NLP
1.[NLP] 대규모 언어모델(LLM) 구조 정리

대규모 언어모델(LLM, Large Language Model)은 입력된 문장을 토큰 단위로 분해하고, 주어진 맥락(context)에서 다음에 올 토큰을 예측하는 것을 학습 목표로 합니다.기존 언어 모델에서는 Encoder-Decoder 구조를 활용하여 입력 문장의 의
2.[NLP] RNN과 Seq2Seq 구조 정리
RNN은 시퀀스(sequence) 데이터를 처리하기 위한 신경망 구조입니다. 일반적인 MLP나 CNN은 입력을 독립적으로 처리하지만, RNN은 \*\*이전 시점의 은닉 상태(hidden state)\*\*를 다음 시점의 입력과 함께 처리함으로써 \*\*시간적 의존성(t
3.[NLP] CS224N 1강 정리 [Word Vectors]

단어의 의미를 컴퓨터가 이해할 수 있는 형태로 바꾸는 가장 단순한 방법은 원-핫 인코딩(One-Hot Encoding)입니다.어휘집(vocabulary)에 있는 모든 단어를 고유한 숫자(인덱스)로 매핑하고, 각 단어를 해당 위치에만 1이 있는 벡터로 표현하는 방식입니다
4.[NLP] CS224N 2강 정리 [Word Vectors and Language Models]
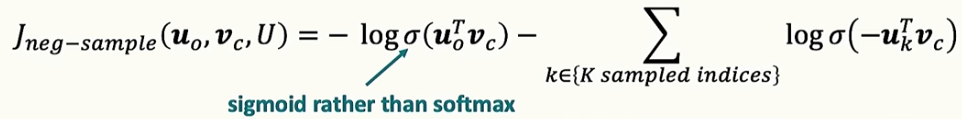
워드 벡터 모델의 목표는 단어를 숫자 벡터로 표현하여 단어 간의 의미적 유사성을 포착하는 것입니다. 이 과정은 경사 하강법(Gradient Descent)이라는 최적화 기법을 사용해 이루어집니다.모델의 예측값과 실제값의 차이(손실 함수)를 줄이기 위해 매개변수를 조금씩
5.[NLP] CS224N 3강 정리 [Backpropagation, Neural Network]

신경망은 여러 개의 계층으로 구성되며, 각 계층의 뉴런은 입력에 가중치(W)를 곱하고 편향(b)을 더한 후 비선형 함수를 적용합니다.중간 계층은 신경망이 스스로 유용한 표현을 학습하도록 돕는 중요한 역할을 합니다.신경망이 복잡한 함수를 근사할 수 있도록 해주는 핵심 요
6.[NLP] CS224N 4강 정리 [Dependency Parsing]
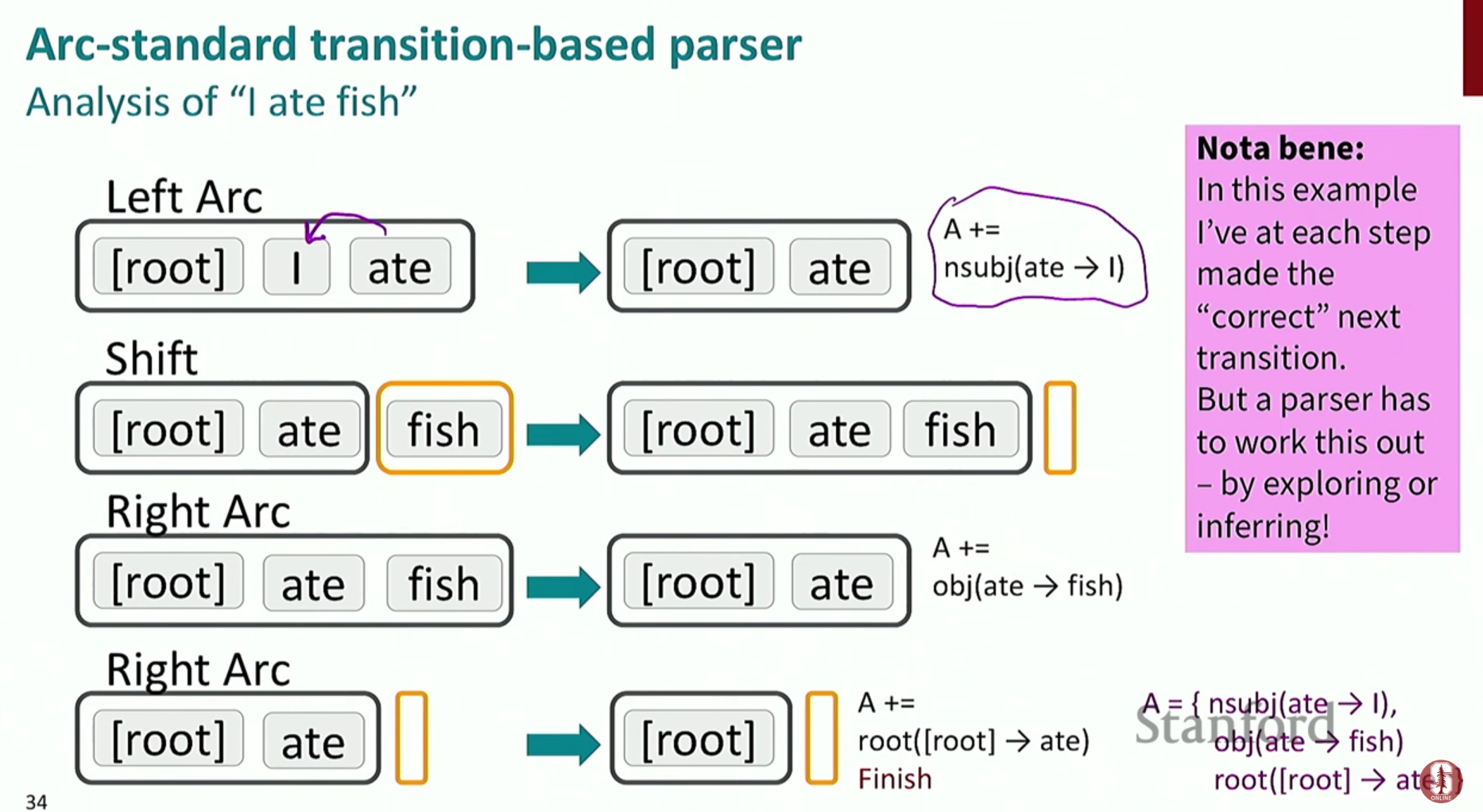
인간 언어의 구조를 이해하는 데는 두 가지 주요 관점이 있습니다.이는 문장을 구성하는 단어들이 계층적인 그룹(구, Phrase)을 형성한다고 보는 방식입니다. 예를 들어 'the cat'은 명사구(NP)가 되고, 'ate a fish'는 동사구(VP)가 되어 이들이 합
7.[NLP] CS224N 5강 정리 [Recurrent Neural Networks]
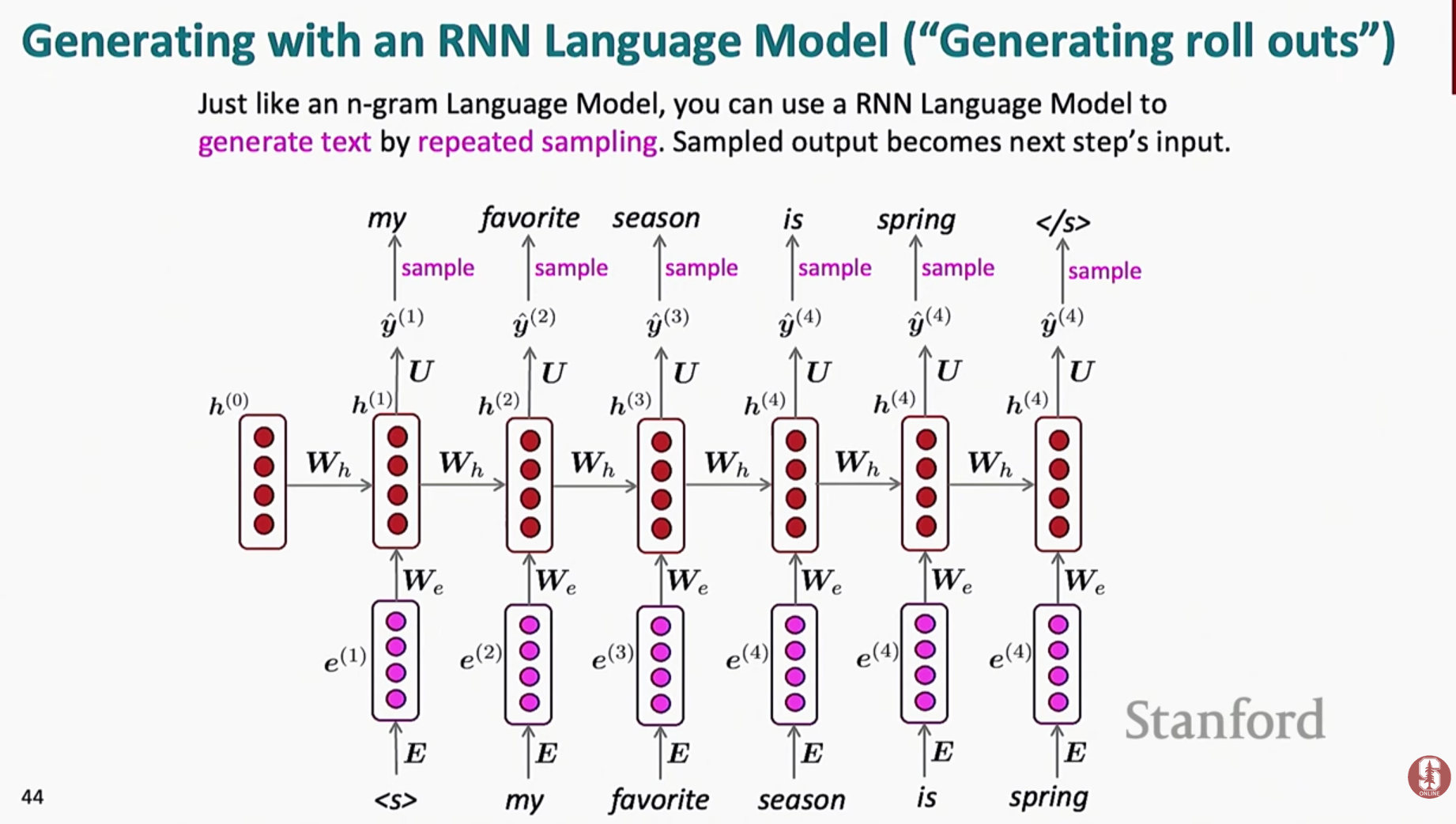
손실 함수를 최소화하는 것을 넘어 모델 성능을 향상시키기 위해 학습된 매개 변수를 조작하는 것을 포함합니다. L2 정규화는 과적합을 방지하는 고전적인 접근법이었지만, 최신 신경망은 완벽한 손실을 달성하기 위해 훈련 데이터에 "과적합"하는 경향이 있으며, 여전히 잘 일반
8.[NLP] CS224N 6강 정리 [Sequence to Sequence]

RNN(Recurrent Neural Network)은 자연어와 같이 순서가 중요한 시퀀스 데이터를 처리하기 위해 설계된 신경망입니다.핵심 아이디어는 이전 시점의 정보를 은닉 상태(hidden state)에 저장하고, 이를 현재 시점의 계산에 활용한다는 점입니다.은닉
9.[NLP] CS224N 7강 정리 [Attention]

BLEU는 생성된 문장(candidate)과 기준(reference) 문장 사이의 n-gram 겹침 정도를 측정합니다.쉽게 말하면:번역 결과 문장과 사람 번역 문장을 n-gram 단위로 비교겹치는 정도가 높을수록 점수가 높음BLEU의 핵심 아이디어는 정확도(precis
10.[NLP] CS224N 8강 정리 [Self-Attention and Transformers]
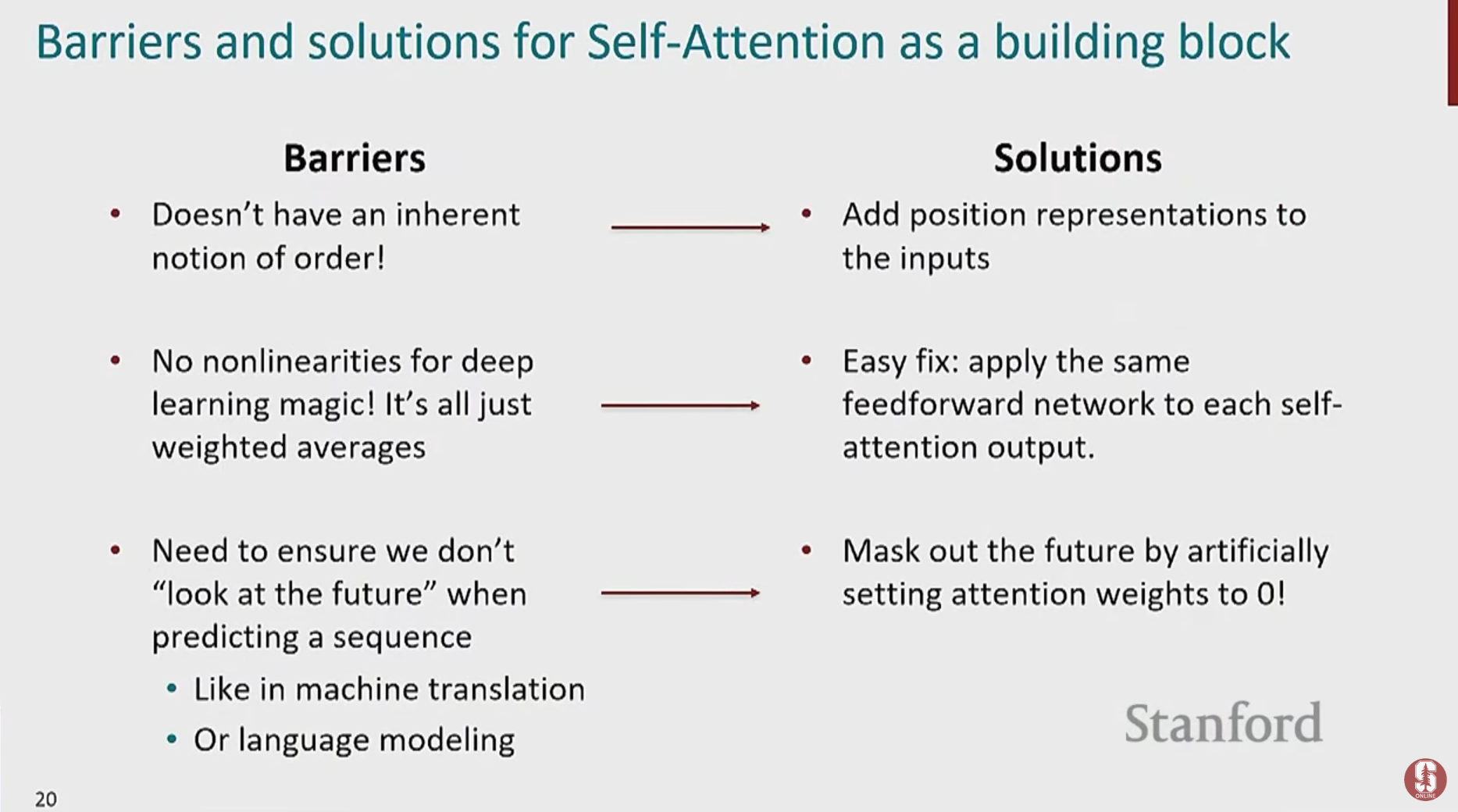
Transformer가 등장한 배경을 이해하려면, 기존의 왕좌를 차지했던 RNN(순환 신경망)이 왜 한계에 부딪혔는지 알아야 합니다.강의에서는 "The chef who went to the stores... and loves garlic was great."라는 예시를
11.[NLP] CS224N 9강 정리 [Pretraining]
1. Pre-training 이전의 근본적 문제: 단어 표현 BERT와 같은 모델이 등장하기 전, 초기 단어 임베딩 모델(Word2Vec 등)들은 '어휘집(Vocabulary)'에 기반하는 근본적인 문제가 있었습니다. 1) 미등록 단어 문제 (Out-of-Vocabu
12.[NLP] CS224N 10강 정리 [Natural Language Generation]
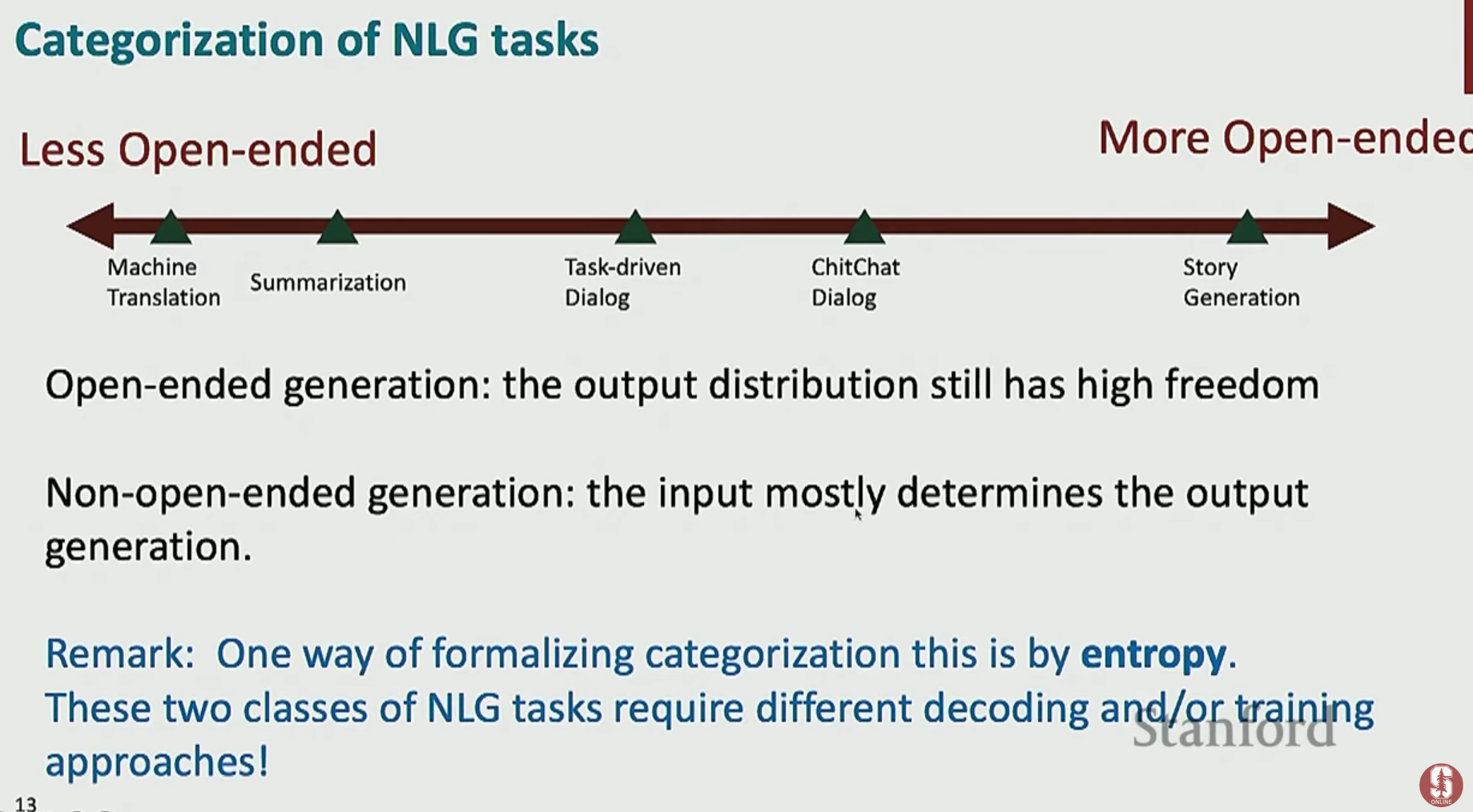
자연어 생성(Natural Language Generation, NLG)은 시스템이 유창하고, 일관성 있으며, 유용한 자연어 텍스트를 출력하는 모든 작업을 의미합니다.자연어 처리(NLP)는 크게 두 가지로 나뉩니다.자연어 이해 (NLU): 입력이 텍스트 (예: 감성 분
13.[NLP] CS224N 11강 정리 [Post-training]
연산 능력의 증가: 1950년대부터 머신러닝 모델에 필요한 연산량은 기하급수적으로 증가해왔습니다. 현재 LLM은 $10^{26}$ FLOPS를 훌쩍 뛰어넘는 연산량을 요구합니다.데이터의 확장: 모델이 커질수록 더 많은 데이터가 필요합니다. 2024년 라마 3 모델은 무
14.[NLP] CS224N 12강 정리 [Benchmarking]
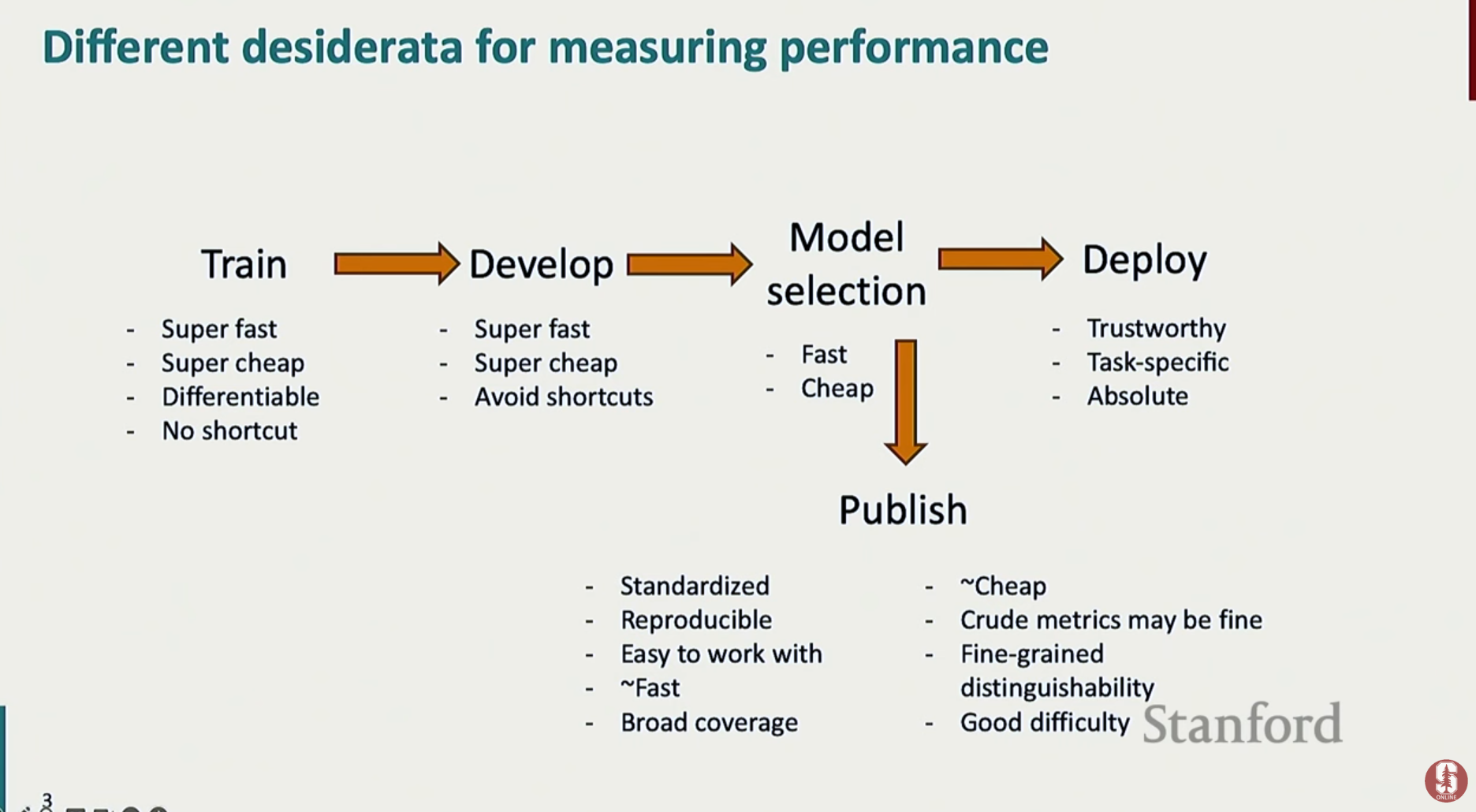
모델의 성능을 측정하는 것은 NLP 프로젝트의 성공을 위해 여러 단계에서 필수적인 과정입니다. 단순한 점수 확인을 넘어, 각 단계의 목표 달성을 위한 핵심적인 역할을 수행합니다.모델 훈련 (Training): 훈련 과정에서 모델이 올바른 방향으로 학습되고 있는지 확인하
15.[NLP] CS224N 13강 정리 [Efficient Training with GPU]
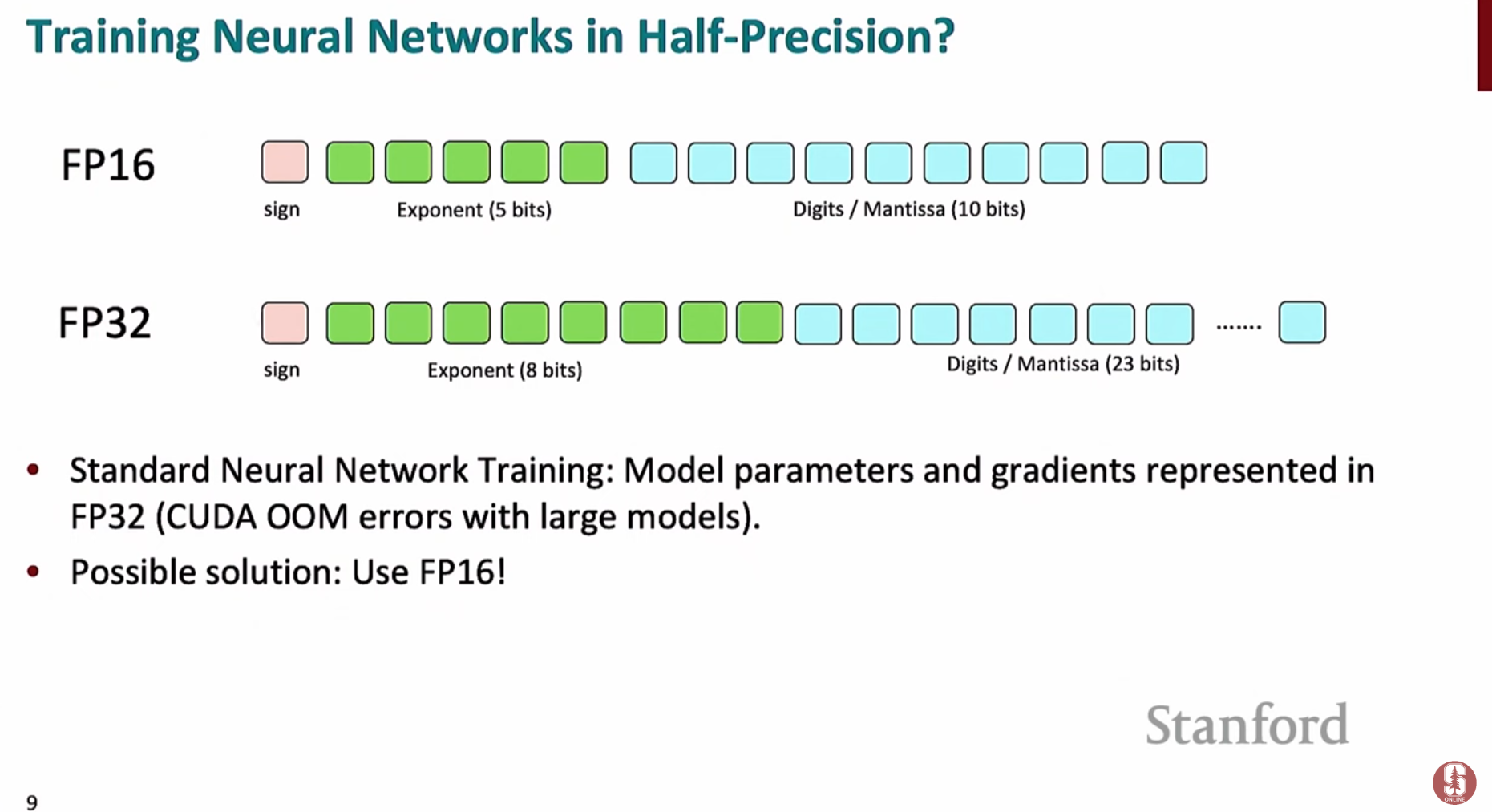
모델 훈련 시 메모리 사용량을 줄이고 속도를 높이기 위해, 기존의 32비트 부동소수점(fp32) 대신 16비트 부동소수점(fp16)을 함께 사용하는 기술입니다.fp32 (단정밀도): 4바이트를 사용하며, 넓은 범위의 숫자를 높은 정밀도로 표현할 수 있어 안정적이지만 메
16.[NLP] CS224N 14강 [Brain-Computer Interfaces]
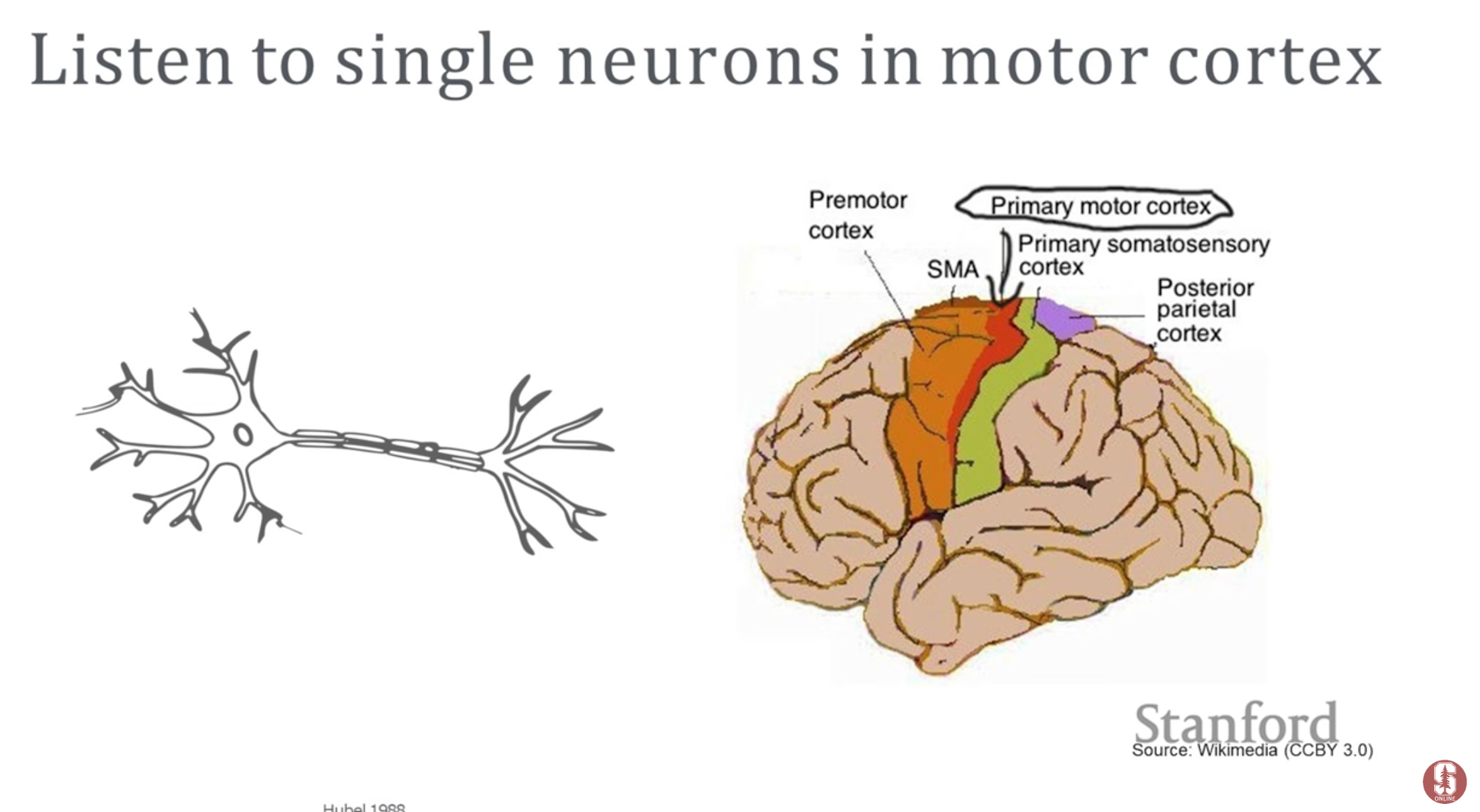
하워드의 사례: 21세에 심각한 뇌졸중으로 인해 '갇힌 상태(locked-in state)'가 된 하워드는 움직이거나 말할 수 없게 되었어요. 뇌 기능은 정상이지만, 자신을 표현할 방법이 없는 것이죠. BCI는 이처럼 신체에 갇힌 사람들이 세상과 다시 소통할 수 있도록
17.[NLP] CS224N 15강 정리 [Reasoning and Agents]
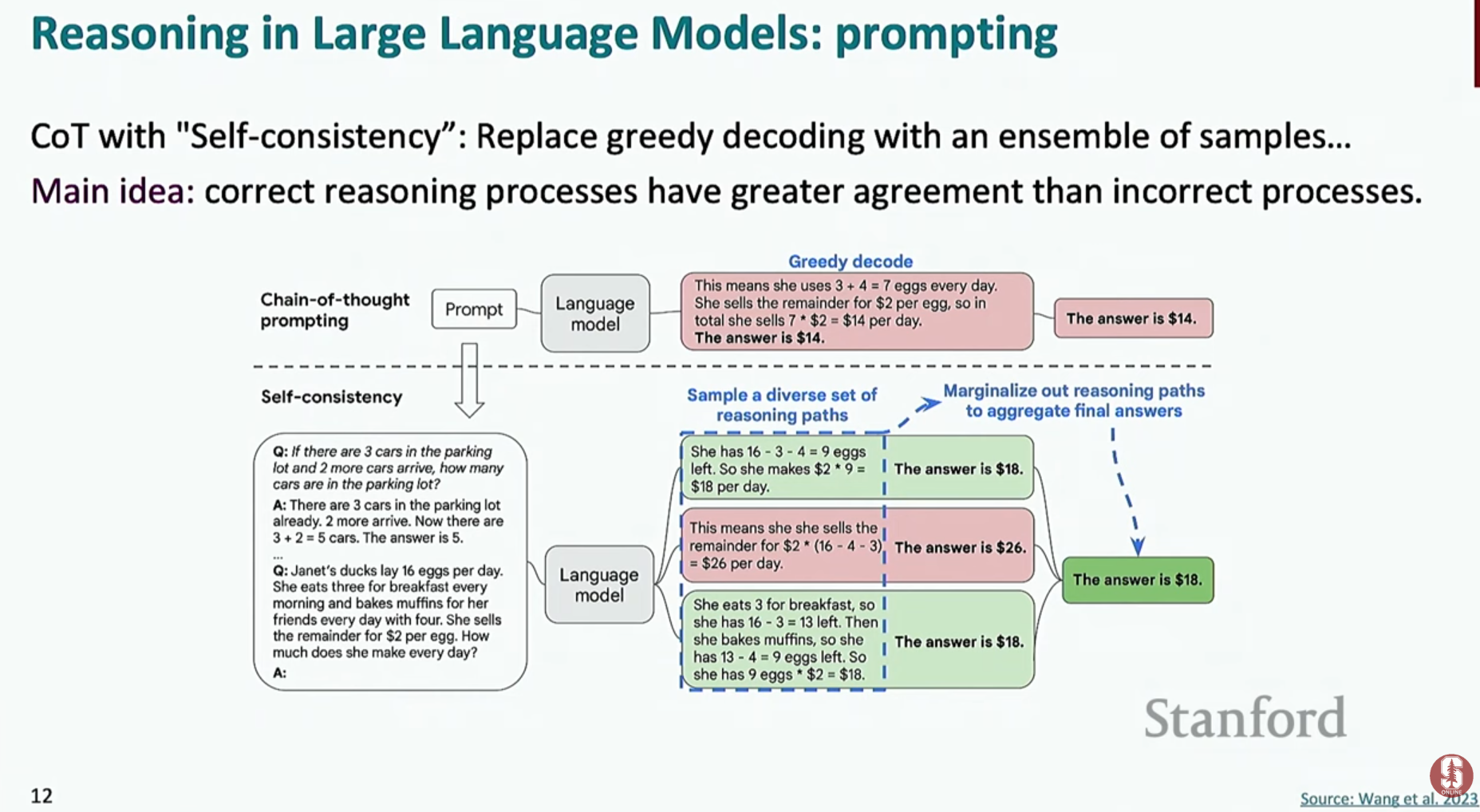
\*\*추론(Reasoning)\*\*이란 주어진 정보를 바탕으로 논리적인 결론을 이끌어내는 과정을 의미해요. 언어 모델의 추론 능력은 복잡한 문제를 해결하는 데 핵심적인 역할을 합니다. 강의에서는 다음과 같은 여러 추론 유형을 소개했어요.연역적 추론 (Deductiv
18.[NLP] CS224N 16강 정리 [After DPO]

초기 모델의 진화: 강의 초반부에서는 언어 모델의 발전사를 간략히 짚어봅니다. BERT, GPT-1, GPT-2 와 같은 초기 모델들이 등장하며 NLP 분야의 기반을 다졌습니다.LLM의 대중화: 2020년 이후, 대규모 언어 모델(LLM)의 잠재력과 유용성에 대한 인식
19.[NLP] CS224N 17강 정리 [ConvNets and TreeRNNs]
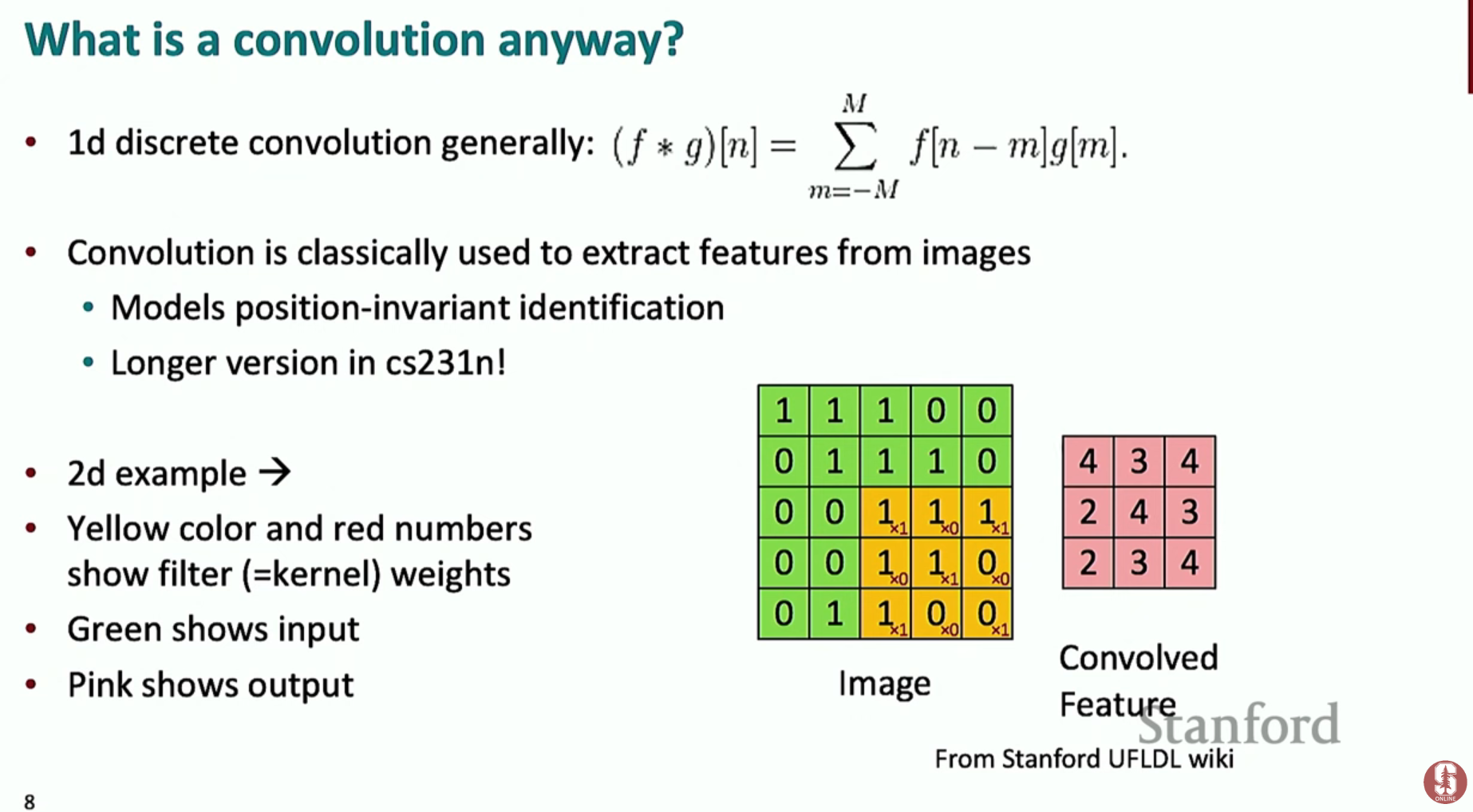
합성곱 신경망(CNN)은 본래 이미지 처리(Computer Vision) 분야를 위해 개발된 딥러닝 모델이야. 이미지 내에서 객체의 위치가 다소 변하더라도 동일한 특징을 인식할 수 있는 변환 불변성(translation invariant) 특징을 추출하는 데 매우 효과
20.[NLP] CS224N 18강 정리 [NLP, Linguistics, Philosophy]
밀집 표현 (Dense Representations): 단어의 의미는 그 단어가 사용되는 맥락을 통해 파악할 수 있다는 분포 의미론(Distributional Semantics)에 기반합니다. 이는 단어를 고차원 공간의 밀집 벡터(Dense Vector), 즉 단어 벡
21.[NLP] CS224N 19강 정리 [Multimodal Deep Learning]
1\. 멀티모달리티(Multimodality)의 서막 1\) 멀티모달리티란 무엇인가? 멀티모달리티(Multimodality)란, 텍스트, 이미지, 음성, 오디오 등 여러 '모드(mode)'의 정보를 함께 처리하고 이해하는 인공지능 분야를 의미합니다. 인간은
22.[NLP] CS224N 20강 정리 [Model Interpretability & Editing]
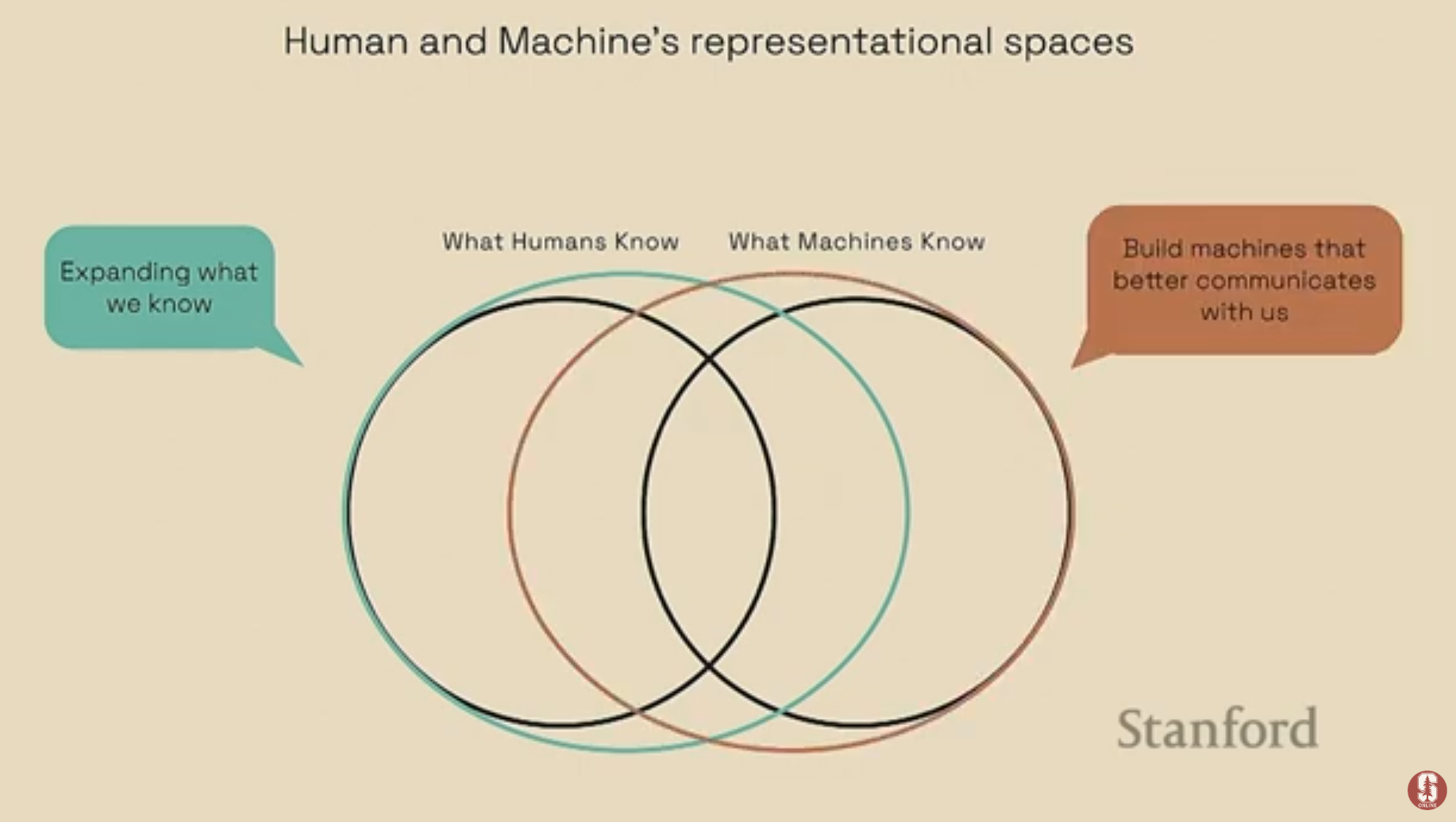
이 스터디 노트는 구글 브레인의 김빈 박사님의 강의를 바탕으로 작성되었으며, 기계가 인류에게 이롭도록 돕는 효과적인 인간-기계 소통의 중요성을 탐구합니다.강의 목표: 기계가 인류에게 이로움을 주도록 만드는 것으로, 이를 위해 효과적인 인간-기계 소통을 구축하는 것이 핵
23.[NLP] CS224N 21강 정리 [Hugging Face Tutorial🤗]
강의 속 예제 코드 $\\Rarr$ \[https://colab.research.google.com/drive/13r94i6Fh4oYf-eJRSi7S_y_cen5NYkBmHugging Face는 트랜스포머(Transformer) 기반의 최신 NLP 모델들을 아
24.[NLP] CS224N 22강 정리 [PyTorch Tutorial]
강의 예시 코드 $\\Rarr$ https://colab.research.google.com/drive/1Pz8b_h-W9zIBk1p2e6v-YFYThG1NkYeS?usp=sharingPyTorch는 딥러닝 모델을 만들고 학습시키는 데 사용되는 강력한 오픈소스
25.[NLP] 단어 임베딩과 학습 원리
임베딩 층: 단어를 고정 길이 벡터로 변환벡터 공간에서 단어 의미를 학습 → 비슷한 단어끼리 가까워짐Word2Vec, LLM 모두 문맥 기반 의미 구조 형성차이점:Word2Vec: self-supervised, 주변 단어 예측 기반LLM: next-token predi
26.[NLP] CS25 V5 1강 정리 [Overview of Transformers]

본 강의는 트랜스포머(Transformers)와 머신러닝, 그리고 AI가 우리 삶에서 얼마나 중요한 부분이 되었는지 예측하고 시작되었으며, 현재 거대 언어 모델(LLMs)과 AI가 세상을 주도하고 있음을 확인했습니다.예시로는 ChatGPT나 이미지/비디오 생성 모델인
27.[NLP] CS25 V5 2강 정리 [RL as a Co-Design of Product and Research]
본 강의는 CS25 Transformer United의 두 번째 강의이며 외부 연사가 참여하는 첫 번째 강의이다.강연자 Karina Nguyen은 OpenAI에서 제품(Product) 및 연구(Research) 업무를 모두 수행하고 있으며, 이전에는 Anthropic에
28.[NLP] CS25 V5 3강 정리 [The Advent of AGI]
강의는 AGI(일반 인공지능)의 도래와 지능형 에이전트의 설계, 평가, 배포 방식에 대한 재고를 다룬다.최근 에이전트 및 새로운 모델 개발로 인해, 현재 시스템은 채팅 및 추론 분야에서 이미 평균적인 인간 수준을 넘어서는 초지능을 갖춘 것처럼 보인다.AGI의 형태: A
29.[NLP] CS25 V5 4강 정리 [Large Language Model Reasoning]
본 강의는 Google DeepMind의 Denny Zhou가 대규모 언어 모델(LLM)의 추론 능력에 대해 발표한 내용이다.Denny Zhou는 Google Brain에서 추론 팀을 설립했으며, Chain-of-Thought (CoT) 프롬프팅과 Self-Consis
30.[NLP] Position Encoding 이해하기
벡터의 고유성을 이해하기 위해 차원에 대해서 저는 다음과 같이 생각했습니다."각 차원이 독립된 평행세계처럼 동작한다”정확하게 말하자면 차원은 평행세계라기보다 하나의 위치를 각기 다른 정밀도(차원)로 측정하는 '측정 도구' 모음이라고 합니다.예컨대, 이를 Attentio
31.[NLP] 텍스트 전처리 실험: 정규표현식 vs KoBART GEC 가성비 분석

"데이터 전처리에 딥러닝 모델을 태우면 얼마나 좋아질까? 그리고 시간은 얼마나 걸릴까?"자연어 처리(NLP) 프로젝트를 진행하다 보면 가장 먼저 마주하는 벽은 \*\*'데이터의 질(Quality)'\*\*입니다. 특히 네이버 영화 리뷰 데이터(NSMC) 같은 댓글 데이
32.[NLP] CS25 V5 5강 정리 [On the Biology of a Large Language Model]
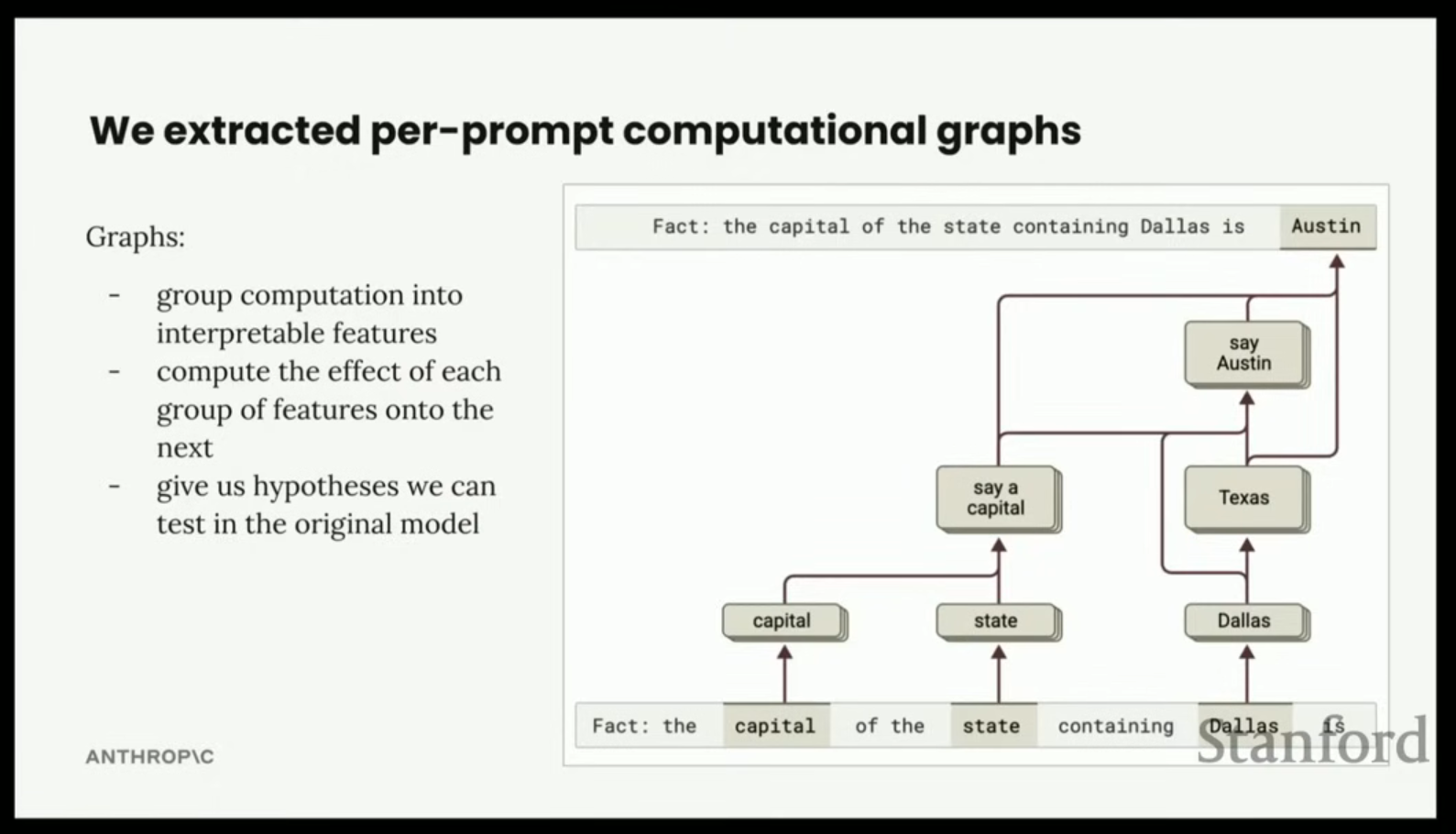
본 강의는 Anthropic의 기계론적 해석 가능성(mechanistic interpretability) 팀에서 회로(circuits) 연구를 이끌고 있는 Joshua Batson의 발표 내용이다.Josh Batson은 Anthropic 이전에 Chan Zuckerbe
33.[NLP] CS25 V5 6강 정리 [Multimodal World Models for Drug Discovery]
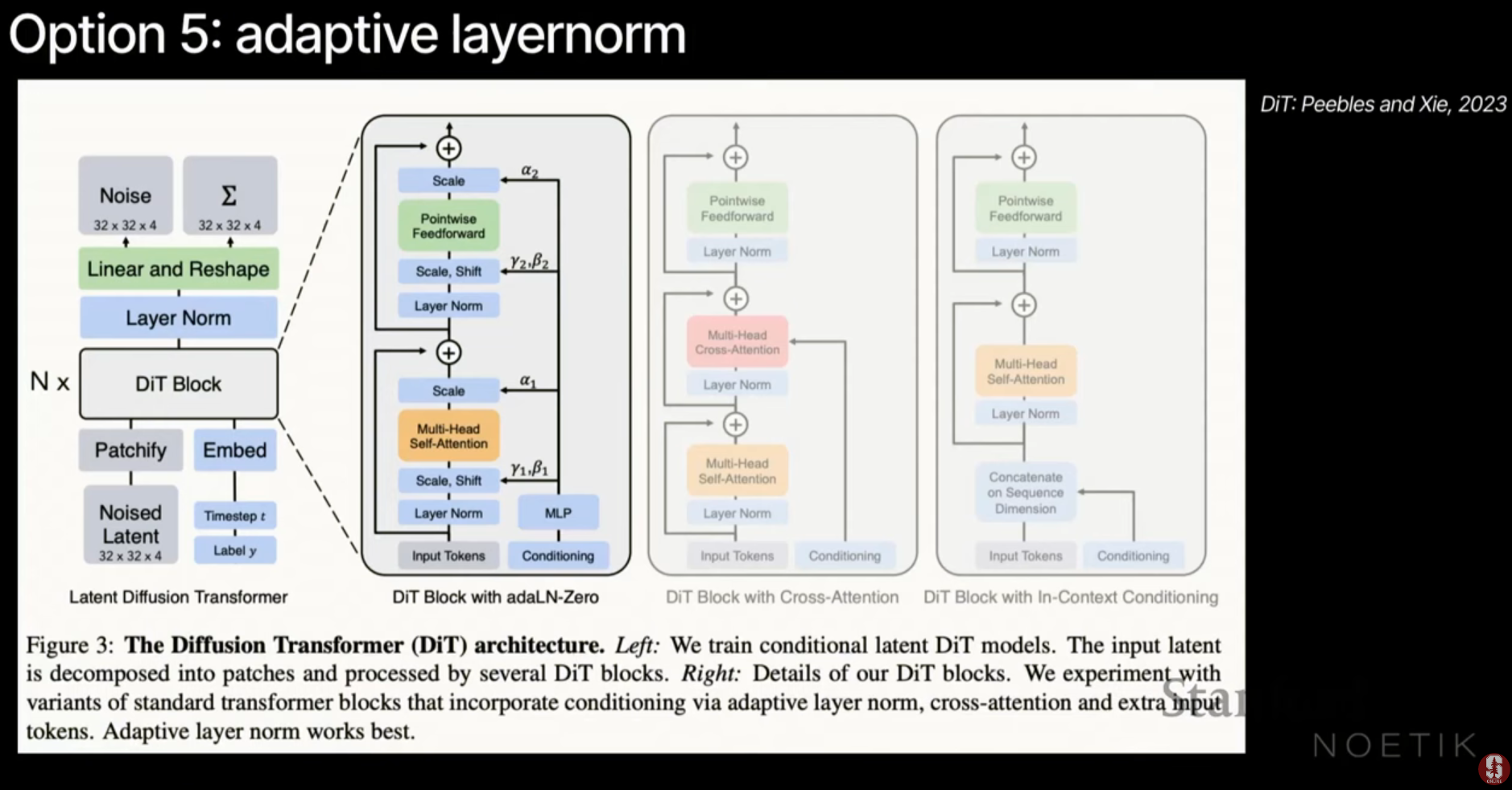
본 강의는 Noetik.ai의 ML 과학자인 Eshed Margalit이 진행하였으며, 신경과학적 관점과 머신러닝 기술을 결합하여 암 치료를 위한 멀티모달 월드 모델(Multimodal World Models)을 구축하는 방법을 다룹니다.AI의 통합 목표: AI의 핵심
34.[NLP] CS25 V5 7강 정리 [Transformers in Diffusion Models for Image Generation and Beyond]
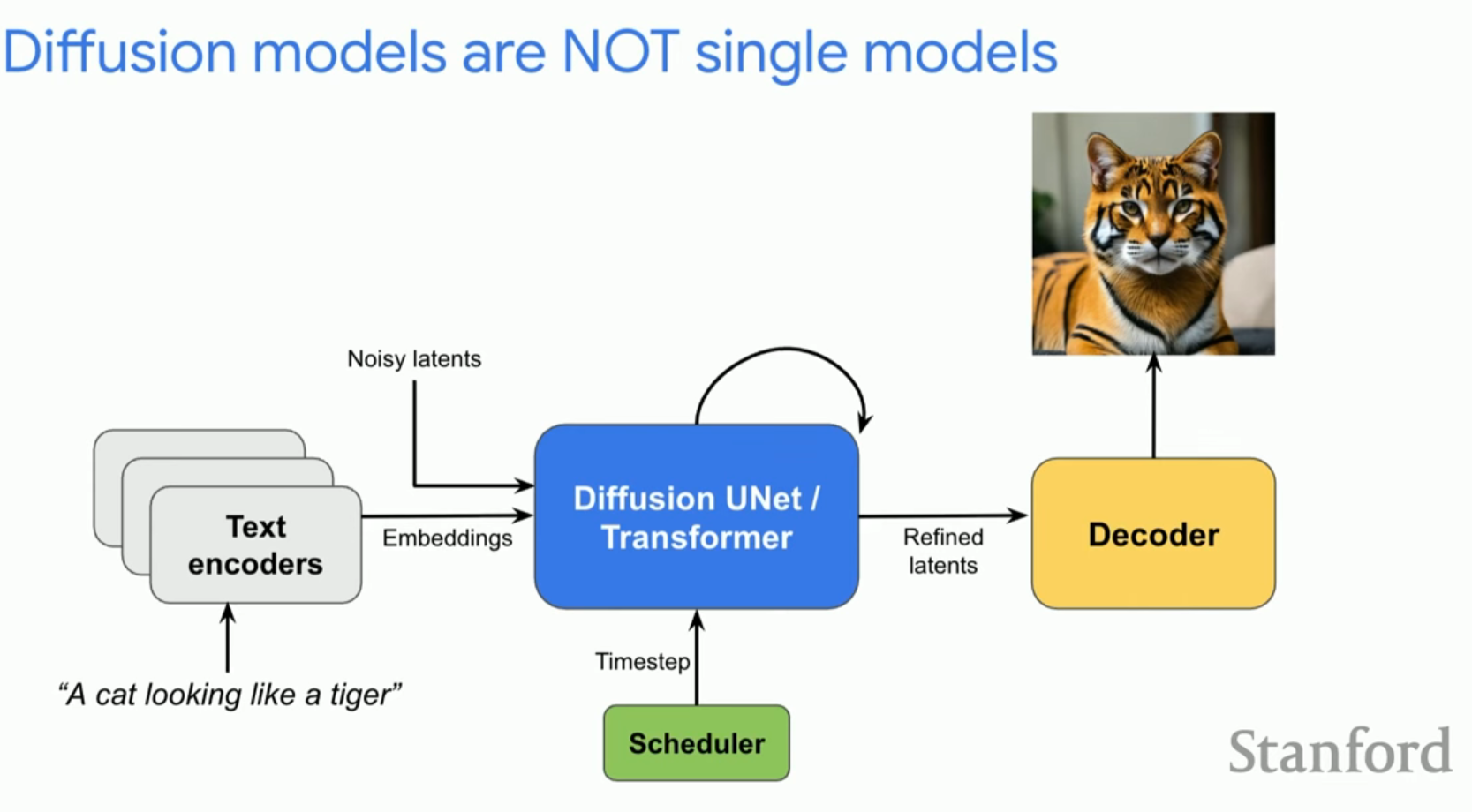
확산 모델은 무작위 노이즈 벡터를 점진적으로 디노이징(Denoising)하여 실사 이미지로 변환하는 반복적(Iterative) 프로세스입니다.반복적 성격: 한 번에 생성되는 GAN과 달리, 확산 모델은 순차적으로 노이즈를 제거하며 이미지를 정제합니다.조건부 생성: 텍스
35.[NLP] CS25 V5 8강 정리 [Transformers for Video Generation]
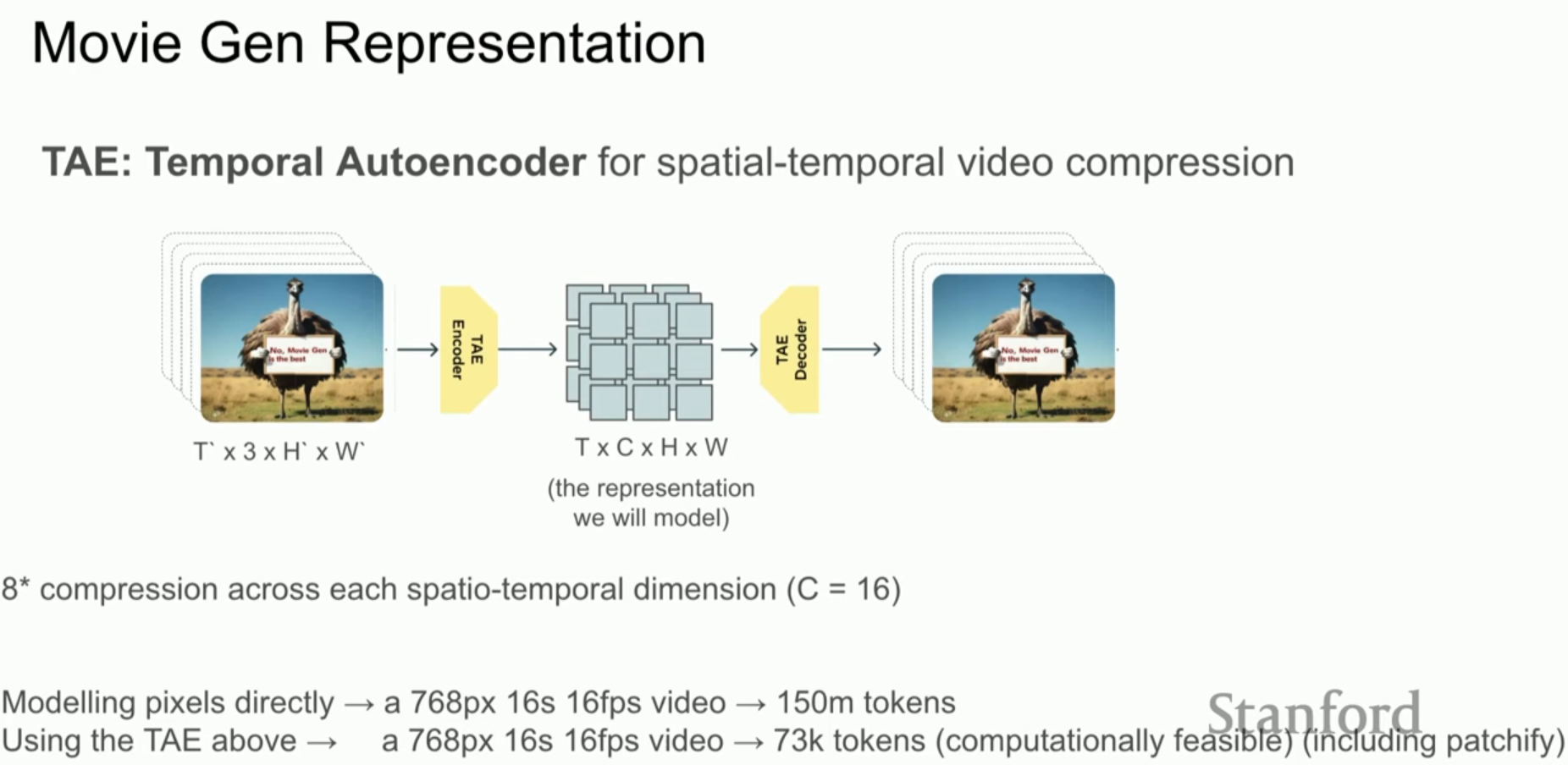
1. 비디오 생성 기술의 비약적 발전과 배경 기술적 진보: 2022년의 상태(State-of-the-art)와 2024년의 Movie Gen을 비교하면 불과 2년 만에 실사와 구분이 불가능한 수준으로 품질이 비약적으로 향상되었습니다. 물리 법칙의 학습: 최신 모델들은