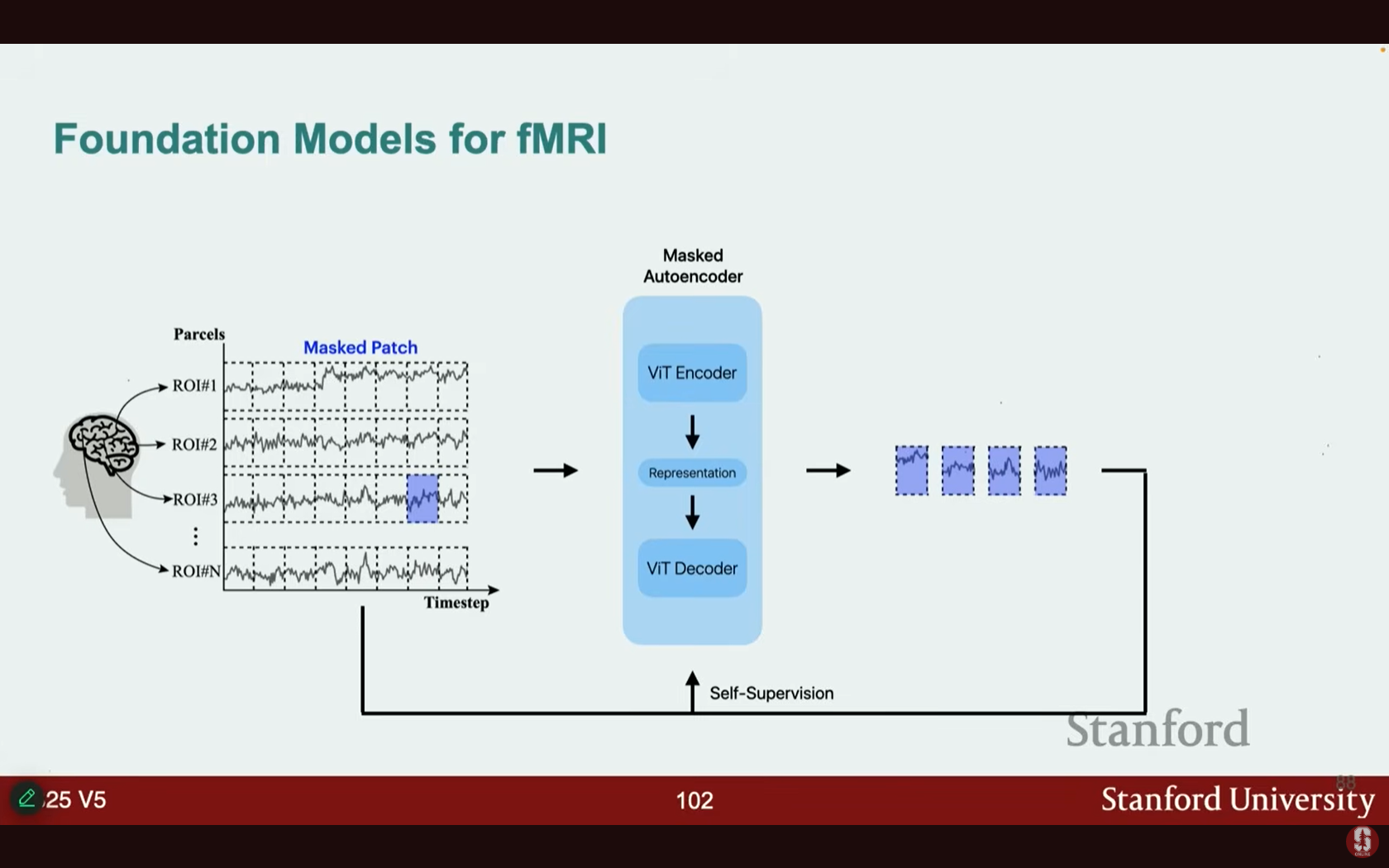
- 트랜스포머 기반 자기 지도 학습 (Self-supervised Training):
- 원시 데이터를 트랜스포머 모델에 직접 입력하며, 매우 좋은 사전 학습 목표로 사용될 수 있습니다.
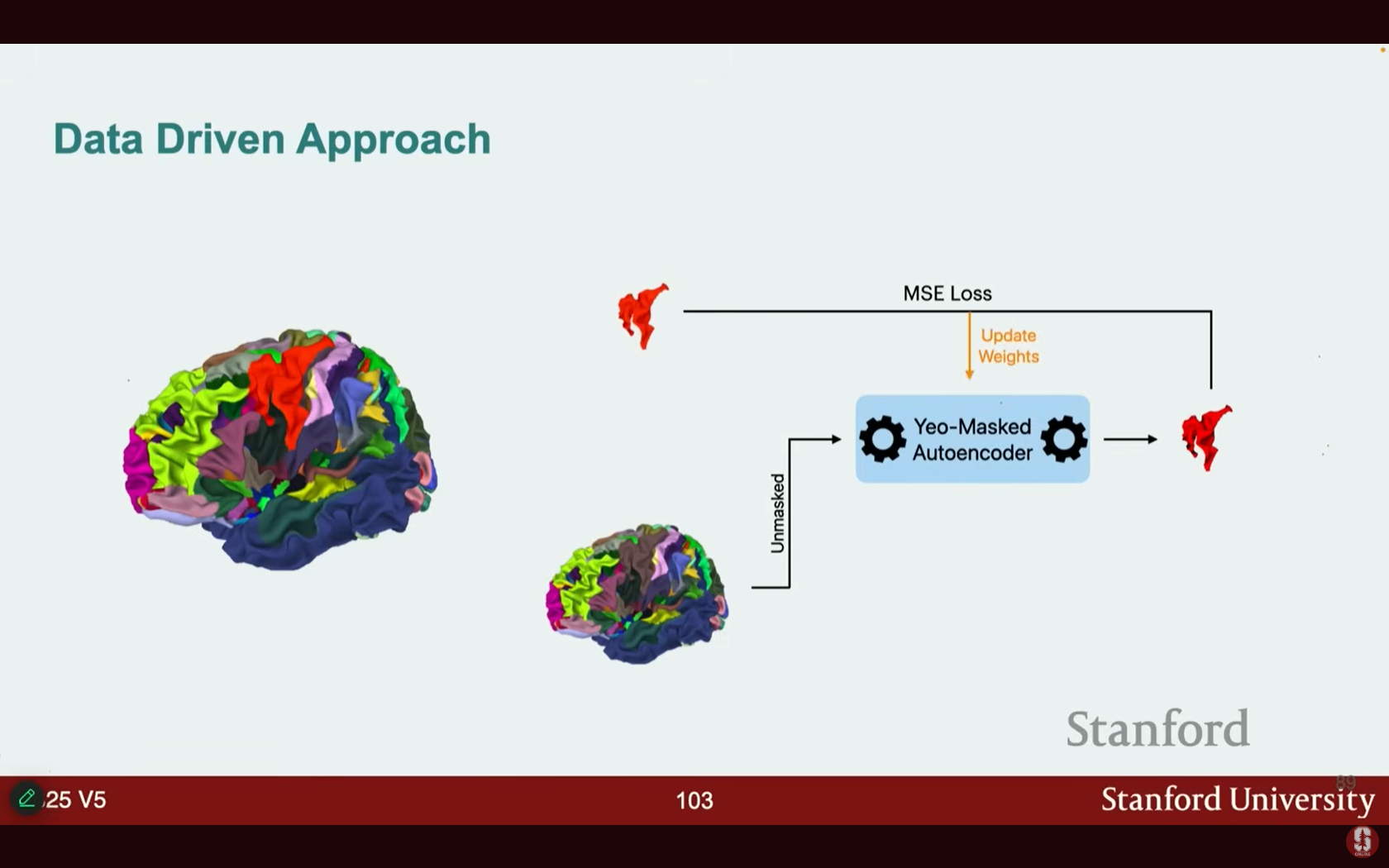
- 자기 지도 학습: 쌍을 이루는 레이블이 지정된 데이터 없이, 원시 데이터를 사용하여 학습 목표를 설정합니다.
- 방법: 시간 경과에 따른 ROI(관심 영역) 활동 데이터의 일부를 마스킹 아웃(mask out)하고, 트랜스포머가 마스킹된 부분을 예측하도록 훈련합니다.
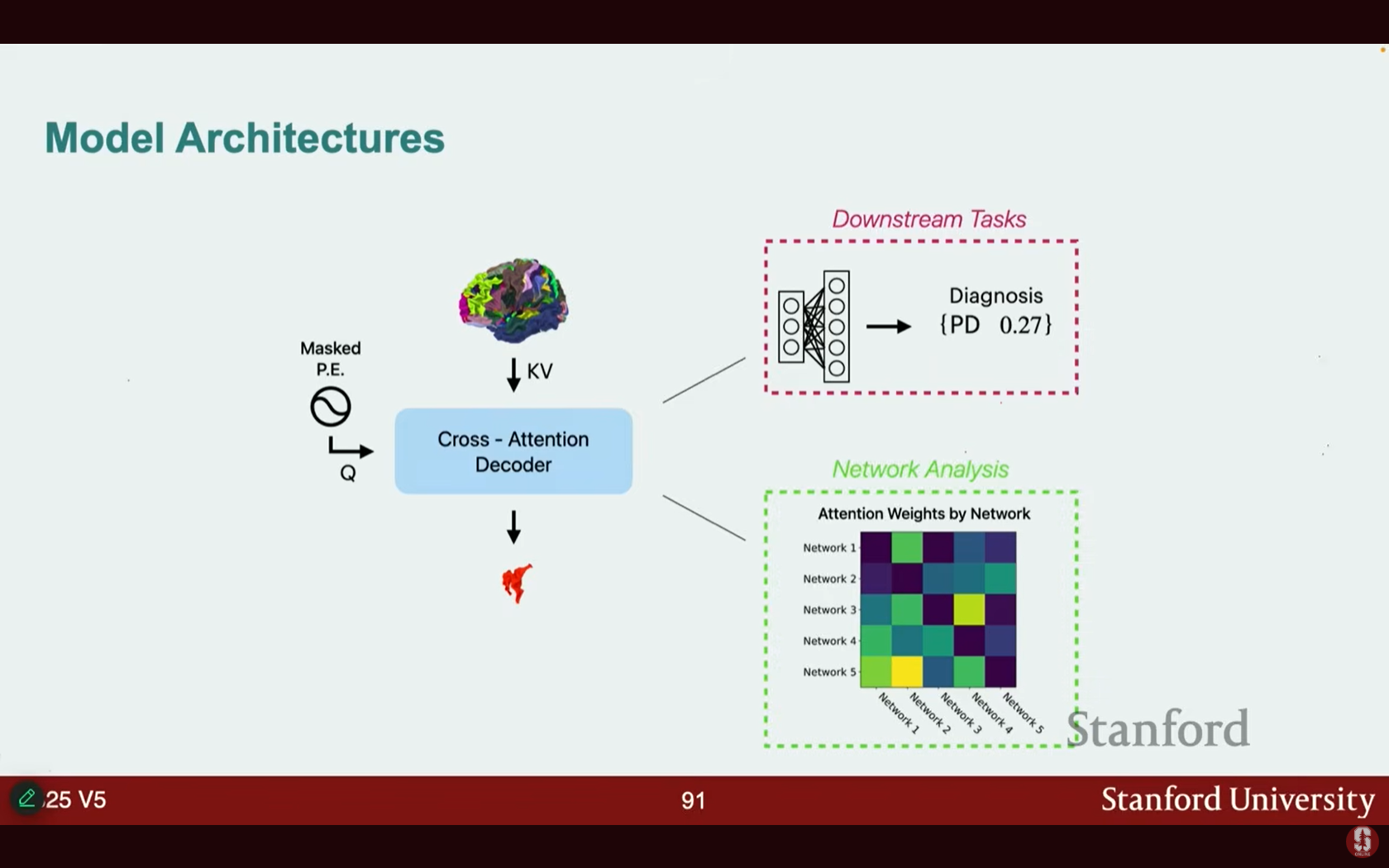
- 아키텍처: 이 접근 방식은 교차 주의(Cross Attention)를 활용합니다.
- 교차 주의: 자기 주의가 단일 시퀀스 내에서 주의를 기울이는 것과 달리, 교차 주의는 두 개의 서로 다른 시퀀스(예: 마스킹된 뇌 영역과 마스킹되지 않은 뇌 영역) 사이에서 주의를 적용합니다.
- 마스킹되지 않은 영역으로부터 마스킹된 뇌 영역을 예측하도록 학습합니다.
- 결과 및 활용:
- 모델은 현저성 네트워크(Salience Network) (감각 및 의사 결정 관련)와 디폴트 모드 네트워크(Default Mode Network, DMN) (공상, 기억 반추 관련) 등 뇌 활동을 잘 예측했습니다.
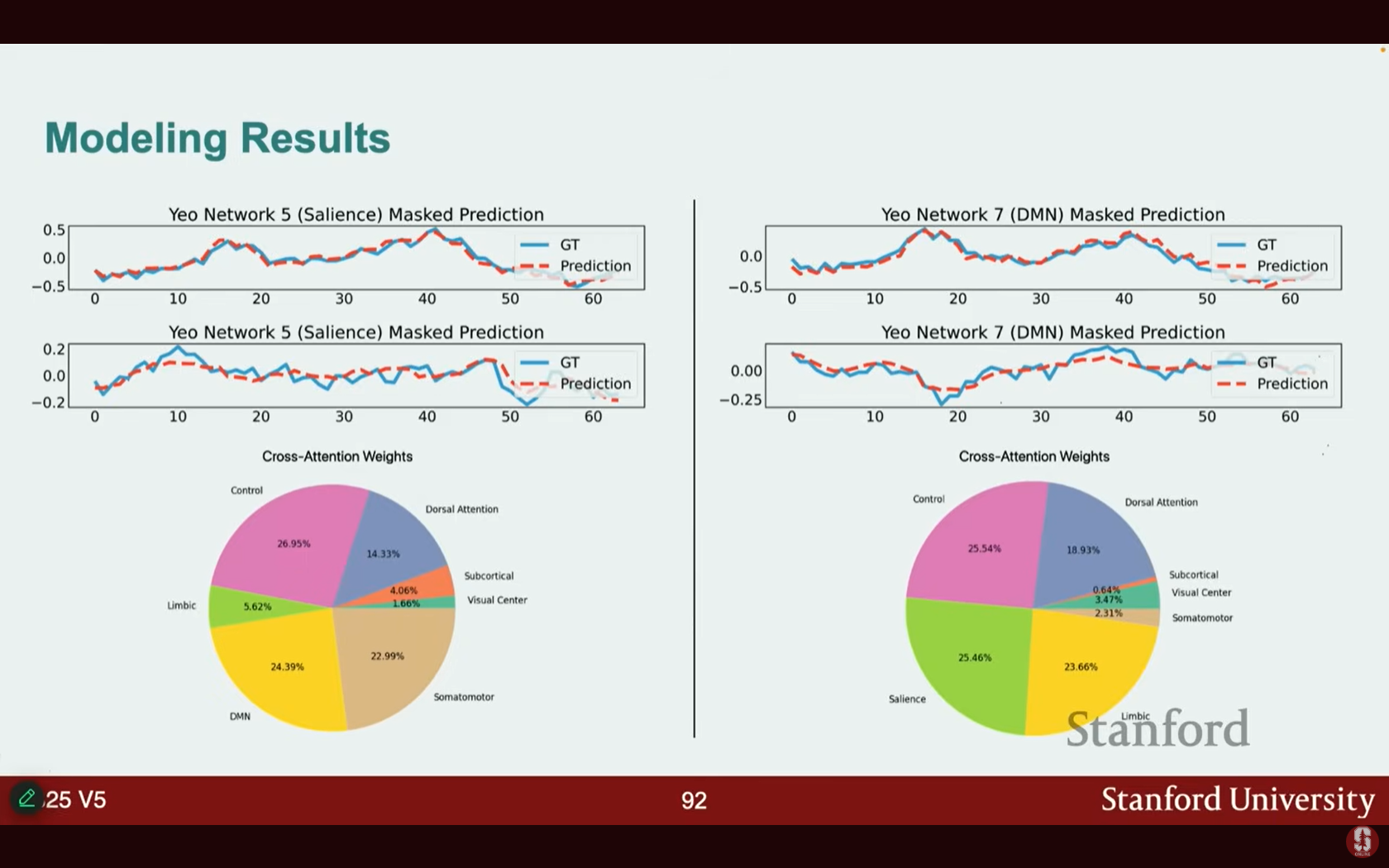
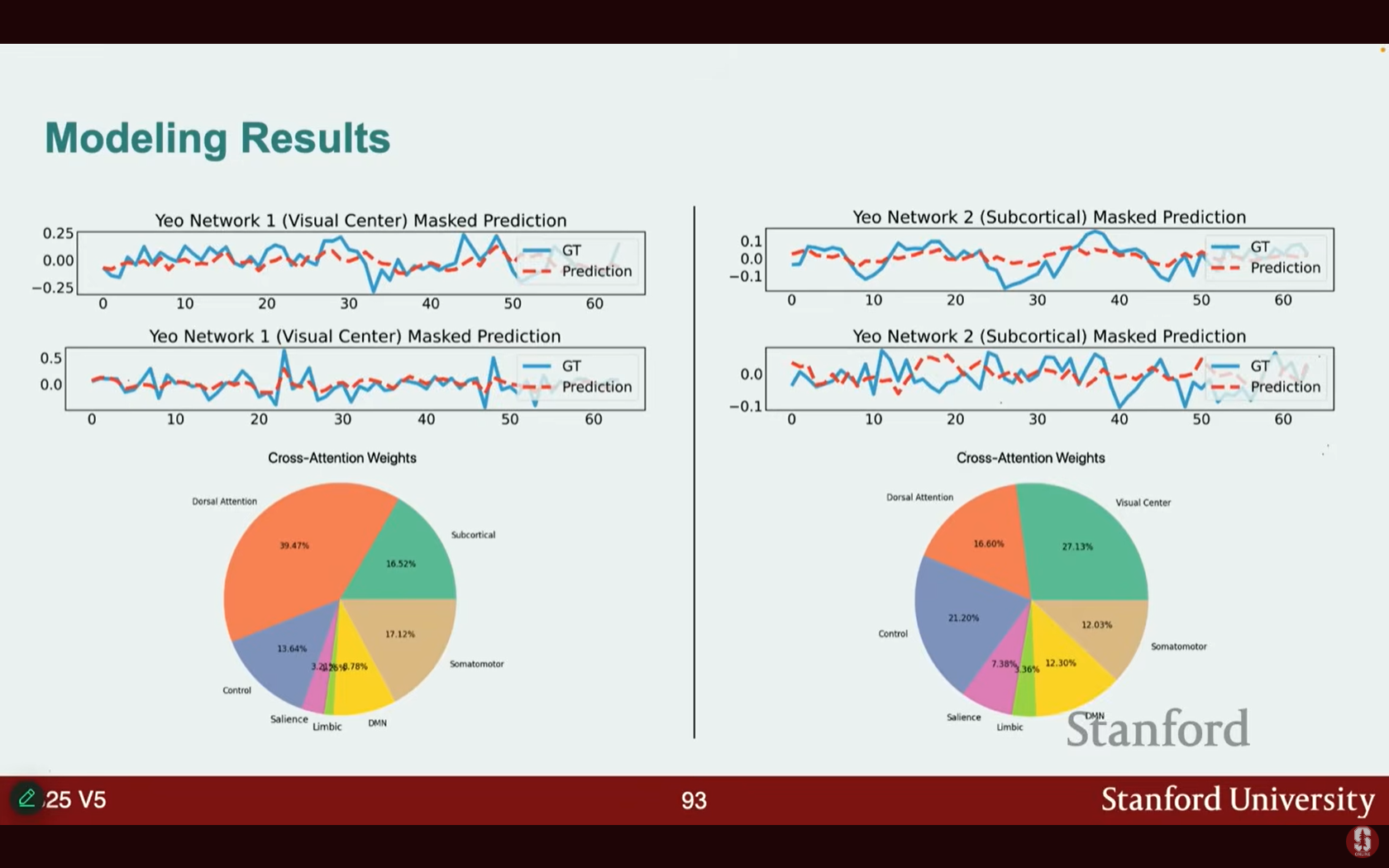
- 주의 가중치 분석: 현저성 네트워크 예측 시, 모델이 DMN과 제어 네트워크(Control networks)에 강하게 의존하는 것으로 나타났습니다. 이는 서로 다른 뇌 네트워크가 정보를 공유하는 방식을 이해하는 데 도움이 됩니다.
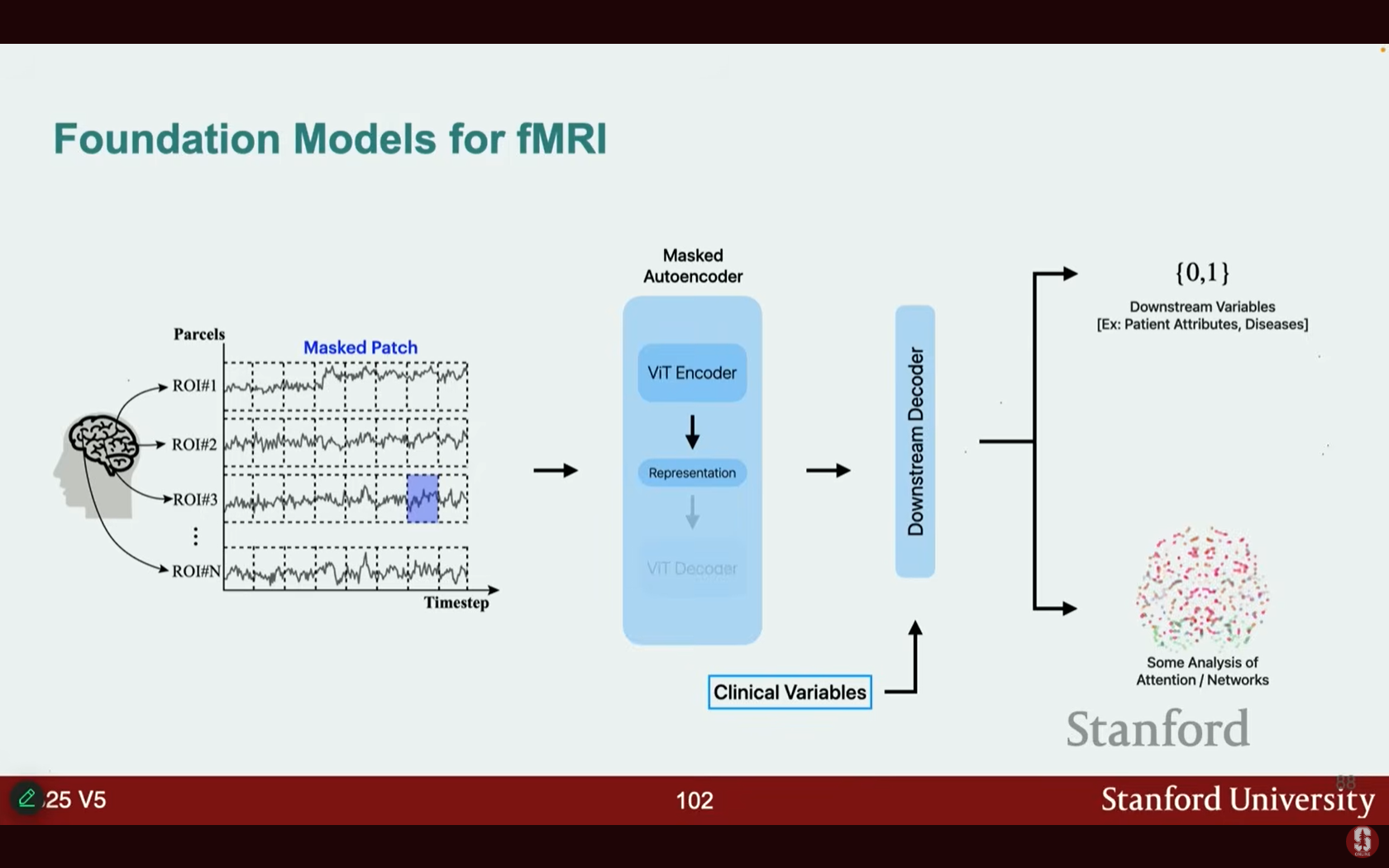
- 다운스트림 작업: 모델의 한 구성 요소를 파킨슨병(Parkinson's disease) 예측에 해당하는 학습 가능한 토큰으로 대체하여 미세 조정할 수 있습니다.
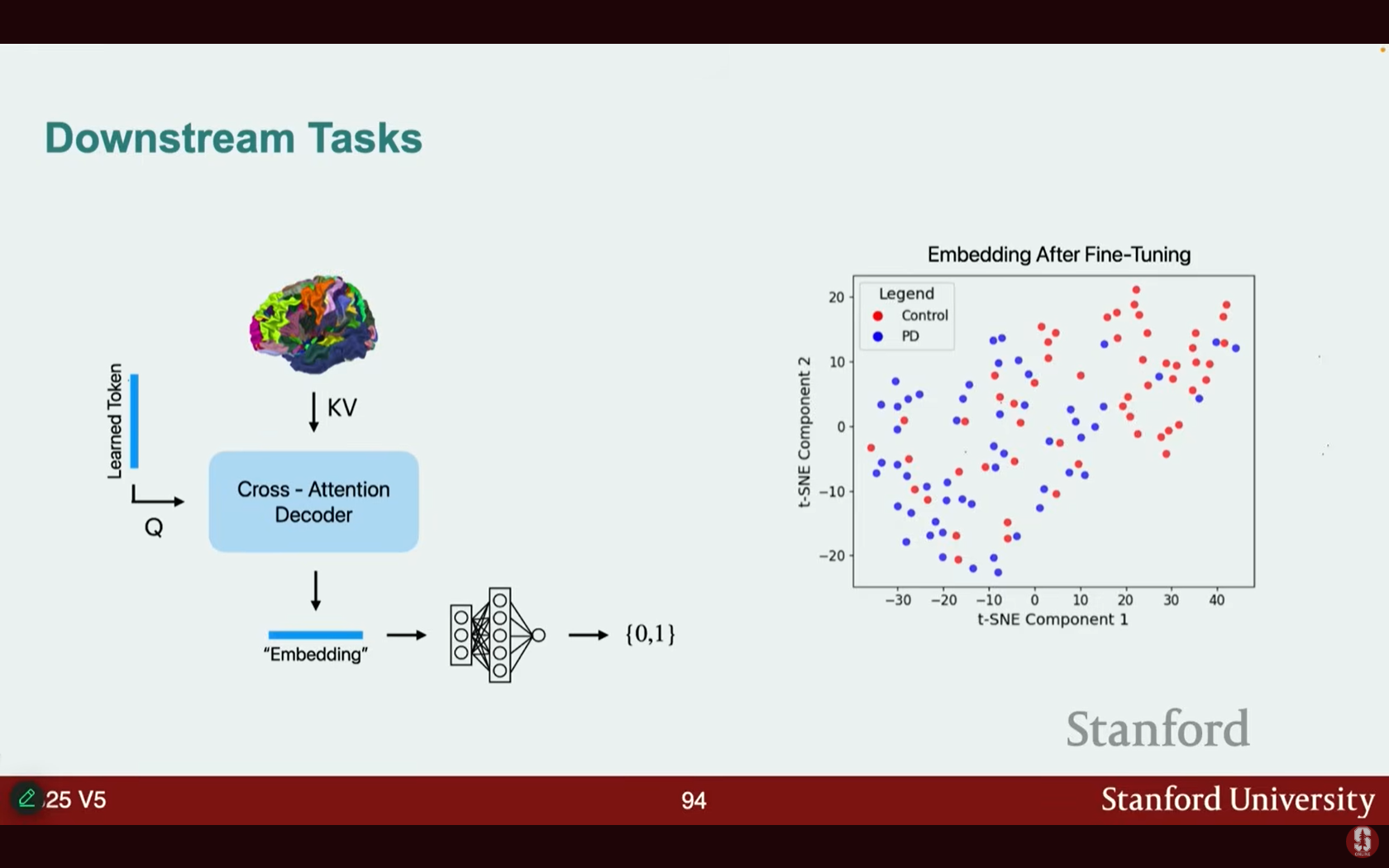
- 레이블이 지정된 데이터셋으로 미세 조정 후, 파킨슨병 예측에서 선형 상관관계 기반 방법보다 훨씬 높은 약 70%의 정확도를 달성했습니다.
- 모델은 현저성 네트워크(Salience Network) (감각 및 의사 결정 관련)와 디폴트 모드 네트워크(Default Mode Network, DMN) (공상, 기억 반추 관련) 등 뇌 활동을 잘 예측했습니다.
5. 트랜스포머의 미래와 도전 과제
1) 미래 응용 분야
- 트랜스포머는 거의 모든 산업 및 부문에서 더 많은 응용을 가능하게 합니다.
- 주요 잠재적 영향:
- 범용 에이전트(Generalist agents) 및 장기 비디오 이해 및 생성
- 도메인 특화 파운데이션 모델(Domain specific foundation models) (예: Doctor GPT, Lawyer GPT)
- 개인 맞춤형 교육 및 튜터링 시스템
- 고급 의료 진단 및 환경 모니터링
- 실시간 다국어 통신
- 대화형 환경 및 게임 내 비플레이어블 캐릭터(NPCs)

2) 현재의 한계 및 AGI를 향한 장벽
- 현재 트랜스포머 모델의 한계점이며, 인공 일반 지능(AGI) 개발의 장벽으로 간주될 수 있는 요소들입니다.


(1) 핵심 약점 및 부족한 정보
- 컴퓨팅 복잡성 감소 (Computation Complexity): 계산 효율성.
- 인간 제어 가능성 및 정렬 향상 (Controllability/Alignment): 모델을 인간의 뇌에 맞게 정렬.
- 적응적 학습 및 일반화 (Adapted Learning and Generalization): 다양한 도메인에 걸친 학습.
- 다감각 멀티모달 구현 (Multisensory Multimodal Embodiment): 직관적인 물리학 및 상식.
- 무한하고 외부적인 기억 (Infinite and External Memory): 뉴럴 튜링 머신(Neural Turing Machines)과 같은 개념.
- 무한한 자체 개선 능력 (Infinite Self-Improvement): 연속적/평생 학습(continual or lifelong learning).
- 완전한 자율성 (Complete Autonomy): 호기심, 욕구, 목표 포함.
- 장기적 의사 결정 (Long Horizon Decision-making).
- 감성 지능, 사회적 이해, 윤리적 추론 및 가치 정렬.
(2) 주요 기술적 과제
- 효율성 (Efficiency): LLM을 일상적인 응용 프로그램에 사용하기 위해 '초소형 LLM(tiny LLMs)'으로 축소하여 휴대폰, 스마트워치 등 소형 장치에서 빠르고 쉽게 실행할 수 있도록 해야 합니다.

- 해석 가능성 (Interpretability): 모델이 확장됨에 따라 (수조 개의 파라미터), LLM은 이해하기 어려운 블랙 박스(black box)가 됩니다.
- 메커니즘적 해석 가능성 (Mechanistic Interpretability) 연구를 통해 ML 모델의 개별 구성 요소나 노드 수준의 작동이 전체 의사 결정 과정에 어떻게 기여하는지 이해하고 통제력을 높여야 합니다.

- 메커니즘적 해석 가능성 (Mechanistic Interpretability) 연구를 통해 ML 모델의 개별 구성 요소나 노드 수준의 작동이 전체 의사 결정 과정에 어떻게 기여하는지 이해하고 통제력을 높여야 합니다.
- 규모 확장의 수확 체감 (Diminishing Returns of Scaling): 단순히 더 큰 모델과 더 많은 데이터로 확장하는 것만으로는 더 이상 최적의 솔루션이 아니며, 사전 학습 성능이 포화되고 있습니다.

- 파국적 망각 (Catastrophic Forgetting): 후속 학습 단계에서 너무 많은 새로운 정보로 과부하를 주면, 모델이 사전 학습 단계에서 학습했던 지식을 잊어버리는 현상입니다.
- 확장 한계 돌파를 위한 노력:
- 새로운 아키텍처 (예: Mamba, 상태 공간 기계 - State Space Machines).
- 스마트한 데이터 전략 (품질, 순서, 구조) 및 개선된 훈련 절차.

3) 연속적/평생 학습의 필요성 (Continual/Lifelong Learning)
- 배경: AI와 인간 사이의 가장 큰 격차 중 하나는 배포 후에도 지속적으로 개선하는 능력, 즉 연속적 학습이 부족하다는 점입니다.
- 인간은 매일 학습하며 뇌의 가중치를 업데이트하지만, LLM은 사전 학습 후 '고정'되어 추론 중에는 학습이 일어나지 않습니다.
- 도전 과제: 모델의 뇌나 가중치를 지속적으로 업데이트하는 진정한 평생 학습을 가능하게 하는 메커니즘을 찾는 것입니다.

- 모델 편집 (Model Editing): 연속적 학습의 한 시도로, 새로운 사실이나 데이터 포인트가 주어질 경우 전체 모델을 업데이트하는 대신 특정 노드나 뉴런을 대상으로 업데이트하는 방식입니다.
- 예시: ROME (Rank One Model Editing)은 인과적 개입(causal intervention) 메커니즘을 통해 특정 사실 예측에 가장 많이 기여하는 뉴런 활성화를 찾아 업데이트합니다.
- 한계점: 지식 기반의 단순한 사실에 주로 작동하며, 모델의 실제 기술이나 능력(예: 수학적 추론) 업데이트에는 적용하기 어렵습니다. 또한, 한 번에 하나의 사실만 대상으로 하므로 관련 사실로 변경 사항을 전파하기 어렵습니다.

- 최근 관련 연구:
- MEMIT: 대규모 사실적 지식 편집(Mass Editing of Factual Knowledge)으로, 한 번에 수천 개의 상호 관련된 사실을 동시에 수정할 수 있습니다.
- Chem (Continue Evolving from Mistakes): 모델의 실수를 식별하고 점진적으로 업데이트하여 자체 개선을 이룹니다.
- Lifelong Mixture of Experts: 기존 MoE 아키텍처에 새로운 도메인에 대한 새로운 전문가(experts)를 지속적으로 추가하고, 과거 전문가를 동결하여 파국적 망각을 방지합니다.
- CLOB / Progressive Prompts: 가중치를 업데이트하지 않고 과거 지식을 프롬프트 메모리에 요약하거나 소프트 프롬프트 벡터를 학습/압축하여 연속 학습을 가능하게 합니다 (진정한 가중치 업데이트는 아님).
- 결론: 진정한 연속 학습은 모델의 '뇌' 또는 가중치를 어떤 방식으로든 업데이트해야 할 것입니다.

AI 공부합니다